Репликация БД: виды, модели и настройка
В продакшен-средах отказоустойчивость и доступность данных — не просто требования, а необходимость. Репликация баз данных (БД) — ключевой инструмент, который позволяет создавать копии данных на нескольких серверах, обеспечивая непрерывность работы даже при сбоях. Разберем, как устроена репликация, какие существуют механизмы репликации и как выбрать подходящий для вашего проекта.


- Что такое репликация БД и зачем нужна
- Архитектурные модели: Master-Slave, Multi-Master и Peer-to-Peer
- Модели синхронизации: от строгой консистентности до желаемой производительности
- Синхронная репликация: гарантия консистентности
- Технические методы реализации: как копируются данные
- Репликация в популярных СУБД: особенности настройки
- Проблемы и вызовы: с чем придется столкнуться
- Репликация vs Шардинг (горизонтальное партиционирование)
- Будущее и тренды: репликация в облаке и не только
Что такое репликация БД и зачем нужна
Репликация баз данных — процесс создания копий данных и их хранения на нескольких серверах. Это позволяет обеспечить отказоустойчивость и надежность БД, распределить нагрузку в высоконагруженных системах и приложениях.
Для поддержания актуальности данных изменения, которые вносятся в приоритетный сервер базы данных, полуавтоматически или автоматически применяются к копиям. Это необходимо и для того, чтобы обеспечить непрерывную работу сервисов при сбое главного сервера. В таком случае его заменит одна из реплик. Этот подход называется High Availability — повышение доступности БД.
Три причины использовать репликацию
Мы уже упомянули эти причины, теперь расскажем о них подробнее:
Доступность. При падении одного сервера система или приложение вручную или автоматически переключается на реплику. Таким образом сервис может работать с минимальными простоями.
Масштабирование чтения. Нагрузка SELECT-запросами распределяется между несколькими серверами, в том числе репликами. Это позволяет снизить риск перегрузки главного сервера и повысить производительность базы данных.
Резервное копирование и аналитика. Реплика используется для бэкапов и нагруженных отчетов, которые могут влиять на производительность базы данных.
Репликация — это базовый механизм построения масштабируемых, отказоустойчивых и надежных систем хранения данных.
Архитектурные модели: Master-Slave, Multi-Master и Peer-to-Peer
