Нереляционная база данных NoSQL — что это и в чем ее особенности
Мы уже рассказывали про реляционные — табличные — базы данных и СУБД MySQL и PostgreSQL. Однако при работе с огромными объемами информации, которые генерирует современная IT-среда, они не всегда удобны. И здесь на помощь приходят нереляционные базы данных (NoSQL). О том, в чем их особенности и в каких случаях они могут пригодиться, поговорим в этой статье.

Основное отличие между реляционными и нереляционными базами данных заключается в том, каким способом они хранят содержимое:
реляционные БД представляют информацию в виде таблиц с определенным числом столбцов — это удобно при работе с однотипными данными;
нереляционные БД позволяют более гибко подходить к управлению данными, определяя информационную модель в процессе работы приложения.
NoSQL(not only SQL, «не только SQL») — это тип баз данных, для работы с которыми используется не только язык SQL, но и столбцовые, графовые, документоориентированные системы, а также системы модели «ключ — значение».
Почему потребность в базах NOSQL вообще возникла? Ведь казалось бы, основная задача любой базы данных — чтобы все лежало на своих местах и было логически связано. Это действительно так. Однако здесь приходится учитывать технические ограничения реляционных баз, которые не позволяет им эффективно выполнять некоторые задачи.
Чтобы разобраться с методами организации данных детальнее, обратимся к аналогии «стул vs. шкаф с дворецким», которую мы уже использовали в одной из предыдущих статей.
Зачем придумали базы NoSQL
Представьте: вам нужно быстро одеться, чтобы поехать на работу. При этом вы можете:
обратиться за помощью к личному дворецкому — он подберет для вас идеально подходящий набор одежды, достав его из шкафа с функционально разделенными полками;
взять нужную одежду со стула, на котором царит полный хаос, но зато все на виду и в быстром доступе.
В этой аналогии шкаф с личным дворецким и стул с наваленной на него одеждой — это реляционная и нереляционная база данных соответственно.
Какие задачи решают нереляционные базы данных
Использование нереляционных баз данных будет эффективно в тех случаях, когда:
…предстоит работа с очень большим объемом данных. Представьте, что вы купили много одежды: дворецкий едва справляется с тем, чтобы распаковывать ее, гладить, сортировать и раскладывать по ящикам шкафа. В такой ситуации ему трудно быстро предоставить вам нужную одежду на выход. Поэтому будет проще взять ее со стула.
…доступность данных важнее их полноты и связности. Возможно, васильковая рубашка лучше смотрится с синими джинсами, чем белая футболка. Но футболку вы можете надеть прямо сейчас, а рубашку еще надо найти.
…нужно работать с разнородными данными. Допустим, у вас в гардеробе имеются повседневные джинсы, специальные шорты для велогонок, запонки, ковбойская шляпа и костюм имперского штурмовика. Тогда дворецкому сложно понять, как правильно классифицировать все эти виды одежды.
…есть потребность в масштабировании. Что делать, если в вашем в шкафу не хватает места под новый костюм? Можно купить новый комод и отвести в нем ящик под этот костюм. А можно расширить условный стул до масштабов комнаты и просто оставить там костюм. Или даже много костюмов.
…важна адаптивность к новым способам применения данных. Например, вы решили разжаловать домашнюю футболку до тряпки. Все, что вам для этого потребуется — взять ее со стула. А если просить дворецкого, он сперва потратит время на поиски, а потом и вовсе принесет не то.
Как появились NoSQL-системы
Нереляционные способы организации данных существовали с самого начала эры компьютерных технологий, но особую популярность получили в конце 2000-х, когда технологический ландшафт сильно изменился:
Возросли объемы данных. С появлением социальных сетей, IoT и Big Data объемы данных стали так велики, что реляционные базы перестали эффективно справляться с их хранением и обработкой.
Наличие неструктурированных данных. Многие современные данные (например, JSON-, XML-, лог-файлы, ) не имеют строгой структуры, что делает их хранение в таблицах неудобным.
Рост требований к производительности. Для эффективной работы некоторых видов приложений — онлайн-игр, стриминговых платформ и других систем реального времени — важно обеспечить максимально низкую задержку, что сложно сделать с реляционными базами данных.
