RAG: как ИИ получает доступ к актуальным данным
Большие языковые модели умеют генерировать связные тексты, отвечать на вопросы и помогать решать самые разные задачи. Однако у них есть важное ограничение: они опираются только на те данные, на которых были обучены. Если нужной информации нет в обучающей выборке или она устарела, модель может выдать неточный ответ или сгенерировать убедительно звучащую, но недостоверную информацию.


- Что такое RAG в ИИ
- Чем RAG отличается от обычной LLM
- Почему RAG важна для бизнеса и корпоративных данных
- Как работает RAG-система
- Архитектура RAG-системы
- RAG и генеративный ИИ
- RAG-система и ИИ-агент
- Локальная RAG-система
- Где используется RAG в ИИ
- Преимущества и недостатки RAG
- Как внедрить RAG-систему
- Частые вопросы о RAG
Чтобы снизить риск таких ошибок и дать нейросети доступ к актуальным данным, используют технологию Retrieval-Augmented Generation (RAG). Вместо того чтобы отвечать только на основе собственных знаний, модель сначала ищет релевантную информацию во внешних источниках — документах, базах знаний, корпоративных хранилищах и других системах, — а затем формирует ответ с учетом найденных данных.
В статье разберем, что такое RAG, как устроены такие системы, из каких компонентов они состоят и в каких задачах используются. Также рассмотрим различия между RAG, обычными языковыми моделями и ИИ-агентами, а также особенности локального развертывания.

Что такое RAG в ИИ
Retrieval — это поиск и извлечение, Augmented — дополненная, Generation — генерация. Дословно получается RAG — дополненная поиском генерация (Retrieval Augmented Generation). То есть генерация ответа, дополненная предварительным поиском по внешним данным.
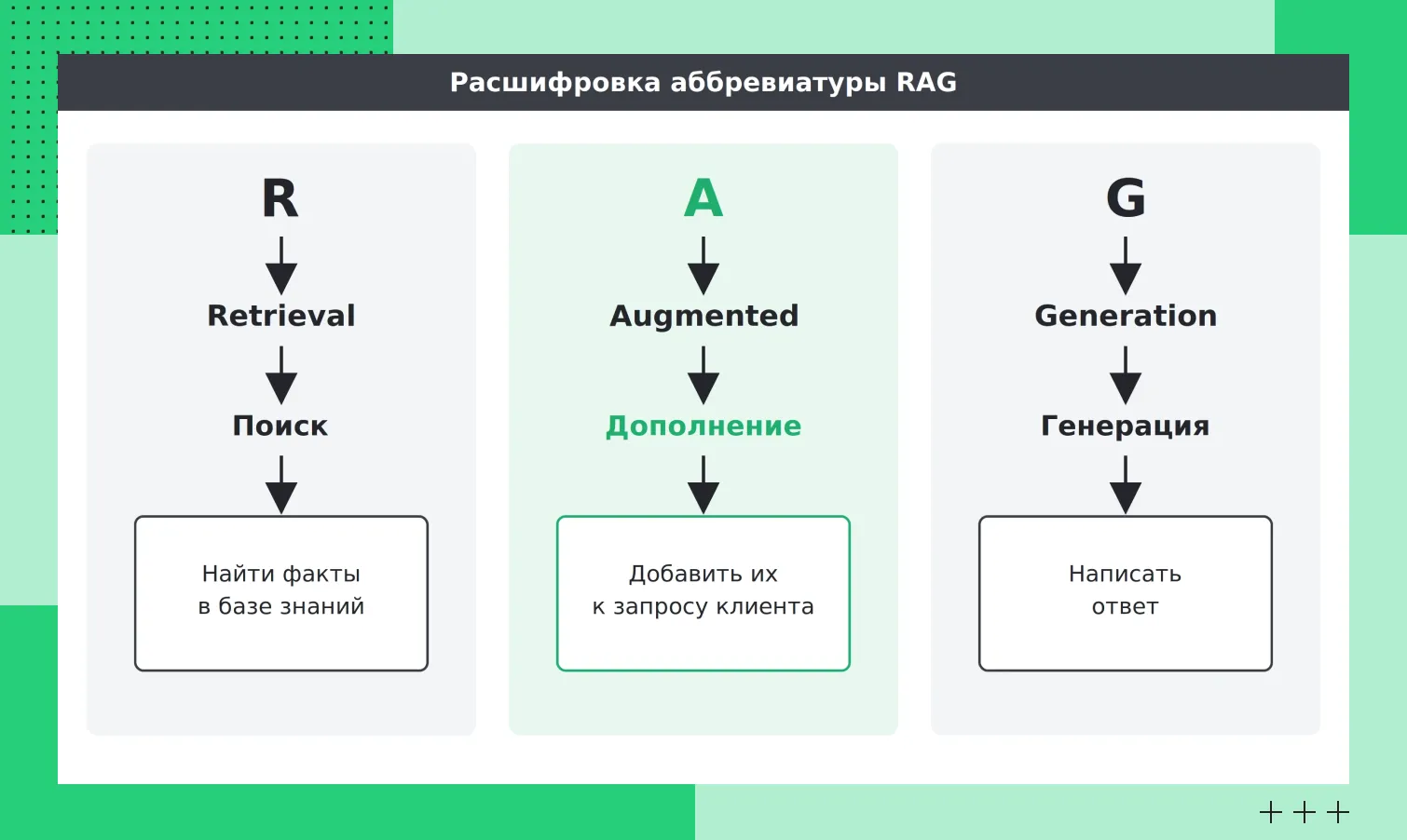 Из каких компонентов состоит RAG
Из каких компонентов состоит RAGВ 2020 году команда исследователей во главе с Патриком Льюисом (Patrick Lewis) представила архитектуру RAG (Retrieval-Augmented Generation) в статье «Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks». Это стало важной вехой в развитии подхода, хотя отдельные идеи совмещения поиска и генерации существовали и ранее.
Сегодня RAG — это один из базовых способов «подружить» модель со свежими и закрытыми данными.
Чем RAG отличается от обычной LLM
Большая языковая модель (Large Language Model, LLM) знает только то, что попало в обучающие данные на момент тренировки. Она не видит ни вчерашних новостей, ни внутренних регламентов компании, ни базы клиентов в CRM. Это похоже на закрытый экзамен: что студент запомнил — то и расскажет, а чего не знает, то в лучшем случае честно пропустит, а в худшем — придумает. RAG достраивает этот пробел: дает модели доступ к внешним знаниям прямо в момент запроса.
Из этой разницы вытекают три практических отличия RAG от LLM:
актуальность — базу знаний можно обновлять без переобучения модели: добавили новый документ, и система уже отвечает с учетом него;
проверяемость — ответ ссылается на источник, с которым можно свериться;
стоимость — не нужно дообучать модель под каждый новый файл, а это экономит и деньги, и время.
Критерий | Обычная LLM | RAG система |
Источник знаний | Память внутри модели | Внешняя база знаний в момент запроса |
Свежесть данных | На момент обучения | Обновляется без переобучения |
Проверяемость | Источник назвать нельзя | Ответ со ссылкой на документ |
Закрытые данные компании | Недоступны | Доступны через базу знаний |
Обновление | Дорогое переобучение | Замена документов в базе |
Почему RAG важна для бизнеса и корпоративных данных
Корпоративные базы знаний почти всегда закрыты, разрозненны и постоянно меняются. Регламенты обновляются, прайсы пересматриваются, появляются новые приказы. Переобучать модель под каждое такое изменение дорого и медленно, а главное — бессмысленно: к моменту окончания обучения данные уже могут устареть.
RAG решает эту задачу: дает модели доступ к базе знаний компании. Например, служба поддержки отвечает клиентам по действующему регламенту; меняется регламент — и бот в тот же день отвечает по новой версии.
