Что такое ETL: процесс, инструменты и подходы к интеграции данных
Когда в компании много разрозненных данных из разных источников, приходится тратить усилия и время только на то, чтобы в них разобраться. Собрать информацию, привести ее в порядок и загрузить в нужное хранилище поможет ETL-процесс — основа управления данными. Из статьи вы узнаете, как он работает.


Что такое ETL
ETL — сокращение от терминов Extract, Transform, Load. Это процесс, который подразумевают извлечение данных из источников, преобразование и загрузку в базу. Он позволяет превратить разрозненную информацию в упорядоченный набор для бизнес-целей и анализа.
ETL-системы поддерживают работу с большинством структурированных и полуструктурированных форматов данных: текстовыми, числовыми, JSON, CSV, XML, Avro, Parquet. Для неструктурированных данных (графика, видео, аудио) ETL обычно извлекает метаданные или управляет путями к файлам, а непосредственная обработка контента выполняется специализированными инструментами (например, в ML-пайплайнах с использованием Python).
Разберем пример. У компании есть сведения о продажах, но они хранятся в трех разных местах: Excel-файлах из офлайн-точек, в базе интернет-магазина и в CRM, куда менеджеры ежедневно вносят информацию о сделках. Чтобы составить отчет, сведения нужно собрать вместе. Тут поможет ETL.
ETL-система скачивает Excel-файлы из папки, подключается к базе интернет-магазина, делает API-запросы к CRM — это этап извлечения (Extract). На следующем этапе преобразования (Transform) система очищает данные от дубликатов и некорректных записей, приводит их к единому формату и структуре. И только после этого, на этапе загрузки (Load), подготовленные данные помещаются в целевое хранилище. Такой подход гарантирует, что в хранилище попадают уже качественные и консистентные данные, готовые к аналитике.