Необходимость горизонтального масштабирования. Современные системы часто работают в распределенных средах, где данные хранятся на множестве серверов. Реляционные базы данных плохо подходят для таких сценариев.
Перечисленные вызовы спровоцировали передовые IT-компании обратиться к нереляционным СУБД. Например, Google начала использовать распределенные файловые системы, системы координации и метод обработки данных MapReduce для таких приложений как Google Maps и Google Earth. А позже создала собственную масштабируемую СУБД, основанную на модели хранения данных в виде столбцов.
В дальнейшем описанные Google технологии вызвали большой интерес среди разработчиков, который привел к созданию проекта Hadoop и ряда связанных с ним инициатив. А уже в 2007 году Amazon последовала примеру Google и представила свою базу данных — Amazon DynamoDB.
SQL и NoSQL: отличия в структуре данных, управление информацией и транзакциями
Как мы говорили выше, основное отличие между SQL и NoSQL базами — разные форматы хранения данных. Реляционные базы хранят их в виде таблиц, что удобно при работе с системами, где важны точность, структурированность и надежность (например, банковские системы). А NoSQL больше подходят тогда, когда важны скорость, гибкость и масштабируемость (например, при работе с социальными сетями или аналитике больших данных).
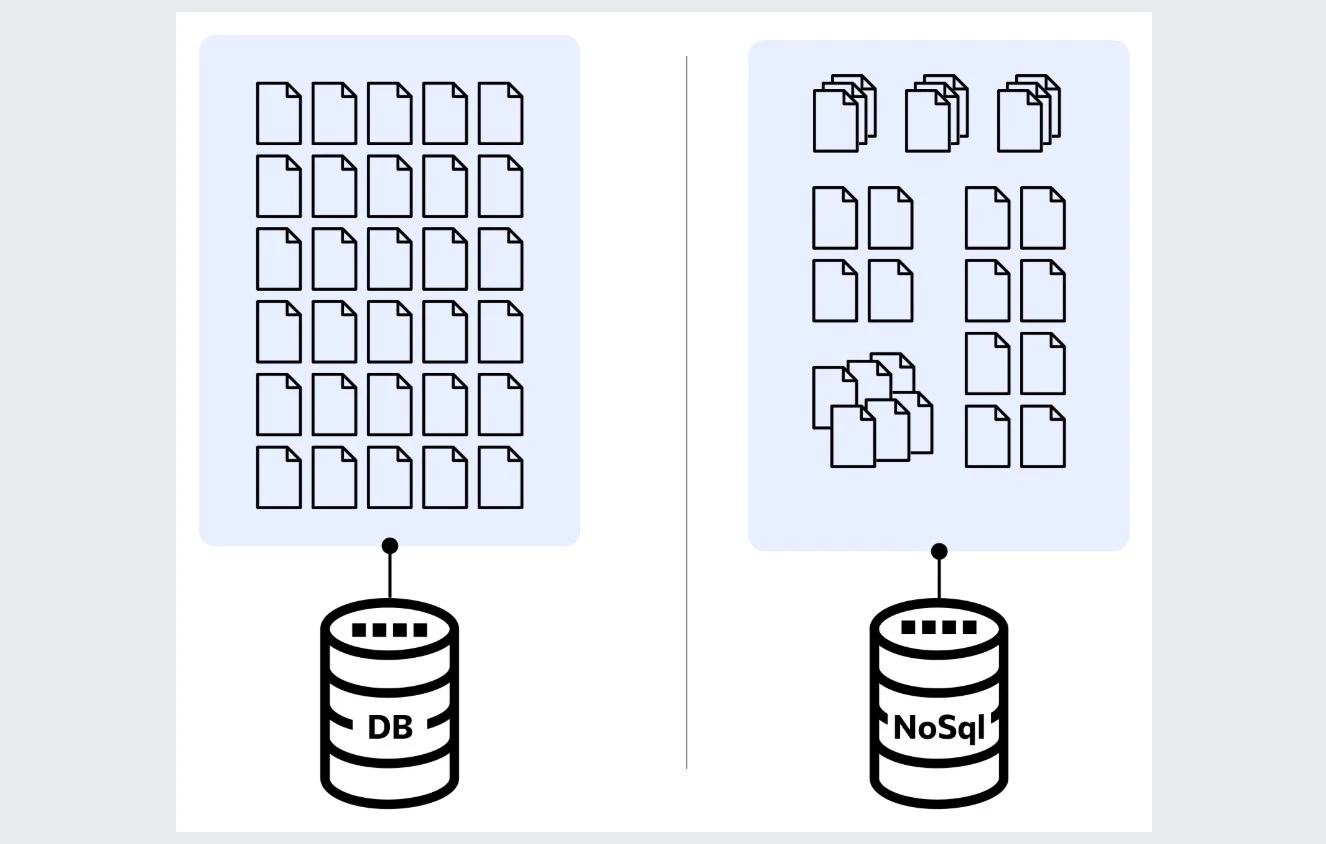 Различия между SQL и NoSQL базами данных
Различия между SQL и NoSQL базами данныхОсновные отличия структуры данных SQL и NoSQL баз
Если представить данные как деньги, то реляционные базы будут банковским счетом, куда можно положить свои средства и хранить их в соответствии со строго определенными правилами. А нереляционные базы станут аналогом домашней копилки — можно использовать ее для хранения любого количества денег и открыть в любое время.
