Big Data: что это, где применяется и как работать с большими данными в облаке
Соцсети, мессенджеры, IoT-устройства, банковские транзакции и даже умные дома генерируют терабайты информации ежедневно. Эти огромные массивы информации, а также технологии их обработки, то есть большие данные (Big Data), нужны бизнесу, чтобы принимать обоснованные решения.
В этой статье поговорим про Big Data: расскажем о характеристиках, принципах и методах работы с большими данными в облаке.


Что такое Big Data
BigData — это огромные массивы структурированных и неструктурированных данных, из которых сложно извлекать пользу традиционными методами, а также технологии работы с ними, которые как раз и позволяют обрабатывать такой масштабный объем информации.
Как же понять, что ваша data — big? Критерии очень зыбки. Изначально, в 2001 году аналитик Даг Лейни ввел три ключевых критерия таких данных: Volume, Velocity и Variety. Позднее стало понятно, что этого недостаточно, и пора выделить дополнительные признаки. Так сформировалась «концепция 6V», которой должна соответствовать информация, чтобы считаться BigData:
Volume, или объем. А много — это сколько? Специалисты по работе с данными договорились, что это точно больше 8 Гб (столько обычно помещается в оперативной памяти стандартного компьютера) и даже, вероятнее всего, больше 150 Гб — эта цифра часто упоминается в технических статьях и отраслевых курсах. Впрочем, обе эти цифры — скорее не стандарт, а практический ориентир, продиктованный тем, что обычно после этой отметки традиционные базы данных начинают «тормозить». На деле же для малого бизнеса биг датой можно назвать и 50 Гб в день, а для крупной транснациональной корпорации — и зеттабайта будет мало.
Variety, или разнообразие. Информация должна быть разнородной, это может быть, что угодно — текст, видео, логи. Главное, чтобы данные в массиве были согласованы.
Velocity, или скорость. Данные должны обновляться быстро и в реальном времени, чтобы оставаться актуальными.
Variability, или изменчивость. На такую информацию сильно влияет контекст, который необходимо учитывать: время суток, погода, сезон.
Veracity, или достоверность. Чтобы из данных можно было извлечь реальную пользу, они должны соответствовать реальности. Однако в датасет нередко проникает «мусор»: ошибки ручного ввода, результаты некорректной работы датчиков, дубликаты, пропущенные при заполнении поля и просто фейки. Поэтому крайне важно прежде, чем анализировать что-то на основе BigData, убедиться в чистоте данных.
Value, или ценность. Это, пожалуй, основной критерий: собранная информация должна способствовать извлечению практической пользы в различных сферах жизни. Например, соцсеть хранит данные о движениях мыши каждого пользователя и технически — это BigData, но если компании эти данные не нужны для достижения бизнес-целей или их хранение обходится слишком дорого, они избыточны.
Итак, чтобы считаться Big Data, данные должны соответствовать хотя бы некоторым, а в идеале всем критериям выше. Рассмотрим на примерах, что можно и нельзя считать большими данными.
 Различия между массивом данных и Big Data
Различия между массивом данных и Big DataКраткая история и развитие концепции больших данных
Критическая потребность в «укрощении» больших данных возникла в 60-80-х годах XX века. Например, в 1960-ом в США проводили перепись населения, используя для обработки данных передовые технологии того времени: перфокарты, магнитные ленты и ЭВМ, которые занимали целые комнаты. Уже в 70-х прогресс шагнул чуть дальше и появилась возможность пользоваться для хранения первыми HDD-дисками, стали появляться первые хранилища данных. Важной вехой стало возникновение первых реляционных баз данных, однако скорости их работы оставляли желать лучшего. А в 80-90-х стали появляться первые попытки распараллелить вычисления на несколько процессоров или использовать много компьютеров в сети для работы с данными.
Однако поворотной точкой в истории BigData стали нулевые, когда интернет и соцсети начали генерировать огромные объемы данных. В 2004 году корпорация Google для обработки крупных объемов данных предложила подход MapReduce — технологию для параллельной обработки больших данных на кластерах серверов. То есть MapReduce позволяла разбить задачу на части:
Map — распределял данные между множеством компьютеров.
