Prometheus: как установить, настроить и использовать систему мониторинга
Prometheus — это инструмент мониторинга, который помогает командам видеть, как работают их серверы, приложения и сервисы в реальном времени. Он позволяет быстро выявлять проблемы, поддерживать стабильность сервисов и повышать производительность, что делает его важной частью современных DevOps-практик.


Что такое Prometheus
Prometheus — это высокопроизводительная система для сбора метрик и отправки оповещений (алертов). Она помогает следить за состоянием приложений и серверов и быстро реагировать на сбои.
Главная особенность Prometheus — pull-модель: сервер сам опрашивает источники данных через специальные HTTP-адреса (эндпоинты). Это упрощает контроль нагрузки и автоматическое обнаружение целей. Такой подход отличает Prometheus от многих других систем, где данные нужно отправлять принудительно (push).
Для короткоживущих задач (например, разовых пакетных заданий) предусмотрен компонент Pushgateway. Он позволяет таким задачам «протолкнуть» свои метрики в систему, если они не успевают дождаться опроса.
Как развивалось решение:
2012 год — проект создан инженерами SoundCloud для мониторинга распределенных сервисов.
2015 год — исходный код был открыт для сообщества, после чего инструмент начал активнее развиваться.
2016 год — Prometheus принят в Cloud Native Computing Foundation (CNCF) в качестве второго проекта после Kubernetes. Позже были добавлены экспортеры, сервис-дискавери, интеграции с Kubernetes и масштабируемое хранение данных.
Сегодня Prometheus стал стандартом мониторинга в облачных и микросервисных средах.
Особенности Prometheus:
Модель Pull — сервер сам опрашивает эндпоинты, упрощая сбор метрик.
Встроенное хранилище временных рядов (TSDB) — данные локально хранятся и идентифицируются по имени метрики и набору меток (labels) в формате ключ-значение. Это многомерная модель данных: одна метрика (например, http_requests_total) может иметь множество измерений (method=POST, endpoint=/api, status=200).
Экспортеры — готовые агенты для популярных сервисов, таких, как Node Exporter, Blackbox Exporter и др.).
Особенности масштабирования — стандартный Prometheus не имеет встроенной кластеризации и высокой доступности (HA). Он поддерживает федерацию (federation) для иерархического сбора данных, но это не делает отдельный инстанс отказоустойчивым. Для создания глобального query-слоя, долгосрочного хранения и обеспечения отказоустойчивости используются дополнительные компоненты: Thanos, Cortex или Grafana Mimir. Они работают поверх инстансов Prometheus, объединяя их данные, но сам сервер Prometheus остается немасштабируемым «из коробки».
Интеграция с Alertmanager — отправка обнаруженных проблем к сервису обработки оповещений, который группирует похожие оповещения (чтобы избежать «шторма уведомлений»), убирает дубликаты, подавляет (ингибирует) ложные срабатывания и маршрутизирует алерты в различные системы оповещения (receivers): электронную почту, мессенджеры (Slack/Telegram через webhook), PagerDuty, OpsGenie, а также через веб-хуки общего назначения в любые другие системы.
Интеграция с Kubernetes — автоматическое обнаружение новых подов, сервисов и нодов в кластере и сбор метрик с них.
Если вы используете Evolution Managed Kubernetes от Cloud.ru, развернуть Prometheus можно буквально за несколько команд. Сервис предоставляет готовые инструменты для мониторинга через маркетплейс плагинов, а автоматическое масштабирование кластера позволяет экономить ресурсы — вы платите только за то, что действительно используете. Гибкие настройки мастер-узлов и гарантированная доля vCPU на рабочих узлах обеспечивают стабильную работу самого мониторинга даже под высокой нагрузкой.
Сравнение Prometheus с другими популярными решениями для мониторинга:
Особенность | Prometheus | Другие инструменты |
Модель сбора данных | Pull | Push или смешанная |
Хранение данных | TSDB-база для метрик | Внешние базы или централизованные хранилища |
Масштабирование | Федерация (иерархический сбор) + внешние решения для кластеризации (Thanos/Cortex) | Зависит от системы: от централизованной до нативной кластеризации |
Язык запросов | PromQL | Зависит от конкретной системы |
Интеграция с Kubernetes | Встроенная через механизмы service discovery — автоматическое обнаружение подов, сервисов, нод и эндпоинтов Kubernetes без дополнительных агентов | Требует плагинов или агентов |
Установка и запуск | Легкий и автономный бинарник | Может требовать сложной настройки и дополнительных сервисов |
Алертинг | Встроенный Alertmanager | Внешний модуль |
Как работает Prometheus
Разберем компоненты решения и процессы, за которые отвечает система.