Различия в управлении данными и транзакциями: ACID vs BASE
Управление данными в SQL и NoSQL осуществляется по разным принципам. В SQL используется подход ACID (Atomicity, Consistency, Isolation, Durability), согласно которому каждая транзакция должна быть:
Атомарной (Atomicity): либо выполняется все, либо ничего. Если что-то пошло не так, операция отменяется.
Согласованной (Consistency): после операции данные остаются в корректном состоянии (например, баланс по дебетовому счету не может быть отрицательным).
Изолированной (Isolation): операции выполняются последовательно и не мешают друг другу.
Долговечной (Durability): после завершения операции данные сохраняются, даже если система отключена.

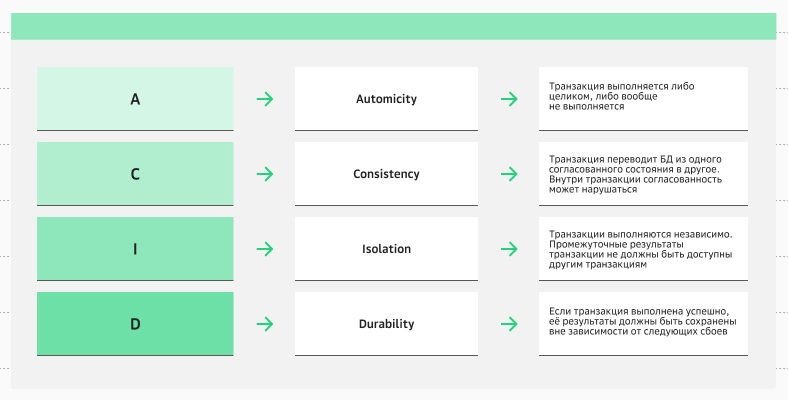 Принципы ACID, на которых базируется надежность реляционных СУБД
Принципы ACID, на которых базируется надежность реляционных СУБДACID-подход повышает надежность управления данными, но часто снижает скорость процессов.
В NoSQL используется подход BASE (Basically Available, Soft state, Eventually consistent), что расшифровывается как:
Basically Available (Базовая доступность): система всегда готова работать, даже если часть данных временно недоступна.
Soft state (Мягкое состояние): данные могут со временем меняться, даже без новых операций.
Eventually consistent (Конечная согласованность): в конечном итоге все данные станут согласованными, но не обязательно сразу.
Четыре типа баз данных NoSQL
Теперь рассмотрим структуру основных типов нереляционных БД.
Ключ-значение (Key-Value Store)
В базах типа «ключ-значение» данные хранятся в виде пар, где ключ — это уникальный идентификатор, а значение — это данные, которые могут быть любого типа: строка, число, JSON-объект и т.д. Это одна из самых простых моделей хранения, которая обычно используется для задач, где требуется быстрый доступ к данным по уникальному идентификатору. Например, для задач кеширования, хранения сессий пользователей или настроек.
К популярным NoSQL СУБД этого типа относятся:
Redis. Высокопроизводительная база данных, часто используемая для кеширования и работы с временными данными.