Спрос на такой подход быстро растет. По прогнозу аналитической компании MarketsandMarkets от октября 2025 года, объем мирового рынка RAG в 2025 году оценивается в 1,94 млрд долларов и, по прогнозам, достигнет 9,86 млрд долларов к 2030 году (CAGR 38,4%). Оценки разных агентств разнятся, но направление у всех одно: рынок кратно растет.
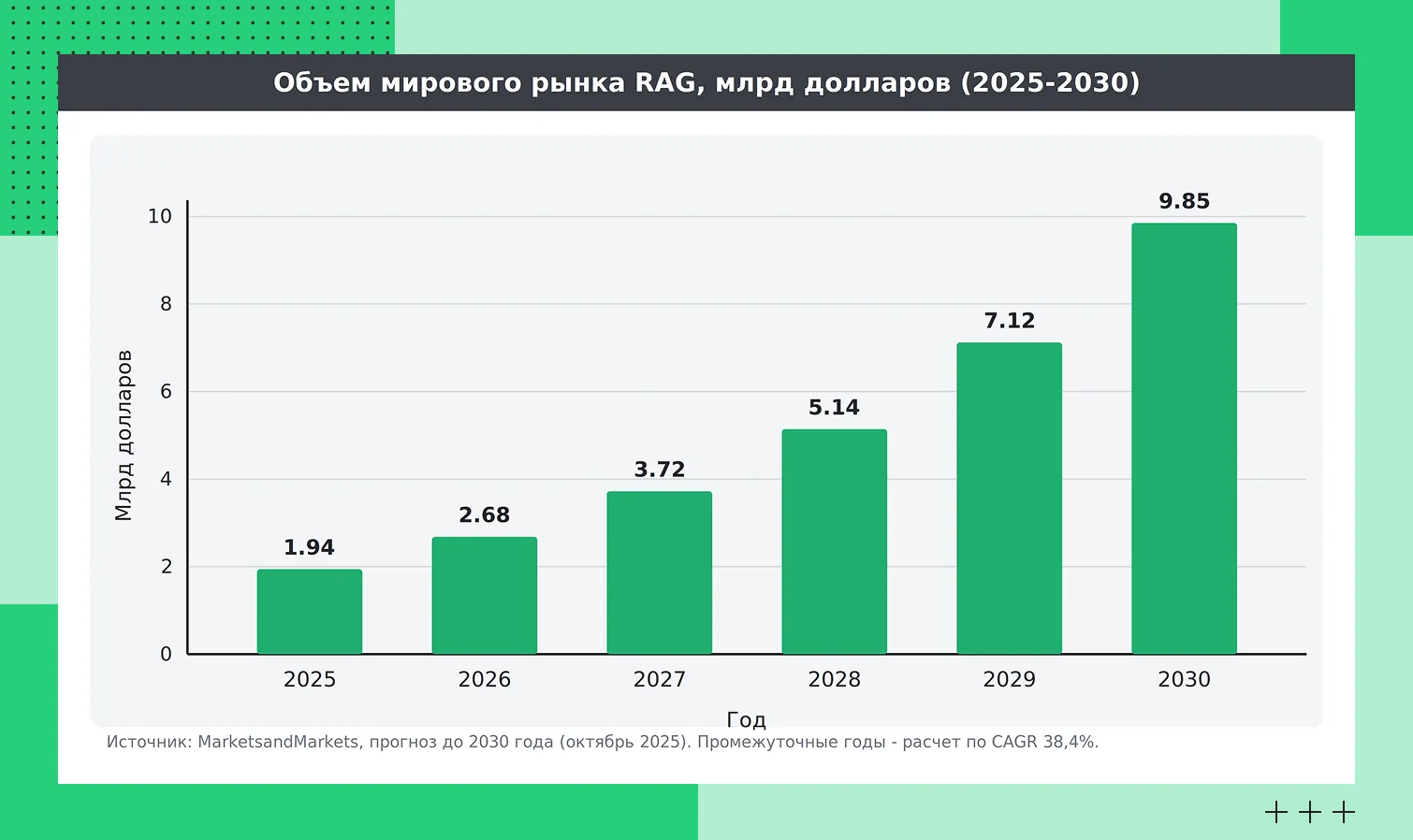 Объем мирового рынка RAG в млрд долларов
Объем мирового рынка RAG в млрд долларовКак связаны поиск, извлечение данных и генерация ответа
В основе RAG лежит последовательность действий: найти — извлечь — сгенерировать.
Сначала компонент-ретривер (модуль поиска релевантных фрагментов) ищет в базе фрагменты, которые связаны с запросом по смыслу. Затем выбранные данные передаются модели как контекст. После этого языковая модель формирует ответ, опираясь на полученную информацию. В основе поиска лежит семантическое сходство векторов (поиск по смыслу). Однако многие промышленные RAG-системы используют гибридный поиск, сочетающий семантический и лексический поиск (например, BM25, TF‑IDF) для повышения качества релевантности.
Например, если пользователь спрашивает про «отпуск», система может найти материалы про «ежегодный оплачиваемый отдых», даже если слово «отпуск» в тексте не используется.
Такая последовательность шагов превращает RAG в связанный процесс: от запроса пользователя до ответа, основанного на свежих данных.
Почему система Retrieval Augmented Generation (RAG) снижает число галлюцинаций
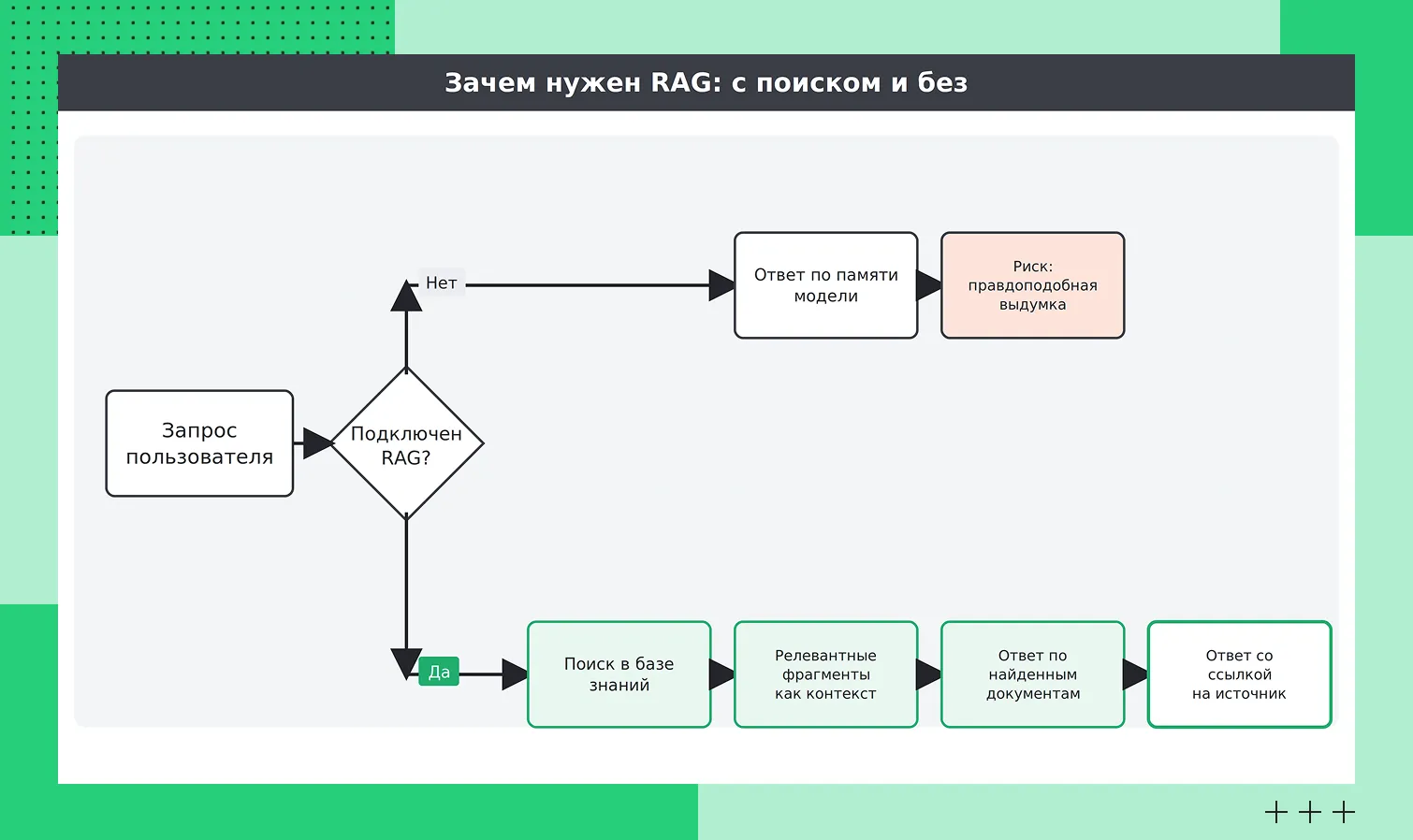 Как обрабатывается запрос пользователя с RAG и без нее
Как обрабатывается запрос пользователя с RAG и без нееГаллюцинация в языковых моделях — это правдоподобный, но фактически неверный ответ. Она возникает потому, что модель генерирует текст на основе вероятностного продолжения, и иногда это продолжение не опирается на реальные данные.