Архитектурная модель определяет, какие серверы будут принимать записи, как распространяются изменения и обеспечивается отказоустойчивость. Выбранный подход влияет на сложность сопровождения базы данных, устойчивость к сбоям и производительность. В большинстве корпоративных СУБД используются три модели.
Master-Slave (Источник-Реплика): классическая распространенная схема
В данной модели операции записи выполняются на сервере Master. Оттуда изменения передаются к репликам — Slaves. Чтение данных возможно как с главного сервера, так и с реплик.
Эта модель отличается понятной моделью согласованности данных и простотой реализации. Она поддерживается большинством популярных СУБД и используется там, где преобладают операции чтения.
Минус в том, что главный сервер Master будет единой точкой отказа, если не предусмотрены дополнительные механизмы автоматического переключения. Второй недостаток — невозможность масштабировать операции записи, поскольку изменения проходят через один узел.
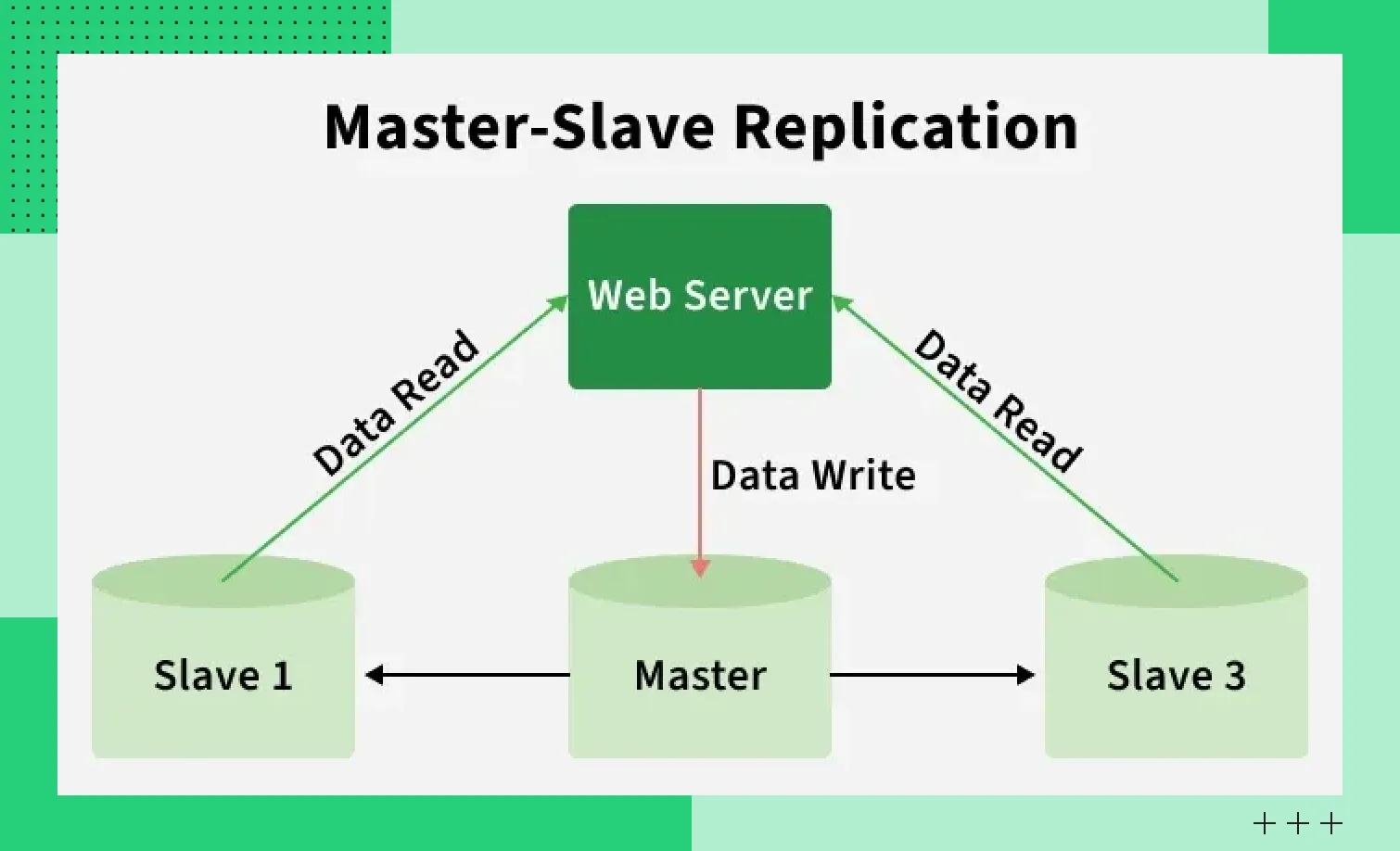 Репликация Master-Slave
Репликация Master-Slave Multi-Master (Источник-Источник): запись в несколько узлов
В этой модели операции записи одновременно принимают несколько узлов базы данных. Каждый участник процесса может принимать запросы на запись, однако на практике для PostgreSQL и MySQL это требует дополнительных расширений (для PostgreSQL — BDR, pglogical; для MySQL — Galera Cluster), так как встроенная Multi-Master репликация в этих СУБД отсутствует или имеет ограничения.
Модель Multi-Master подразумевает, что данные реплицируются между участниками кластера. Если какие-то данные изменяются одновременно, возможны конфликты. Их нужно своевременно обнаруживать и разрешать на уровне прикладной логики либо с помощью встроенных механизмов СУБД. Учитываются преднастроенные правила приоритета версий и временные метки.
Преимущество архитектуры Multi-Master — возможность масштабировать операции записи, поскольку нагрузка будет распределяться между несколькими узлами. Второй плюс — отказоустойчивость. Если один сервер выйдет из строя, то запись данных не остановится — в процессе будет задействован другой сервер. Это снижает риски простоя системы.
Минус архитектуры в сложности настройки и рисках конфликтов данных при параллельных изменениях. Наличие конфликтов может негативно влиять на логику приложения и приводить к временной несогласованности записей.
