Популярные базы данных: обзор распространенных СУБД
Еще недавно реляционные системы управления базами данных (СУБД) были универсальным решением и использовались везде. Принцип «одна база для всех сценариев» работал, пока правила игры не изменились. Рост объемов данных, появление распределенных систем и ужесточение требований к скорости обработки сделали универсальный подход неэффективным. Сегодня на рынке представлены десятки специализированных решений — под любые задачи и архитектуры. Разберемся, что и для каких случаев выбрать: проверенную классику или современную сложную СУБД.


Фундамент — парадигмы хранения данных
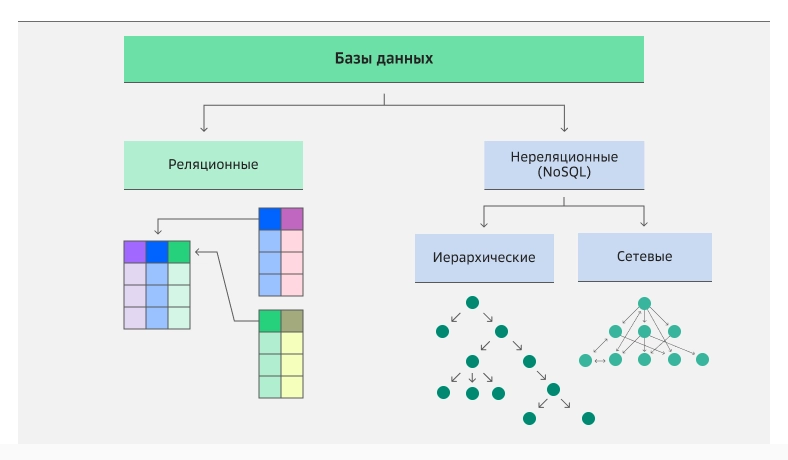
СУБД построены на разных принципах. Есть реляционные, нереляционные и гибридные модели. Рассказываем, чем они отличаются и где полезны.
Реляционная модель (SQL): таблицы, схемы и гарантии ACID
Реляционные базы подразумевают хранение данных в виде таблиц со строками — записями и столбцами — атрибутами. Первые содержат сведения об объектах, вторые — описывают свойства этих объектов.
SQL — стандартный язык программирования для реляционных БД. Он используется для формирования запросов, с помощью которых можно искать, структурировать и отображать информацию.
Реляционные базы данных построены по принципу ACID (Atomicity, Consistency, Isolation, Durability). Расшифруем:
A (Атомарность) — транзакция выполняется корректно либо не выполняется.
C (Согласованность) — по окончании транзакции база данных переходит из одного корректного состояния в другое.
I (Изолированность) — транзакции изолированы друг от друга в целях обеспечения согласованности данных.
D (Долговечность) — после выполнения транзакции данные не теряются даже при сбоях системы.
Связать таблицы между собой в реляционных базах помогают ключи:
Первичный ключ (Primary Key) является идентификатором записей в таблице. Он гарантирует уникальность каждой записи в таблице и предотвращает дублирование.
Внешний ключ (Foreign Key) устанавливает связи между таблицами, обеспечивая ссылочную целостность данных.
Ключи в совокупности гарантируют корректность записей и позволяют обеспечить согласованность данных.
Структуру реляционных баз данных описывают схемы. Это «карты», где указаны типы хранимой информации, созданные таблицы, ключи и связи. Схемы отвечают за логическую организацию данных.
Примеры реляционных баз данных: PostgreSQL, MySQL, MariaDB, Microsoft SQL Server, Oracle Database. Они подходят для ERP, CRM, бухгалтерских и банковских сервисов и других систем, где недопустимы ошибки и потеря данных.
Нереляционные модели (NoSQL): отказ от универсальности ради специализации
Ограничения классических реляционных баз данных создавали неудобства в работе распределенных и высоконагруженных систем. Как альтернатива появились NoSQL-модели. Они отошли от универсальной модели и предлагают специализированные решения — документоориентированные, колоночные и графовые базы данных.