Reduce — собирал и объединял результаты.
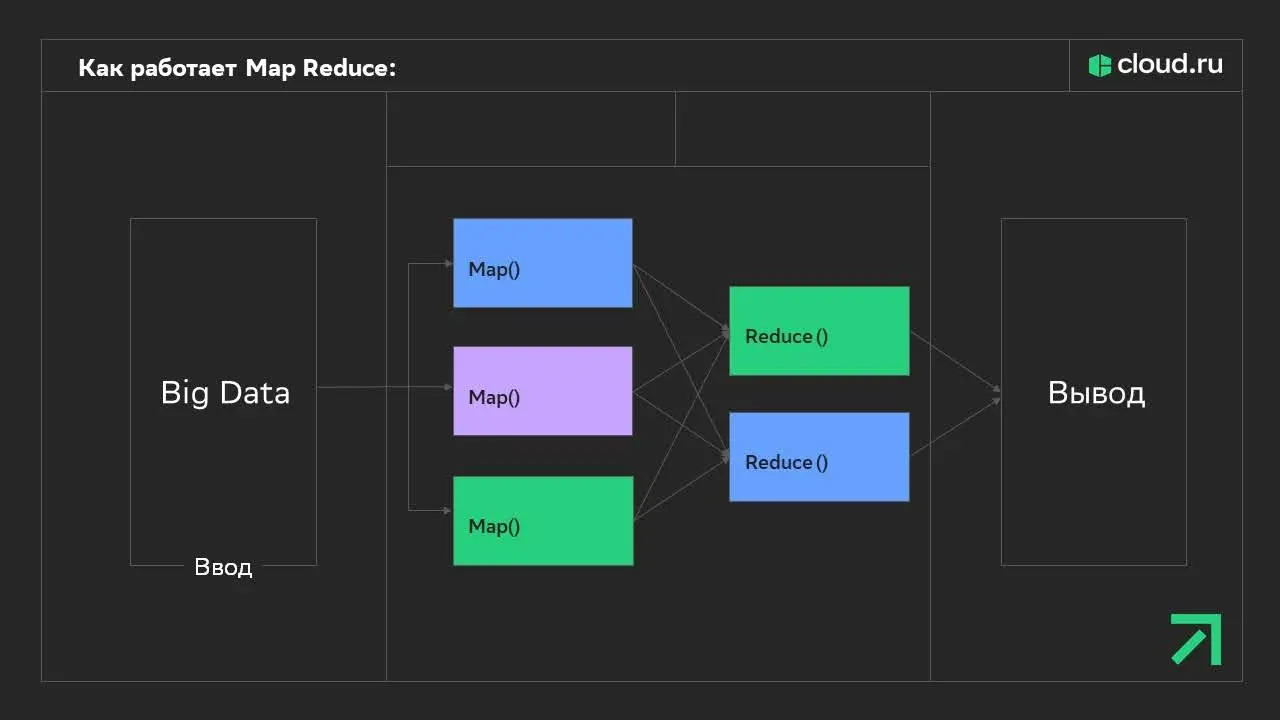 Принцип работы MapReduce
Принцип работы MapReduceЧисло рабочих узлов при таком подходе можно увеличивать как угодно: это дает возможность работать со впечатляющими массивами данных. Изменения произошли и в подходе к хранению данных: в дополнение к MapReduce Google создала GFS — распределенную файловую систему для эффективной работы с быстро растущим количеством данных. Позднее, вдохновившись наработками Google, Yahoo! создала Hadoop — платформу с открытым исходным кодом, позволяющую распределять данные для анализа по кластерам компьютеров.
В 2008 году термин «бигдата» впервые употребил профессор Школы информации Беркли Клиффорд Линч. С тех пор данные и способы извлечь из них пользу множились, однако весь потенциал BigData не раскрыт до сих пор.