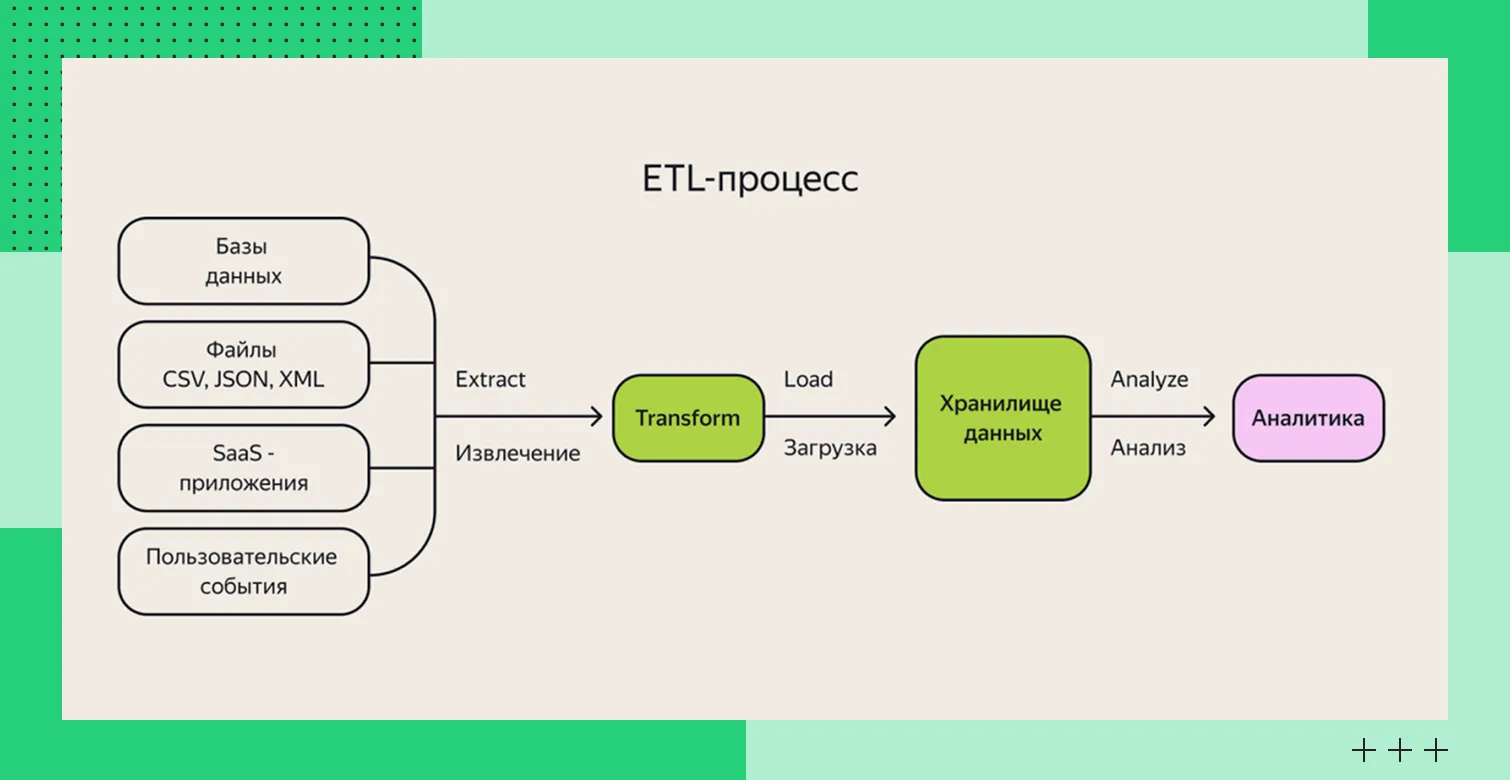 Концепция ETL
Концепция ETLКак работает ETL: этапы и описание процессов
Теперь рассмотрим этапы, о которых говорили в предыдущем разделе.
Извлечение данных (Extract)
На первом этапе идет сбор сведений из доступных источников: корпоративных баз данных, CRM и ERP-систем, веб-сервисов, файловых хранилищ, логов приложений и даже IoT-устройств. Задача — собрать информацию в первоначальном виде, ничего не упустив.
Извлечение можно выполнять разными методами: от прямых SQL-подключений до использования потоковых каналов и загрузки файлов. К единому виду информацию приводить не нужно — это происходит на следующем этапе.
Преобразование (Transform)
Далее собранные данные приводятся в порядок. Выполняется очистка от ошибок, дубликатов и некорректных значений, согласование форматов и структур, нормализация.
При необходимости сведения объединяются, агрегируются и дополняются внешней информацией. Этот этап трудоемкий — здесь сведения превращаются из разрозненных и «грязных» в единый, пригодный для анализа набор.
Преобразованная информация должна соответствовать бизнес-политикам и требованиям аналитики.

Загрузка данных (Load)
На финальном шаге преобразованные сведения загружаются в целевую систему: хранилище данных, витрину или аналитическую платформу. Загрузка может выполняться по-разному — полной перезаписью или инкрементально, когда добавляются только новые или измененные записи. По окончании процесса информация будет доступна для BI-инструментов, создания отчетов, автоматизации и любых аналитических задач.