Принцип NoSQL-систем описывает теорема CAP. Она утверждает, что в распределенных системах нельзя на должном уровне одновременно обеспечить согласованность и доступность данных, возможность разделения сети. Нужно решить, какими свойствами жертвовать ради отказоустойчивости и масштабируемости.
NoSQL-базы применяются там, где важны доступность и горизонтальное масштабирование: в веб-приложениях, системах аналитики, потоковой обработке данных и микросервисных архитектурах.
 Различия между СУБД
Различия между СУБДНовые гибридные и многомодельные подходы
Благодаря эволюции технологий можно не выбирать между SQL и NoSQL и использовать гибридные СУБД. Они поддерживают разные типы данных и способы доступа в одной платформе.
В основе — концепция, которая подразумевает, что не нужно закрывать все задачи с помощью одного решения. Можно использовать несколько технологий, например, транзакционные данные хранить в реляционной базе, документы — в документоориентированной. Такая гибкость позволит построить масштабируемую архитектуру, где каждое решение выполняет свои задачи.
Реляционные СУБД (SQL) — столпы индустрии
Классические системы с кратким описанием и примерами применения:
СУБД | Особенности | Типовые сценарии использования |
PostgreSQL — «База данных для всех случаев» |
| Сложные транзакционные и аналитические нагрузки, универсальные системы, проекты с меняющимися требованиями |
MySQL и MariaDB — «Король веб-разработки» | MySQL:
MariaDB (форк MySQL):
| Веб-приложения (LAMP и LEMP), сайты и сервисы с преобладанием операций чтения |
Microsoft SQL Server — «Интеграция с экосистемой Microsoft» |
| Корпоративные приложения на Microsoft, системы отчетности и бизнес-аналитики |
Oracle Database — «Флагман для mission-critical систем» |
| Mission-critical системы, финансовые, телекоммуникационные и государственные проекты |
Хотя PostgreSQL является ACID-совместимой СУБД, некоторые служебные команды администратора базы данных (DDL), такие как VACUUM, CREATE DATABASE, ALTER DATABASE и CREATE TABLESPACE, не могут быть выполнены внутри транзакционного блока (BEGIN; ... COMMIT;) и выполняются вне транзакций
Документоориентированные базы и ключ-значение
Такие решения позволяют работать с неструктурированными и полуструктурированными данными, быстро выполнять запросы и горизонтально масштабироваться. Сравним представителей этой категории:
СУБД | Особенности | Типовые сценарии использования |
MongoDB (документоориентированная) |
| Каталоги, CMS и контент-платформы, приложения и работа с JSON-подобными форматами |
Redis (ключ–значение, in-memory БД) |
| Кэширование, хранение пользовательских сессий, очереди задач, рейтинги и real-time системы |
Amazon DynamoDB (ключ–значение и документоориентированная, managed) |
| Высоконагруженные веб-приложения, микросервисы, системы с плавающей нагрузкой и глобальные сервисы |
Azure Cosmos DB (мультимодельная NoSQL, managed) |
| Геораспределенные приложения, SaaS-платформы и облачные сервисы |
Колоночные, графовые и временные ряды
Специализированные решения созданы для конкретных задач, таких, как аналитика, мониторинг событий, установление связи между объектами. Рассказываем о самых популярных СУБД в этой категории.
Колоночные и ширококолоночные СУБД: ClickHouse, Apache Cassandra
Важно различать колоночные (column-oriented) и ширококолоночные (wide-column) базы данных.
ClickHouse — это классическая колоночная СУБД (column-oriented). Она оптимизирована под аналитические нагрузки (OLAP): данные физически хранятся по колонкам, что обеспечивает рекордную скорость агрегации и сжатия для сложных запросов. ClickHouse идеально подходит для аналитики логов, метрик и построения отчетности. Однако стоит учитывать, что его архитектура лучше всего оптимизирована для операций фильтрации и агрегации над одной таблицей, в то время как сложные JOIN'ы между большими таблицами могут быть менее эффективны по сравнению с традиционными MPP-системами.