Amazon DynamoDB. Управляемая база данных от Amazon, которая масштабируется автоматически и подходит для высоконагруженных приложений.
Riak. Распределенная база данных, которая обеспечивает высокую доступность и отказоустойчивость.
Приведем пример, как могут выглядеть операции с данными в нереляционной СУБД Redis. В Redis запросы выполняются с помощью специальных команд, а не на языке запросов, как в SQL. Например:
SET: сохранить значение по ключу.
GET: получить значение по ключу.
DEL: удалить ключ и его значение.
EXISTS: проверить, существует ли ключ.
INCR: увеличить числовое значение на 1.
DECR: уменьшить числовое значение на 1.
KEYS: найти ключи по шаблону.
FLUSHALL: удалить все данные из базы.
Вводить команды можно в интерактивном режиме (CLI) или использовать клиентские библиотеки для различных языков программирования, в числе которых Python, JavaScript, Java, PHP. Redis прост в использовании и идеально подходит для задач, где важны скорость и простота доступа к данным.
 Преимущества использования Evolution Managed Redis от Cloud.ru
Преимущества использования Evolution Managed Redis от Cloud.ru Документоориентированные базы данных
Документоориентированные базы данных (Document Stores) — это тип NoSQL баз данных, где данные хранятся в виде документов, обычно в формате JSON, BSON или XML.
Документы в документоориентированных БД — это самостоятельные единицы, которые содержат всю необходимую информацию. Они могут быть вложенными, что позволяет им хранить сложные структуры данных.
Документоориентированные базы данных, такие как MongoDB или CouchDB, используют собственные языки запросов или API для работы с данными. В отличие от SQL, где данные хранятся в таблицах, здесь они содержатся в коллекциях документов.
MongoDB предоставляет консольный интерфейс (MongoDB Shell), где можно вводить команды напрямую, например:
insertOne(document): вставить один документ.
find(query): найти документы по запросу.
findOne(query): найти один документ по запросу.
updateOne(query, update): обновить один документ.
deleteOne(query): удалить один документ.
createIndex(keys): создать индекс для ускорения поиска.
Документоориентированные базы данных хорошо подходят для задач, где данные имеют сложную структуру или часто меняются. Например, для каталогов товаров, профилей пользователей или систем контент-менеджмента. Кстати, в Cloud.ru есть отдельный облачный сервис Advanced Document Database Service with MongoDB для работы с документоориентированными базами.
 Преимущества использования Advanced Document Database Service with MongoDB от Cloud.ru
Преимущества использования Advanced Document Database Service with MongoDB от Cloud.ruСтолбцовые базы данных
Столбцовые базы данных — это тип NoSQL баз данных, где данные хранятся в виде колонок, а не строк, как в реляционных базах. При этом каждая колонка содержит определенный тип данных, а группируются они в семейства колонок. Это позволяет эффективно хранить и обрабатывать большие объемы данных, особенно в распределенных системах.
К самым популярным из столбцовых баз данных относятся Apache Cassandra и HBase, которые используют API или собственные языки запросов для работы с данными.
Например, основные команды на языке представления запросов CQL (Cassandra Query Language) выглядят следующим образом:
CREATE KEYSPACE: создание keyspace (аналог базы данных).
CREATE TABLE: создание таблицы.
INSERT: вставка данных.
SELECT: поиск данных.
UPDATE: обновление данных.
DELETE: удаление данных.
К преимуществам столбцовых баз можно отнести:
Быстрый поиск: если вам нужно найти данные по определенному критерию, столбцовые базы делают это мгновенно, потому что все нужные данные хранятся вместе.
Экономия памяти: если в какой-то колонке много повторяющихся значений, база данных может сжать эти данные, чтобы сэкономить место.
Масштабируемость: столбцовые базы легко масштабируются для работы с огромными объемами данных, что делает их идеальными для задач аналитики и Big Data.
Графовые базы данных
Графовые базы данных хранят данные в виде узлов (сущностей) и ребер (связей между сущностями). Каждый узел и каждое ребро могут иметь свои атрибуты (свойства).
Как это работает? Представим, что у нас есть три человека: Иван, Мария и Петр. Они дружат между собой, а также посещают определенные места. Тогда взаимосвязи между ними в графовой БД можно отобразить так:
Узлы (сущности):
Рёбра (связи):
Такая структура делает графовые базы идеальными для задач, где важно анализировать сложные связи.