Архитектура системы
Prometheus состоит из нескольких компонентов, которые взаимодействуют между собой по протоколу HTTP:
Сервер Prometheus — опрашивает источники, собирает метрики и хранит их в собственной базе данных в виде временных рядов. Он же отвечает за обработку запросов и формирование алертов.
Экспортеры — собирают метрики с приложений, баз данных, оборудования или контейнеров и делают их доступными для Prometheus.
Клиентские библиотеки — позволяют разработчикам интегрировать сбор метрик в код приложений. Также они помогают отслеживать количество запросов, ошибки, задержки и другие показатели производительности.
Такая архитектура делает систему мониторинга гибкой. Решение может собирать метрики с разных источников и масштабироваться вместе с инфраструктурой.
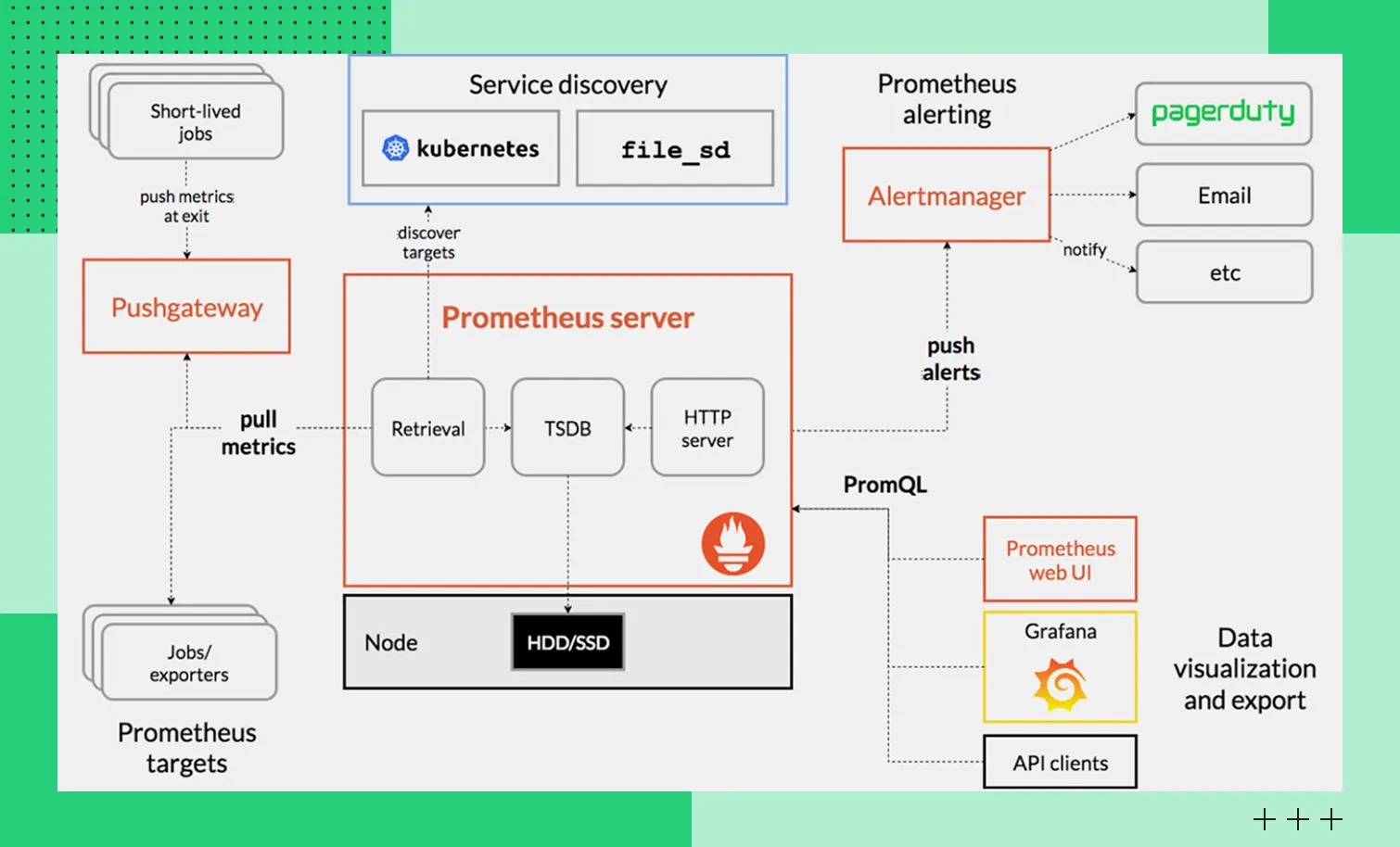 Архитектура решения
Архитектура решенияПринципы сбора и обработки данных
Сервер Prometheus опрашивает источники метрик через HTTP-эндпоинты. Каждая метрика сохраняется в виде временного ряда — набора значений, привязанных ко времени.
