
Графические ускорители необходимы для обработки больших объемов данных, особенно требующих вычислений с плавающей запятой. Такие мощности — подходящий инструмент для ресурсоемких AI и ML-приложений. Например, для обучения и инференса нейронных сетей и языковых моделей, анализа данных. Видеокарты также нужны для работы с качественной графикой, 3D-моделированием, рендерингом или видео.
Виртуальные машины
Идеальный вариант для начальных стадий разработки и тестирования благодаря простой гибкой настройке.
Виртуальные машины с GPU позволяют быстро развернуть инфраструктуру с нужными ресурсами и масштабироваться по мере необходимости.
ML-сервис
Подходящий вариант для ускорения разработки и обучения моделей. Вычисления происходят на мощных одиночных или кластерных узлах с поддержкой Infiniband, чтобы обеспечить высокую пропускную способность с минимальными задержками.
ML-сервис с графическим процессором позволяет масштабировать ресурсы и автоматизировать процессы обучения и инференса сложных моделей.
Выделенный сервер
Оптимальный вариант для задач, которые требуют непрерывной работы с графическим процессором, или работы с интенсивными вычислительными задачами.
Выделенные серверы с GPU обеспечивают максимальную производительность с полным контролем над аппаратными ресурсами.
Графические ускорители
Модель | vRAM | Пропускная способность памяти | Для кого | Как получить |
B300 | 288 ГБ HBM3e | 8 ТБ/с | Для юридических лиц и ИП | |
H100 | 80 ГБ HBM2e/HBM3 | 3.35 ТБ/с | Для юридических лиц и ИП | |
A100 | 80 ГБ HBM2e | 2 ТБ/с (80 ГБ vRAM) | Для юридических лиц и ИП | |
A100 | 40 ГБ | 1.55 ТБ/c (40 ГБ vRAM) | Для юридических лиц и ИП | |
V100 | 16/32 ГБ HBM2 | 900 ГБ/с | Для физических лиц | Промокод для личного кабинета EVOLUTIONGPUV100 В личный кабинет |
Наличие видеокарт уточняйте у менеджера через заявку на консультацию
* Акцией предусмотрено применение одного промокода и участие в акции ограничено для отдельных видов договоров
Преимущества сервера с видеокартой
Ускоренное выполнение задач
Графические процессоры существенно ускоряют выполнение операций с плавающей запятой, уменьшают время обучения и вывода моделей.
Эффективное использование ресурсов
Графические ускорители обрабатывают параллельные задачи, максимизируют использование ресурсов, снижают стоимость вычислений
Повышенная производительность
Мощности с GPU обеспечивают высокую производительность AI- и ML-приложений, что позволяет быстрее получать результаты
Стоимость вычислительных мощностей с GPU
Возможности | Выделенный сервер | Виртуальная машина | ML-сервис |
Гибкость конфигурации | Средняя | Высокая | Средняя |
Контроль над ресурсами | Полный | Частичный | Частичный |
Обучение на нескольких GPU | Да | Да | Да |
Распределенное обучение (Multi-node) | Нет | Нет | Да |
Поддержка сетевых подключений Infiniband | В зависимости от конфигурации | Нет | Да |