К самым известным СУБД, работающим с графами относятся: Neo4j, ArangoDB, Amazon Neptune и OrientDB. Они широко используются в социальных сетях, рекомендательных системах, при анализе сетей и других областях, где важны связи между данными.
Нереляционные базы данных стали популярным решением для современных приложений, где требуется высокая производительность, гибкость и масштабируемость. Однако как и любая технология, они имеют свои преимущества и недостатки.
Преимущества NoSQL баз данных
Рассмотрим подробнее преимущества NoSQL баз данных.
Гибкость модели данных и отсутствие жесткой схемы
В отличие от реляционных баз данных, где данные должны соответствовать строго определенной схеме, NoSQL базы позволяют хранить их в различных форматах без необходимости заранее определять структуру. Это особенно полезно в ситуациях, когда структура данных часто меняется или когда данные имеют сложную вложенную структуру.
В современных приложениях данные часто меняются. Например, в социальных сетях важна возможность добавления новых полей данных. И если при работе с реляционной базой это требует изменения схемы таблиц, что может быть сложно и затратно, то NoSQL база позволяет просто добавлять новые поля в документ или запись без изменения структуры.
Также стоит отметить, что некоторые данные имеют вложенную структуру, например, JSON-документы. В реляционных базах данных такие данные приходится «размазывать» на несколько таблиц, что усложняет запросы и замедляет работу. В NoSQL базах вы можете хранить такие данные в их изначальном виде.
Масштабируемость и распределенность
Современные приложения нередко должны обрабатывать огромные объемы данных, оставаясь доступными даже при высоких нагрузках. И в решении этой задачи базы NoSQL также эффективны:
NoSQL базы поддерживают горизонтальное масштабирование, что позволяет легко добавлять новые серверы для обработки растущих объемов данных. Например, чтобы увеличить производительность Apache Cassandra, вам не нужно покупать новый более производительный сервер. Вы можете просто добавить в существующую базу еще один в кластер.
NoSQL базы данных используют распределенные системы хранения, где данные реплицируются на несколько серверов. Это обеспечивает отказоустойчивость и высокую доступность. Например, в Amazon DynamoDB данные автоматически реплицируются на несколько серверов в разных зонах доступности. Если один сервер выходит из строя, данные остаются доступны на других серверах.
Высокая производительность и доступность больших данных
Мы уже упоминали, что распределение данных между множеством серверов позволяет нереляционным БД обрабатывать миллионы запросов в секунду, а репликация данных обеспечивает их доступность даже при выходе из строя части серверов.
Помимо этого, низкие задержки при работе с NoSQL БД обусловлена рядом их архитектурных и технических особенностей:
как правило в NoSQL нет сложных операций типа JOIN, когда нужно соединить две таблицы по какой-нибудь колонке;
NoSQL базы разного типа изначально оптимизированы под определенную структуру данных: никто не будет использовать ключ-значение там, где нужны столбцы, и наоборот;
многие NoSQL базы используют оперативную память (RAM) для хранения данных, что обеспечивает чрезвычайно высокую скорость доступа.
Недостатки NoSQL баз данных
Нереляционные базы данных имеют и ряд технологических недостатков, которые могут ограничивать их использование в определенных сценариях. Их ключевые проблемы: невысокая универсальность, сниженная надежность транзакций и отсутствие стандартизированных инструментов для разработки и отладки. Рассмотрим их поподробнее.
Ограниченная поддержка сложных запросов
В сравнении с реляционными базами данных NoSQL-базы менее универсальны. Они не всегда поддерживают сложные запросы, такие как JOIN, агрегации или вложенные подзапросы:
В реляционных базах данных JOIN позволяет объединять данные из нескольких таблиц. В NoSQL базах данных, таких как MongoDB или Cassandra, такие операции либо отсутствуют, либо требуют дополнительных усилий для реализации.
Также сложности вызывает агрегация данных: например, подсчет суммы, среднего значения или группировка. В Redis, например, агрегация данных требует написания дополнительных скриптов или использования сторонних инструментов. А в Cassandra агрегационные функции ограничены и могут требовать дополнительной обработки на стороне приложения.
