INSERT INTO SQL: примеры добавления данных в таблицу
С базами данных приходится иметь дело многим специалистам, даже не связанным с IT-сферой. Маркетолог, финансовый аналитик или логист — умение работать с базами данных всегда плюс. В этой статье расскажем об одном из базовых операторов для управления базами данных — INSERT INTO, который позволяет добавлять в таблицы новые данные.

- Почему команда INSERT важна
- Основная структура команды
- Пример создания таблицы и первичный ключ
- Пример 1: простое добавление данных
- Пример 2: вставка нескольких записей одновременно
- Пример 3: применение оператора SET
- Пример 4: вставка с использованием выражений
- Пример 5: добавление данных из другой таблицы
- Пример 6: использование значения по умолчанию
- Пример 7: добавление или обновление при наличии дубликата
- Пример 8: игнорирование ошибок при добавлении
- Пример 9: вставка в указанные партиции
- Пример 10: изменение приоритета вставки
Базы данных — это то, без чего сегодня не обходится ни один бизнес, будь то табличка с днями рождения сотрудников в Google Docs или огромный датасет для обучения ML-модели.
Базы данных бывают реляционными и нереляционными:
Реляционные базы как шкаф педантичного аристократа с множеством ящиков. В каждом из них может храниться только определенный вид предметов: например, в одном носки, в другом брюки, в третьем пиджаки. При этом предметы из одной категории связаны с содержимым другой: пиджак в клетку носим только с брюками из той же ткани.
Нереляционные базы данных как тот самый стул для вещей, которые уже неловко класть к чистым в шкаф, но еще жалко нести в корзину для грязного. Носки, джинсы, футболки и ремни на него можно складывать свободно, безо всякой структуры, пока место не закончится.
Чтобы работать с реляционными базами данных, где все по полочкам, используется структурированный язык запросов SQL. Если вновь обратиться к аналогии выше, это инструкция, что с чем носить и по каким ящикам раскладывать новые предметы гардероба. Но где вы видели аристократов, которые сами таким занимаются? Для этого есть условный дворецкий — система управления базами данных, которая понимает вас с полуслова и составляет комплекты для каждого случая.
Почему команда INSERT важна
SQL является стандартным языком для работы с реляционными базами данных и системами управления (СУБД): MySQL, PostgreSQL, Oracle, Microsoft SQL Server и другими. А оператор INSERT INTO используется в SQL для добавления новых записей в таблицы баз данных. Без этой команды единственное, что мог бы делать наш «дворецкий» со шкафом — это открывать его, грустно смотреть на вещи и уничтожать ненужные предметы гардероба.
Сегодня покажем вам, как отдавать команды своему «дворецкому», используя сервис Cloud.ru Evolution Managed PostgreSQL® и соответствующий этой СУБД диалект.
Основная структура команды
Допустим, у нас есть таблица с контактами сотрудников, в которую нужно добавить новичка. Основная структура команды INSERT будет выглядеть так:
Этот запрос добавляет запись об Иване Иванове в таблицу employees, последовательно указывая значения для столбцов имя/фамилия/должность/номер_телефона/зарплата.
Пример создания таблицы и первичный ключ
Давайте создадим таблицу employees, к которой будем обращаться в последующих примерах:
id — это имя первого столбца в таблице.
INT означает, что этот столбец будет хранить целочисленные значения.
PRIMARY KEY указывает, что столбец является первичным ключом таблицы. Первичный ключ должен быть уникальным для каждой записи и не может содержать NULL значений. Он используется для идентификации каждой строки в таблице.
first_name — имя сотрудника.
last_name — фамилия сотрудника.
VARCHAR(15) — ограничение по длине строки в символах. Здесь максимально допускается 15 символов.
phone_number — номер телефона.
position — должность сотрудника, у нас 'Инженер поддержки'.
salary — зарплата сотрудника.
DECIMAL(10, 2) — числовые значения длиной до 10 символов и с 2 знаками после запятой.