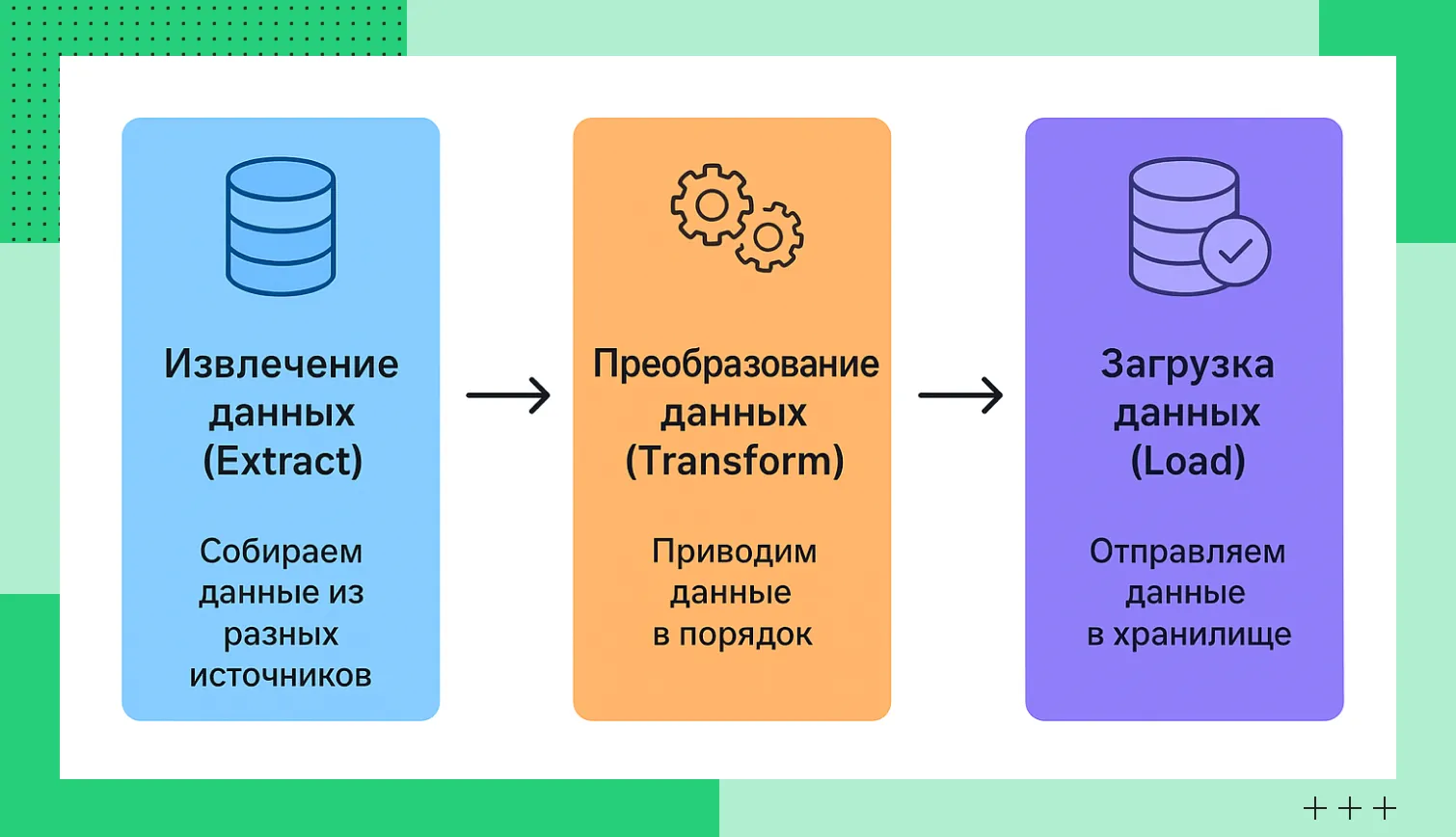 Этапы ETL
Этапы ETLИнструменты для ETL
Решения могут быть коммерческими, бесплатными и облачными. При выборе учитывайте особенности ИТ-инфраструктуры, бюджет, объемы и типы данных, требования к скорости и сложности трансформаций.
Платные ETL-системы
Коммерческие решения дают готовую инфраструктуру, официальную поддержку и стабильность, которой сложно добиться своими силами. Они позволяют быстрее запускать проекты, снижать риски ошибок и работать с большими объемами данных.
