Брокер сообщений Apache Kafka: архитектура, принципы работы и применение
Apache Kafka соединяет микросервисы, обрабатывает транзакции в реальном времени, управляет потоками информации в крупных компаниях, которые известны на весь мир. К примеру, 80% компаний из рейтинга Fortune 100 используют именно Apache Kafka.


Когда вы делаете заказ в интернет-магазине, ставите кому-то лайк в соцсети или оставляете заявку на консультацию, Apache Kafka передает сообщение об этом в какой-либо сервис. Благодаря этому вы можете получить свою покупку, а лента в соцсетях подстроится под вас.
В статье расскажем, что такое Apache Kafka и для чего он нужен. А еще поговорим о его архитектуре, принципах работы и областях применения.
Что такое Apache Kafka?
Apache Kafka (или же просто Kafka) — это брокер сообщений, платформа для потоковой обработки событий. Kafka принимает, хранит и распределяет непрерывные потоки событий от тысяч источников.
Рассмотрим работу Kafka на примере интернет-магазина. Каждое действие пользователя — просмотр товара, добавление в корзину, оплата — это событие. Kafka фиксирует все эти события в реальном времени и доставляет их в нужные источники, например в базу данных или сервис аналитики.
Apache Kafka — проект с открытым исходным кодом. Облачные провайдеры предлагают управляемые версии Kafka, которые облегчают работу с брокером. С Evolution Managed Kafka® вам не придется заниматься инфраструктурой, переживать о надежности и безопасности: все уже предусмотрено, а еще можно работать в интуитивно понятном интерфейсе.
В каких задачах используется Kafka:
Публикация и подписка на потоки записей. Приложения могут отправлять данные в Kafka и читать их. Отправителей называют продюсерами, а получателей — консьюмерами. Продюсерами могут быть, например, микросервисы: приложение для аутентификации пользователей, приема оплаты.
Надежное хранение. Kafka сохраняет все отправленные записи на диск. Данные не теряются после прочтения и могут быть использованы повторно, например, из базы данных сведения о заказе интернет-магазина можно отправить на склад, чтобы поставщики занялись сборкой.
Обработка в реальном времени. Данные становятся доступны консьюмерам сразу после публикации, нет никаких задержек.
Масштабируемость и отказоустойчивость. Kafka работает как кластер из нескольких серверов. Если один сервер выходит из строя, другие продолжат работу, и данные не затеряются.
 Узнать больше о том, как работает Kafka, можно из официальной документации
Узнать больше о том, как работает Kafka, можно из официальной документацииKafka родилась внутри LinkedIn. В 2010 году инженеры компании столкнулись с проблемой: сотни внутренних систем генерировали данные, но не могли обмениваться ими быстро и надежно. Существующие решения были слишком медленными, сложными или ненадежными.
Инженеры LinkedIn под руководством Джея Крепса, Джуна Рао и Ниха Ниркара создали Kafka как внутренний проект. Задачей было объединить все потоки данных LinkedIn в одну централизованную платформу, чтобы обрабатывать триллионы сообщений в день.
В 2011 году LinkedIn открыла исходный код Kafka, и проект перешел к компании Apache Software Foundation. Поэтому в названии Kafka появилось слово Apache. А название Kafka — отсылка к писателю Францу Кафке.
Архитектура Apache Kafka
Представьте себе почтовое отделение. Одни люди приходят, чтобы отправить письмо, а другие — чтобы получить. В самом отделении почты есть сотрудники, которые хранят письма и посылки. Отправления как-то промаркированы и отсортированы: есть хрупкие посылки или небольшие конверты, заказные письма и крупные коробки. Примерно так же устроена работа Kafka: платформа помогает отправлять сообщения с данными и доставляет их назначенному получателю.
Здесь подробнее рассмотрим, какие компоненты есть у Kafka, что делает каждый из них и на чем построена архитектура сервиса.
Основные компоненты
Брокеры — это серверы Kafka, или основные рабочие узлы. Они принимают данные, хранят их и отдают по запросу. Один брокер — это один сервер, обычно они объединяются в группы и образуют кластер.