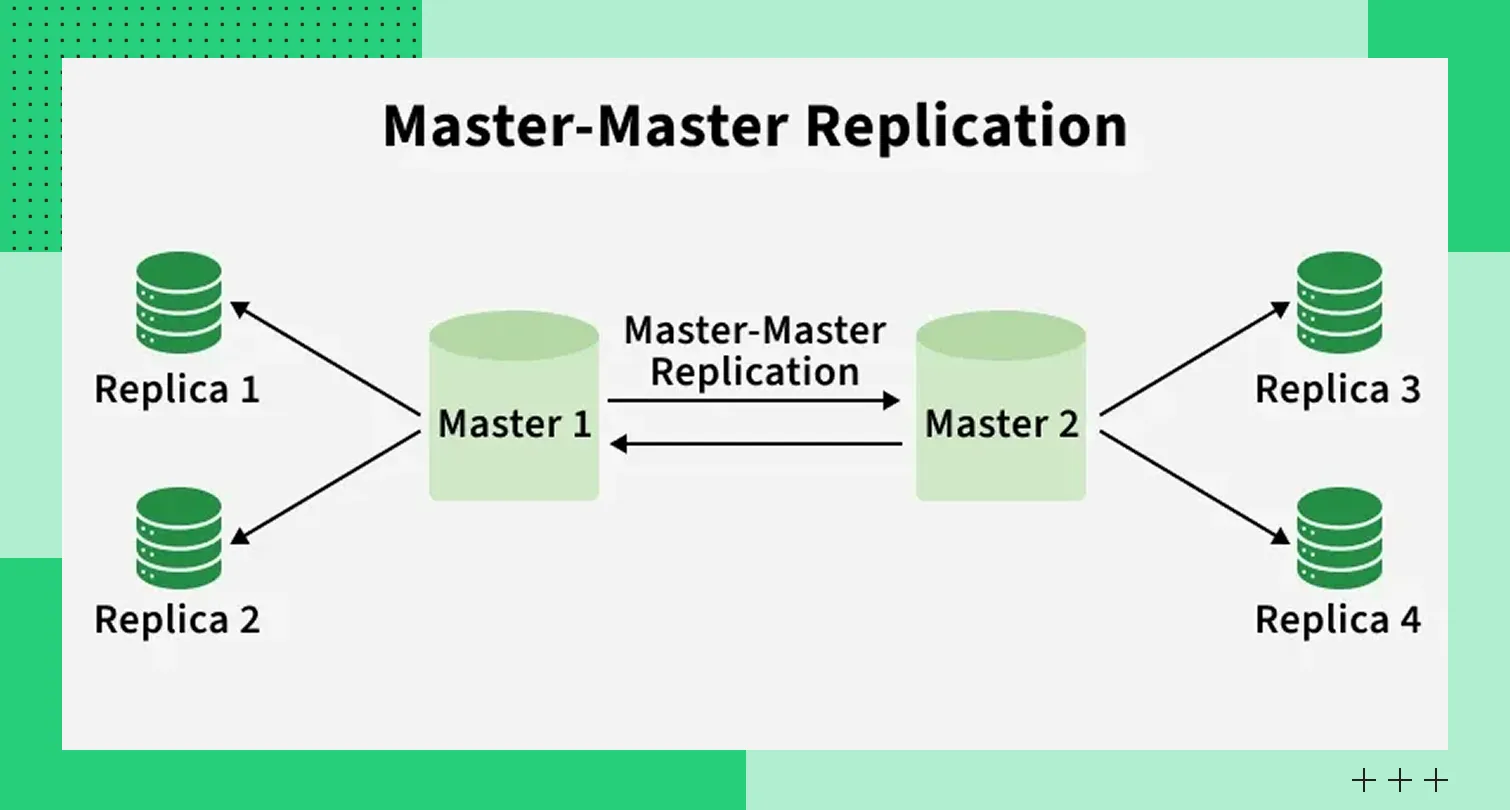 Репликация Master-Master
Репликация Master-MasterКаскадная и управляемая топологии (Chain, Star)
В таких топологиях изменения от приоритетного сервера получают не все узлы. В модели Chain данные от Master передаются к первой реплике, затем к следующей и дальше по алгоритму к участникам кластера. В схеме Star сервер Master передает изменения определенному числу промежуточных узлов. Они дальше распространяют данные на те реплики, которые находятся у них в подчинении.