Принципы работы с большими данными
Работа с большими данными — процесс комплексный: их нужно извлечь из источников, направить на хранение, обработать и придумать способы анализа для достижения конкретных целей. Инструменты и методы могут быть разными, но главными принципами для любого крупного BigData-проекта являются:
Горизонтальная масштабируемость. Рост производительности обеспечивается за счет добавления новых вычислительных единиц, а не апгрейда. Данных стало в 10 раз больше? Значит понадобится 10 серверов, а не один в 10 раз мощнее.
Распределенная обработка. Чтобы быстро и эффективно съесть слона, нужно поделить его на кусочки и есть параллельно. Есть 1000 документов и 10 серверов? Пусть каждый обработает по 100 документов.
Отказоустойчивость. Чтобы при падении одного сервера, вся работа не оказывалась под угрозой, данные и задачи должны дублироваться. Для этого каждый блок данных хранится в нескольких копиях на разных машинах.
Есть и условно-обязательные принципы: их соблюдение рекомендуется, но не во всех проектах они строго обязательны:
Близость данных. Если код выполняется на одном сервере, а данные лежат на другом, могут возникнуть перегрузки и задержки в самой сети. И то, и другое существенно влияет на скорость всей системы (например, как в случае с Hadoop). Именно поэтому запускать задачи лучше на тех же серверах, где находятся данные, или как можно ближе к ним.
Разделение хранилища и вычислений. Этот принцип гласит, что сама вычислительная единица (Compute) и хранилище (Storage) должны представлять из себя два независимых слоя общей системы, которые масштабируются и управляются раздельно. Это необходимо для большей гибкости, экономии ресурсов и повышения отказоустойчивости.
Если бы процессы хранения и вычисления не были разделены, это выглядело бы примерно так: библиотекари живут прямо в библиотеке и не могут отходить от вверенных им полок в другие отделы. Даже если сейчас в секторе нет другой работы, а в библиотеку поступили новые книги, на работу с которыми еще не наняли нового сотрудника.
Пакетная и потоковая обработка. Задачи должны быть разделены на те, которые обрабатываются за раз в определенный период, и на те, что анализируются в реальном времени. Например, банковское приложение накапливает и анализирует категории трат, чтобы в конце месяца выдать пользователю отчет о том, сколько потрачено на маркетплейсах, а сколько — в супермаркетах. Но если деньги на сберегательных счетах этого пользователя будут внезапно пересланы незнакомому адресату, банк заблокирует операцию мгновенно, потому что фрод-детектор обрабатывает данные транзакций «на лету».
Этапы и инструменты для работы с большими данными
Для эффективной работы с Big Data используется обширный набор специализированного ПО и технологий. Рассмотрим сам алгоритм, а также софт и подходы, которые используются на каждом этапе взаимодействия с данными.
Сбор
На этом этапе нам важно получить данные из разных источников по заданным параметрам, прежде всего по актуальности. В качестве источников может выступать что угодно:
Интернет — информация с сайтов, социальных сетей, онлайн-сервисов. Сюда входят геолокация, запросы, хештеги, фото, видео, файлы cookie.
Статистика — демографические, экономические, социологические и иные сведения, которые собирают государственные органы и исследовательские центры.
Банковские данные — сведения об операциях в банковских и платежных сервисах.
Технические данные — например, данные из умных устройств, датчиков сотовой связи, камер видеонаблюдения.
Информация может поступать из внешних источников, например, официальных API сервисов (с помощью REST API, GraphQL, Apache Nutch или Scrapy) или внутренних ресурсов и систем (через Kafka, Sqoop), пакетами раз в определенный период (Apache Sqoop, AWS Glue/Azure Data Factory, Spark JDBC) или непрерывным потоком (Apache Kafka, Fluentd/Logstash, AWS Kinesis/Google PubSub, Mosquitto). Выбор конкретного ПО зависит от формата данных, требований к задержке и инфраструктуры.
Собранная информация проходит Data Cleaning — проверку на достоверность. Если обнаружится ненужная или ложная информация, она будет отсечена.
Хранение
Отсортированная информация размещается в распределенных хранилищах и на специальных облачных серверах. Для хранения BigData используются следующие подходы и практики:
1. Распределенные файловые системы
Предназначены для хранения неструктурированных и полуструктурированных данных (логи, JSON, видео, аудио, изображения).