Обзор решений, которые используют российские компании:
Инструмент | Описание | Сильные стороны | Кому подходит |
Informatica PowerCenter | Одна из популярных коммерческих платформ для интеграции данных (также доступна облачная версия IICS — Informatica Intelligent Cloud Services) | Надежность, расширенный функционал, поддержка сложных корпоративных сценариев и масштабируемость | Крупные компании, банки, ритейл, телеком и проекты с большими объемами данных |
Talend Data Management (Enterprise) | Коммерческая версия Talend с расширенным функционалом и поддержкой | Разработка процессов, гибкие коннекторы, инструменты для повышения качества данных и официальная поддержка | Средний и большой бизнес, проекты, которым нужны ETL-пайплайны и контроль качества данных |
Microsoft SQL Server Integration Services (SSIS) | ETL-платформа от Microsoft, встроенная в SQL Server | Высокая скорость работы, нативная интеграция с Microsoft SQL Server и BI-экосистемой | Компании с Microsoft-инфраструктурой |
Бесплатные и опенсорсные ETL
Если есть возможность самостоятельно доработать инструмент под свои задачи, можно выбрать бесплатное решение. Вот варианты:
Инструмент | Описание | Сильные стороны | Для чего подходит |
Apache NiFi | Платформа для потоковой и пакетной обработки данных с визуальными потоками | Простая настройка, гибкое управление потоками, низкая задержка при потоковой передаче данных и гарантия доставки | Стриминг, интеграция между системами, маршрутизация данных и IoT-сценарии |
Pentaho Data Integration (Kettle) | Одна из самых известных бесплатных ETL-платформ с широкими возможностями трансформации данных | Готовые коннекторы, визуальный редактор, развитое сообщество поддержки | Классические ETL-процессы, миграция данных, построение пайплайнов для BI |
Apache Airflow | Оркестратор рабочих процессов (workflow orchestrator), позволяющий описывать ETL-пайплайны в виде направленных ациклических графов (DAG) на языке Python | Гибкость, автоматизация, управление зависимостями и развитая экосистема | Сложные пайплайны, автоматизация преобразований, интеграция с облачными решениями |
Meltano | Современная open source-платформа на базе Singer-коннекторов | Масштабируемость, интеграция с аналитическими инструментами | Аналитика и срочные проекты |
Apache Spark | Единый движок для пакетной и потоковой обработки больших данных | Высокая производительность, встроенные API для ETL/ELT на Scala, Python, SQL; поддержка потоковой обработки (Spark Streaming) и машинного обучения (MLlib) | Обработка больших данных (Big Data), high-performance ETL, объединение пакетной и потоковой обработки |
Evolution Managed Spark | Управляемый облачный сервис для развертывания кластеров Spark | Автоматическое развертывание и масштабирование кластеров, интеграция с облачной инфраструктурой, отсутствие необходимости в ручном администрировании серверов | Компании, которые хотят использовать Spark для ETL, трансформаций и аналитики без управления собственной инфраструктурой |
dbt (data build tool) | Инструмент для трансформации данных по методологии ELT | SQL-ориентированный подход, управление зависимостями, автоматическая документация, тестирование данных, активное сообщество | Трансформация данных в облачных хранилищах (Snowflake, BigQuery, Redshift), modern data stack |
Облачные ETL-платформы
Облачные платформы подходят компаниям, которые хотят запускать процессы интеграции данных без сложной локальной инфраструктуры. Они упрощают подключение разных источников, автоматизируют подготовку информации и справляются с нагрузкой по мере роста объемов. Кроме того, платформы снижают затраты на эксплуатацию и освобождают команду от ручной поддержки серверов.
Описание популярных решений:
Инструмент | Описание | Сильные стороны | Для чего подходит |
AWS Glue | Платформа от Amazon для построения ETL/ELT-процессов | Автоматическая подготовка данных, интеграция с сервисами AWS и масштабирование без работы с серверами | Big Data, автоматизация загрузок, подготовка данных для аналитики и Data Lake в AWS |
Azure Data Factory | Облачный сервис Microsoft для интеграции и оркестрации данных | Встроенные коннекторы, создание пайплайнов, интеграция с SQL Server, Synapse и Power BI | Гибридные и облачные ETL/ELT-процессы, корпоративная интеграция и решения в экосистеме Azure |
Google Cloud Dataflow | Платформа потоковой и пакетной обработки данных на базе Apache Beam | Работа со стримингом, автоматическое масштабирование, высокая производительность и интеграция с BigQuery | Стриминг-аналитика, real-time ETL и обработка больших объемов данных |
Snowflake | Облачная платформа данных (Data Cloud) с разделением хранения и вычислений | Поддержка ELT-подхода, мощная обработка полуструктурированных данных (JSON, Avro, Parquet), независимое масштабирование, интеграция с экосистемой данных | Data Warehouse, Data Lake, ELT-процессы, работа с большими объемами данных в облаке |
Evolution Managed BI | Подключение к различным источникам данных (Microsoft SQL Server, MySQL, PostgreSQL и др.), создание интерактивных дашбордов, графиков и диаграмм, отсутствие необходимости управлять инфраструктурой | BI-аналитика, визуализация данных из ETL-пайплайнов, построение отчетности для бизнес-пользователей |
Преимущества и недостатки ETL-процессов
ETL-процессы помогают бизнесу, но недостатки у них есть. В таблице перечислили их вместе с преимуществами, чтобы было проще взвесить «за» и «против».