Принцип таких моделей репликации описан на схемах:
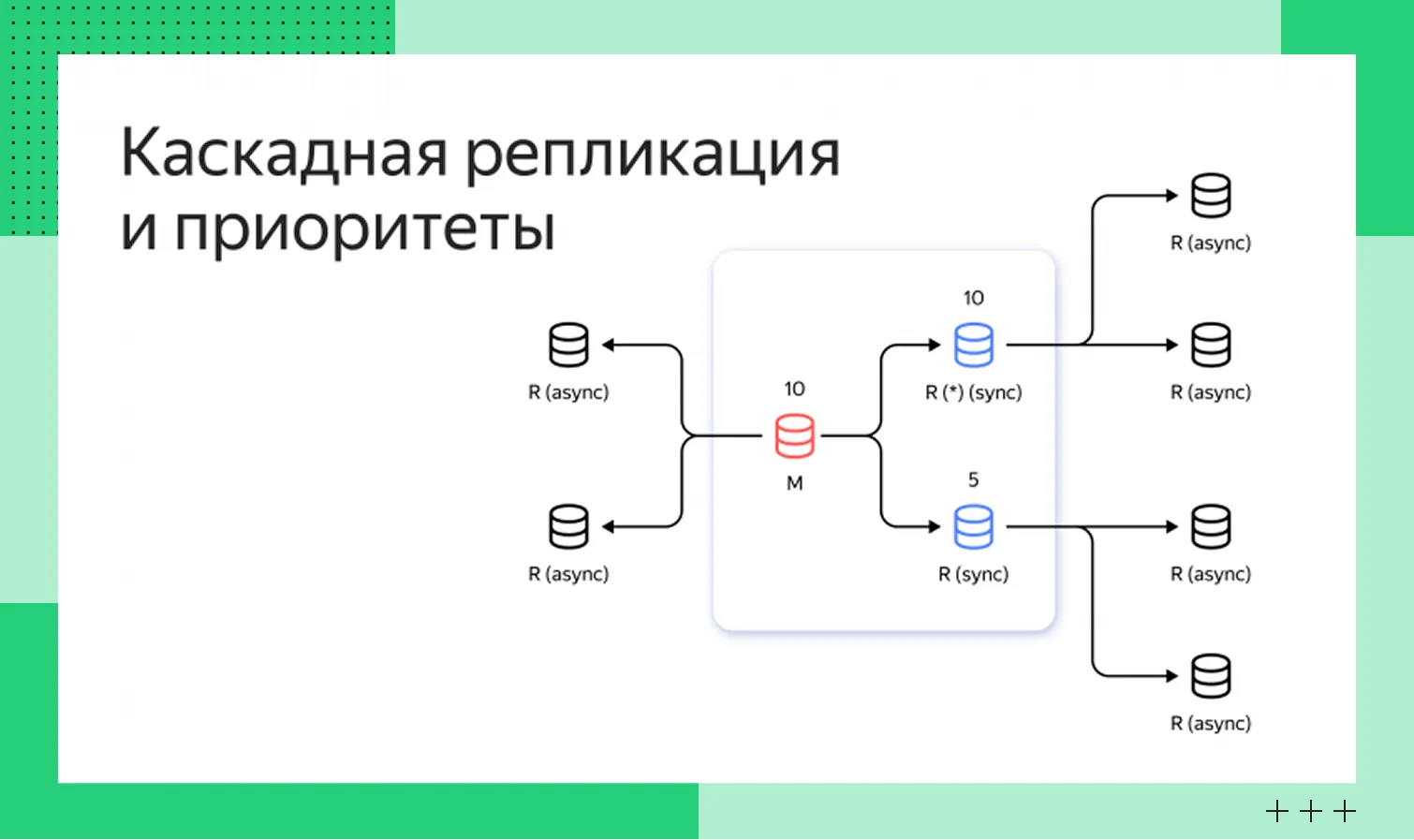 Каскадная репликация
Каскадная репликация Управляемая топология
Управляемая топологияКаскадная и управляемая топологии применяются в больших кластерах с целью разгрузить главный сервер. Такие подходы позволяют уменьшить количество прямых соединений с Master, оптимизировать сетевой трафик и снизить потребление вычислительных ресурсов.
Преимущество таких схем репликации — легкая масштабируемость, что важно при большом количестве реплик. Модели Chain и Star упрощают подключение новых узлов, повышают устойчивость системы к пиковым нагрузкам и высвобождают ресурсы главного сервера Master.
Недостаток — возможные задержки при распространении изменений, поскольку данные идут на реплики не напрямую, а через промежуточные узлы. Также усложняется мониторинг системы и диагностика проблем на стороне зависимых реплик.