Как система работает с данными:
Сбор. Prometheus периодически опрашивает эндпоинты экспортеров и клиентских библиотек, получает актуальные значения метрик и сохраняет в базе данных.
Хранение. Встроенная TSDB Prometheus оптимизирована для эффективной записи и чтения временных рядов, но хранит данные на локальном диске. Для управления местом используется механизм retention (автоматическое удаление старых данных). Для долгосрочного хранения и централизованного анализа данных из нескольких инстансов Prometheus используется протокол remote_write для отправки во внешние хранилища (Thanos Receive, Cortex, VictoriaMetrics), а также в другие TSDB, поддерживающие этот протокол (например, M3DB, InfluxDB).
Обработка. Для анализа и визуализации данных применяется язык запросов PromQL. С его помощью можно строить графики, рассчитывать средние значения, сравнивать показатели и формировать алерты.
Prometheus обеспечивает полный цикл наблюдения за инфраструктурой — от сбора данных до отправки уведомлений о проблемах.

Установка и настройка Prometheus
На странице загрузок Prometheus скачайте нужную версию архива для Linux, например:
Распакуйте файлы:
Создайте пользователя и каталог для хранения данных:
Создайте systemd-unit, чтобы запускать Prometheus как сервис. Пример /etc/systemd/system/prometheus.service:
Затем выполните настройки:
Введите в браузере http://<IP_сервера>:9090. Должен появиться интерфейс Prometheus.
Запуск Prometheus через Docker и Kubernetes
Запустите систему мониторинга через Docker командой:
Чтобы метрики не терялись при перезапуске контейнера, используйте механизм bind‑mount для хранения данных. Как это может выглядеть:
Для установки и запуска через Kubernetes добавьте официальный репозиторий Helm чартов для Prometheus:
Установите Prometheus:
С помощью команды вы развернете Prometheus и необходимые экспортеры. Дополнительно можно использовать механизмы сервис-дискавери и ServiceMonitor.
Конфигурация Prometheus
Настройте Prometheus так, чтобы он собирал метрики только от нужных сервисов. Настройки можно выполнять в основном конфигурационном файле — prometheus.yml. Он обычно находится в каталоге /etc/prometheus/.
Пример минимальной конфигурации:
Это значит, что каждые 15 секунд система мониторинга будет опрашивать указанный сервис (scrape_interval) и с той же периодичностью оценивать правила алертинга и записи (evaluation_interval), если они определены.
Советы по конфигурированию:
Разделяйте конфигурацию по зонам, чтобы потом было проще разобраться, что и зачем вы мониторите.
Используйте метки и группировки, чтобы было проще фильтровать метрики и строить дашборды.
Настраивайте оптимальные интервалы сбора, чтобы он не был слишком частым или слишком редким.
Храните конфигурацию в системе контроля версий — так проще отслеживать изменения.
При запуске через Docker монтируйте внешнее хранилище для метрик, чтобы информация не потерялась при перезапуске контейнера.
Функции и возможности Prometheus
Рассмотрим три главные функции системы мониторинга — сбор метрик, алерты и интеграции.
Сбор и хранение метрик
Prometheus собирает данные о работе приложений, серверов и сервисов в виде метрик — числовых показателей, которые показывают, как работает система. Например, это может быть загрузка процессора, количество запросов к базе данных или время ответа веб-сервиса.
