Машинное обучение: что такое Machine Learning (ML), виды, модели, методы
Машинное обучение уже давно перестало быть технологией, о которой говорят только ученые и разработчики. Сегодня алгоритмы ML помогают рекомендовать фильмы и музыку, распознавать речь, искать мошеннические операции, прогнозировать спрос на товары и даже находить заболевания на ранних стадиях. Почти каждый человек ежедневно взаимодействует с сервисами на основе моделей машинного обучения, даже если не задумывается об этом.
Но интерес к ML-технологиям только усиливается. Компании внедряют их, чтобы автоматизировать рутинные процессы, быстрее анализировать большие объемы данных и принимать решения на основе фактов, а не предположений. А благодаря развитию облачных технологий обучать модели становится проще: для этого уже не нужна собственная дорогостоящая инфраструктура.
В статье разберем, что такое машинное обучение, какие виды и модели ML существуют, как работают и где применяются на практике.


Что такое машинное обучение
Машинное обучение (Machine Learning, ML) — это раздел искусственного интеллекта. Смысл в том, что система не получает жестко прописанные правила, а учится на примерах. Ей дают данные — дальше она уже сама ищет в них закономерности и делает выводы.
Простой пример — интернет-магазин. Нужно понять, какие товары человеку могут подойти. Можно попробовать описать это правилами: возраст, покупки, время захода, сезон и не только. Но таких правил становится слишком много, и поддерживать их сложно. Поэтому обычно идут другим путем — берут реальные данные о поведении пользователей и уже на них обучают модель.
Дальше важный момент. В обычной разработке логика заранее прописана. В машинном обучении ее нет изначально — она формируется в процессе обучения. Поэтому результат сильно зависит от данных и от того, насколько удачно выбран алгоритм.
Если упростить, то в любой ML-системе есть три базовые вещи:
данные, с которыми работает модель;
алгоритм обучения;
модель, которая выдает прогноз.
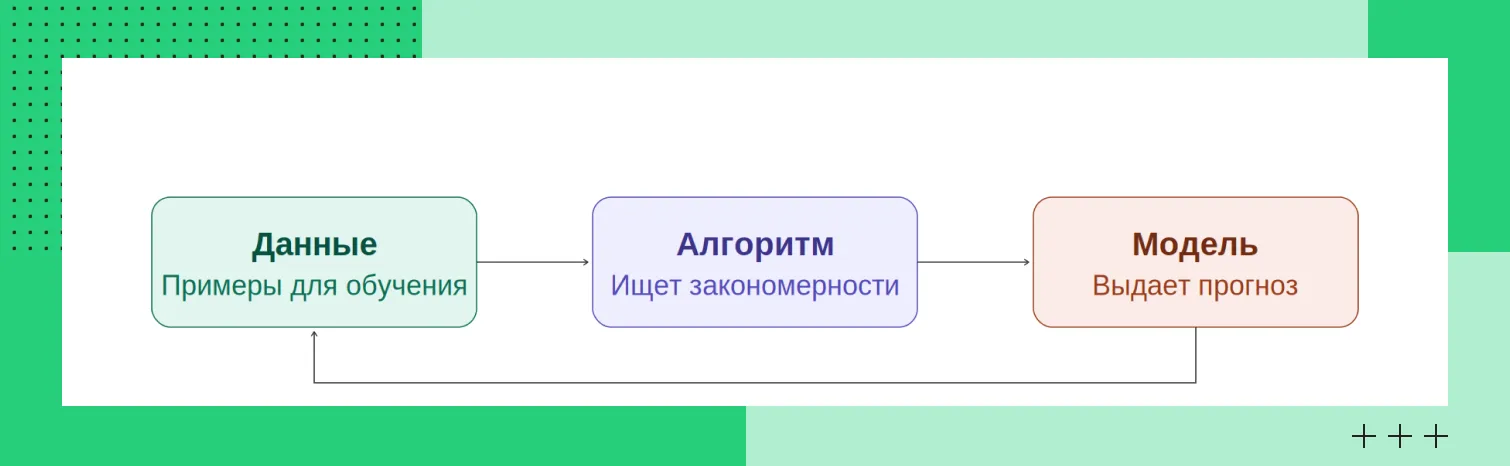 Новые данные переобучают модель
Новые данные переобучают модельИ еще один момент, который часто недооценивают. Все это не работает «раз и навсегда». Данные меняются, поведение пользователей меняется тоже. Из-за этого модели приходится периодически переобучать — иначе качество начинает падать.