Преимущества | Недостатки |
Повышение качества данных. Сведения очищаются, структурируются и приводятся к единому формату, поэтому с ними удобно работать. | Потребность в ресурсах. Для стабильной работы нужны мощности, хранилище и поддержка. |
Объединение данных в одном месте. Компания получает единый, согласованный источник актуальных сведений. | Долгая обработка. Из-за больших объемов данных загрузка длится дольше. |
Преобразование информации. Можно адаптировать структуру и логику под задачи бизнеса. | Сложная адаптация под изменения. Любой новый источник требует доработки. |
Автоматизация рутины. Процессы загружают данные по расписанию и снимают рутинную работу с сотрудников. | Задержки при пакетной обработке. Традиционные пакетные (batch) ETL-процессы обновляют данные по расписанию, что может не подходить для задач, требующих near real-time аналитики. Хотя существуют потоковые (streaming) ETL-решения, они сложнее в проектировании и поддержке. |
Работа с большими объемами информации. Обработка оптимизирована под растущие потоки сведений. | Зависимость качества обработки от исходных данных. Некоторая информация требует специальных фильтров. |
ETL-процессы дают компаниям контроль над качеством и структурой данных, позволяют объединять информацию из разных источников и автоматизировать рутинные задачи. Однако они требуют значительных ресурсов, а традиционные пакетные реализации вносят задержки в обновление данных, что может не подходить для задач, чувствительных к актуальности информации.
Применение ETL
Чтобы данные приносили пользу бизнесу, их нужно не просто собирать из разных источников, но и объединять. Это как раз делают ETL-процессы. Они помогают компаниям получать целостную картину и ускорять аналитику. Примеры применения:
Объединение данных из разных систем. Сбор информации из CRM, ERP, бухгалтерии, кадровых и других источников в единое хранилище.
Создание корпоративного хранилища данных. Подготовка сведений для перемещения в хранилища, где они становятся структурированными, согласованными и готовыми для аналитики.
Автоматизация отчетов и аналитики. Получение регулярных обновлений данных и готовых витрин для BI-инструментов вместо ручного экспорта и сводных таблиц.
Работа с большими данными. Обработка значительных объемов разной информации — от логов и телеметрии до транзакций и событий.
Миграция данных между системами. Перенос информации корректно и без потерь в момент перехода на новые приложения или базы.
Обогащение данных. Добавление внешних атрибутов в процессе преобразования информации, например, классификации, геометок, справочников, вычисляемых полей.
Подготовка информации для машинного обучения. Очищение, нормализация и структурирование данных, превращение «сырых» наборов в качественные датасеты.
Мониторинг качества информации. Выявление ошибок, дубликатов и несогласованности, обеспечение надежности аналитики и отчетности.
Внедрение ETL-процесса: пошаговый план
Внедрение ETL — это полноценный проект, который начинается с выстраивания бизнес-целей и заканчивается вводом выбранных решений в эксплуатацию. Подходите к делу системно и учитывайте все — от планирования и выбора архитектуры до тестирования, контроля качества и поддержки.