Параметр | Master-Slave | Multi-Master | Chain и Star |
Принцип работы | Записи выполняются на главный узел — Master. Изменения последовательно передаются на дополнительные узлы | Каждый сервер может принимать записи. Внесенные изменения синхронизируются между участниками кластера | Master передает изменения на промежуточные узлы, которые от них поступают на другие реплики согласно схеме записи данных |
Тип операций записи | Только на Master | На всех узлах | На Master через промежуточные узлы |
Чтение данных | С Master и с реплик или только с реплик | С любого сервера | С главного узла и реплик |
Согласованность данных | Четкая последовательность, согласованность | Возможны конфликты при параллельных изменениях на разных узлах | Зависит от расстояния до Master-узла. При большом расстоянии бывают отставания |
Отказоустойчивость | Единая точка отказа — сервер Master | Любой узел может принимать записи | Промежуточные узлы могут стать узким местом |
Масштабируемость по записи | Ограничена Master-узлом | Нагрузка распределяется между узлами | Master остается источником записи, но нагрузку на сеть можно оптимизировать |
Масштабируемость по чтению | Можно добавить реплики | Можно читать с любого узла | Зависит от расположения узлов и задержки передачи данных |
Сложность настройки | Легкие реализация и мониторинг | Нужны механизмы разрешения конфликтов | Нужно контролировать процессы записи и промежуточные узлы |
Риск конфликтов данных | Редко бывают конфликты | Возникает при одновременных изменениях | Редкие конфликты |
Задержки репликации | Минимальные благодаря прямому соединению между мастер-узлом и репликами | Иногда возникают при синхронизации узлов | Зависит от количества промежуточных узлов и их производительности |
Что нужно контролировать | Состояние реплик | Конфликтующие записи и синхронизацию | Промежуточные узлы и целостность цепочки |
Применимость | OLTP и системы, где преобладает чтение | Системы с частыми операциями записи | Большие кластеры с множеством реплик и системы, где нужна оптимизация сетевого трафика |
Плюсы | Модель, которую легко эксплуатировать | Масштабирование операций записи и отказоустойчивость | Оптимизация нагрузки на Master-узел, масштабируемость и оперативное подключение новых узлов |
Минусы | Проблемы при отказе сервера Master, ограниченные операции записи | Сложные настройки и риски конфликтов при записи данных | Задержки распространения изменений и сложный мониторинг |
Модели синхронизации: от строгой консистентности до желаемой производительности
Механизм репликации не определяет случаи, когда транзакция будет считаться зафиксированной. За баланс между отказоустойчивостью, задержками записи и консистентностью данных отвечает модель синхронизации. Таких моделей три — синхронная, асинхронная и полусинхронная.
Синхронная репликация: гарантия консистентности
При такой модели репликации фиксация транзакций на сервере Master происходит только после того, когда все реплики подтвердят получение и запись данных. В СУБД подход реализуется по-разному. Важно отметить, что синхронная репликация не включена по умолчанию. Например, в PostgreSQL параметр synchronous_commit по умолчанию имеет значение on, но synchronous_standby_names пуст, поэтому фактически репликация работает в асинхронном режиме до явной настройки standby-узлов. При настройке синхронная репликация в PostgreSQL управляется через параметры synchronous_commit и synchronous_standby_names. При этом можно указать не только ожидание от всех реплик, но и кворумное подтверждение с помощью ключевого слова ANY. Например, ANY 2 (node1, node2, node3) будет ждать подтверждения от любых двух из трех реплик.
Модель дает гарантии консистентности данных. После завершения транзакции сведения уже будут на репликах и никуда не исчезнут даже при неожиданном отказе Master-узла. Однако есть проблема — зависимость скорости записи от медленных или недоступных реплик.
Преимущества | Минусы |
Консистентность данных | Задержка записи |
Zero Data Loss при отказе главного узла | Блокирование записи при недоступности реплики |
Предсказуемое поведение при создании реплик | Слабое масштабирование в геораспределенных средах |
Применимость для критичных данных | Необходимость в скоростной сети |
Асинхронная репликация: производительность в ущерб гарантиям
В такой модели мастер-узел фиксирует транзакцию сразу после локальной записи, а на реплики изменения отправляются позже. Это стандартный подход для СУБД MySQL, PostgreSQL и MongoDB по умолчанию. В PostgreSQL асинхронная репликация настраивается параметром synchronous_commit = off, в MongoDB — write concern w: 1.
Асинхронная репликация позволяет минимизировать задержки записи и адаптировать систему к растущим нагрузкам. Стоит учитывать, что в случае отказа главного узла последние транзакции могут не попасть на реплики. Еще важно знать, что дополнительные узлы часто отстают от источника, что может сказаться на чтении данных.
Преимущества | Минусы |
Высокая производительность записи | Возможна потеря данных |
Минимальная задержка транзакций | Replication lag на репликах |
Легкое масштабирование | Риск потери данных при падении Master |
Простая эксплуатация |
Полусинхронная репликация: баланс между гарантиями и скоростью
Полусинхронная репликация — промежуточный вариант между двумя вышеописанными моделями. В этом сценарии Master-узел ждет подтверждения хотя бы от одной реплики перед фиксацией транзакции. Подход поддерживается многими современными СУБД как опциональный режим, но не является стандартным «из коробки». Например, в MySQL требуется установка плагинов semi-sync replication на источнике и на реплике (в MySQL 8.0 — rpl_semi_sync_source и rpl_semi_sync_replica соответственно), в PostgreSQL настраивается через параметры synchronous_commit и synchronous_standby_names с указанием хотя бы одного standby.
В плане рисков потери данных полусинхронная репликация выигрывает у асинхронной модели. При этом нет таких жестких требований, как при синхронном подходе.