RAG снижает вероятность таких ошибок за счет «привязки» ответа к конкретным источникам. Вместо того чтобы формировать ответ только на основе внутренних параметров, модель получает найденные фрагменты из базы знаний и использует их как основу для генерации. Это ограничивает пространство для выдуманных фактов и делает ответ более правдоподобным.
Дополнительное преимущество — возможность опираться на источники и, в ряде случаев, показывать их пользователю для проверки информации.
При этом RAG не устраняет галлюцинации модели полностью. Если система поиска извлекла нерелевантные или ошибочные фрагменты, модель может сформировать неверный ответ. Это называют принципом «мусор на входе — мусор на выходе». Поэтому качество итогового результата напрямую зависит от качества поиска и подготовки данных.
Как работает RAG-система
У RAG есть два режима работы. Первый — подготовка базы, его называют индексацией. Второй — ответ на конкретный запрос в реальном времени. Разберем оба пошагово.
Индексация документов и подготовка базы знаний
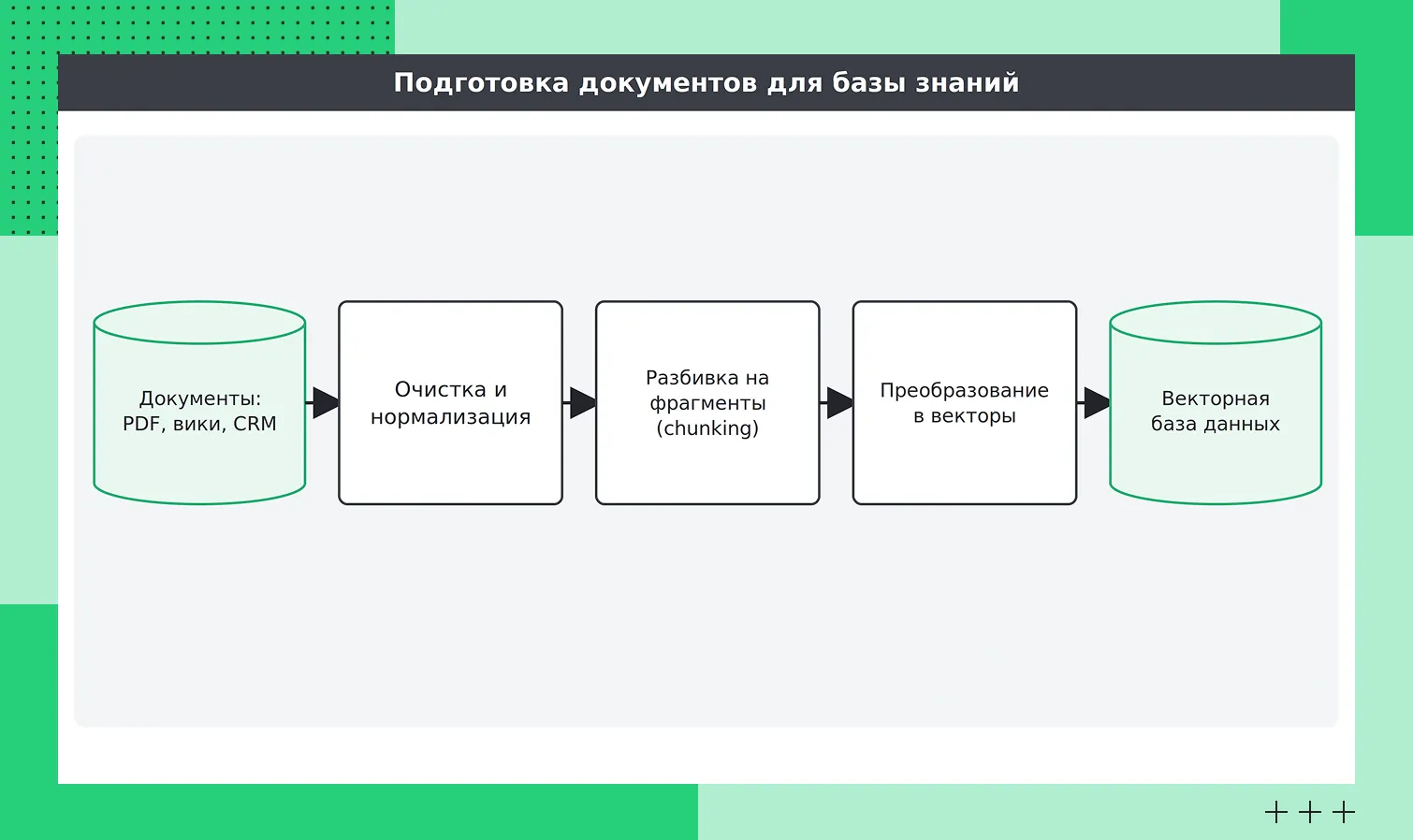 Примерно так выглядит процесс индексации документов
Примерно так выглядит процесс индексации документовСначала документы нужно подготовить. Их загружают, очищают от лишнего, разбивают на небольшие фрагменты (chunking), превращают каждый фрагмент в числовой вектор с помощью эмбеддинг-модели и записывают в векторную базу данных.
Например, регламент на 200 страниц не получится целиком положить в запрос — он не поместится в контекстное окно модели. Поэтому его режут на сотни фрагментов по несколько сотен слов каждый, и дальше система работает уже с ними. От того, насколько удачно нарезаны фрагменты, напрямую зависит качество будущих ответов.
Поиск релевантных фрагментов по запросу пользователя
Когда пользователь отправляет запрос, система обрабатывает его так же, как и документы при индексации: преобразует текст в векторное представление. Затем выполняется поиск по базе данных, где сравниваются векторы запроса и документов. Для оценки близости часто используется косинусная мера сходства, после чего выбираются наиболее релевантные фрагменты — обычно несколько лучших вариантов (top-k).
И запрос, и фрагменты документов представляются как точки в многомерном векторном пространстве. Чем ближе эти точки друг к другу, тем выше их семантическая схожесть. В результате система отбирает фрагменты, расположенные ближе всего к запросу, и на их основе будет сформирован ответ.
Передача контекста в языковую модель
Найденные фрагменты вместе с исходным запросом пользователя формируют итоговый промпт, который передается языковой модели. При этом объем контекста ограничен размером контекстного окна, поэтому в него включают только наиболее релевантные фрагменты, а не всю информацию.
