Машинное обучение с учителем: что это такое, методы, примеры, алгоритмы
Представьте, что решаете задачи на уроке математики. Вы можете делать это тремя способами: обратиться за помощью к репетитору, самостоятельно искать закономерности и получать ответы, а также действовать методом проб и ошибок — предлагать решения наугад, получая пятерки или неуды в зависимости от результатов. Также и с AI-моделями— их можно обучать с учителем, без учителя и с подкреплением.
В этой статье подробнее поговорим про машинное обучение (machine learning) моделей с учителем: разберемся, что это такое и как работает, какие есть алгоритмы такого обучения и как они применяются на практике.


Введение
Обучение с учителем — один из самых распространенных методов машинного обучения. Причиной тому преимущества, в числе которых:
Высокая точность прогнозирования. Обучение с учителем позволяет получить более точные прогнозы в сравнении с обучением без учителя, где требуется большое количество неразмеченных данных.
Широкий спектр применения. Обученные с учителем модели могут решать самые разные практические задачи — от прогнозирования продаж и диагностики заболеваний до фильтрации спама и распознавания образов.
Высокая степень интерпретируемости. Многие модели, особенно древовидные или линейные, позволяют понять, какие именно признаки и как повлияли на итоговое решение, что критически важно в таких областях, как медицина или финансы.
Контроль процесса обучения. Наличие размеченных данных позволяет оценивать прогресс модели и своевременно вносить целенаправленные корректировки для улучшения.
Оценка производительности алгоритма. Наличие правильных ответов дает возможность оценить эффективность модели с помощью точных метрик.
Инкрементальное обучение. Некоторые модели могут доучиваться на новых данных, сохраняя при этом знания, полученные из предыдущих данных.
Основы машинного обучения с учителем
Машинное обучение с учителем — это подход, при котором модель обучается на размеченных данных для решения задач классификации и регрессии. В основе этого подхода лежит использование датасета с готовыми примерами и ответами для обучения прогнозной модели.
Что такое обучение с учителем
Если в случае с задачками по математике учитель демонстрирует ученику типовые задачи, способы их решения и ответы, то при обучении моделей посредник не требуется. Нужны только размеченные данные (датасет) и выбранный алгоритм обучения.

Машинное обучение с учителем (supervised learning) — метод, при котором модель обучается на заранее размеченном наборе данных (датасете). То есть использует готовые примеры, включающие как сами вопросы, так и ответы, которые нужно давать.
 Процесс обучения с учителем: от размеченных данных к прогнозированию на новых примерах
Процесс обучения с учителем: от размеченных данных к прогнозированию на новых примерах
Признаки, отклики и обучающая выборка
Концепции и термины, которые используются при обучении с учителем — это признаки, отклики и обучающая выборка:
Машинное обучение работает с объектами (objects) — отдельными сущностями (например, веб-страницами, посетителями сайта или товарами), которые модель анализирует, чтобы найти скрытые закономерности и сделать точный прогноз. А характеристиками объектов выступают признаки (features).
Отклик, или целевая переменная (target) — это тот ответ, который модель ищет в процессе обучения.
А набор данных, на котором AI-модель учится находить взаимосвязи между признаками и откликом, — это датасет. Чаще всего его делят на обучающую выборку (training set) и тестовую выборку (test set), где первая нужна для непосредственного обучения модели, а тестовая — для оценки качества результатов.
Чтобы понять, как эти сущности взаимодействуют между собой, представьте, что модель учится делать предсказания о посетителях сайта. Предположим, что одним из объектов в обучающей выборке, выступает пользователь с такими признаками:
возраст = 28
город = Москва
источник_перехода = соцсети
количество_посещений_сайта = 5
На основе этих признаков ML-модель и будет давать отклик, то есть предполагать, с какой вероятностью пользователь с заданными признаками может совершить покупку на сайте или другое целевое действие.
Типы задач обучения с учителем
Обучение с учителем позволяет решать два типа задач: регрессию и классификацию.
 Типы задач обучения
Типы задач обучения Выбор между ними зависит от того, какой результат нужно получить — численное значение или категорию.
Задачи регрессии
В задачах регрессии модель предсказывает численное значение — непрерывную числовую величину. Это может быть любое число в заданном диапазоне.
Как это работает:
При оценке домов в недвижимости: модель оценивает признаки домов (их площадь, расположение, количество комнат и прочие) и делает прогноз стоимости в виде конкретной цены.
При составлении прогноза погоды: анализируются характеристики текущего дня — например, температура, влажность, давление — и предсказывается погода на завтра.
Задачи классификации
В задачах классификации модель относит объект к одной из категорий — классов. Ответ здесь — это метка из конечного набора вариантов.
Как это работает:
В спам-фильтрах: модель оценивает содержимое электронного письма и классифицирует его как «спам» или «не спам».
При постановке диагноза: проводится анализ симптомов пациента, на основе которого он определяется в категорию «здоров» или «болен».