Примеры технологий:
HDFS (Hadoop Distributed File System) — стандарт для хранения данных в экосистеме Hadoop.
Amazon S3, Google Cloud Storage — облачные объектные хранилища.
К их преимуществам можно отнести:
Масштабируемость (можно добавлять узлы).
Отказоустойчивость (данные реплицируются).
Поддержку потоковой обработки.
2. NoSQL-базы данных
Незаменимы для работы с разнородными, быстро меняющимися данными, где реляционные СУБД неэффективны.
NoSQL-базы бывают следующих типов:
Документные (MongoDB, Couchbase) — для JSON, XML.
Колоночные (Cassandra, HBase) — аналитика, временные ряды.
Ключ-значение (Redis, DynamoDB) — кэширование, сессии.
Графовые (Neo4j) — соцсети, рекомендации.
Их преимущества:
Горизонтальное масштабирование.
Гибкость схем (не требуют строгой структуры).
3. Data Warehouse (DWH)
Хранят структурированные данные для аналитики и бизнес-отчетности. В отличие от других подходов, оптимизированы для сложных запросов (агрегация, JOIN) и поддерживают ETL-процессы (извлечение, трансформация, загрузка).
Примеры:
Snowflake — облачное DWH с разделением вычислительных ресурсов и хранилища.
Google BigQuery — serverless-аналитика.
Teradata, Vertica — корпоративные решения.
К их преимуществам можно отнести:
Высокую скорость обработки запросов.
Интеграцию с BI-инструментами (Tableau, Power BI).
4. Специализированные и гибридные решения
Вобрали в себя комбинацию разных подходов для сложных сценариев.
Примеры:
Data Lakehouse (Delta Lake, Apache Iceberg) — объединяет возможности Data Lake и DWH: хранит сырые данные (как Data Lake), но поддерживает транзакции и ACID (как DWH).
Гибридные СУБД (PostgreSQL + расширения для JSON/временных рядов).
In-Memory системы (Apache Ignite) — для высоконагруженных операций.
В числе преимуществ:
Универсальность (подходят для смешанных нагрузок).
Снижение затрат (не нужно развертывать отдельные системы).
Анализ
Это основной этап работы с Big Data. Его проводят с помощью нейросетей и языка запросов SQL.
Для анализа данных используют разные способы, например:
сплит-тестирование — сравнение двух вариантов массива информации;
машинное обучение — AI задают поток данных без систематизации, чтобы он выработал для себя новые навыки;
анализ сетевой активности — изучение владельцев аккаунтов, участников групп в соцсетях, взаимоотношений между ними.

Достоинства Big Data
Рассмотрим основные плюсы работы с большими данными.
Больше возможностей в принятии решений. Работа с Big Data позволяет получить полную картину происходящей ситуации, установить в ней логические связи и закономерности. Так можно выработать эффективные стратегии и сделать точные прогнозы еще до принятия решения. Например, через анализ больших данных можно выявить факторы, из-за которых растут затраты компании. А значит, бизнес может устранить эти расходы и оптимизировать бюджет.
Быстрое решение проблем. Обработка больших данных позволяет оперативно выявить неисправность, сбой или другую нештатную ситуацию в инфраструктуре. Без этой технологии пришлось бы изучать причины проблем вручную. На основе анализа собранной Big Data бизнес может определить возможные инфраструктурные риски и подготовиться к ним заранее.
Понимание клиента. Один из типов биг даты — сведения обо всех действиях клиентов. С их помощью тот, кто работает с Big Data, может составить примерный портрет целевой аудитории, который пригодится для дальнейшего предложения товаров, услуг и увеличения продаж.
Проблемы Big Data
Есть у технологии больших данных и слабые места, о которых тоже нужно знать.
Риски для конфиденциальности. Хранилища с данными о клиентах и их действиях могут стать объектом хакерской атаки или утечки. Например, эти ситуации могут происходить из-за действий конкурентов или недобросовестных сотрудников. Поэтому, если компания работает с Big Data, она должна защитить сервер, на котором работают большие данные.