Сегодня машинное обучение используют практически везде:
банки — поиск подозрительных операций;
медицина — помощь с диагностикой;
производство — прогноз поломок оборудования;
логистика — маршрутизация;
сервисы — подбор рекомендаций;
маркетинг — работа с аудиторией.
Если совсем просто, машинное обучение нужно для одного — чтобы разбирать большие объемы данных и находить в них закономерности, которые вручную уже сложно заметить.
Виды машинного обучения
Есть разные подходы к обучению моделей. Разница в том, какие данные доступны алгоритму и как он получает информацию. А какой из подходов выбрать, зависит от самой задачи, объема данных и результата, который нужно получить.
 Чем больше и разнообразнее данные, тем точнее модель
Чем больше и разнообразнее данные, тем точнее модель Обучение с учителем (Supervised Learning)
Обучение с учителем — самый распространенный подход в машинном обучении. Он предполагает использование размеченных данных с заранее указанными правильными ответами для каждого примера.
Допустим, требуется научить модель определять, является ли электронное письмо спамом. Для этого ей показывают множество сообщений, каждое из которых уже помечено как «спам» или «не спам». Анализируя такие примеры, алгоритм постепенно выявляет признаки, по которым можно отличить одну категорию от другой. После завершения обучения модель начинает работать с новыми письмами и самостоятельно определяет их категорию.
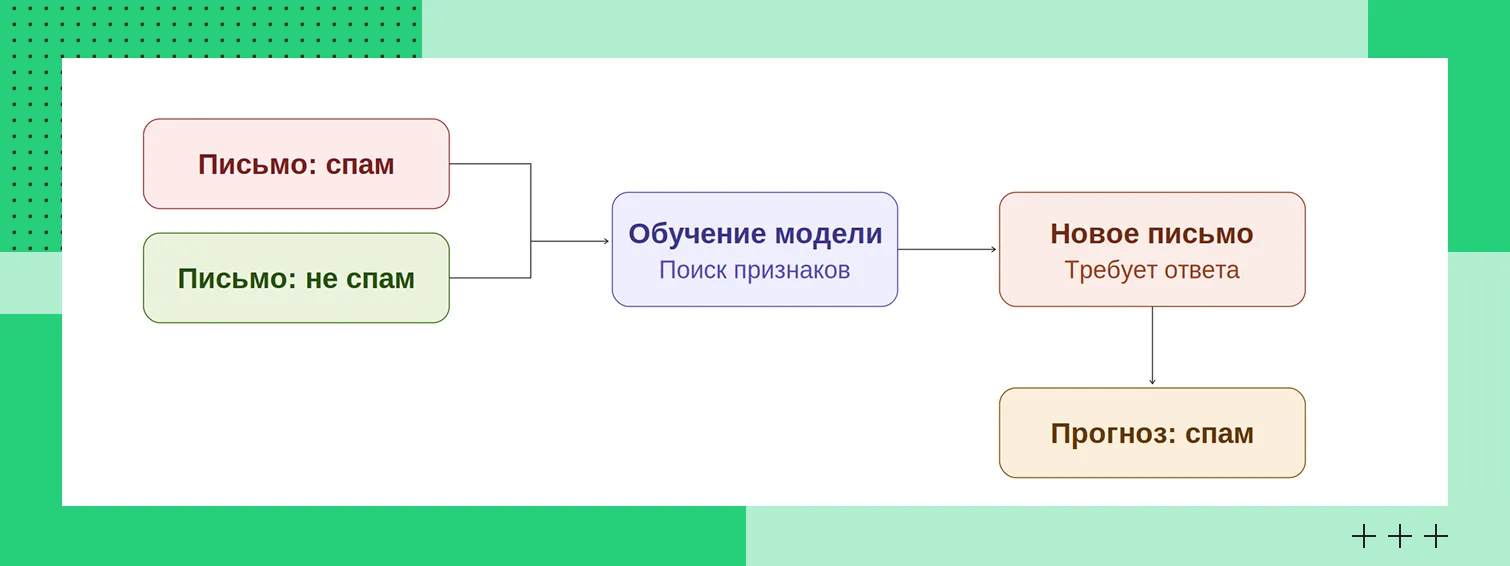 Пример фильтрации спама
Пример фильтрации спамаОбучение с учителем применяется для двух типов задач: классификация и регрессия. Классификация используется, когда нужно выбрать одну категорию из нескольких. Например:
распознавание мошеннических операций;
определение тональности отзывов;
диагностика заболеваний;
выявление спама.