Этап внедрения | Описание | Что учитывать |
Формулировка целей и требований | Определите, зачем вам ETL и какие бизнес-задачи будут решаться. Например, формирование отчетов, аналитика или консолидация данных | Опишите, какие сведения нужны и из каких источников. Подумайте, как часто будет обновляться информация, с какими требованиями к качеству и скорости |
Инвентаризация источников данных | Составьте полный список источников: базы данных, CRM, ERP, файлы и логи, внешние API и др | Проверьте доступность источников, объемы и формат данных. Это поможет избежать «сюрпризов» на следующих шагах |
Проектирование архитектуры и потоков данных | Спроектируйте, как данные будут извлекаться, каким образом трансформироваться и куда попадут в результате | Выбирайте подходящую ETL -схему. Подумайте об оркестрации, масштабируемости и производительности |
Выбор инструментов и инфраструктуры | Решите, будете использовать открытое ПО (open-source), облачные сервисы или коммерческие ETL-платформы | Оцените нагрузку, бюджет, требования к скорости, гибкости и поддержке. Убедитесь, что решение впишется в ИТ-экосистему |
Реализация ETL-конвейеров | Опишите такие процессы, как извлечение, очистку, трансформацию и загрузку. Настройте staging-зоны, правила очистки, логику преобразований | Обеспечьте логичную структуру: модульность, понятные шаги, документацию и контроль версий |
Тестирование и валидация | Проверьте, что данные корректно извлекаются, преобразуются и загружаются. Продумайте возможные ошибки и сценарии их устранения | Обязательно протестируйте корректность, консистентность, производительность, устойчивость к сбоям. Настройте мониторинг и логирование |
Развертывание и запуск в продакшен | Переведите ETL-процессы в рабочее состояние: по расписанию или триггеру. Мониторьте регулярность и стабильность | Убедитесь, что процессы работают стабильно. Проверьте, получаете ли уведомления об ошибках и метрики успеваемости |
Поддержка, оптимизация и масштабирование | Со временем объемы данных растут, а требования меняются. ETL-система должна к этому адаптироваться | Внедрите проверку качества данных, возможность incremental-загрузок, параллельную обработку и мониторинг. Дорабатывайте логику по мере роста задач |
Альтернативы и дополнения к ETL
ETL долгое время был стандартом для интеграции данных. Однако с ростом объемов информации, развитием облачных платформ и потребностью в скорости появились новые подходы, дополняющие классический.
ELT (Extract, Load и Transform)
ELT — альтернативный архитектурный подход, который отличается последовательностью операций. В отличие от классического ETL, где данные преобразуются до загрузки, в ELT данные сначала загружаются в целевую систему в «сыром» виде, а трансформация выполняется уже внутри хранилища. Это стало возможным благодаря современным облачным хранилищам с мощными вычислительными ресурсами (Snowflake, Google BigQuery, Amazon Redshift).
Преимущества ELT:
Быстрая загрузка больших объемов данных благодаря их минимальной предварительной обработке.
Использование мощностей хранилища для трансформаций информации.
Гибкость аналитики, поскольку можно создавать новые модели данных без изменения процесса ETL.
Упрощение архитектуры данных, так как нет необходимости в отдельном ETL-сервере для обработки информации перед загрузкой.
Поддержка разнообразных источников, загрузка структурированных, полуструктурированных и неструктурированных данных.
Простая масштабируемость, особенно в облачных решениях, где мощность можно увеличивать согласно потребностям.
Ускорение получения аналитической информации, поскольку данные сразу доступны в хранилище.
Повышение качества информации, поскольку преобразование можно проводить централизованно в хранилище по единым стандартам обработки.
Возможность применения продвинутой аналитики и машинного обучения для работы с данными.
Снижение затрат на управление отдельной ETL-инфраструктурой, особенно в облачных средах с разделением вычислений и хранения (например, Snowflake, Google BigQuery, Amazon Redshift), где можно масштабировать вычислительные ресурсы независимо от хранения.
ETL предполагает трансформацию сведений до загрузки, ELT — после. Эта концепция подходит для облачных платформ и хранилищ больших данных.
