Hadoop: что это такое и для чего применяется система Apache Hadoop
Hadoop — ответ дорогостоящим DWH. Фреймворк позволяет обрабатывать большие объемы данных на кластерах из стандартных серверов. Hadoop уже не просто технология, а фундамент экосистемы Big Data. Рассказываем, как работает продукт и в чем его преимущества.


Происхождение и философия Hadoop
Разберемся, как возник проект и что стало мотивацией к его созданию. Затронем идеи, которые легли в основу и до сих пор влияют на развитие систем для обработки данных.
Проблема, которую решает Hadoop
До появления Hadoop обработка больших данных строилась за счет вертикального масштабирования (scale-up). Этот подход подразумевает наращивание мощности одного сервера за счет более дорогих CPU, памяти и дисков. Однако все упиралось в ограничения оборудования и росту стоимости инфраструктуры. К тому же, традиционные DWH-системы не подходили для работы с неструктурированными данными.
Hadoop стал альтернативой, работая в концепции горизонтального масштабирования (scale-out), когда нагрузка распределяется между несколькими серверами. Вместо одного мощного узла получается кластер из бюджетного железа, которое можно добавлять по мере роста данных. Ключевой принцип архитектуры Hadoop заключается в том, что перемещать вычислительные задачи к данным дешевле, чем перемещать сами данные. На практике это означает, что задачи выполняются на тех узлах кластера, где хранятся обрабатываемые данные, что минимизирует сетевой трафик и повышает общую производительность системы.
От Google MapReduce и GFS к открытому Apache-проекту
В начале 2000-х годов Google опубликовал несколько статей с описанием принципов работы Google File System (GFS) и модели распределенных вычислений MapReduce. Из публикаций было ясно, что обработку огромных объемов данных можно выполнять без дорогого оборудования на кластере из обычных серверов.
Идеями вдохновился разработчик Дуг Каттинг и решил реализовать подобные механизмы и запустить их в открытый доступ. Изначально его проект развивался как часть Nutch, но скоро выделился в самостоятельное решение. Название Hadoop появилось спонтанно — в честь игрушечного слона сына Дуга Каттинга. Новый продукт получил активную поддержку в Yahoo!, где его начали использовать для анализа и индексации больших объемов данных.
Ключевые принципы: надежность через избыточность, обработка данных «на месте»
Философия Hadoop основана на том, что отказы при обработке информации — норма, а не исключение. Надежности системы можно достичь без дорогого оборудования — за счет избыточности данных и автоматического восстановления при сбоях.
Данные и их копии в распределенном виде хранятся на разных узлах кластера. Они обрабатываются непосредственно там, где находятся. Это позволяет минимизировать сетевой трафик и ускорить масштабирование.
Архитектурное ядро: три столпа Hadoop
В основе Hadoop три ключевых компонента, у каждого из которых свой фронт работы в кластере. Один отвечает за управление, второй — за хранение, третий – за выполнение вычислений. Разберемся, что это за компоненты.
HDFS (Hadoop Distributed File System): распределенное хранилище
HDFS — файловая система, предназначенная для работы с большими данными, распределенными по разным узлам кластера. В архитектуре два типа узлов. NameNode хранит метаданные — структуру каталогов, имена файлов, сведения о данных и их расположении. DataNode отвечает за хранение блоков данных и обслуживание запросов пользователей.
Важно отметить, что в базовой конфигурации NameNode представляет собой единую точку отказа (Single Point of Failure), поскольку хранит все метаданные файловой системы. В производственных кластерах для обеспечения высокой доступности (High Availability) настраивается режим с активным и резервным NameNode, где метаданные синхронизируются через выделенные journal nodes.
Отказоустойчивость системы обеспечивается с помощью репликации блоков данных. По умолчанию для каждого блока создается три копии (реплики), которые распределяются по разным узлам кластера. Если один узел выходит из строя, система автоматически восстанавливает недостающие реплики на других работоспособных узлах.