Регрессия используется, если нужно предсказать числовое значение. Например, а таких задачах:
определение стоимости недвижимости;
выявление объема продаж;
потребление электроэнергии;
время доставки заказа.
Главное преимущество такого подхода — точность даже при наличии обширного объема размеченных данных. Но их подготовка часто становится самым сложных и длительным этапом проекта.

Обучение без учителя (Unsupervised Learning)
При выборе обучения без учителя алгоритм получает данные без готовых ответов. Ему неизвестно, какие объекты похожи друг на друга и какие закономерности нужно найти. При этом модель сама исследует информацию и ищет скрытые структуры.
Распространенная задача такого подхода — кластеризация. Алгоритм объединяет похожие объекты в группы по их характеристикам.
Например, интернет-магазин может автоматически разделить покупателей на сегменты в зависимости от поведения: те, кто регулярно совершает дорогие покупки, приходит только во время акций, давно не проявлял активности и так далее. После этого уже не трудно подготовить отдельные предложения для каждой группы клиентов.
Еще одно популярное направление — уменьшение размерности. Современные наборы данных могут содержать сотни и даже тысячи признаков. Не все из них одинаково полезны. Специальные алгоритмы позволяют сократить количество признаков без существенной потери информации. Это ускоряет обучение моделей и помогает лучше визуализировать данные.
Обучение с частичным участием учителя (Semi-supervised Learning)
В реальности полностью размеченные данные встречаются далеко редко. И как с этими неидеальными данными проводить обучение?
В подобных случаях используют обучение с частичным участием учителя. Этот подход предполагает применение небольшого количества размеченных данных и большого объема неразмеченных.
Происходит это так: сначала модель обучается на примерах с ответами, а затем использует полученные знания для анализа остальных данных. Это повышает качество ее работы без необходимости размечать весь массив информации вручную.
Такой подход применяется:
при обработке медицинских изображений;
в распознавании речи;
при анализе текстов;
в системах компьютерного зрения.
Чем больше доступных данных удается использовать в процессе обучения, тем выше вероятность получить точную модель при меньших затратах на подготовку датасета.
Обучение с подкреплением (Reinforcement Learning)
В отличие от предыдущих подходов, здесь алгоритм не получает готовые правильные ответы. Вместо этого он взаимодействует с окружающей средой, выполняет действия и получает вознаграждение или штраф в зависимости от результата. То есть задача модели при таком обучении — научиться принимать такие решения, которые в долгосрочной перспективе принесут максимальную награду.
Этот принцип напоминает обучение человека через опыт. Если действие оказалось успешным, вероятность повторения возрастает. Если результат оказался неудачным, стратегия постепенно меняется.
Обучение с подкреплением используется там, где важна последовательность решений:
управление роботами;
автономный транспорт;
интеллектуальные игровые системы;
оптимизация логистики;
управление ресурсами в дата-центрах.
Глубинное обучение (Deep Learning)
Глубинное обучение считается отдельным направлением машинного обучения и основано на использовании многослойных нейронных сетей.
Если классические модели часто требуют ручного выбора признаков, то глубокие нейронные сети способны самостоятельно выделять важные характеристики прямо из исходных данных. Благодаря этому они особенно хорошо справляются со сложными задачами, где объем информации очень велик.
Deep Learning широко используется для обработки:
изображений;
текста;
аудио;
видео;
временных рядов.