Темы (топики) — это категории, по которым распределяются полученные данные. Продюсерам и консьюмерам так гораздо удобнее искать нужную информацию. Допустим, если вы используете Kafka, чтобы собирать сведения о покупателях интернет-магазина, у вас может быть несколько тем: «заказы», «клиенты», «склады». Этим категорирование не ограничивается, можно разграничить данные по любому признаку и объединить их в отдельную тему.
Партиции — способ разделения тем на части. Топик можно раздробить на партиции, чтобы быстрее получать нужную информацию. Принцип деления можно выбрать любой, к примеру, месяц совершения заказа или буква, с которой начинается фамилия покупателя.
Допустим, интернет-магазин разрастается, клиентов и заказов становится все больше. Тогда темы с «заказами» и «клиентами» можно разделить на партиции, и все они будут лежать на разных брокерах. В итоге появятся партиции, где заказы рассортированы по месяцам, а клиенты — по региону, чтобы было понятно, с какого склада товары приедут к ним быстрее.
А еще если тему не делить, она будет лежать на одном брокере, и это усложнит параллельную обработку данных. С разделением на партиции получение и отправка информации ускорятся, и передача данных не будет запаздывать.
Продюсеры — приложения, которые отправляют данные в Kafka. Они решают, в какую тему и партицию записать сообщение. Например, на сайте интернет-магазина клиент положил товар в корзину, заполнил данные о себе и оформил заказ. В этом случае веб-сайт магазина выступит продюсером, который отправил информацию о покупателе и его заказе.
Что может быть продюсером:
Сайты или приложения, которые направляют в Kafka информацию о действиях пользователя: сколько он пробыл на странице, что смотрел, нажимал, покупал.
Устройства умного дома, или IoT-устройства: колонки, телевизоры, термометры, лампочки, чайники, роботы-пылесосы. Они могут отправлять данные о температуре в комнате, влажности, уровне освещения, времени своей работы или истории общения с пользователем.
Системы логирования и мониторинга, которые передают информацию о внутренних процессах и инцидентах в приложении.
Микросервисы, которые отправляют в базы данных сведения о том, что завершился какой-то процесс. Например, человек зарегистрировался на сайте или оформил доставку.
Консьюмеры — приложения, которые читают данные из тем. Они следят за смещениями в партициях, чтобы знать, какие сообщения они уже обработали. Группа консьюмеров может читать одну тему, распределяя нагрузку между собой.
Примеры консьюмеров:
Системы аналитики, которые собирают информацию, чтобы потом на ее основе строить прогнозы, рекомендательные системы или проводить исследования. В аналитические системы могут попадать истории просмотров пользователей, самые популярные страницы, товары и много чего еще.
CRM-системы, которые рассылают пользователям уведомления: SMS, пуши, email-рассылки.
ML- и DL-алгоритмы. Они собирают из Kafka данные для обучения. Возможен вариант, где AI-моделям дают доступ к определенным топикам, например, с заказами каждого пользователя. А модели используют эти данные, чтобы отвечать клиентам в чат-боте: когда приедет заказ, на какой стадии сбора он находится, что в него включено, сколько стоит.
Микросервисы, которые срабатывают после определенных событий (триггеров) и запускают другие процессы. К примеру, после того, как человек зарегистрировался на платформе, сработает триггер — добавление в базу данных нового пользователя. Это послужит сигналом, что микросервис должен отправить человеку приветственный email.