Поддержка NVLink | В зависимости от конфигурации | Нет | В зависимости от конфигурации |
Предустановленное ML-окружение | Нет | Нет | Да |
Тарификация | Месяц | Час | Месяц/Минута |
Круглосуточная поддержка | Да | Да | Да |
Модель оплаты | Allocated | Pay-as-you-go | Allocated / Pay-as-you-go |
Цена (с НДС) | От 5 355 000 руб. в месяц HGX (8xH100 80GB) | V100 от 240 руб за час | V100 от 2,5 руб за минуту A100 от 4,5 руб за минуту H100 от 9,5 руб за минуту |
Основные сценарии использования
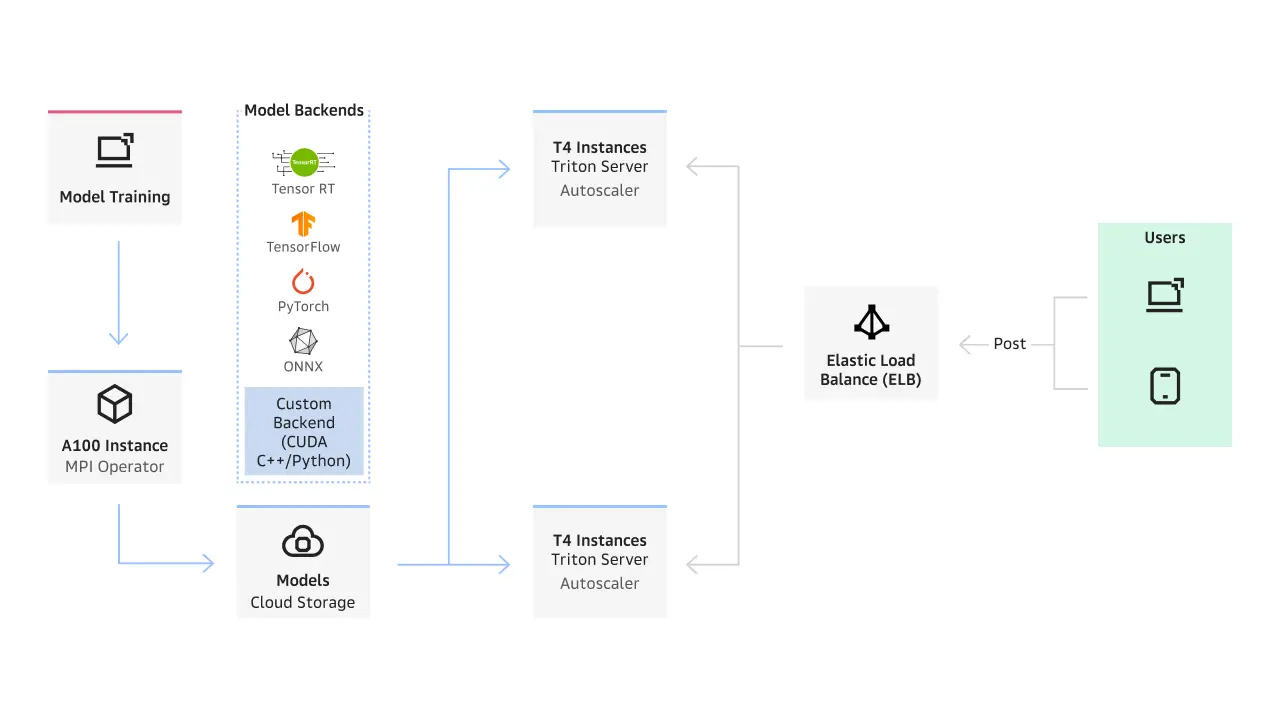
Сократить время с нескольких недель до нескольких часов на разработку, тестирование и внедрение нейронных сетей для компьютерного зрения, обработки естественного языка или рекомендательных систем
Эффективность использования GPU в облаке
Низкие стартовые затраты
Преимущество: аренда виртуальных машин по мере необходимости исключает большие начальные инвестиции в аппаратное обеспечение.
Экономия: оплата только за используемые ресурсы сокращает расходы.
Ускорение научных и инженерных разработок
Преимущество: облачные ресурсы быстро масштабируют вычислительные мощности для сложных задач.
Экономия: время на исследования сокращается, команды R&D быстрее переходят от экспериментов к внедрению.
Высокая производительность
Преимущество: полный доступ к мощным аппаратным ресурсам обеспечивает высокую производительность.
Экономия: скорость выполнения задач сокращает время на разработку и вывод продукта на рынок.
Гибкость в изменении конфигураций
Преимущество: возможность быстро менять конфигурации виртуальных машин под текущие задачи.
Экономия: регулирование ресурсов в зависимости от нагрузок оптимизирует затраты.
Снижение затрат на рабочую силу
Преимущество: ML-сервисы автоматизируют рутинные задачи из MLOps цикла.
Экономия: рабочее время сотрудников распределяется на более важные и сложные задачи.
Сокращение переменных затрат
Преимущество: удобное планирование бюджета с фиксированными затратами на выделенные серверы.
Экономия: долгосрочная аренда снижает переменные затраты.
Оптимально для краткосрочных задач
Преимущество: подходит для краткосрочных проектов или временных нужд.
Экономия: нет необходимости в долгосрочной аренде или покупке дорогостоящего оборудования.
Проверка гипотез
Преимущество: доступ к нужной конфигурации ресурсов ускоряет тестирование новых идей и гипотез.
Экономия: существенное сокращение времени и затрат на развертку тестовой среды и экспериментальные вычисления.
Полный контроль над конфигурацией
Преимущество: возможность настроить сервер для специфических задач.
Экономия: эффективное использование ресурсов, снижение затрат на администрирование и обслуживание благодаря настройке под конкретные нужды.
Дополнительные возможности
Ответы на вопросы

Вебинары
Истории успеха
Cloud.ru – ведущий провайдер облачных и AI‑технологий
Больше чем просто поддержка