Именно благодаря глубокому обучению появились современные голосовые помощники, системы автоматического перевода, генеративные модели, сервисы распознавания лиц и многие другие интеллектуальные приложения.
Однако обучение таких моделей требует серьезных вычислительных ресурсов. Обычно для этого используют графические процессоры (GPU), потому что на CPU такие задачи выполняются слишком медленно. Чем больше данных и сложнее модель, тем заметнее разница.
На практике для обучения DL-моделей часто используют облачные сервисы с поддержкой GPU. В облаке можно арендовать GPU и развернуть виртуальные машины, выделенные серверы или ML-среды с графическими ускорителями (B300, H100, V100, A40, A100). Это удобно, когда не хочется строить собственную инфраструктуру: можно получить нужные мощности под задачу обучения модели или инференса и наращивать их или сокращать, если нужно.
Модели машинного обучения
Одни алгоритмы ML подходят для прогнозирования числовых значений, другие — для классификации объектов, третьи способны находить сложные закономерности в больших массивах данных. Давайте рассмотрим их подробнее.
Линейная и логистическая регрессия
Несмотря на название, логистическая регрессия относится не к задачам прогнозирования числовых значений, а к классификации.
Линейная регрессия — одна из самых простых моделей машинного обучения. Она помогает предсказывать непрерывные значения на основе данных. Например, с ее помощью можно оценить стоимость квартиры, спрогнозировать объем продаж или рассчитать потребление электроэнергии.
Модель строит зависимость между входными параметрами и целевой переменной, поэтому хорошо работает там, где между ними существует относительно простая связь.
Логистическая регрессия используется для задач классификации. Она определяет вероятность того, что объект относится к определенному классу. Например, с ее помощью можно предсказать, одобрит ли банк кредит, является ли письмо спамом или относится ли финансовая операция к мошенническим.