Перед передачей данные часто проходят дополнительную сортировку — переранжирование. На этом этапе система уточняет порядок фрагментов, чтобы выше оказались те, которые лучше всего соответствуют запросу.
В результате модель получает компактный набор информации, достаточный для формирования более точного ответа.
Как RAG-модель ИИ формирует итоговый ответ
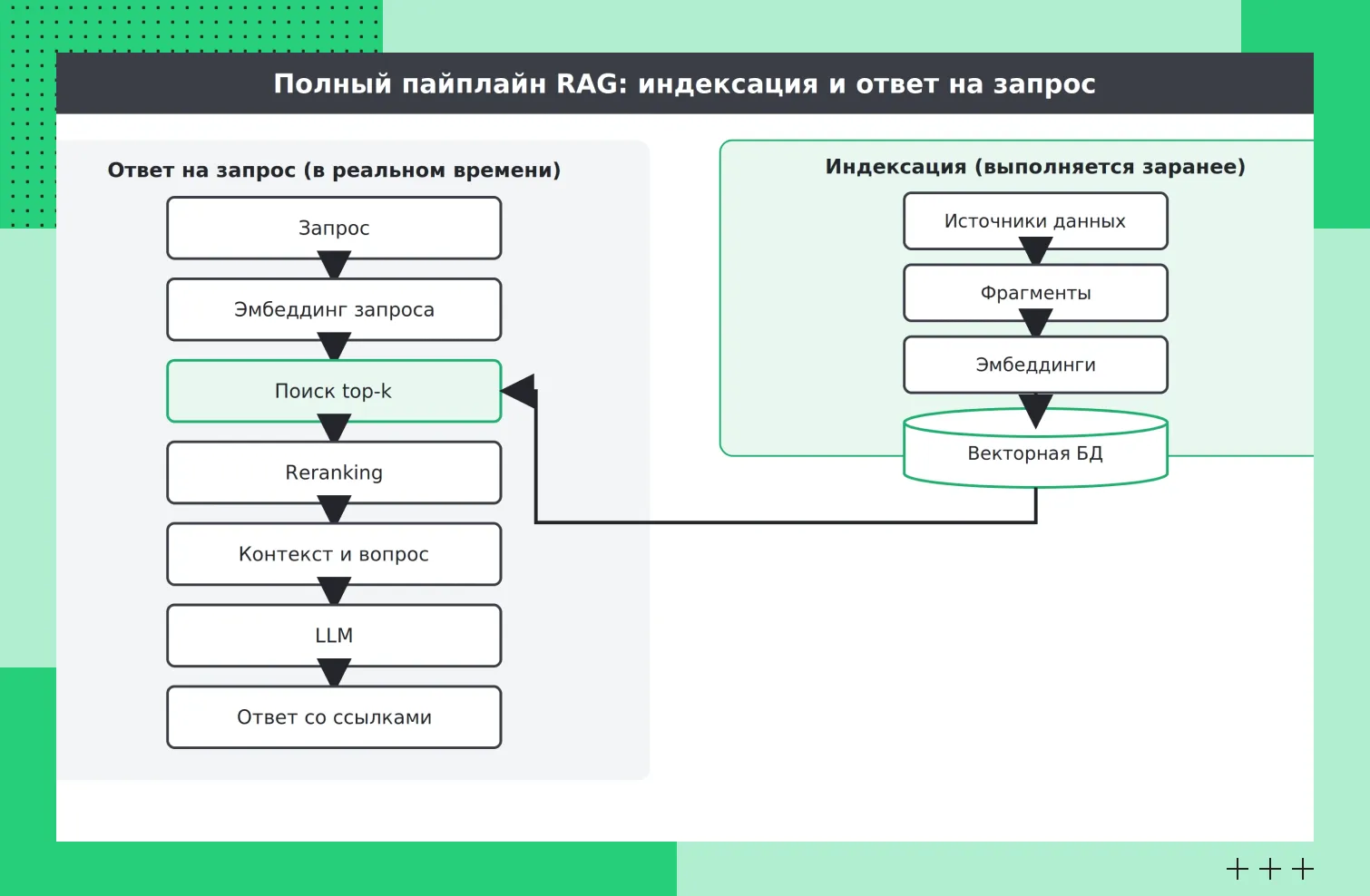 Примерно так RAG-модель формирует итоговый ответ
Примерно так RAG-модель формирует итоговый ответНа финальном шаге RAG-модель генерирует ответ, опираясь на переданный контекст, а не на абстрактную память. В идеале система еще и указывает, из каких документов взята информация, чтобы ответ можно было проверить. Так замыкается весь цикл: от вопроса — к поиску, от поиска — к обоснованному ответу.
Архитектура RAG-системы
Если собрать все шаги из предыдущего раздела вместе, получится набор взаимосвязанных компонентов. Это и есть архитектура RAG-системы — рассмотрим ее внимательно.
Источники данных: документы, базы знаний, CRM, сайты
Основой системы являются данные. В качестве источников могут использоваться документы, корпоративные базы знаний, системы по управлению взаимоотношениями с клиентами (CRM), страницы сайтов, а также переписки и другие текстовые материалы.
Чем разнороднее источники, тем важнее этап подготовки данных. Информацию приводят к единому формату, чтобы ее можно было одинаково обрабатывать и индексировать в системе поиска.
Embeddings, векторная база данных и ретривер
Эмбеддинги (embeddings) — это плотные векторные представления данных (текста, изображений, аудио и других типов), кодирующие их семантический смысл. Похожие по смыслу объекты имеют близкие векторы в многомерном пространстве. В RAG-системах эмбеддинги используются как для фрагментов документов, так и для пользовательских запросов.
В RAG-системе за поиск отвечают три компонента.
Эмбеддинг-модель преобразует текст в векторы — числовые представления, в которых заложен смысл запроса и документов.
Векторная база данных хранит такие векторы и быстро находит те, которые наиболее близки друг к другу по смыслу.
Ретривер (retriever) — это компонент системы, который управляет процессом поиска. Он определяет стратегию, например, семантический, ключевой или гибридный поиск, сравнивает векторы и выбирает наиболее релевантные фрагменты для дальнейшей передачи в модель.
LLM в архитектуре RAG-системы
Большая языковая модель в этой схеме выполняет роль генератора ответа. Модель может быть с открытым исходным кодом (open source) или коммерческой, доступной по программному интерфейсу приложения (Application Programming Interface, API), от выбора зависят стоимость, контроль и качество. Много зависит от промпта — инструкции, которая задает модели правила: отвечать только по контексту, указывать источники, не додумывать.
Оркестрация, reranking и контроль качества ответа
Все этапы RAG-системы объединяет оркестратор — компонент, который управляет последовательностью действий от получения запроса до формирования финального ответа.
Отдельную роль играет переранжирование (reranking). На этом этапе более точная модель пересортировывает найденные фрагменты, чтобы в контекст языковой модели попали наиболее релевантные данные.
Дополнительно в систему могут входить проверки качества ответа и механизмы цитирования источников, которые помогают сделать результат более прозрачным и проверяемым.