Преимущества | Минусы |
Снижение рисков потери данных | Необходимость погружения в топологию сети |
Отсутствие необходимости в подтверждении записи от всех реплик | Возможное отставание записи на репликах |
Устойчивость к сбоям | Сложность настройки |
Применимость в продакшен-среде |
Технические методы реализации: как копируются данные
Цель репликации одна — доставить копии данных на реплики. На практике СУБД используют для этого разные механизмы. Описываем три подхода, которые чаще всего применяются в продакшен-среде.
Репликация на основе бинарного журнала (Binary Log/WAL)
В этом подходе главный сервер фиксирует в журнале транзакций все изменения, а реплики воспроизводят их в том же порядке. В MySQL и MariaDB сервер Master записывает изменения в бинарный лог, Replica читает и применяет его. В PostgreSQL физическая репликация реализуется через потоковую репликацию (streaming replication) на основе WAL, где изменения передаются с primary на standby в реальном времени. WAL Shipping — это более старый механизм доставки архивов WAL, который не используется для синхронной репликации в продакшене.
Преимущества | Риски |
Проверенная модель | Реплика привязана к структуре и версии данных |
Ожидаемый порядок транзакций | Ограничена гибкость, поскольку сложно реплицировать часть данных |
Минимальная логическая сложность | Задержка репликации при чрезмерной нагрузке на источник |
Применимость для OLTP-нагрузок | Создание реплик требует внешних инструментов |
Логическая репликация (Logical Decoding)
Логическая репликация работает на более высоком уровне абстракции. Передаются не физические изменения блоков, а логические операции, такие, как INSERT и UPDATE. Реплики самостоятельно применяют операции к своим таблицам. Это удобно, но нужны сложные предварительные настройки.
Преимущества | Риски и проблемы |
Выборочная репликация таблиц | Дополнительная нагрузка на CPU |
Возможность репликации между версиями СУБД | Не все DDL автоматически реплицируются |
Удобство для миграций и интеграций | Нужны четкие схемы организации данных |
Применимость для CDC и аналитики | Сложные отладка и мониторинг |
Репликация на уровне дисковых блоков
В этом подходе реплицируются не данные СУБД, а дисковые блоки. Для базы данных ничего не меняется, поскольку логика синхронизации происходит на уровне инфраструктуры. Такая схема подойдет для High Availability-сценариев. Только она сложно реализуется и имеет много ограничений.
Преимущества | Риски и ограничения |
Прозрачность для СУБД | Мгновенное копирование ошибок |
Независимость от типа базы данных | Сложный процесс переключения с приоритетного узла на реплику |
Минимальный RPO (целевая точка восстановления) | Отсутствие выборочности данных |
Применимость к legacy-системам | Слабое масштабирование |
Репликация в популярных СУБД: особенности настройки
При выборе СУБД для продакшен-среды важную роль играет реализация репликации. У каждой системы свои подходы к настройке реплик и управлению ими. Рассмотрим особенности для популярных СУБД — MySQL, PostgreSQL и MongoDB.
Критерий | MySQL и MariaDB | PostgreSQL | MongoDB |
Базовая архитектура | Primary → Replica (Master–Slave) | Primary → Standby и Subscriber | Replica Set (Primary + Secondaries + Arbiter) |
Типы репликации | Асинхронная, полусинхронная | Физическая (streaming), логическая | Встроенная с настраиваемыми уровнями консистентности (write concern), включая асинхронный режим по умолчанию и синхронное подтверждение большинством узлов (majority) |
Механизм передачи данных | Binary Log (binlog) | WAL (Write-Ahead Log) | Oplog |
Гранулярность репликации | Транзакции и строки | Физическая — весь кластер Логическая — отдельные таблицы | Вся база данных |
Форматы репликации | Statement-Based (SBR)Row-Based (RBR)Mixed | WAL-записи и логические изменения строк | BSON-операции |
GTID / идентификаторы транзакций | GTID (обязателен для автоматизации failover) | LSN (физическая) Replication slots (логическая) | Timestamp + term |
Failover | Внешний (Orchestrator, MHA, ProxySQL) | Внешний (Patroni, repmgr). Начиная с PostgreSQL 16, добавлена встроенная поддержка pg_promote() для управления продвижением standby | Встроенный, автоматический |
Выбор лидера | Нет (назначается вручную) | Нет (через внешние инструменты) | Автоматические выборы (Raft-подобный алгоритм) |
Согласованность данных | Eventual consistency | Физическая — почти синхронная Логическая — eventual | Eventual (настраиваемая) |
Чтение с реплик | Да (read replicas) | Да | Да (read preference) |
Политики чтения | На уровне приложения и прокси | На уровне приложения | primary, secondary, nearest и majority |
Задержка репликации | Возможна при пиковой нагрузке | Минимальная (физическая) | Возможна при сетевых задержках |
DDL-операции | Реплицируются (зависит от формата) | Физическая — всегда; Логическая — не реплицируются автоматически (требуют ручного выполнения на подписчиках или использования расширений, таких как pglogical) | Реплицируются автоматически |
Обновление версии без влияния на работу системы | Ограниченно | Возможно (logical replication) | Возможно (rolling update) |
Типичные сценарии использования | Масштабирование чтения, понятные топологии | HA-кластеры, строгая надежность | HA и горизонтальное масштабирование |
Сложность настройки | Средняя | Высокая | Низкая |
Нативность репликации | Частично (failover — внешний) | Частично | Встроена |
Production-ready из коробки | Да, но с внешними компонентами | Да, но требует обвязки | Да |
Проблемы и вызовы: с чем придется столкнуться
При внедрении репликации БД многие сталкиваются с проблемами и техническими ограничениями. Не застрахованы даже те, кто использует облачные сервисы и продвинутые СУБД. Рассказываем, что делать, чтобы держать процесс репликации под контролем.