Сбор метрик происходит так: Prometheus сам опрашивает источники данных (серверы, приложения, контейнеры) через специальные точки доступа, которые называются эндпоинтами. Все собранные сведения хранятся во встроенной базе данных Prometheus, оптимизированной для быстрого чтения и записи. Хранение временных рядов позволяет отслеживать изменения показателей со временем и выявлять проблемы до того, как они станут критическими.
Настройка алертинга
Prometheus позволяет создавать правила оповещений (alerting rules) на основе условий (например, если метрика выше порога). Когда правило срабатывает, Prometheus отправляет уведомление в Alertmanager. Alertmanager отвечает за дальнейшую обработку: группировку, подавление дубликатов и доставку оповещений по разным каналам — электронной почте, в мессенджеры, PagerDuty и другие системы.
Оповещения можно отправлять по разным каналам: электронная почта, мессенджеры (Slack/Telegram), системы обработки инцидентов (PagerDuty, OpsGenie) и через веб-хуки в любые другие системы.
Мониторинг и интеграция
Prometheus интегрируется с инструментами, которые помогают собирать метрики с компонентов инфраструктуры. Например, Node Exporter собирает метрики операционной системы (CPU, память, диск, сеть, файловые системы). cAdvisor (Container Advisor) собирает метрики использования ресурсов контейнерами (CPU, память, сеть, диск) независимо от конкретной реализации container runtime. В Kubernetes cAdvisor встроен непосредственно в компонент kubelet, работающий на каждом узле кластера, что позволяет собирать метрики всех запущенных подов без дополнительной установки.
Интеграция позволяет построить полную картину работы всей системы и понять, как взаимодействуют серверы, приложения и контейнеры. Данные можно визуализировать с помощью графиков и дашбордов, чтобы команда могла легко анализировать состояние инфраструктуры.
Интеграция Prometheus с другими инструментами
Интеграция Prometheus позволяет систему мониторинга гибкой и эффективной. Помимо сбора и хранения метрик компаниям нужны визуализация, своевременные оповещения, работа с контейнерами и облачными платформами. Благодаря интеграции с Grafana и экспортерами мониторинг становится полноценным и покрывает все нужды бизнеса.
Интеграция с Grafana
Чтобы было проще анализировать и визуализировать метрики, Prometheus часто используют в тандеме с Grafana — платформой для визуализации данных. С ее помощью удобно создавать дашборды. Что можно в них отразить:
загрузку процессора и память на серверах;
количество запросов к веб-приложению и базам данных;
время отклика сервисов;
ошибки и сбои в работе приложений.
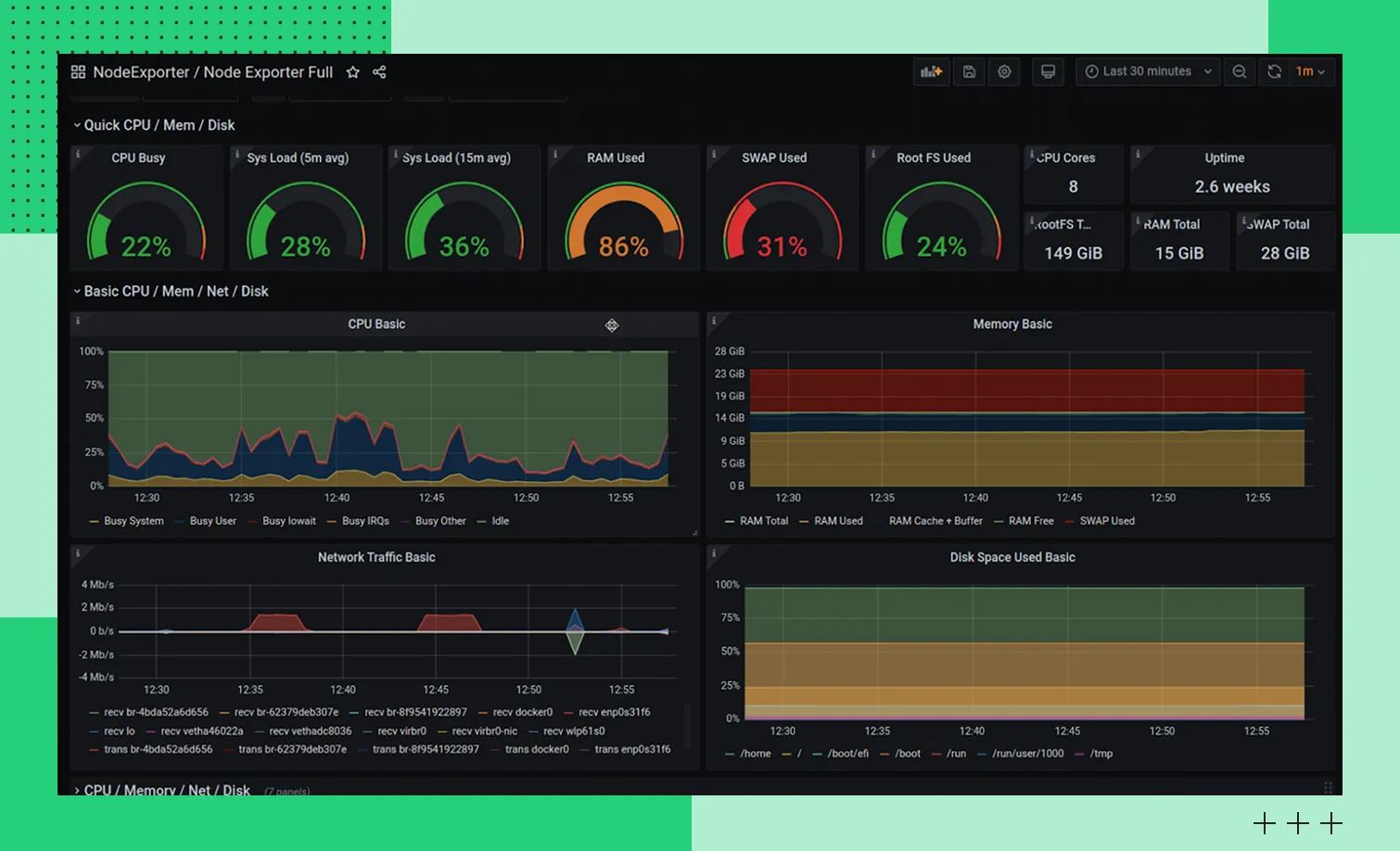 Пример дашборда
Пример дашбордаИспользование Grafana помогает команде глубже вникнуть в состояние инфраструктуры и выявлять проблемы до того, как они повлияют на пользователей. Дашборды можно настраивать для разных команд, например, DevOps, разработчиков и менеджеров.
Настройка и использование экспортеров
Экспортеры — это утилиты, которые собирают метрики из приложений, сервисов и с оборудования, чтобы передать их в Prometheus. Они расширяют возможности системы мониторинга, позволяя отслеживать даже те источники, которые не могут напрямую отдавать метрики.
Примеры популярных экспортеров:
Node Exporter — собирает данные о сервере, такие, как CPU, свободная память, диски, сеть;
cAdvisor — собирает метрики использования ресурсов контейнерами (CPU, память, сеть, диск). В Kubernetes встроен в компонент kubelet на каждом узле кластера;
PostgreSQL Exporter — отвечает за метрики базы данных PostgreSQL, такие, как количество соединений, активные транзакции, задержки
MySQL Exporter — работает с базами данных MySQL;
Blackbox Exporter — проверяет доступность веб-сервисов и API.
Интегрировать Prometheus с экспортерами несложно — достаточно их запустить как отдельные процессы. Система мониторинга подключается к ним через эндпоинты и начинает собирать метрики. На основе полученной информации можно строить дашборды с Grafana.
Практические сценарии использования Prometheus
Что можно мониторить с помощью системы:
Серверы и виртуальные машины. Prometheus в комбинации с Node Exporter помогает компаниям следить за состоянием физических и виртуальных серверов — загрузкой процессора, использованием памяти, диском и сетью. В больших дата-центрах метрики позволяют прогнозировать перегрузки и распределять нагрузку, чтобы сервисы не «проседали».
Контейнеры и Kubernetes-кластеры. Система мониторинга хорошо работает с контейнерами и сама обнаруживает новые поды. Она собирает сведения о том, сколько ресурсов потребляют контейнеры и сколько запросов обрабатывают, какие ошибки возникают. Такой подход используется в Shopify и GitLab. Он помогает управлять многочисленными микросервисами, которые постоянно запускаются и масштабируются.