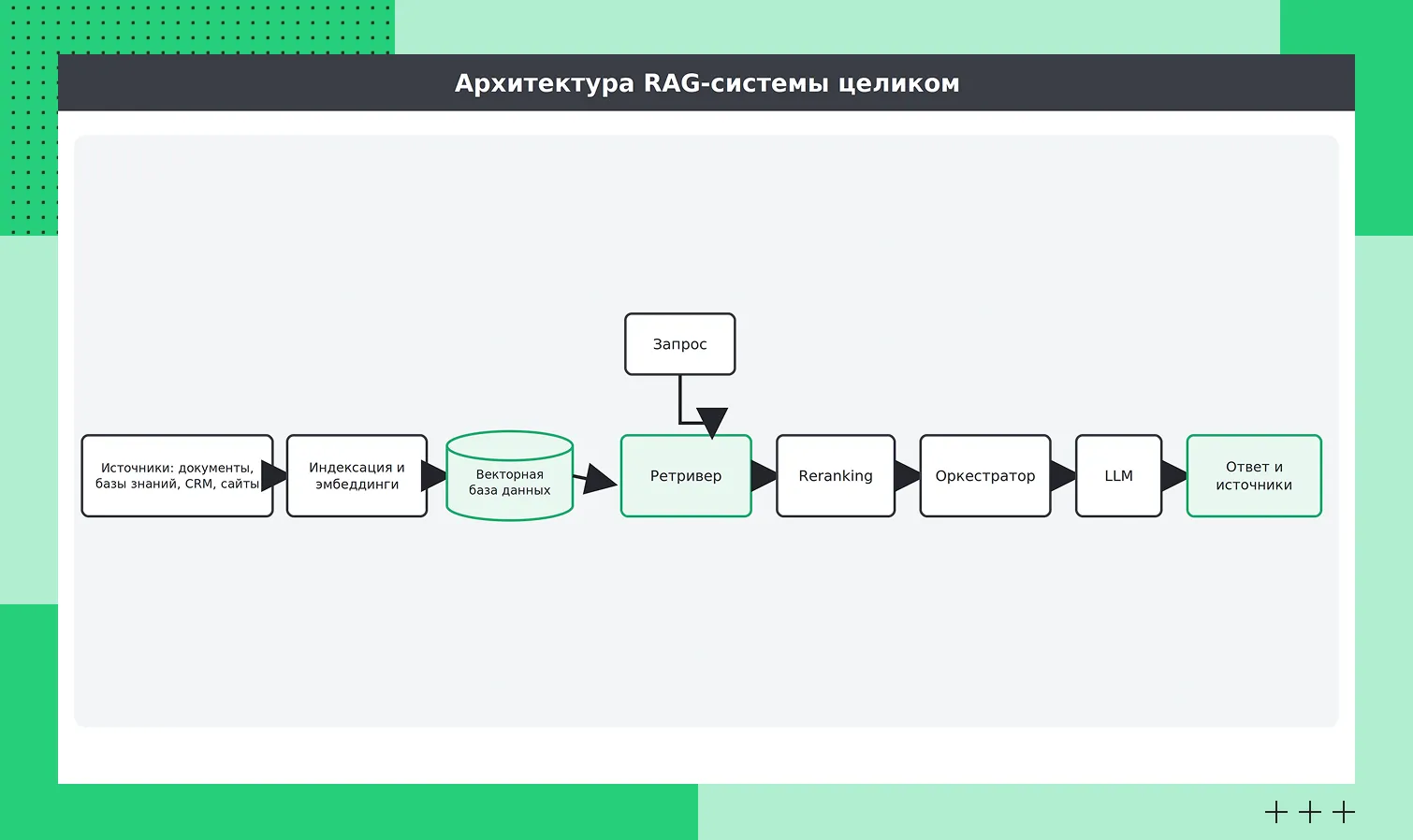 Как работает оркестрация и reranking в формировании готового ответа
Как работает оркестрация и reranking в формировании готового ответаСобрать такую систему вручную — отдельная инженерная задача. Необходимо выбрать эмбеддинг-модель, развернуть и настроить векторную базу данных, реализовать поиск и переранжирование, связать все компоненты через оркестратор и настроить регулярное обновление данных. Часть этих задач можно решить с помощью готовых инструментов и платформ, не разрабатывая все с нуля.
Чтобы не собирать пайплайн по кускам, компании используют готовые решения. Например, в составе цифровой среды AI Factory есть сервис Evolution Managed RAG — готовый к работе облачный сервис для дополненной поиском генерации, который использует только собственные данные пользователя для повышения точности ответов.
Представим страховую компанию: ей нужно, чтобы бот поддержки отвечал строго по действующим регламентам, а сами документы оставались в российском контуре. Вместо того чтобы вручную поднимать векторную базу, ретривер и оркестратор, команда загружает регламенты в Evolution Managed RAG — и поиск по базе знаний поднимается без отдельной инфраструктуры. Данные при этом остаются в сертифицированном облаке Cloud․ru. Если регламент меняется, достаточно обновить документ в базе, и бот будет отвечать по новой версии.
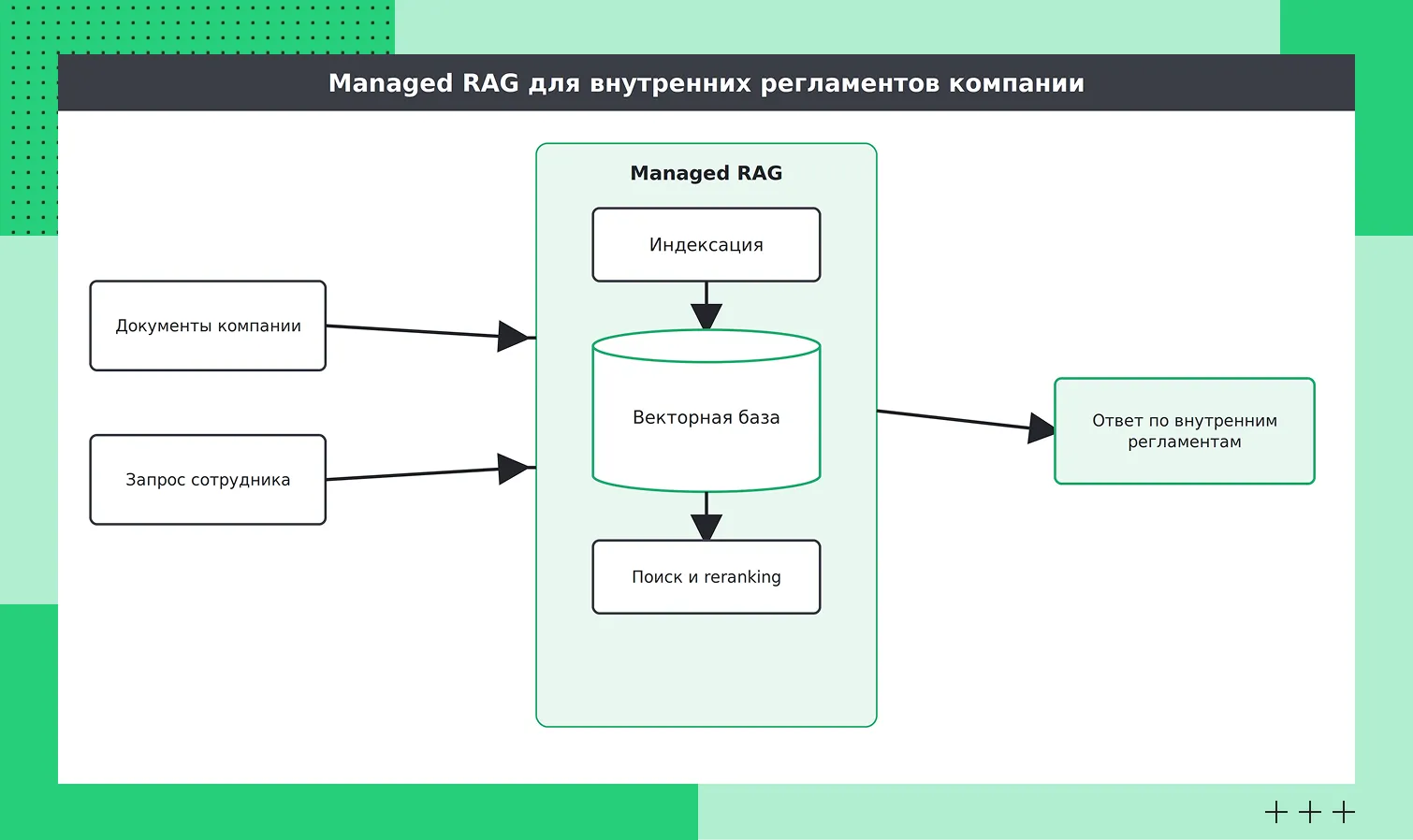 Принцип работы сервиса Evolution Managed RAG
Принцип работы сервиса Evolution Managed RAGRAG и генеративный ИИ
Иногда RAG и генеративный ИИ ошибочно противопоставляют, хотя на самом деле RAG — это архитектурное дополнение к генеративному ИИ, а не альтернатива. RAG усиливает генеративный ИИ, предоставляя ему доступ к внешним данным.