Отставание реплики (Replication Lag) и последствия
Отставание происходит, когда реплики не успевают синхронизироваться с главным сервером. Последствие — «устаревшее» чтение (stale read). Это значит, что до пользователя доходят данные, которые уже изменились на сервере Master.
Выявить отставания помогают такие метрики, как задержка применения транзакций, разница между номерами транзакций на главном сервере и репликах, временные метки свежих изменений.
Отставания нужно оперативно выявлять, если приложения для принятия решения используют только актуальные, часто обновляемые данные. В этом случае из-за проблем с доставкой изменений может пострадать бизнес-логика.
Конфликты репликации в Multi-Master топологиях
В Multi-Master-архитектурах бывают ситуации, когда одна и та же запись одновременно меняется на нескольких узлах. Такие конфликты нужно выявлять и разрешать, чтобы поддерживать целостность данных. Что можно сделать:
применить правила приоритета узлов;
изучить временные метки для выбора последней версии данных;
обработать изменения на уровне прикладной логики.
В третьем случае система зафиксирует конфликт и предложит приложениям самостоятельно выбрать правильное значение на основе заложенных в логику принципов.
Согласованность чтения (Read Consistency)
Проблемы согласованности могут возникать, когда реплики обслуживают операции чтения. Примеры ситуаций:
Монотонное чтение (Monotonic Reads) — ситуации, когда последовательные запросы пользователя могут возвращать старые данные. И это несмотря на то, что обновления уже применились на главном узле. Пример такого случая — пользователь видит старую версию своего аккаунта после недавнего редактирования.
Чтение собственных записей (Read Your Writes) — недавно внесенные изменения не отображаются на репликах из-за того, что дополнительный узел отстает от главного. Такие ситуации нарушают логику работы сервисов, особенно тех, которые предоставляют доступ к функционалу через сетевое соединение.
Эти проблемы часто связаны с асинхронной моделью репликации, при которой данные на дополнительных узлах могут обновляться с задержкой. В других подходах такое тоже бывает, но реже. Бороться с проблемой можно несколькими способами:
Принудительное чтение с Master после записи. Если изменения только что внесены, критичные запросы стоит какое-то время направлять на главный сервер. Способ повысит нагрузку на узел, зато обеспечит доступ к достоверным данным.
Отслеживание задержки реплик. Состояние можно мониторить с помощью специальных систем. Они зафиксируют, насколько отстают реплики и дадут приложению возможность подождать, когда дополнительные узлы «догонят» главный.
Схемы контроля согласованности можно использовать непосредственно на уровне приложения. Например, назначать на один узел определенные сессии, фиксировать версии данных или применять кворумное чтение.
Репликация vs Шардинг (горизонтальное партиционирование)
При проектировании масштабируемых систем хранения данных иногда возникает выбор между репликацией и шардированием. Важно понимать различия между подходами и то, как та или иная схема будет влиять на отказоустойчивость и производительность. Рассказываем, когда выбирать репликацию, когда — шардирование. И сценарии, где допустимо сочетание подходов.
Отличие: копирование данных vs разделение данных
При репликации одни и те же данные копируются на несколько узлов. Все реплики будут содержать одинаковый набор информации. Логика работы с данными в этом сценарии такая — операции чтения можно распределять между узлами, снижая нагрузку на главный сервер. Если главный сервер выйдет из строя, его заменят реплики. Таким образом информация все равно будет доступна пользователям.