Виртуализация данных
Виртуализация — технология, которая позволяет создавать единое логическое представление информации из разрозненных источников без ее физического перемещения или дублирования. Пользователи и приложения могут работать с виртуализированными данными так, будто они находятся в одном месте, хотя источники остаются независимыми.
Система виртуализации подключается к базам данных, хранилищам и внешним сервисам. Сведения остаются в исходных системах, но создается слой, который объединяет их в единое представление. Пользователи и аналитические приложения получают доступ к информации через этот слой с помощью привычных запросов (SQL, API и т.д.).
Преимущества виртуализации данных:
Мгновенный доступ к данным. Нет необходимости ожидать ETL-процессов, потому что сведения из разных источников доступны сразу.
Снижение затрат на хранение и репликацию. Данные не копируются в отдельное хранилище, что экономит место. Однако важно понимать, что это преимущество достигается за счет переноса нагрузки на исходные системы-источники: каждый аналитический запрос выполняется непосредственно к CRM, ERP или другим операционным базам. При интенсивном использовании это может потребовать дополнительной оптимизации производительности источников.
Возможность объединять данные в реальном времени для аналитики и отчетности. Можно строить отчеты и дашборды на актуальных показателях без задержек.
Снижение сложности интеграции. Не нужно создавать отдельные пайплайны для каждого источника, поскольку виртуализация объединяет их на логическом уровне.
Поддержка разнообразных источников данных. Через единый логический слой будут доступны локальные базы, облачные хранилища, API и каталоги.
Повышение безопасности и контроля доступа. Можно задавать права на уровне виртуализированных представлений, не затрагивая исходные данные.
Гибкость и масштабируемость. Можно подключать новые источники данных или изменять модели представления без влияния на существующие процессы.
Чем сложнее инфраструктура, тем заметнее выгода от виртуализации данных.
Потоковая обработка (стриминг)
Стриминг данных — метод обработки информации в реальном времени. События и данные обрабатываются по мере поступления, а не после того, как накопятся. Информация непрерывно поступает из разных источников: сенсоров, веб-сервисов, логов приложений и др. Система стриминга обрабатывает события на лету: фильтрует, агрегирует, трансформирует и анализирует. Результаты передаются в аналитические системы, дашборды, уведомления или хранилища данных.
Преимущества потоковой обработки:
Мгновенная аналитика и реакция на события. Можно принимать решения в реальном времени, например, реагировать на подозрительные действия пользователей.
Обработка больших объемов данных без задержек. Системы потоковой обработки справляются даже с высокочастотными событиями.
Гибкая интеграция с разными источниками и хранилищами. Можно получать события с IoT-устройств, веб-приложений, баз данных и облачных сервисов.
Снижение необходимости в массивных промежуточных хранилищах. Данные обрабатываются по мере поступления, что уменьшает потребность в накоплении больших объемов «сырых» данных. При этом для обеспечения надежности, возможности повторной обработки и отказоустойчивости события обычно сохраняются в распределенном журнале (например, Apache Kafka).
Поддержка сложной аналитики и машинного обучения. Можно строить модели прогнозирования, детектировать аномалии и давать персонализированные рекомендации «на лету».
Автоматизация процессов и уведомлений. На основе потоковых данных можно автоматически запускать рабочие процессы или уведомлять пользователей о критических событиях.
Масштабируемость и отказоустойчивость. Современные платформы потоковой обработки (например, Apache Kafka, Apache Flink и Spark Streaming) легко масштабируются и работают при высоких нагрузках.
Стриминг позволяет выявлять проблемы до того, как они становятся инцидентами.
Заключение
Компании стремятся повысить ценность данных и ускорить принятие решений. В этом помогут технологии, которые обеспечивают доступность и актуальность информации. ETL-процессы дают фундамент, ELT ускоряет обработку больших объемов, виртуализация снижает затраты, а стриминг помогает реагировать на события в реальном времени. Оптимально не выбирать что-то одно, а комбинировать подходы, создавая архитектуру, которая будет развиваться вместе с бизнесом.