Сложные аналитические запросы, которые требуют обработки больших объемов данных (например работа с временными рядами) тоже затруднены в NoSQL СУБД.
Меньшая надежность транзакций в сравнении с SQL
Как уже было сказано, принцип хранения данных в NoSQL базах сконцентрирован на доступности и скорости в ущерб атомарности, согласованности, изоляции и долговечности. Из этого вытекают некоторые проблемы с надежностью транзакций — слабая изоляция, сложности с распределенным управлением и временная несогласованность данных.
Возвращаясь к аналогии с дворецким и стулом, может произойти следующее:
Грязное чтение (Dirty Read). Пока дворецкий (SQL) аккуратно складывает вещи в ящик, никто не может туда заглянуть. Со стулом все иначе. Допустим, вы испачкали футболку и хотите отнести ее в корзину для белья, но вас отвлекает телефонный звонок. Чтобы освободить руки вы кидаете футболку на стул. В этот момент ее может взять кто угодно.
Потерянные обновления (Lost Update). Такое происходит, когда две транзакции одновременно обновляют одни и те же данные, но одно из них теряется.
Неповторяемое чтение (Non-repeatable Read). Данные, прочитанные в рамках одной транзакции, могут измениться, если другая транзакция их обновит.
Указанные особенности важно учитывать при выборе базы данных для вашего проекта, особенно если вы работаете с критически важными данными или сложными данными.
Когда лучше выбирать NoSQL базы данных
Нереляционные базы данных стали мощным инструментом для современных приложений — особенно для решения задач, связанных с аналитикой, работой с большими данными и высоконагруженными системами. Они подходят для сценариев, где требуется гибкость, масштабируемость и высокая производительность и широко используются в следующих сферах:
Социальные сети. NoSQL базы данных идеально подходят для хранения и обработки данных пользователей, их связей и взаимодействий.
Стриминговые платформы. Чтобы предлагать персонализированные рекомендации, нужно сначала изучить, что нравится пользователям. Именно поэтому такие стриминговые гиганты как Netflix и Spotify используют NoSQL СУБД для хранения данных о пользовательских предпочтениях.
Финансовые технологии (FinTech). В финансовой сфере надежность и консистентность данных предельно важны. Но несмотря на недостатки концепции BASE, все-таки есть способы эффективного применения NoSQL баз в данной сфере. Например, можно использовать нереляционные базы в комбинации с традиционными SQL, применять компенсационные транзакции или двухфазные коммиты, чтобы избежать ошибок. А еще настраивать уровень согласованности данных в распределенных системах и пользоваться временными метками. Среди тех, кто хранит данные о пользователях в нереляционных базах — PayPal и Revolut.
Здравоохранение. Для хранения историй болезней, результатов анализов и других данных пациентов NoSQL базы тоже отлично подходят. Cerner, одна из крупнейших компаний в области медицинских технологий, использует с этой целью MongoDB, а Flatiron Health анализирует данные пациентов из Cassandra для борьбы с раком.
Ритейл и электронная коммерция. Когда интернет-магазин в очередной раз предлагает вам товар, от которого просто невозможно отказаться, это тоже заслуга СУБД, хранящих неструктурированные данные. Walmart использует Cassandra для хранения данных о товарах, заказах и пользователях, а eBay хранит то же самое в MongoDB. Это помогает улучшить поиск, рекомендации и даже позволяет управлять товарными запасами.
Интернет вещей. Чтобы лампочка в «умном доме» зажглась по расписанию, а датчик затопления вовремя забил тревогу, такие производители IoT-устройств и промышленных датчиков как Bosch и Siemens тоже используют нереляционные БД.
Гейм-индустрия. Чтобы прогресс не потерялся в самый ответственный момент, а премиумный танк не исчез из ангара, данные о вас, ваших достижениях и игровых процессах регулярно сохраняются в базах. Вам — приятный игровой опыт, разработчикам — монетизация и лояльность публики.
Итак, NoSQL базы данных — это отличный выбор для задач, где требуется быстрая обработка данных, масштабируемость и гибкость, но для критически важных систем с высокой нагрузкой на транзакции и сложными аналитическими запросами стоит рассмотреть реляционные базы данных или гибридные подходы.