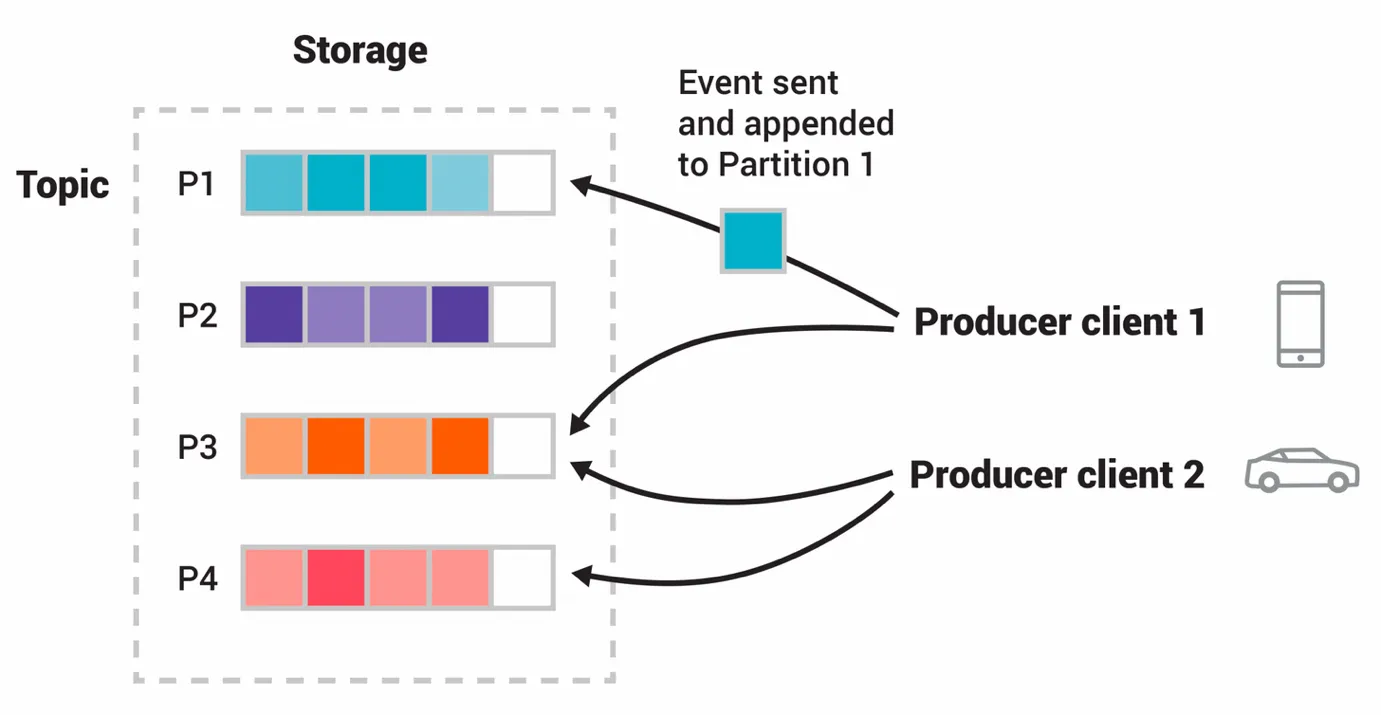 В этом примере два разных продюсера — телефон и авто — записывают данные в одну из четырех партиций одного топика. Продюсеры отправляют информацию в партиции независимо друг от друга, могут доставлять данные в одно и то же место. Источник: kafka.apache.org.
В этом примере два разных продюсера — телефон и авто — записывают данные в одну из четырех партиций одного топика. Продюсеры отправляют информацию в партиции независимо друг от друга, могут доставлять данные в одно и то же место. Источник: kafka.apache.org.Дистрибутивная архитектура
Дистрибутивная архитектура Kafka — принцип, согласно которому ни одна деталь не является уникальной или незаменимой. Если какой-то компонент выйдет из строя, его функции подхватят другие элементы. В итоге все будет работать стабильно, передача сообщений не прервется.
Предлагаем детальнее рассмотреть, за счет чего это возможно:
Партиции. Каждая тема разделена на партиции, а они, в свою очередь, распределены по разным брокерам в кластере. Если откажет один брокер, вы потеряете доступ только к тем партициям, лидером которых он был. Все остальные данные это не затронет, и доступ к ним останется.
Репликация. У каждой партиции есть несколько точных копий, или реплик. Одна реплика главная, и она по умолчанию обрабатывает все запросы. Остальные — последователи, они непрерывно копируют данные, которые поступают на главную партицию. Если с ней что-то произойдет, например, упадет сервер, на котором она находится, система автоматически выберет нового лидера среди оставшихся реплик. Для согласованности данных лидером станет наиболее актуальная реплика (in-sync replica). Это занимает несколько секунд, и зачастую этот сбой незаметен.