Управляемый ClickHouse®
Аналитика в современном мире требует не только мощной СУБД, но и надежной инфраструктуры. Чтобы сосредоточиться на данных, а не на администрировании, обратите внимание на сервис Evolution Managed ClickHouse® от Cloud.ru.
Что внутри:
Готовый кластер за пару кликов — никакой ручной установки и настройки.
Автоматическое обслуживание — обновления, резервное копирование и мониторинг.
Гибкость — меняйте параметры кластера без перезапуска через удобный интерфейс.
Высокая доступность — сервис подходит для продакшн-нагрузок и аналитики.
Интеграция с экосистемой — логирование, управление доступом и уведомления из коробки.
Apache Cassandra — это ширококолоночная (wide-column store) база данных. Она основана на архитектуре Amazon Dynamo и модели данных Google Bigtable. Cassandra ориентирована на хранение огромных объемов данных, горизонтальную масштабируемость и отказоустойчивость без единой точки отказа. В отличие от колоночных СУБД, она оптимизирована под запись, а не под сложную аналитику, и идеально подходит для проектов, где критически важны непрерывная запись данных, распределенность и постоянная доступность информации (например, в IoT или трекинге событий).
Графовые СУБД: Neo4j
Графовые СУБД применяют структуру графа для хранения данных и запросов. Здесь два базовых компонента — узлы и ребра. Узлы — это сущности данных со свойствами, которые их описывают. Ребра отображают связь между узлами. Эти связи могут быть ориентированными и неориентированными. В ориентированных графах у всех ребер есть определенное направление, в неориентированных — нет.
Пример графовой СУБД — Neo4j. Сущности тут хранятся в виде нод, а отношения между ними — в виде ребер. Это позволяет оперативно выполнять запросы по цепочкам связей и искать сложные зависимости без JOIN-операций. Neo4j подходит для систем рекомендаций (recommender systems), выявления мошенничества (fraud detection) на основе связей, управления графами знаний (knowledge graphs), анализа социальных сетей и других задач, где важны связи между сущностями.
СУБД временных рядов (TSDB): InfluxDB, TimescaleDB
СУБД временных рядов или Time Series Databases подойдут для проектов, где ключевым измерением является время. У каждой записи есть временная метка, поэтому можно делать выборки по определенным интервалам. TSDB-базы сжимают данные, группируют их по времени и позволяют выполнять агрегатные операции с малой нагрузкой на систему.
Представители класса — InfluxDB и TimescaleDB. InfluxDB — решение со своим языком запросов и высокой производительностью при записи метрик. TimescaleDB — реляционное расширение PostgreSQL. База сочетает модель временных рядов и все возможности реляционной БД (полноценный SQL, JOIN'ы, ACID-транзакции) для сложной аналитики.
Обе СУБД часто применяются в IoT-проектах и системах мониторинга, откуда постоянно поступают данные. Также они подходят для хранения финансовых котировок и телеметрии.

Встраиваемые и легковесные базы для десктопа, мобильных и edge-устройств
Такие СУБД нужны для локального хранения данных на устройствах и обработки в edge-инфраструктуре. Они работают внутри приложения и требуют минимальных ресурсов.
СУБД | Особенности | Типовые сценарии использования |
SQLite (встраиваемая реляционная СУБД) |
|
|
DuckDB (встраиваемая аналитическая СУБД, OLAP) |
|
|
Правила выбора базы данных
Не стоит использовать какую-то БД потому, что она востребована другими компаниями. Ориентируйтесь на свои задачи, тип систем и данных. Рассказываем, как сделать верный выбор.
Чек-лист вопросов
Какая структура данных — четкая схема или эволюционирующая? Нужны ли сложные связи?