Главные преимущества обеих моделей — скорость обучения и интерпретируемость. Поэтому они часто становятся отправной точкой при разработке ML-решений.
Деревья решений и случайный лес (Decision Trees and Random Forests)
Дерево решений — это модель, которая принимает решение, шаг за шагом отвечая на вопросы о характеристиках объекта. Она похожа на дерево с ветвями, где каждый узел отвечает за проверку конкретного условия. Отсюда и название.
Деревья решений легко интерпретировать, однако отдельные модели могут слишком точно подстраиваться под обучающие данные и терять результативность на новых примерах.
А чтобы повысить качество прогнозов, используют случайный лес — группу из множества деревьев решений. Каждое из них строит собственный прогноз, а итоговый результат определяется на основе голосования или усреднения.

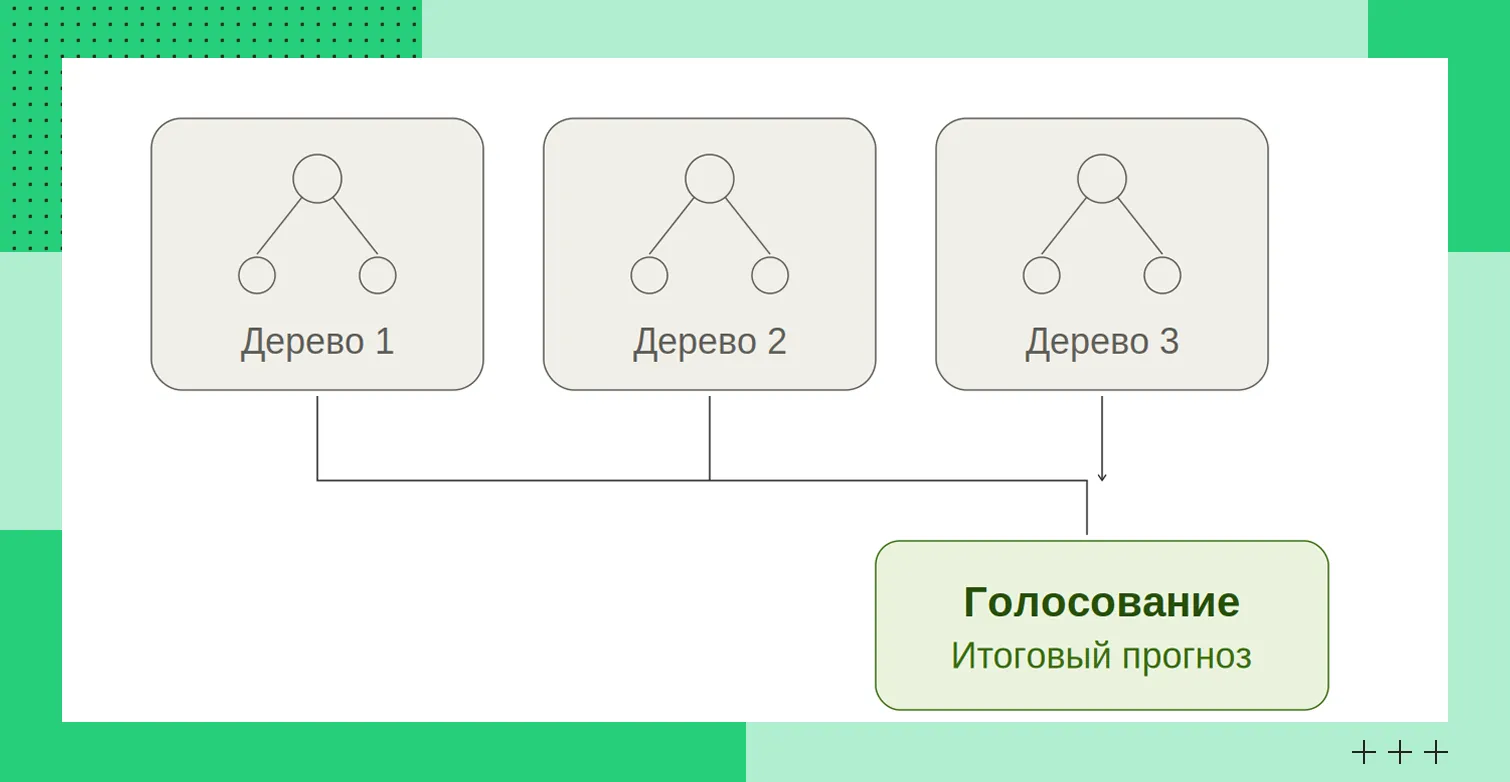 Случайный лес устойчивее к переобучению, чем одно дерево
Случайный лес устойчивее к переобучению, чем одно дерево Такой подход дает более высокую точность и устойчивость к переобучению, поэтому случайный лес применяется в задачах классификации, прогнозирования и анализа рисков.
Метод опорных векторов (SVM)
Метод опорных векторов (Support Vector Machine, SVM) предназначен в первую очередь для задач классификации. Задумка заключается в том, чтобы найти границу, которая лучше всего разделяет объекты классов. Чем больше расстояние между этой границей и ближайшими объектами, тем надежнее считается модель.
SVM показывает себя при работе с небольшими и средними наборами данных, в случаях если признаки объектов обладают сложными зависимостями. Алгоритм используют для распознавания изображений, анализа текстов, биоинформатики и других задач, где важно добиться точности классификации.
Нейронные сети
Нейронные сети состоят из взаимосвязанных вычислительных элементов — искусственных нейронов, организованных слоями. Во время обучения сеть постепенно настраивает внутренние параметры, чтобы находить сложные закономерности.