Отсутствие привязки к одному брокеру. У каждой партиции — свой брокер, который является для нее лидером. Получается, что нет какого-то единого брокера, к которому направляются все сообщения. А еще это делает масштабирование удобнее: если нужно увеличить емкость хранилища или пропускную способность, можно прямо во время работы добавить новый брокер, и внутри кластера перераспределятся лидеры для каждой партиции.
Принципы работы Apache Kafka
Механизмы, о которых расскажем в этом разделе, объясняют, как Kafka удается стабильно и эффективно работать даже при больших нагрузках.
Принцип publish-subscribe
Kafka работает по принципу pub-sub. В концепции pub-sub взаимодействующие сервисы называются издателями и подписчиками. Если вообразить себе газетный киоск, то издатели приносят свежие выпуски, а читатели подписываются на интересное и читают только те, что им нужно.
Издатели не знают в лицо каждого своего читателя, а подписчики читают только издания, которые им интересны: кто-то про рыбалку, кто-то про спорт, а кто-то про моду.
Теперь приземлим пример с киоском на работу самого Kafka:
Продюсеры — это издатели, отправители. Они направляют сообщения в определенные темы, не зная, кто и когда их прочитает.
Консьюмеры — читатели «издания». Они подписываются на нужные темы и читают сообщения оттуда. Одному микросервису нужны контактные данные пользователей, системе прогнозирования спроса — сведения о просмотрах товаров и покупках, сервису прогноза погоды — данные со спутников. На эти топики консьюмеры и подписаны, а что не надо — не читают.
Брокеры — сам киоск, где хранятся все газеты, то есть сообщения с данными.
Принцип publish-subscribe позволяет разделить продюсеров и консьюмеров — они общаются не напрямую, а через посредника в виде брокера. Издатели и читатели не знают о существовании друг друга, но все равно получают друг от друга сообщения. Это позволяет легче масштабироваться: количество издателей и подписчиков можно легко изменить, и это не повлияет на обмен информацией.
Офсеты и управление состоянием
Офсет — это порядковый номер сообщения внутри партиции. Офсет можно сравнить с книжной закладкой: когда вы что-то читаете и прерываетесь, то оставляете закладку, чтобы позже вернуться к нужной странице. Так же делают и консьюмеры:
Каждый запоминает, на каком месте в партиции он остановился. Консьюмер может делать это автоматически — коммитить свою позицию в служебную тему __consumer_offsets. А еще можно настроить офсеты вручную, например, коммитить их только после того, как сообщение будет успешно обработано.
При перезапуске консьюмер продолжает чтение с места, где прервался в прошлый раз.
Офсет пригодится, если вдруг основной сервис — служба доставки, интернет-магазин, приложение для записи на прием — упало. Когда его перезапустят, консьюмер, который читал информацию в партиции из темы «клиенты», вернется в место, где он остановился. А после заберет оттуда нужные данные о человеке, который хотел что-то купить или оформить доставку.
Масштабированное хранение данных
Kafka не удаляет сообщения сразу после прочтения. Вместо этого он хранит их какое-то время или до достижения определенного лимита. Это похоже на камеру хранения на вокзале: багаж будет на сохранении, пока владелец его не заберет или не закончится срок хранения.
Благодаря такому подходу новый консьюмер может подключиться к партиции и прочитать сообщения за последние несколько дней, недель или даже лет. Например, если вы запустите систему аналитики, она проанализирует все заказы за указанный период, а не только те, что поступили после запуска системы.
Преимущества использования Apache Kafka
Apache Kafka — мощный инструмент, который позволяет обмениваться сообщениями и строить надежные, гибко масштабируемые системы обработки данных. И у Kafka есть много плюсов, которые позволяют этого добиться — поговорим о них подробнее.
Высокая пропускная способность
Kafka обрабатывает миллионы сообщений в секунду с минимальными задержками. Она достигает такой скорости за счет последовательной записи на диск и эффективной компрессии данных. Это позволяет строить системы в реальном времени для аналитики, мониторинга и уведомлений.
Надежность и отказоустойчивость
Данные в Kafka не теряются при сбоях, так как каждое сообщение реплицируется на несколько серверов и сохраняется на диске. Если один сервер выйдет из строя, его обязанности мгновенно перейдут к другому. Такая замена занимает несколько секунд и часто незаметна пользователям.