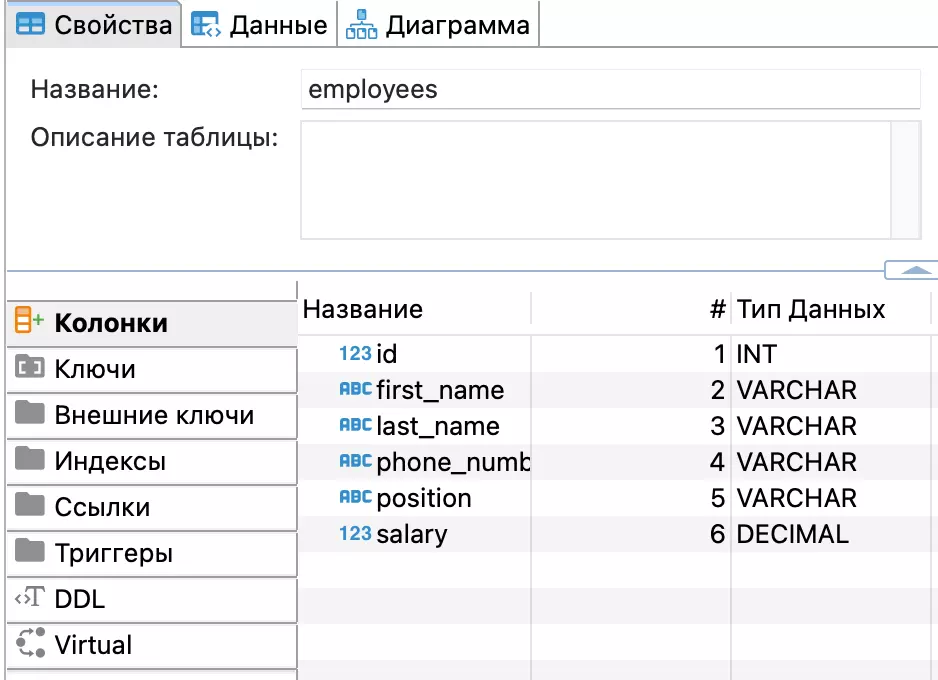 Так будет выглядеть структура созданной таблицы
Так будет выглядеть структура созданной таблицыПример 1: простое добавление данных
Для корректной записи нового значения в таблицу нам нужно либо прописать, в которые столбцы таблицы какие значения проставляем, либо указать id новой строки. Если не прописать порядок столбцов, значения будут добавлены во все столбцы в том порядке, в котором столбцы создавались изначально. Важно, чтобы количество и порядок значений соответствовали количеству и порядку столбцов в таблице:
После выполнения этой команды можно обратиться к базе данных и проверить, появилась ли новая запись.
 Новая запись в базе данных
Новая запись в базе данныхПример 2: вставка нескольких записей одновременно
Разумеется, базы оперируют огромными массивами данных, поэтому и добавлять их можно массово, главное — соблюдать правильный порядок значений. Добавим двух новых сотрудников:
В этом запросе каждая запись добавляется в таблицу employees в рамках одного INSERT INTO, что делает процесс вставки более эффективным и удобным.
 Две новые записи в таблице
Две новые записи в таблице
Пример 3: применение оператора SET
Как добавлять новые значения, мы разобрались, но что делать, если нам нужно добавить не новую строку, а изменить одно из значений? Например, одному из сотрудников повышают зарплату, и это нужно отразить в базе. Команда UPDATE может использовать оператор SET для обновления значений, выбираемых оператором WHERE, например:
 Результат использования команды UPDATE с оператором SET
Результат использования команды UPDATE с оператором SETВ некоторых СУБД, таких как MySQL, SET можно использовать в команде INSERT INTO для задания значений столбцов. Это менее распространенный синтаксис, но он может быть полезен для явного указания значений:
Пример 4: вставка с использованием выражений
Вставка с использованием выражений в SQL позволяет применять вычисления или функции, чтобы задавать значения столбцам при добавлении новых записей в таблицу. Это может включать математические операции, вызовы функций или использование подзапросов для определения значений. Использовать такие вставки полезно в случаях:
Когда требуется автоматизация вычислений. Вставка с выражениями позволяет автоматически вычислять значения, что упрощает ввод данных и снижает вероятность ошибок.
Для динамической генерации данных. Использование функций и подзапросов позволяет динамически генерировать значения на основе текущих данных или системного времени.
Для обработки сложных логик. В случаях, когда значения зависят от сложных вычислений или логики, выражения позволяют реализовать эту логику непосредственно в запросе.