Базы данных. С помощью экспортеров система мониторинга может получать информацию о количестве активных соединений и транзакций за секунду, скорости выполнения запросов. Prometheus помогает отслеживать состояние распределенных баз данных и вовремя замечать слабые места в системе хранения.
Веб-приложения и API. Blackbox Exporter позволяет проверять доступность сайтов и API. Крупные интернет-магазины вроде Zalando или eBay используют такой мониторинг, чтобы не пропускать моменты, когда фронтенд или бэкенд начинает тормозить или перестает отвечать.
Мониторинг микросервисов и распределенных систем. Prometheus может собирать данные из кода в клиентских библиотеках для Go, Python, Java и других языков. Это помогает следить за работой отдельных сервисов и контролировать простои.
Кейсы использования системы мониторинга:
Компания | Как используется Prometheus | Результат |
SoundCloud | Prometheus использовался для мониторинга микросервисов SoundCloud. Он помогал отслеживать нагрузки и текущее состояние сервисов | Помог решить проблемы масштабирования и нестабильности деплоя. Обеспечил контроль за множеством сервисов при росте нагрузки и числа пользователей |
Spotify | В своей инфраструктуре компания использует Prometheus с другими DevOps инструментами для мониторинга потоковой передачи, производительности сервисов и пользовательской активности | Помогает оперативно отслеживать метрики, проблемы с производительностью, нагрузку и стабильность сервисов. Это важно для стриминговой платформы с миллионами пользователей |
Netflix | Использует Prometheus вместе с другими системами для наблюдения за состоянием сервисов, производительностью и алертингом | На распределенных системах с высоким трафиком Prometheus позволяет обнаруживать проблемы, быстро реагировать и обеспечивать стабильность работы |
Компания, использующая AWS сервисы | Использует сервис Managed Service for Prometheus для Prometheus, чтобы мониторить Kubernetes, контейнеры, EC2 инстансы и другие ресурсы без необходимости поддерживать мониторинговую инфраструктуру | Обеспечивает масштабирование мониторинга, охват различные типы окружений, снижение нагрузки на DevOps команду и экономия ресурсов |
Облачные и ИТ компании | Используют Prometheus для мониторинга Kubernetes кластеров, микросервисов, метрик контейнеров и кластеров. Компании применяют федерацию, масштабирование и централизованный сбор метрик | Позволяет агрегировать метрики, мониторить множество кластеров, гибко настраивать алерты и визуализацию |
Масштабирование мониторинга
С ростом инфраструктуры увеличивается количество серверов, контейнеров и сервисов, поэтому одного экземпляра Prometheus может быть недостаточно. Чтобы система оставалась стабильной и по-прежнему качественно собирала метрики, нужно правильно ее масштабировать. Советы для крупных инфраструктур:
Разделяйте сбор метрик — используйте несколько экземпляров Prometheus для разных кластеров или групп сервисов, чтобы снизить нагрузку на один инстанс.
Используйте федерацию — объединяйте данные с нескольких серверов Prometheus в один центральный для анализа и визуализации, чтобы не перегружать отдельный инстанс.
Удаляйте старые данные — оставляйте в Prometheus только актуальные метрики за последние дни/недели, а более старые метрики сохраняйте в другое хранилище.
Фильтруйте метрики при сборе — собирайте только нужные данные, чтобы не перегружать систему и не тратить ресурсы на лишнее.
Используйте горизонтальное масштабирование — если один экспортер не справляется с большим количеством метрик, запускайте несколько экземпляров.
Для удобства управления правилами оповещений группируйте их по логическому признаку (например, по командам или микросервисам). Группы правил позволяют контролировать частоту вычисления (evaluation interval) и упрощают навигацию. Жесткого лимита на количество правил в группе нет, но рекомендуется не делать их слишком большими для удобства поддержки.
Заключение
Prometheus решает основные задачи мониторинга — от сбора метрик до алертинга и визуализации. Он особенно хорошо подходит для динамических сред (например, Kubernetes) благодаря встроенным механизмам service discovery, которые позволяют автоматически находить новые цели для мониторинга без ручной перенастройки.
Благодаря гибкости и богатым возможностям интеграции Prometheus приносит пользу не только техническим специалистам, но и бизнесу в целом. Использование системы снижает риски длительных простоев, повышает стабильность сервисов и ускоряет реакцию на инциденты, что напрямую влияет на качество пользовательского опыта и репутацию компании.