Легкая масштабируемость
Чтобы увеличить пропускную способность, достаточно просто добавить новых серверов в кластер.
Сохранение истории сообщений
Kafka хранит историю от пары часов до нескольких лет. Это дает много возможностей: заново обращаться к прошлым данным, анализировать исторические тренды, проводить более глубокую аналитику, а еще восстанавливать сервисы после крупных сбоев. Еще это удобно, когда нужно подключить какой-нибудь новый сервис, к примеру CRM или базу данных. Они смогут обратиться ко всей истории сообщений, а не только к информации, которая появилась после их запуска.
Интеграция с другими сервисами
Kafka соединяется с популярными базами данных, системами аналитики и облачными сервисами через коннекторы с помощью Kafka Connect. Готовые коннекторы есть для PostgreSQL, Elasticsearch, AWS S3 и сотен других систем.
Применение Apache Kafka
Kafka в реальном времени обрабатывает огромные потоки данных, и поэтому платформа стала популярна у многих крупных компаний и в разных областях. Здесь расскажем, где и для чего используют Apache Kafka.
Потоковая аналитика и мониторинг
Например, в агрегаторах такси Kafka применяется, чтобы рассчитывать динамическое ценообразование. Для этого нужно передать и проанализировать сообщения о доступных водителях, спросе на авто, погоде, пробках. Сначала продюсеры отправляют эту информацию в Kafka, консьюмеры — например, системы аналитики, — берут эти данные и на их основе делают расчет.
Сбор телеметрии и показаний датчиков
В умных домах и на производстве датчики отправляют показания температуры, влажности, расхода энергии. Kafka принимает потоки данных и фильтрует аномалии, а системы контроля эти сведения забирают. Например, если датчик на заводской линии показывает перегрев, Kafka мгновенно передает сигнал системе безопасности, и та останавливает конвейер.
Обработка финансовых операций
Банки и платежные системы используют Kafka, чтобы отслеживать транзакции. К примеру, каждая операция по карте проходит через Kafka, откуда попадает в системы фрод-мониторинга. А они анализируют характер транзакции — ее время, геолокацию, MCC-код, размер оплаты — и определяют, мошенническая она или нет. Так подозрительные операции блокируют еще до того, как деньги спишутся с карты.
Синхронизация между микросервисами
Когда пользователь меняет email в профиле, приложение для аутентификации публикует событие в Kafka, а все заинтересованные сервисы (рассылки, уведомления, аналитика) получают обновленные данные без прямых вызовов API друг к другу.
Рекомендательные системы
С помощью Kafka стриминговые платформы анализируют поведение пользователей: что они смотрят, как долго задерживаются на эпизоде сериала, какие жанры предпочитают, что добавляют в избранное. Эти данные сразу попадают в алгоритмы рекомендаций, которые подбирают индивидуальный контент для каждого.
Здравоохранение
Есть возможность наблюдать за пациентами, которые лечатся в стационаре, прогнозировать изменения в их состоянии, чтобы оперативно реагировать, если наступит экстренный случай.
Конкуренты и альтернативы
Один из главных конкурентов Apache Kafka — RabbitMQ. Это классический брокер сообщений, который работает с очередями. Он хорошо подходит, когда нужно гарантированно доставить каждое сообщение конкретному получателю.
Kafka же создан для потоковой передачи больших объемов данных многим подписчикам одновременно. Если RabbitMQ похож на курьерскую службу, которая доставляет отдельные посылки, то Kafka — это лента новостей, которую читают тысячи людей.
Когда лучше выбрать Kafka:
нужно обрабатывать потоки данных от тысяч источников: показатели датчиков, клики пользователей, логи, данные со спутников;
нужно хранить данные неделю, месяц или год, иметь возможность их перечитать;
в высоконагруженных сервисах, когда нагрузка превышает сто тысяч сообщений в секунду;
данные нужны сразу нескольким системам: аналитики, мониторинга и хранения одновременно.
Если же ваша задача — гарантированно доставить каждое сообщение конкретному получателю, и нагрузка в самом сервисе невелика, RabbitMQ может оказаться проще в настройке и использовании.