Предположим, прошел уже год с последнего повышения зарплаты, навыки сотрудников выросли, как и инфляция. Давайте исправим это вставкой с использованием выражений:
Теперь доход каждого сотрудника автоматически увеличивается на 5000 рублей и умножается на коэффициент 1.05.
 Зарплаты в таблице, повышенные с помощью вставки с использованием выражений
Зарплаты в таблице, повышенные с помощью вставки с использованием выраженийТакже можно реализовать и более сложные схемы. Например, помимо математических операций можно использовать функции NOW(), CURDATE() или CONCAT().
Пример 5: добавление данных из другой таблицы
Часто случается, что данные, которые необходимо сопоставить, находятся в разных базах. Чтобы их «склеить» тоже можно использовать INSERT INTO с добавлением подзапроса.
Предположим, у нас есть таблица с новыми сотрудниками new_employees:
Туда уже успели занести новую сотрудницу Марию Петрову:
Таблицы с новыми и текущими сотрудниками одинаковы по структуре, а потому мы хотим их объединить, добавив в основную базу значения, которых в ней еще нет. Здесь нам потребуется подзапрос SELECT для исключения уже существующих записей:
Но ведь структура баз может и не совпадать, что делать в таких случаях? Предположим, у нас есть таблица candidates, которая хранит данные о соискателях на открытые вакансии, структура у нее следующая:
В таблице уже имеется запись о Марии:
Представим, что Марию приняли на работу, поэтому надо перевести данные из candidates в employees, но структура таблиц отличается. Нужно разбить full_name на first_name и last_name, а также перенести остальные данные:
В этом запросе:
split_part(full_name, ' ', 1): функция извлекает первую часть разделенной пробелом строки full_name и используется для first_name.
split_part(full_name, ' ', 2): извлекает вторую часть разделенной пробелом строки full_name и используется для last_name.
Остальные столбцы напрямую сопоставляются с employees.
 Результат переноса не совпадающих по структуре значений
Результат переноса не совпадающих по структуре значений Пример 6: использование значения по умолчанию
В некоторых СУБД команда INSERT INTO автоматически проставляет NULL при отсутствии значений для столбца. Однако это не всегда приемлемо. Чтобы такого не происходило, можно использовать значение по умолчанию — оно помогает сохранить консистентность и согласованность данных в базе, а также снизить число ошибок, произошедших из-за невнимательности пользователей.
Давайте добавим в базу employees PostgreSQL новый столбец, который будет использовать значение по умолчанию. Предположим, что мы хотим добавить столбец status, который будет указывать, работает сейчас сотрудник, уволился или, например, ушел в декретный отпуск. По умолчанию все новые сотрудники будут иметь статус active.
А теперь добавим в таблицу новую запись:
Поскольку мы не указали значение для столбца status, наш новый сотрудник автоматически получит значение active, установленное по умолчанию. В этом легко убедиться, проверив результат.
 Использование значения по умолчанию
Использование значения по умолчаниюПример 7: добавление или обновление при наличии дубликата
Вставка или обновление при наличии дубликата — это техника, используемая в SQL для обработки ситуаций, когда вставляемая запись вызывает нарушение уникальности из-за дублирования ключей. Вместо того чтобы вызывать ошибку, запись либо обновляется, либо игнорируется. Это особенно полезно при работе с уникальными ключами, такими как первичные ключи и индексы.
В MySQL можно использовать конструкцию ON DUPLICATE KEY UPDATE. Если вставляемая запись вызывает дублирование уникального ключа, то вместо ошибки происходит обновление указанных столбцов:
Таким образом, если мы снова попытаемся вставить данные Ивана с его id, данные в таблице не будут дублироваться — произойдет только обновление зарплаты.
В PostgreSQL используется конструкция INSERT ... ON CONFLICT, которая позволяет указать, что делать в случае конфликта:
В данном случае, если возникает конфликт по id, то зарплата обновляется новым значением.
Пример 8: игнорирование ошибок при добавлении
Нам не всегда нужно, чтобы данные в таблицах обновлялись, даже если при вводе новых данных дублируется уникальный ключ. Как раз для таких случаев в MySQL существует конструкция INSERT IGNORE: она не вызывает ошибку и не прерывает выполнение, вместо этого проблемная запись просто не вставляется.