Как RAG усиливает генеративный ИИ
Генеративные LLM демонстрируют высокое качество связных текстов и рассуждений, но их фактологические знания ограничены данными, на которых они обучены, и со временем могут устаревать. RAG компенсирует это ограничение: предоставляет модели доступ к актуальным и закрытым данным, повышает достоверность ответов и позволяет ссылаться на источники. В связке RAG и генеративный ИИ работают как редактор и архив: один формулирует ответ, второй обеспечивает его необходимыми знаниями.
В каких задачах RAG дает наибольший эффект
Преимущества RAG особенно заметны в сценариях, где требуется опираться на актуальную или специализированную информацию. К таким задачам относятся ответы на вопросы о недавних событиях, работа с внутренними документами компании, поиск сведений в профессиональных областях и любые сценарии, где важна проверяемость источников. Без доступа к внешним данным модель в таких случаях часто ограничивается общими формулировками или допускает фактические ошибки.
Когда лучше использовать RAG, а когда fine-tuning
Важно не путать два разных инструмента:
RAG меняет то, что модель знает, — он подает знания извне.
Дообучение (fine-tuning) меняет то, как модель себя ведет, — ее стиль, формат, тон, узкие навыки. Если задача в том, чтобы отвечать по постоянно меняющимся данным, нужен RAG. Если задача в том, чтобы модель всегда отвечала в фирменном стиле или владела специфическим форматом, помогает дообучение. На практике их комбинируют.
Параметр | RAG | Fine-tuning | Связка RAG и fine-tuning |
Что меняет | Знания модели | Поведение и стиль | И знания, и поведение |
Свежесть данных | Высокая, база обновляется | Фиксируется на момент обучения | Высокая |
Стоимость изменений | Низкая | Высокая | Средняя |
Когда выбирать | Меняющиеся факты, ссылки на источник | Стабильный стиль, узкий формат | Сложные продуктовые сценарии |
RAG-система и ИИ-агент
RAG-системы и ИИ-агентов часто используют вместе, но они решают разные задачи. Чтобы не путать эти подходы, важно понять, какую роль каждый из них играет в работе с данными.

Чем отличается RAG-система от ИИ-агента
RAG — это архитектурный паттерн, дополняющий генерацию LLM поиском по внешним источникам данных. ИИ-агент — это автономная система, способная воспринимать окружение, планировать последовательность действий, использовать инструменты (включая RAG) и принимать решения для достижения поставленных целей. RAG может быть одним из инструментов агента, но не наоборот.
Как ИИ-агент использует RAG для доступа к знаниям
Когда агенту не хватает информации, он сам решает обратиться к этому инструменту, получает нужные фрагменты и продолжает работу. То есть агент достает все знания, когда они становятся нужны.
ИИ-агент c RAG в поддержке клиентов, аналитике и автоматизации
Связка ИИ-агента и RAG наглядно проявляется в практических сценариях.
В поддержке клиентов агент находит ответы в регламентах и может самостоятельно инициировать или оформлять обращение.
В аналитике — извлекает данные из отчетов и формирует на их основе выводы.
В автоматизации — получает нужную информацию из базы перед выполнением действия, например созданием заявки.
Во всех этих случаях распределение ролей остается одинаковым: RAG обеспечивает доступ к знаниям, а ИИ-агент отвечает за действия и принятие решений.
Кстати, если требуется не просто искать информацию в базе знаний, а строить более сложные сценарии с автономными ИИ-агентами, можно использовать сервис Evolution AI Agents. Он позволяет создавать мультиагентные системы, в которых несколько агентов взаимодействуют друг с другом, обращаются к внешним сервисам и работают с корпоративными данными. Платформа поддерживает MCP-серверы, благодаря чему агентов можно подключать к базам знаний, внутренним инструментам и другим источникам информации компании.
Связка: LLM + RAG + инструменты + память агента
Полноценный ИИ-агент обычно строится из четырех основных компонентов:
языковая модель как ядро системы;
RAG для доступа к внешним знаниям;
инструменты для выполнения действий;
механизм памяти для сохранения контекста между шагами.
В такой архитектуре LLM отвечает за рассуждение и генерацию ответов, RAG обеспечивает доступ к актуальной информации, инструменты позволяют взаимодействовать с внешними сервисами через вызовы функций или API, а память сохраняет важные данные для последующих шагов работы.
В результате формируется непрерывный цикл: получение задачи → поиск информации или выполнение действия → сохранение промежуточного состояния → переход к следующему шагу.
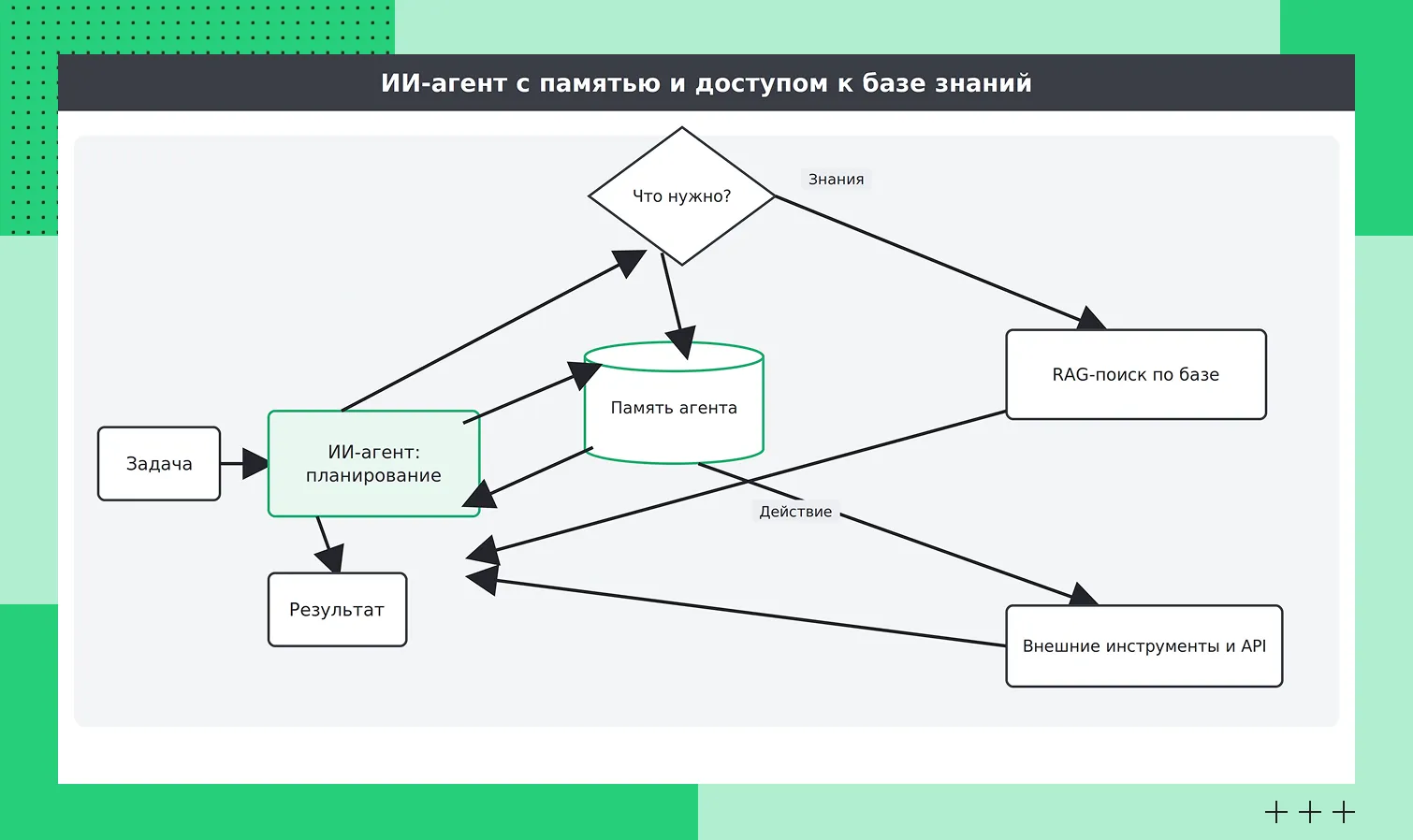 Как примерно работает связка: LLM + RAG + инструменты + память агента
Как примерно работает связка: LLM + RAG + инструменты + память агентаЛокальная RAG-система
Не всегда данные можно отправлять во внешние сервисы. В таких случаях встает вопрос о локальном развертывании.