Качество и надежность данных. Big Data содержит много информации, поэтому велик риск включения ложных, неточных или противоречивых данных. Специалистам нужно тщательно проверять собираемую информацию на точность и истинность. Например, контролировать вид и длину таблиц, дату редактирования и количество строк.
Стоимость и сложность инфраструктуры. Инфраструктура для Big Data стоит дорого, поскольку для работы нужны объемные хранилища и мощные процессоры. Перед внедрением этой технологии компании нужно рассчитать бюджет. Важно учесть, что количество данных со временем будет расти, поэтому инфраструктуру придется расширять.
Где используют Big Data
Перечислим сферы деятельности, где работают с большими данными.
Социальные медиа. Анализ Big Data помогает рекомендовать пользователям контент на основе их предпочтений, истории чтения и просмотров. Например, так работают алгоритмы Youtube.
Маркетинг. Big Data используют в получении портрета покупателя или пользователя услуг, чтобы узнать его «боли» и пути их закрытия. Другие задачи, решаемые большими данными в маркетинге — анализ рынка, прогноз рыночной ситуации и динамики цен, проработка рекламных кампаний.
Медицина. Изучение больших данных позволяет предсказывать эпидемии и распространение неинфекционных заболеваний, разрабатывать стратегии профилактики и лечения болезней. Например, во время пандемии коронавируса в 2020–2022 годах были собраны данные о заболеваемости коронавирусом: часть из них доступна на Стопкоронавирус.рф и других ресурсах.
Транспорт и логистика. С помощью анализа «больших данных» можно узнать, какие маршруты наиболее удобны и наименее затратны. Это оптимизирует городскую инфраструктуру и перевозку пассажиров и грузов. Например, технология Big Data встроена в сервисы навигации и такси.
Наука. С помощью Big Data ученые создают новые технологии, прогнозируют и прорабатывают условия экспериментов.
Промышленность. С помощью «больших данных» оптимизируют производство, прорабатывают технику безопасности для предотвращения опасных ситуаций, управляют механизмами поставок.
Подбор и управление персоналом (HR). Big Data помогает определить профиль подходящего кандидата, где за основу берутся характеристики успешных соискателей. Также анализ данных используют в планировании рабочего графика сотрудников. Например, МТС использует большие данные в мероприятиях по оптимизации нагрузки на сотрудников, а Google — в сокращении текучки кадров.
Образование. Анализ больших данных применяют, чтобы получить примерные «портреты» будущих студентов и разработать образовательные программы. Еще Big Data собирает данные о студентах, не справляющихся с учебой, и причинах их низкой успеваемости. Поэтому с этой технологией преподаватели вовремя замечают проблемы у студента и принимают меры по их решению или улучшению учебного процесса. Проекты, использующие Big Data, есть в британском университете Ноттингем Трент и американских университетах Пердью и Карнеги-Меллона.
Банки. Финансовые и кредитные организации тоже используют технологию Big Data, чтобы составить примерный портрет клиента. Это помогает подбирать актуальные условия услуг, например, кредитования. Также помощью больших данных собирают данные о случаях и схемах мошенничества. На их основе сотрудники банков составляют рекомендации клиентам, чтобы они избежали обмана. А еще банки собирают сведения об атаках хакеров, чтобы вырабатывать меры по защите банковской системы.
Государственное управление. Органы власти собирают Big Data для анализа экономических, социологических и других процессов в обществе. Они составляют прогнозы развития жизни населения и вырабатывают стратегии по решению возможных проблем.
Искусственный интеллект. Нейросети, рисующие картинки или пишущие тексты, постоянно учатся на тысячах существующих изображений и написанных постах и статьях из Big Data.
Кто работает с Big Data
В работе с Big Data участвуют три основных вида специалистов.
Инженер Big Data. Этот человек занимается организацией инфраструктуры Big Data, чтобы она могла собирать данные, а другие специалисты смогли проводить дальнейшую работу с ними. Он настраивает автоматизированный сбор данных в хранилище и их движение по инфраструктуре, занимается их структурированием и очищением от ошибок. Дата-инженер должен знать инструменты Big Data и базы данных SQL, а еще разбираться в облачных технологиях.