Если данные формализованы, и нужны сложные связи между ними, выбирайте реляционные базы — PostgreSQL или MySQL. Если структура данных эволюционирует, подойдут системы вроде MongoDB, которые позволят работать с гибкими JSON-структурами. В приоритете связи? Подойдут графовые базы данных.
Что преобладает — чтение или запись? Какое желаемое время отклика?
Для систем с короткими транзакциями и частыми обновлениями используются базы вроде PostgreSQL или Oracle. Если в приоритете чтения с минимальными задержками, подойдут in-memory-хранилища, например, Redis. Для аналитики нужны колоночные решения, такие как ClickHouse.
Какой объем данных сегодня и какой может быть через 3 года?
При проектировании учитывайте не только существующую информацию, но и рост объема данных. Если планируете вертикальное масштабирование, выбирайте классические реляционные базы, например, PostgreSQL. При потенциальном увеличении нагрузки обратите внимание на системы, которые масштабируются горизонтально — ClickHouse и Cassandra.
Нужна строгая модель ACID или eventual consistency (согласованность в конечном счете) допустима?
Не всегда нужна строгая консистентность. Если речь о системах, где расхождения данных недопустимы, требуется базы с поддержкой ACID, такие, как PostgreSQL или Oracle. Для логов, пользовательских событий или рекомендаций допустима согласованность в конечном счете (eventual consistency). В таких архитектурах данные могут сначала поступать в потоковую платформу (например, Apache Kafka), выступающую в роли надежного буфера и источника событий, а затем асинхронно обрабатываться и записываться в специализированные БД, такие как ClickHouse или Elasticsearch.
Какой стек технологий использует компания? Есть ли навыки обслуживания сложных решений?
Важно понять, с чем умеет работать команда. Простой вариант — PostgreSQL. В командах с сильной экспертизой можно использовать сложные связки типа Kafka+ClickHouse или Kafka+Cassandra. Только убедитесь, что решение вписывается в инфраструктуру.
Что предпочтительнее — оpen-source или коммерческая лицензия, управляемый облачный сервис? Какой бюджет заложен?
Если хотите избежать лицензионных затрат, выбирайте оpen-source базы данных вроде PostgreSQL, Redis или ClickHouse. Облачные версии Kafka и PostgreSQL, например, Evolution Managed PostgreSQL от Cloud.ru ускорят внедрение, снизят нагрузку на команду, но потребуют более весомых расходов.
Типовые архитектурные паттерны
Первый — полиглотная персистентность (Polyglot Persistence). Это стратегия проектирования, при которой разные компоненты или сервисы одной системы используют разные типы СУБД (SQL, NoSQL, графовые и т.д.), выбирая наиболее подходящий инструмент для конкретной модели данных и паттерна доступа. Например, транзакционные данные пользователей могут храниться в PostgreSQL, часто запрашиваемые сессии — кэшироваться в Redis, а каталог товаров с гибкой структурой — в MongoDB. Вариант подходит, если одну базу нельзя использовать для всех сценариев.
Второй — event-driven микросервисы. В каждом микросервисе своя база, например, PostgreSQL или MongoDB. Взаимодействие между микросервисами может происходить через события, которые публикуются в Kafka. Чтение и запись иногда разделяют, а согласованности данных достигают за счет Saga.
Третий — логирование и аналитика. Данные могут сначала поступать Kafka, затем передаваться в аналитические хранилища. Для высокоскоростной аналитики и отчетов можно использовать ClickHouse. Для временных рядов и мониторинга — TimescaleDB.
Заключение
Тренд в развитии баз данных — не заменять одни технологии другими, а попытаться их «подружить». Например, SQL станет универсальным интерфейсом даже для NoSQL-систем, облачные managed- и serverless-сервисы возьмут на себя операционные задачи, HTAP-платформы — сократят разрыв между транзакционными и аналитическими нагрузками. Не стоит стартовать со сложного — часто хватает PostgreSQL. Специализированные инструменты можно добавлять по мере доказанной необходимости.