Когда бизнесу нужна локальная RAG-система
Локальная RAG-система используется в случаях, когда работа с данными требует повышенного контроля и безопасности. Это может быть обработка персональных данных (ПДн) по требованиям 152-ФЗ, работа с объектами критической инфраструктурой (КИИ), выполнение отраслевых регуляторных требований или внутренние политики компании, запрещающие передачу информации во внешние сервисы.
Также локальное развертывание выбирают компании, которым важно контролировать инфраструктуру, снизить зависимость от внешних API или работать в закрытых корпоративных контурах без доступа к интернету.
В таких условиях приоритетом становится полный контроль над данными и их обработкой.
Преимущества локального развертывания: безопасность и контроль данных
Главное преимущество — данные не покидают периметр. Компания контролирует пайплайн: где хранятся документы, какая модель используется, кто имеет доступ. Это упрощает соответствие требованиям по безопасности данных и снимает риск утечки во внешний сервис.
Какие технологии подходят для локальной RAG-системы
Для локального развертывания берут открытые языковые модели, которые можно запустить на своей инфраструктуре, локальные векторные базы данных вроде FAISS, Milvus или Weaviate и оркестраторы наподобие LangChain или LlamaIndex. Все компоненты доступны в open-source, поэтому можно собрать полностью автономный контур.
Ограничения локальных решений и требования к инфраструктуре
У локального подхода есть свои издержки. Обычно требуются значительные вычислительные ресурсы, часто с использованием графических процессоров (GPU), а также техническая экспертиза команды и ресурсы на поддержку и обновление системы.
Здесь важно учитывать баланс: полностью локальное развертывание на собственной инфраструктуре дает максимальный контроль над данными, но требует больше усилий для сопровождения. Альтернативой может быть изолированный контур в сертифицированном облаке — он сохраняет высокий уровень контроля, но снижает нагрузку на поддержку оборудования.
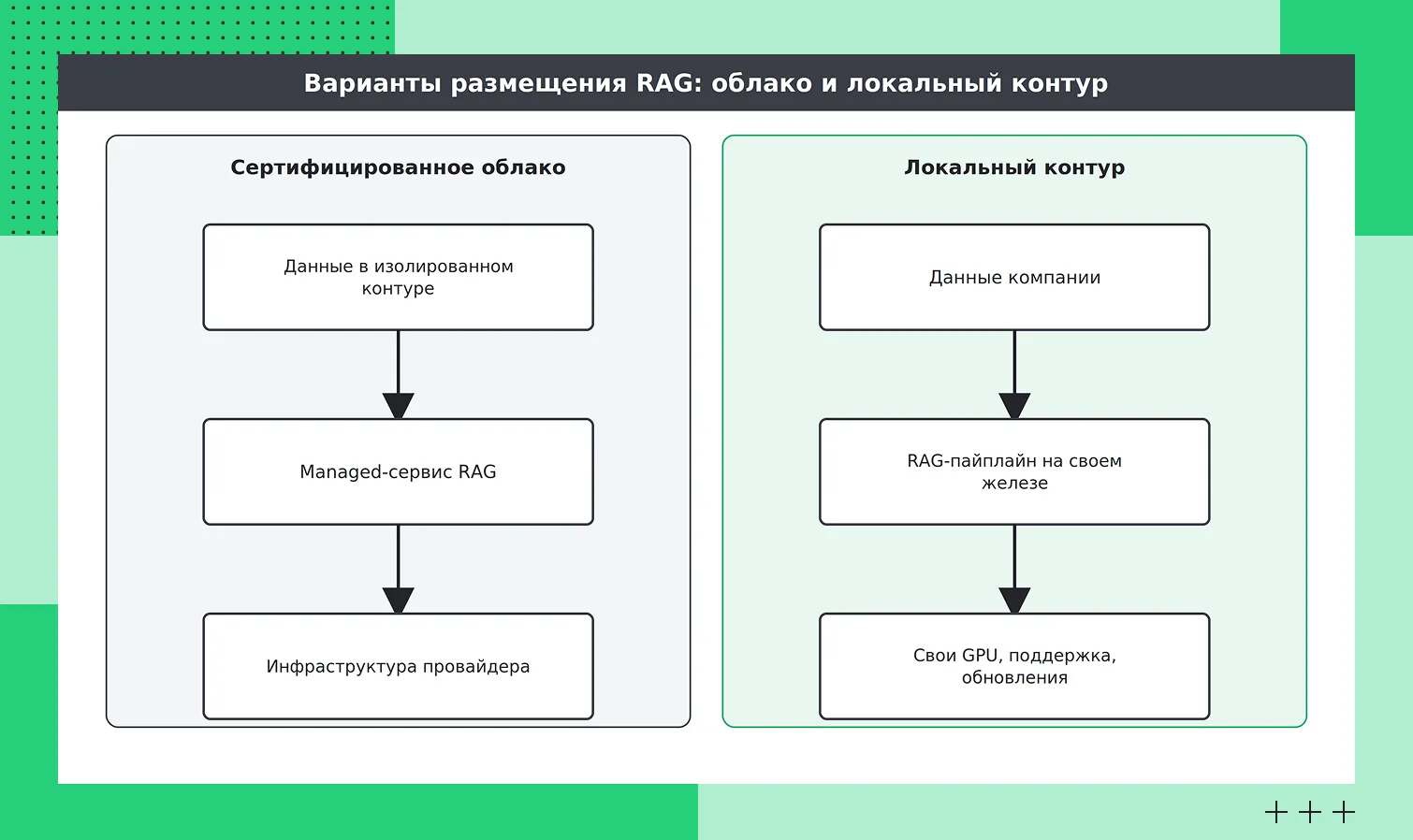 Отличия облачного решения от локального
Отличия облачного решения от локальногоГде используется RAG в ИИ
RAG применяется в задачах, где важно быстро находить точную информацию в больших массивах данных и опираться на свежие источники.
Корпоративные базы знаний и внутренний поиск
Сотрудник задает вопрос и получает ответ из внутренних документов без ручного поиска. Например: «какой порядок согласования отпуска в проектном офисе» — и сразу видит выдержку из регламента.
Чат-боты и ИИ-консультанты
Боты на основе RAG отвечают по актуальной документации, а не по общим знаниям модели. Подход полезен в задачах, где важна точность информации — например, при работе с тарифами, актуальным ассортиментом товаров или их характеристиками.
Юридические, медицинские и финансовые сценарии
В этих сферах критична проверяемость информации. RAG помогает находить данные в нормативных актах, отчетах и протоколах и показывает источник. При этом результат системы не заменяет специалиста и не является окончательным решением.