Шардинг предполагает разделение данных на шарды — группы, каждая из которых будет храниться на своем узле. Информация в этом случае не копируется, а распределяется между серверами. Каждый сервер будет отвечать за разные подмножества данных. Цель подхода — наращивание объема хранимой информации и масштабирования операции записи. Нагрузка параллельно распределяется между узлами, то есть запись можно одновременно выполнять в разные шарды.
Репликацию целесообразно использовать в сценариях, где чтение используется чаще записи, и данные постоянно должны быть доступны. Шардинг применяется в системах с большими объемами информации.
Комбинированный подход: шардирование с репликацией
На практике часто сочетаются оба подхода. Сначала данные делятся на шарды, затем происходит репликация шардов на несколько узлов. Такой подход позволяет масштабировать операции запись и чтение и одновременно обеспечивать отказоустойчивость.
У каждого шарда будет свой набор реплик, среди которых выбирается приоритетный узел и резервные узлы. Если главный выйдет из строя, система переключится на реплику.
Важно отметить, что в отличие от MySQL (NDB Cluster) и MongoDB, PostgreSQL не имеет встроенного шардинга. Для горизонтального партиционирования в PostgreSQL используются расширения, такие как Citus Data, или логика на уровне приложения.
Будущее и тренды: репликация в облаке и не только
В связи с развитием и распространением облачных платформ формируются новые подходы к репликации, которые отличаются от классических схем. Рассказываем, какие подходы становятся популярными.
Управляемые облачные сервисы репликации
Облачные провайдеры включают встроенные механизмы репликации в свои продукты для управления базами данных. Например, в AWS Amazon RDS и Aurora это Read Replicas, в Google Cloud — Cloud SQL Replicas, в Microsoft Azure — Readable Secondaries для Azure SQL и PostgreSQL. Эти механизмы позволяют создавать реплики и управлять ими без специфических ручных настроек и развертывания инфраструктуры.
Облачные сервисы используются для масштабирования операций чтения, удобства использования и повышения доступности баз данных. Созданные реплики автоматически синхронизируются. За восстановление серверов при сбоях, поставку обновлений и регулярный мониторинг отвечает провайдер.
При всех плюсах использования облачных решений есть и минусы. Во-первых, это зависимость от провайдера и функционала конкретного сервиса. Во-вторых, асинхронный характер репликации, что критично для некоторых приложений.
Многорегионная репликация для глобальных приложений
Многорегиональная репликация подходит для приложений и систем с геораспределенной многочисленной аудиторией. Подход подразумевает, что данные будут копироваться между дата-центрами в разных регионах. Это позволит не потерять доступ к информации и снизит риски задержек для пользователей.
В этом подходе приходится искать компромиссы между отсутствием задержек, доступностью и консистентностью данных. Компромиссы описываются PACELC-теоремой, которая гласит, что система должна выбирать между задержкой и консистентностью в нормальном режиме работы, а не только при сбоях. На практике это значит, что нужно быть готовым к асинхронной репликации и временной несогласованности данных.
Change Data Capture (CDC) и стриминг данных
Репликация иногда применяется не на уровне базы, а на уровне изменений данных. С помощью технологии Change Data Capture можно фиксировать изменения в журнале транзакции и в виде потока событий передавать их в другие системы.
Потоки изменений для дальнейшей обработки передаются в стриминговые сервисы, например, Apache Kafka, системы поиска вроде Elasticsearch или распределенные кэши. Для промышленного использования Kafka удобно применять в виде управляемого решения. Сервис Evolution Managed Kafka от Cloud.ru предоставляет готовый кластер Apache Kafka® для потоковой обработки данных в реальном времени. Он избавляет от необходимости заниматься инфраструктурой, обеспечивает надежность, масштабируемость и безопасность корпоративного уровня, а также легко интегрируется с другими облачными сервисами платформы.
Благодаря такому подходу можно строить событийно-ориентированные архитектуры, сразу синхронизировать данные, разделять аналитические и транзакционные нагрузки.
Заключение
Репликация баз данных — это не отдельная специфическая настройка, а базовый элемент архитектуры отказоустойчивой инфраструктуры. Чтобы адаптировать систему к пиковым нагрузкам, минимизировать задержки сети и риски сбоев, нужно правильно выбрать модели репликации и синхронизации данных. Ответьте себе на вопросы:
допустима ли частичная потеря данных;
критичны ли задержки записи;
часто ли возникают сбои при выполнении запросов;
как система должна вести себя при отказе главного узла.
Ответы на вопросы помогут подобрать подход к репликации — синхронный, асинхронный или полусинхронный. Дальше следует определить правильную топологию — Master-Slave, Multi-Master или каскадную схему. При выборе учитывайте преимущества и минусы каждого варианта.