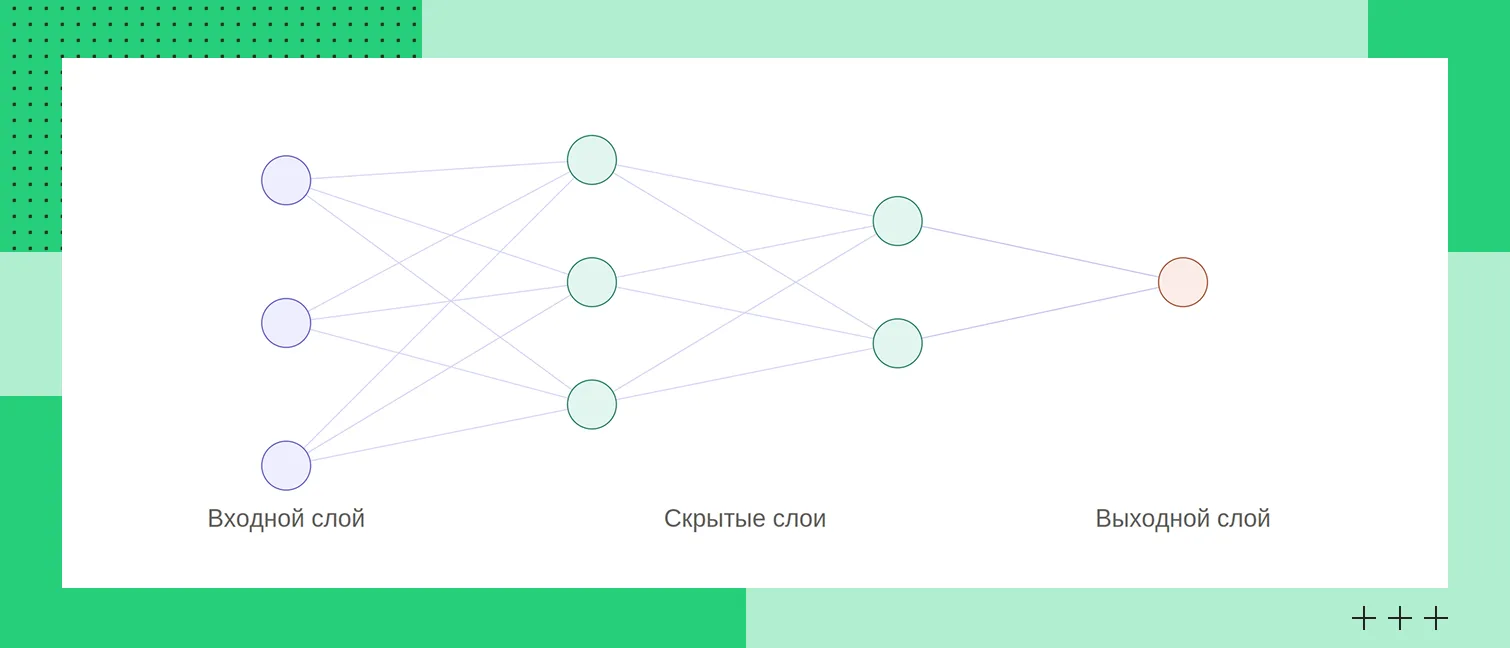 Искусственные нейроны, расположенные слоями
Искусственные нейроны, расположенные слоямиСовременные нейронные сети способны решать задачи, с которыми классические алгоритмы справляются хуже. Они используются для распознавания речи и изображений, машинного перевода, обработки естественного языка, создания рекомендательных систем и генерации контента.
Нейронные сети лежат в основе большинства генеративных моделей и интеллектуальных помощников. Однако для их обучения требуются большие объемы данных и вычислительные ресурсы.
Методы и подходы в машинном обучении
Создать модель — только часть работы. Не менее важно оценить качество прогнозов, подобрать подходящий алгоритм и правильно настроить параметры обучения.
Оценка моделей
Чтобы понять, хорошо ли работает модель, используют особые метрики качества. Оценивают:
Accuracy (точность) — долю правильных ответов;
Precision (точность верных предсказаний) — частоту ошибок при отнесении объекта к тому или иному классу;
Recall (полнота) — долю обнаруженных релевантных объектов;
F1-меру — показатель, который объединяет precision и recall, помогая сравнивать модели при несбалансированности данных.
 Precision и recall особенно важны при несбалансированных данных
Precision и recall особенно важны при несбалансированных данных Для задач регрессии часто используют среднюю ошибку (MAE), среднеквадратичную ошибку (MSE) и корень из нее (RMSE). Эти метрики показывают, насколько прогнозы расходятся с реальными значениями.
Перед внедрением модель также проверяют на тестовой выборке — данных, которые не использовались во время обучения. Это помогает спрогнозировать, насколько результативно алгоритм будет работать.
Выбор и настройка моделей
Универсальной модели, которая одинаково подходит для любых задач, нет. Выбор зависит от структуры данных, доступных вычислительных ресурсов, требований к скорости работы и точности прогнозов.