Алгоритмы обучения с учителем
Выбор алгоритма обучения — ключевой этап в процессе построения AI-модели. Все они подходят для разных типов данных и задач. Вот некоторые из популярных и результативных методов.
Линейная и логистическая регрессия
Эти два алгоритма — основа основ. И несмотря на похожие названия, они решают очень разные задачи.
Линейная регрессия предсказывает количественные значения. Она находит прямые зависимости между параметрами (например, площадь квартиры) и тем, что нужно предсказать (например, цену квартиры).
По сути, линейная регрессия проводит условную прямую линию через точки данных так, чтобы эта линия отражала общую закономерность. Если параметров несколько, она строит многомерную плоскость, но принцип остается тем же — найти математическое правило, связывающее исходные данные с искомым значением.
Логистическая регрессия решает задачи бинарной классификации. В отличие от линейной регрессии, которая предсказывает число (например, цену), логистическая оценивает вероятность. Например, «насколько вероятно, что это письмо — спам?» или «вернет ли клиент кредит?».
Деревья решений (Decision Trees) и случайный лес (Random Forest)
Decision Trees (деревья решений) — это алгоритм, при использовании которого модель имитирует процесс принятия решений человеком, последовательно задавая вопросы о признаках объекта. Например, чтобы принять решение о выдаче кредита, могут использоваться вопросы:
сперва: «Возраст заемщика больше 18?»;
затем: «Стаж работы больше 5 лет?»;
и далее — пока не будет получен итоговый ответ (одобрить или отклонить заявку).
Такой алгоритм позволяет наглядно интерпретировать результат — и это плюс подхода. Но есть и минус: «дерево» склонно к переобучению, то есть «запоминает» тренировочные данные вместо выявления общих закономерностей.
И тут на помощь приходит Random Forest (случайный лес) — алгоритм машинного обучения, суть которого состоит в использовании ансамбля решающих деревьев. Это позволяет ему сочетать простоту и наглядность деревьев решений с точностью и устойчивостью.
Метод опорных векторов (SVM)
Метод опорных векторов (SVM, support vector machine) — это алгоритм для задач классификации и регрессии. Он ищет границу между двумя классами объектов: упрощенно говоря, может отличить кошек от собак на фото или спам от писем.
Важно отметить, что SVM не просто рисует линию между классами, а создает зазор (margin), чтобы даже сложные случаи классифицировались правильно.
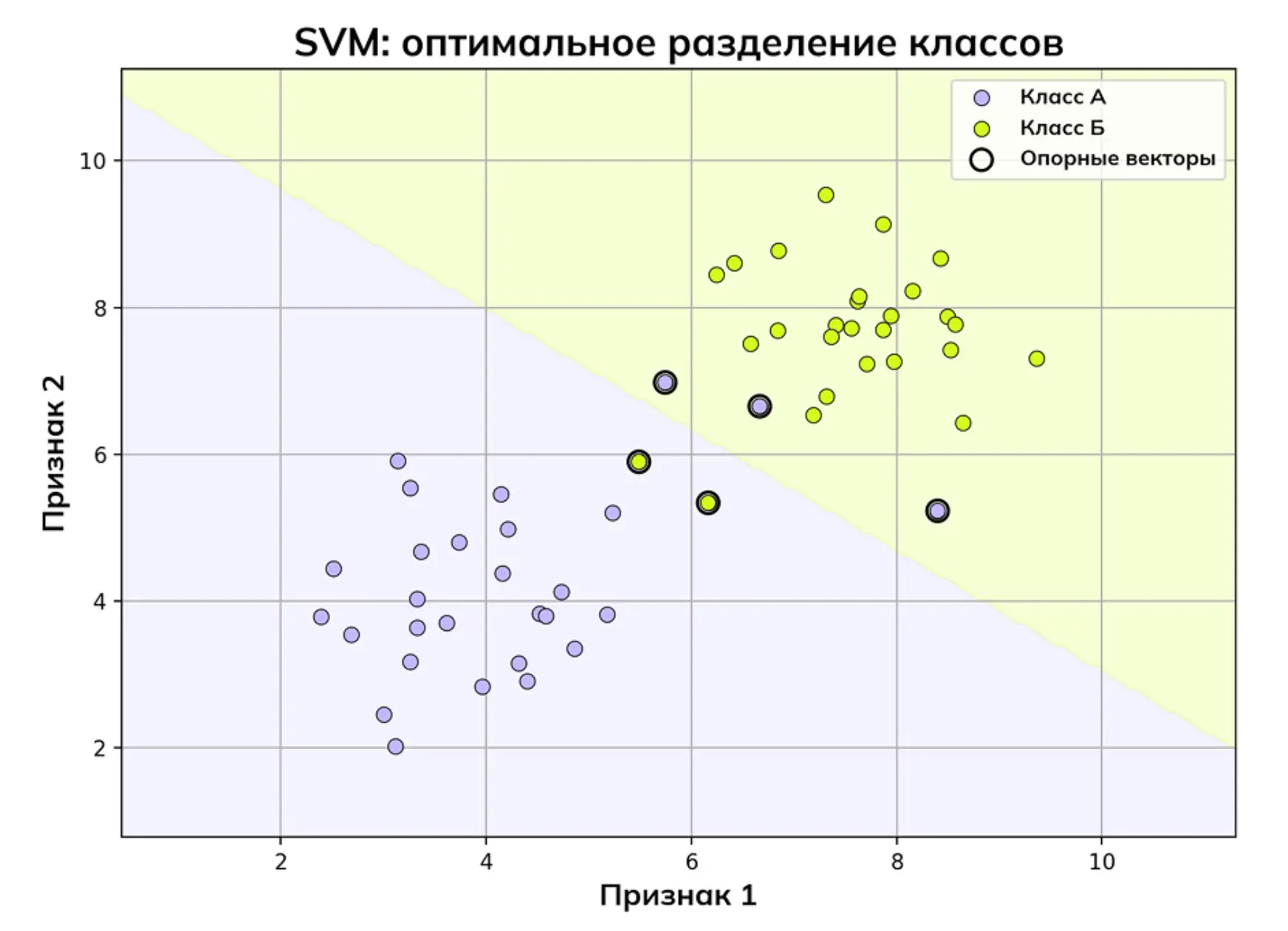 Алгоритм работы метода опорных векторов
Алгоритм работы метода опорных векторовk-ближайших соседей (K-NN)
K-NN (K-Nearest Neighbors) — алгоритм, который работает по принципу «скажи мне, кто твой сосед, и я скажу, кто ты». Идея метода заключается в том, чтобы присвоить новому объекту тот же класс (для классификации) или значение (для регрессии), что и у большинства его ближайших соседей из обучающей выборки.
Выбор алгоритма и оценка модели
Как выбрать правильный алгоритм
При выборе типа модели стоит учесть, что:
В первую очередь алгоритм должен решать практическую задачу. Если бизнес-цель или исследовательский вопрос допускают некоторую погрешность, то осознанный выбор быстрого, но не такого точного алгоритма может быть верным решением.
Время, которое уходит на обучение модели — это важный практический критерий. Часто сложные и точные алгоритмы требуют большого количества времени для обучения, особенно на больших данных. Поэтому при выборе алгоритма нужно задаться вопросом: «Сколько времени можно потратить на обучение?».
Например, если задача модели заключается в анализе транзакций банковских карт с целью выявления мошеннических действий, то алгоритмам SVM и K-NN стоит предпочесть логистическую регрессию или Decision Trees. С их помощью модель будет обучаться быстрее, а это важно при работе с постоянно меняющимися схемами мошенничества.
Важно визуализировать данные или использовать статистические тесты, чтобы оценить их сложность. Если видите нелинейную зависимость, сразу смотрите в сторону более сложных алгоритмов.
Лучше начинать обучение с алгоритмов с малым количеством параметров. А увеличивать сложность стоит тогда, когда точность простых моделей уже не устраивает.
При работе с данными, у которых много признаков (например, это могут быть гены или тексты), не все алгоритмы справятся. Для них подходит метод опорных векторов (SVM) или специальные алгоритмы, разработанные для таких данных.
Метрики оценки качества модели
После обучения модели нужно оценить ее эффективность. Правильно выбранные метрики позволяют понять, насколько модель готова к работе с данными, и сравнить результаты алгоритмов. Вот базовые методы оценки точности для моделей, обученных с учителем.
В задачах классификации метрики основываются на анализе ошибок модели, которые можно представить в виде матрицы ошибок (confusion matrix). Она делит прогнозы модели на четыре категории:
True Positive (TP)— модель верно предсказала положительный класс (например, верно определила спам). | True Negative (TN) — модель верно предсказала отрицательный класс (верно определила не спам). |
False Positive (FP) — модель ошиблась, предсказав положительный класс (определила не спам как спам). | False Negative (FN) — модель ошиблась, предсказав отрицательный класс (пропустила спам). |
На основе этих значений рассчитываются метрики:
Точность (Accuracy) — простейшая метрика, которая отвечает на вопрос: «Какой процент предсказаний модель сделала правильно?». Формула:
Полнота (Recall) — показывает, какую долю объектов положительного, то есть искомого класса модель определила верно. Формула:
Точность (Precision) — показывает, насколько можно доверять положительному прогнозу модели. Формула:
F1-мера (F1-score) — гармоническое среднее между точностью (Precision) и полнотой (Recall). Это единый показатель, который балансирует между двумя этими метриками. Формула:
Заключение
Машинное обучение с учителем — это метод тренировки модели, который позволяет строить прогнозы на основе данных. Такой метод легко интегрируется в бизнес-процессы, адаптируется к типам задач и масштабируется по мере роста данных. Главное условие успеха — внимание к качеству исходных данных и регулярные тесты модели на примерах.