Поддержка сотрудников и клиентов
HR-боты отвечают на вопросы по документам, IT-helpdesk помогает с доступами и настройками, клиентская поддержка — с продуктами и условиями. Везде, где много однотипных запросов и регламентов, RAG снижает нагрузку на специалистов.
Преимущества и недостатки RAG
Чтобы выбор был осознанным, взвесим сильные и слабые стороны подхода.
Плюсы RAG
Главные преимущества:
актуальность — база обновляется без переобучения;
проверяемость — ответ со ссылкой на источник;
экономичность — дешевле, чем дообучать модель;
контроль над данными, особенно при локальном или изолированном развертывании.
Вместе они и делают RAG востребованным в корпоративных сценариях.
Минусы RAG
У RAG есть и ограничения. Качество ответа напрямую зависит от качества поиска: если ретривер возвращает нерелевантные данные, итоговый ответ также может быть неточным.
Кроме того, RAG-система сложнее обычного запроса к языковой модели — в ней больше компонентов и, соответственно, больше точек потенциального сбоя.
Добавляется и задержка на этапы поиска и переранжирования. Наконец, внедрение и поддержка такой инфраструктуры требуют дополнительных затрат.
Как внедрить RAG-систему
Внедрение удобно разделить на пять последовательных этапов:
Определение сценария использования. Сначала нужно понять, какую задачу решает система, для кого она предназначена и по каким критериям будет оцениваться результат. Без этого легко создать технически сложное, но бесполезное решение.
Подготовка данных и базы знаний. Соберите источники, очистите данные, продумайте разбиение на фрагменты и приведите информацию к единому формату. Этот этап во многом определяет итоговое качество системы.
Выбор модели, ретривера и векторной базы данных. Подберите компоненты с учетом языка, предметной области и требований к безопасности. Здесь же определяется, будет ли система работать локально или в облаке.
Тестирование качества ответов. Проверьте систему на наборе реальных запросов и оцените результаты с помощью метрик, а не субъективных ощущений.
Мониторинг, обновление и оптимизация. Регулярно обновляйте базу знаний, отслеживайте качество ответов и улучшайте этапы поиска и переранжирования. RAG — это не разовая настройка, а постоянно развивающаяся система.
Основные ошибки при внедрении
Чаще всего проблемы возникают из-за деталей.
Архитектурные ошибки. Чаще всего проблемы начинаются с неправильной настройки пайплайна. Если документы плохо разбиты на фрагменты, поиск сразу работает хуже и теряет контекст. Дополнительная ошибка — отсутствие переранжирования, из-за чего в итоговый контекст попадают менее релевантные фрагменты и появляются галлюцинации в ответе.
Ошибки выбора компонентов. Результат сильно зависит от используемых моделей и инструментов. Слабая эмбеддинг-модель или модель без поддержки русского языка снижает точность поиска и ухудшает соответствие запроса и найденных данных.
Ошибки в данных. Качество базы знаний напрямую влияет на итоговые ответы. Если в системе есть дубликаты, устаревшие или противоречивые документы, они попадают в контекст и ухудшают качество генерации.
Ошибки отсутствия оценки качества. Распространенная проблема — отсутствие метрик и регулярной проверки работы системы. Без этого невозможно понять, улучшились ли результаты после изменений или наоборот стали хуже, и оптимизация превращается в догадки.
Метрики качества для RAG-систем
Без постоянной аналитики улучшать систему невозможно. Качество оценивают по нескольким направлениям, и для этого есть готовые инструменты, например, библиотека RAGAS (RAG Assessment — Retrieval Augmented Generation Assessment). Она измеряет качество RAG почти без ручной разметки: роль арбитра берет на себя отдельная языковая модель — подход, который называют «модель как судья» (LLM-as-a-judge).
RAGAS оценивает ответы по нескольким базовым метрикам.
Метрика | Что измеряет |
Faithfulness | Насколько ответ верен найденным источникам |
Релевантность ответа | Насколько ответ соответствует вопросу |
Точность контекста | Доля нужных фрагментов в найденных |
Полнота контекста | Нашлись ли все нужные фрагменты |

Удобство такого подхода в том, что метрики разделяют качество поиска и генерации. Точность и полнота контекста показывают, насколько хорошо сработал поиск информации, а достоверность и релевантность ответа — насколько корректно модель использовала этот контекст.
В ряде метрик используется разбиение ответа на отдельные утверждения с последующей проверкой, подтверждаются ли они найденными источниками.
RAGAS интегрируется с популярными фреймворками оркестрации, такими как LangChain и LlamaIndex, что позволяет встроить оценку качества непосредственно в RAG-пайплайн. В более новых версиях также появляются метрики для агентных систем — например, корректность вызова инструментов (Tool Call Accuracy) и успешность выполнения задачи (Task Success Rate), если RAG используется внутри ИИ-агента.
RAG-модель ИИ: какие компоненты выбрать
RAG-система состоит из нескольких компонентов, и каждый из них подбирается под конкретную задачу. Разберем их по слоям.
Open-source и коммерческие LLM
Открытые модели обеспечивают больше контроля и независимость, но требуют собственных вычислительных ресурсов и технической экспертизы. Коммерческие модели, доступные через API, проще в запуске и часто дают более высокое качество «из коробки», но создают зависимость от внешнего сервиса и затрат на использование.
Выбор между ними обычно определяется требованиями к приватности данных, бюджетом и уровнем контроля над инфраструктурой.
Выбор embeddings-модели
От эмбеддинг-модели зависит, насколько точно система кодирует смысл текста в векторное представление. При выборе учитывают поддержку нужного языка, качество работы в целевой предметной области и особенности обучающих данных модели.
Для русскоязычных баз знаний особенно важно, чтобы модель корректно обрабатывала русский язык и сохраняла смысловую близость между похожими формулировками.
Инструменты для векторного поиска: FAISS, Milvus, Weaviate, Pinecone
Выбор векторной базы данных зависит от масштаба и формата развертывания.
Решение | Тип | Развертывание | Когда подходит |
FAISS | Библиотека | Локально | Прототипы и небольшие проекты |
Milvus | База данных | Локально или в облаке | Большие объемы, высокая нагрузка |
Weaviate | База данных | Локально или в облаке | Гибкие схемы и гибридный поиск |
Pinecone | Управляемый сервис | Облако | Быстрый старт без своей инфраструктуры |
Частые вопросы о RAG
RAG в ИИ — это замена обучению модели?
RAG в ИИ не заменяет обучение модели, а дополняет его. Вместо того чтобы встраивать знания в параметры модели, система получает информацию из внешних источников и передает ее в контекст запроса.
Чем RAG отличается от fine-tuning?
RAG влияет на доступ к информации — модель получает данные из внешних источников во время ответа.
Fine-tuning изменяет поведение модели: как она формулирует ответы, в каком стиле и с какими паттернами работает.
Можно ли сделать локальную RAG-систему без облака?
Да, локальную RAG-систему можно развернуть без облака, используя open-source компоненты. Но такой подход требует собственных вычислительных ресурсов, технической экспертизы и времени на поддержку инфраструктуры.
Подходит ли RAG для ИИ-агентов?
Да, это типовой инструмент агента для доступа к знаниям: агент сам обращается к RAG, когда ему не хватает информации.
Насколько безопасна RAG-система для корпоративных данных?
Зависит от развертывания. Изолированный контур или сертифицированное облако дают нужный уровень контроля над данными.
Заключение
RAG — это простая по идее и мощная по эффекту связка: поиск плюс генерация. Она дает модели доступ к данным, повышает фактологичность и позволяет ссылаться на источники — то, чего обычной языковой модели не хватает по умолчанию.
Качество RAG определяет не магия модели, а инженерия пайплайна — разбивка на фрагменты, эмбеддинги, переранжирование и постоянная оценка результата. Начать можно с малого: выбрать один сценарий, подготовить базу знаний и измерить качество ответов.