Например, если важно объяснить, почему модель приняла то или иное решение, часто выбирают линейную регрессию или деревья решений. Когда на первом месте стоит качество прогнозов, а объем данных большой, предпочтение отдают ансамблевым алгоритмам или нейронным сетям.
После выбора модели начинается этап настройки гиперпараметров — параметров, которые определяют процесс обучения. От них напрямую зависит качество итоговой модели, поэтому разработчики подбирают их с помощью специальных методов поиска, например Grid Search или Random Search.
Оптимизация и обучение
Во время обучения алгоритм постепенно уменьшает количество ошибок, корректируя внутренние параметры модели. Для этого используются методы оптимизации, распространенные из которых — градиентный спуск и модификации.
Чтобы модель не только запомнила обучающие данные, а научилась делать точные прогнозы на новых примерах, применяют дополнительные методы оптимизации. Среди них — регуляризация, ранняя остановка обучения (Early Stopping), увеличение объема данных (Data Augmentation) и кросс-валидация.
После того как модель обучена, ее нужно не только протестировать, но и запустить в реальной среде — чтобы она могла обрабатывать новые данные в продакшене. Этот этап как раз и называется инференсом. На практике для него используют отдельные сервисы, которые позволяют разворачивать и запускать модели без сложной настройки инфраструктуры. Например, в Cloud.ru есть сервис Evolution ML Inference — он предназначен для запуска и масштабирования ML и LLM-моделей.
Примеры использования машинного обучения
Еще недавно машинное обучение применяли только редкие технологические компании. Сегодня ML используют организации всех отраслей — от финансового сектора до промышленности.
Примеры и кейсы
Машинное обучение уже давно вышло за рамки экспериментов и стало частью повседневных процессов в разных отраслях. Проще всего это понять на примерах — где и как компании используют ML на практике.
Онлайн-магазины, стриминговые сервисы и маркетплейсы используют машинное обучение, чтобы предлагать пользователям товары, фильмы, музыку или другой контент с учетом их интересов. Алгоритмы анализируют просмотры, покупки и поисковые запросы, благодаря чему рекомендации становятся персонализированными.
Банки, страховые компании и платежные сервисы применяют ML-модели для выявления подозрительных операций. Если система замечает нетипичное поведение — например, нестандартную сумму перевода или вход в аккаунт с нового устройства, — она может отправить операцию на дополнительную проверку или временно заблокировать ее.
В здравоохранении машинное обучение помогает анализировать результаты исследований, распознавать патологии на медицинских снимках и оценивать риски развития заболеваний. Здесь технологии не заменяют врача, но помогают быстрее обработать информацию и направлять внимание врача.
На производстве алгоритмы используются для прогнозирования отказов оборудования и контроля качества продукции. Анализируя данные с датчиков, модель может заранее определить признаки неисправности и предупредить о необходимости технического обслуживания. Это помогает заранее выявлять неисправности и сокращать расходы на ремонт.
Транспортные и логистические компании применяют машинное обучение для оптимизации маршрутов, прогнозирования сроков доставки и управления цепочками поставок. Алгоритмы учитывают разные факторы — от дорожной ситуации до погодных условий — и помогают распределять ресурсы.
ML помогает сегментировать аудиторию, прогнозировать спрос, оценивать вероятность ухода клиентов и подбирать маркетинговые предложения. Так компании персонализируют сервис и улучшают результаты рекламных кампаний.
С каждым годом сценариев использования машинного обучения становится больше. По мере развития вычислительных мощностей и появления новых инструментов ML становится доступнее не только корпорациям, но и компаниям среднего и малого размера.
Что стоит запомнить
Машинное обучение давно перестало быть чем-то узкоспециальным — сейчас его применяют в бизнесе, науке и самых обычных цифровых сервисах. Оно помогает анализировать большие объемы данных, находить закономерности, строить прогнозы и автоматизировать процессы.
Выбор подхода к машинному обучению и подходящей модели зависит от конкретной задачи, данных и требований к результату. А понимание его принципов помогает оценить возможности технологии и подобрать инструменты для реализации даже очень амбициозных проектов.