Аналитик Big Data. Это специалист, работающий с Big Data. Аналитик Big Data выбирает источники и собирает данные, проводит их анализ с помощью различных аналитических способов, делает выводы на основе собранной информации. Аналитику Big Data нужно владеть такими языками программирования как Python, Java, Go и методами логического анализа.
Big Data Scientist. Обязанности этого специалиста похожи на обязанности дата-аналитика. Но, вместе с этим, дата-сайентист проводит машинное обучение нейросетей, делает выводы и формирует рекомендации для бизнеса. Дата-сайентисту нужны базовые навыки программирования, логического анализа и работы с ИИ.
 Кто работает с Big Data
Кто работает с Big DataНа самом деле, количество ролей при работе с Big Data не ограничивается тремя перечисленными: некоторые команды насчитывают до 11 разных должностей, связанных со сферой.
Будущее Big Data
В будущем объем больших данных будет только расти. К 2025 году объем всех таких данных может составить от 163 до 175 зеттабайт. Если в минувшее десятилетие рост базы данных обеспечило увеличение числа пользователей интернета, то в дальнейшем он будет происходить за счет данных бизнеса и систем мониторинга, а также увеличения числа источников данных — IoT, нейросетей.
Из-за роста данных совершенствуются системы их хранения и обработки. Ожидается, что еще чаще будут использоваться облачные хранилища, сервисы машинного обучения, нейросети.
Облачные хранилища делают работу с большими данными менее затратной. Они более выгодны для бизнеса, чем собственные серверные для хранения. Например, у Сloud.ru тариф хранилища стартует от 630 рублей в месяц. Еще, если хранить данные в облаке, провайдер обеспечивает сохранность информации, а также позволяет анализировать и обрабатывать их быстрее за счет предоставляемых мощностей.
Для работы с Big Data в Cloud.ru доступны следующие сервисы:
Evolution Managed Spark. Сервис на основе Apache Spark для распределенной обработки структурированных, полуструктурированных и неструктурированных данных.
Evolution Managed Trino. Высокопроизводительный SQL-движок для аналитики данных в реальном времени. Поможет объединить данные из разных источников и построить быструю интерактивную аналитику.
Advanced Data Lake Insight (DLI). Служба для обработки данных в Data Lake, которая не требует предварительной структуризации данных.
Advanced Data Warehouse Service (DWS). Управляемое, высокопроизводительное решение для хранения и анализа структурированных данных. Будет полезно для BI-анализа и построения красивых визуализаций, например, через DataArts Insight.
Evolution Managed ArenadataDB. СУБД на основе Greenplum для масштабируемых аналитических задач, обеспечивает высокоскоростную аналитику для BI.
Evolution Managed Metastore. Хранилище метаданных для связанных сервисов (например, Spark, Trino). Помогает централизованно управлять описаниями таблиц, схем и источников данных и упрощает интеграцию между другими сервисами.
Evolution Object Storage. Объектное хранилище для хранения сырых данных любого типа с доступом через S3-совместимый API, есть как на платформе Evolution, так и в составе сервисов Advanced.
Кратко про возможности Сloud.ru при работе с большими данными:
для хранения сырых данных — Object Storage;
для обработки и анализа — Spark или Trino;
в качестве хранилища для BI — DWS или ArenadataDB;
для метаданных — Metastore.
Коротко о Big Data
Понятие Big Data включает в себя массивы данных, созданные в процессе деятельности человека, и технологии работы с ними.
Большие данные используют в маркетинге, науке и других сферах деятельности. Работа с Big Data помогает принимать правильные решения, выявлять и избегать рисков, ускорять работу с информацией.
В дальнейшем объем больших данных во всем мире будет только расти. Для работы с ними уже активно используются облачные хранилища, нейросети и сервисы машинного обучения. Источником больших данных могут быть как обычные пользователи, так и субъекты бизнеса.