Когда использовать INSERT IGNORE:
Обработка дубликатов. Когда вы предполагаете, что будут дубликаты, и хотите избежать прерывания выполнения запроса.
Импорт данных. При массовом импорте данных, где могут быть дубликаты, и важно, чтобы процесс не прерывался.
Упрощение логики. Когда проще игнорировать проблемные записи, чем обрабатывать ошибки вручную.
Предположим, у нас есть таблица employees с уникальным ключом по id. Мы хотим добавить нового сотрудника, но не уверены, что id уникален:
Используя эту конструкцию, важно помнить о подводных камнях:
Использование INSERT IGNORE может скрыть ошибки, которые вы, возможно, захотите исправить, например, ошибки данных.
Убедитесь, что игнорирование ошибок соответствует логике вашего приложения, и вы не упускаете важные данные.
Пример 9: вставка в указанные партиции
Партиционирование — это метод разбиения большой таблицы на более мелкие, управляемые части, называемые партициями, для улучшения производительности и управляемости. Вставка в указанные партиции — это техника, которая позволяет явно указывать, в какую партицию таблицы следует вставить новые данные.
Партиционирование может быть выполнено:
По диапазону (RANGE). Данные распределяются по партициям на основе диапазона значений столбца.
По списку (LIST). Данные распределяются по партициям на основе списка значений.
По хэшу (HASH). Данные распределяются по партициям на основе хэш-функции.
Партиционирование по ключу (KEY). Похоже на хэш-партиционирование, но использует внутреннюю хэш-функцию СУБД.
Предположим, мы хотим партиционировать таблицу employees по столбцу salary, чтобы каждая партиция содержала интересующие нас значения.
В PostgreSQL сделать таблицу партиционированной можно только при ее создании, поэтому потребуется переименовать таблицу или создать новую, а затем разбить ее на несколько маленьких и импортировать значения.
Переименуйте старую таблицу:
Создайте новую партиционированную таблицу:
Создайте партиции:
Перенесите данные:
При последующей вставке значения сразу будут попадать в нужную партицию.
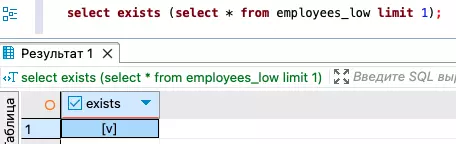 Результат вставки значения в указанную партицию
Результат вставки значения в указанную партициюЕсли вы используете MySQL для партиционирования, необходимо будет выполнить примерно следующий запрос:
Давайте предположим, что мы хотим вставить данные в партицию p1, которая содержит данные с hire_date с 2000 до 2010 года.
PARTITION (p1): Указывает, что данные должны быть вставлены в партицию p1, которая соответствует hire_date в диапазоне с 2000 до 2010 года.
VALUES (102, 'Мария', 'Иванова', '+7 987 654 3210', 'Менеджер', 90000.00, '2003-03-20'): Добавляет новую запись с данными о сотруднике Марии Ивановой, у которой hire_date — 20 марта 2003 года.
Пример 10: изменение приоритета вставки
Некоторые базы данных бывают настолько высоконагруженными, что на их работу может повлиять даже порядок выполнения операций. Для того чтобы база не «зависала», оставалась доступной и не игнорировала команды пользователей, вставки можно приоритизировать с помощью ключевых слов LOW_PRIORITY и HIGH_PRIORITY.
Предположим, вы хотите добавить нового сотрудника, но знаете, что к базе обращается много людей, и не хотите прерывать операции чтения.
В этом случае данные о Сергее добавятся в базу после того, как текущие операции чтения будут завершены.
Теперь у вас есть все необходимые знания, чтобы быстро и легко создавать базы данных и эффективно ими управлять. Кстати, лучше всего делать это у нас, в облаке Cloud.ru: например, на платформе Cloud.ru Evolution можно создать свой кластер управляемых баз данных PostgreSQL, а для поклонников MySQL есть Advanced Relational Database Service. Гарантируем, что благодаря высокой стабильности и надежности этих сервисов, вы сможете сосредоточиться на вашей основной работе, а не на ожидании ответа от базы данных.