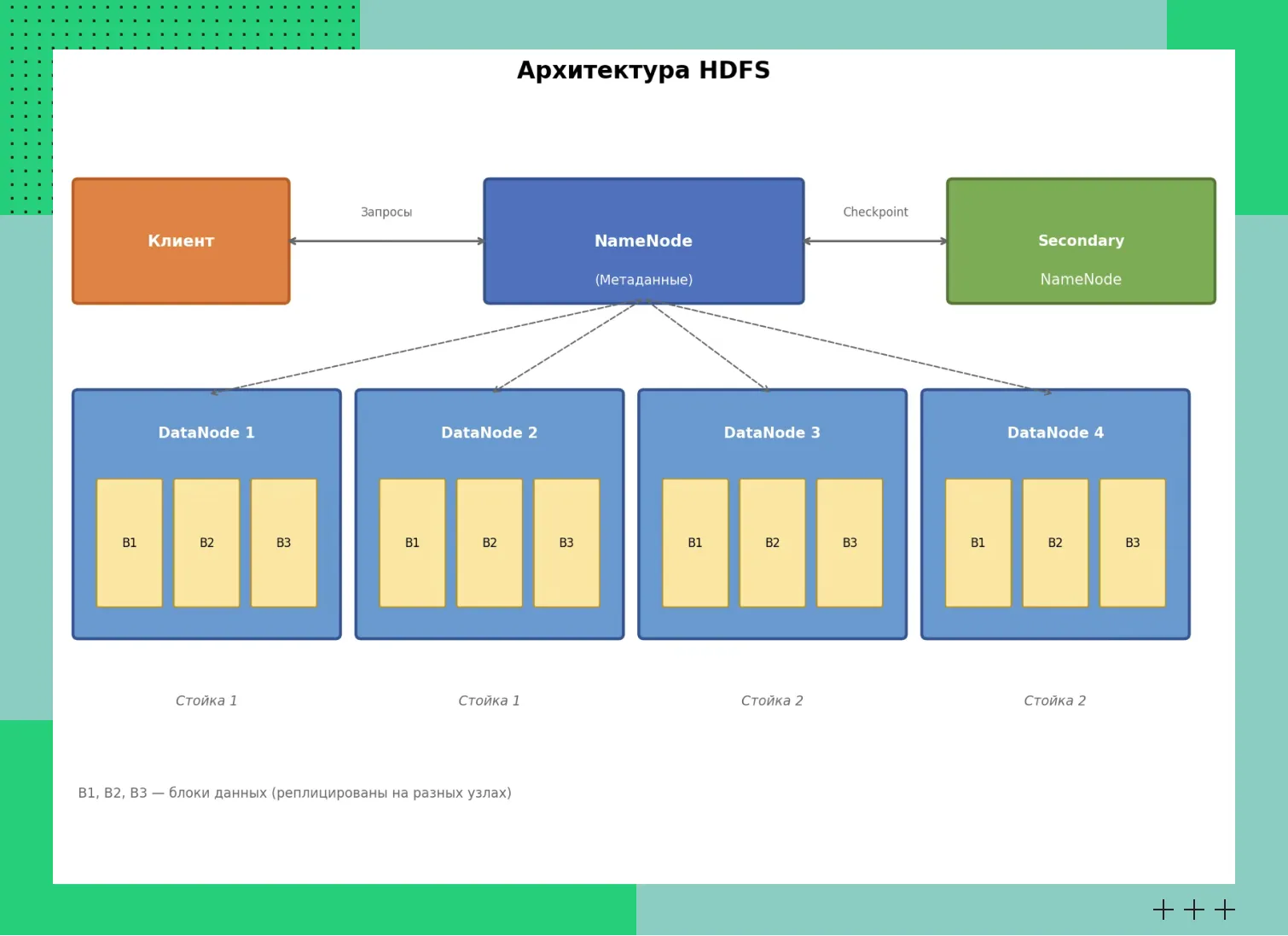 Архитектура HDFS
Архитектура HDFS YARN (Yet Another Resource Negotiator): операционная система кластера
YARN появился в Hadoop 2.0 как эволюционный шаг, который кардинально изменил архитектуру. В Hadoop 1.0 управление ресурсами и планирование задач были жестко встроены в фреймворк MapReduce (компонент JobTracker), что ограничивало экосистему только этой моделью вычислений. Задача YARN — отделить планирование и распределение ресурсов от конкретной модели выполнения задач. Такой подход сделал Hadoop универсальной платформой.
В архитектуре YARN ключевая роль отводится ResourceManager, который отслеживает ресурсы кластера и распределяет их между приложениями. На всех узлах работает компонент NodeManager. Он контролирует использование CPU и памяти на конкретной машине. Для каждого запущенного приложения создается ApplicationMaster, который отвечает за запуск, мониторинг и завершение задач.
Благодаря YARN на одном кластере можно параллельно запускать разные вычислительные движки. Это открыло путь к использованию Apache Spark, Tez, Flink и других систем, что расширило список сценариев применения Hadoop.
MapReduce: устаревшая, но важная модель
MapReduce — первая вычислительная модель Hadoop, которая заложила фундамент распределенной обработки данных. Ее ключевое достоинство — высокая отказоустойчивость за счет сохранения промежуточных результатов на диск, но эта же особенность приводит к значительным накладным расходам на ввод-вывод.
Со временем для большинства аналитических задач MapReduce уступил место более производительным фреймворкам, таким как Apache Spark или Apache Tez, которые используют оптимизированные модели выполнения (например, направленные ациклические графы — DAG) и минимизируют операции с диском за счет кэширования данных в памяти. Однако MapReduce остается поддерживаемым компонентом Hadoop и может быть эффективен для специфичных пакетных задач, где важна максимальная отказоустойчивость, а не низкая задержка.
Экосистема Hadoop: современный инструментарий поверх ядра
Основные инструменты мы собрали в таблицу с кратким описанием:
Компонент | Категория | Назначение | Роль в экосистеме |
Apache Spark | Фреймворк выполнения | Распределенная обработка данных в памяти | Вычислительный движок для ETL, аналитики, ML и стриминга |
Apache Tez | Фреймворк выполнения | Выполнение DAG-графов задач для высокопроизводительной пакетной обработки | Используется как execution engine для Apache Hive и Pig, а также как самостоятельный фреймворк для сложных пайплайнов обработки данных |
Apache Hive | Доступ к данным | SQL‑интерфейс к данным в HDFS | Data Warehouse-слой для аналитических запросов |
Apache HBase | Хранилище данных | NoSQL БД с доступом в реальном времени | Быстрый доступ к большим объемам данных |
Apache Pig | ETL‑инструмент | Описание трансформаций | Упрощение ETL-процессов поверх Hadoop |
Apache ZooKeeper | Служебный сервис | Координация и синхронизация | Обеспечение согласованности в распределенных системах |
Apache Oozie | Оркестрация | Планирование Hadoop-задач | Управление batch-пайплайнами в Hadoop |
Apache Airflow* | Оркестрация | Управление workflow | Универсальная оркестрация data-пайплайнов |
Apache Sqoop | Интеграция данных | Перенос между БД и Hadoop | Массовая загрузка и выгрузка данных |
Apache NiFi | Потоковая обработка | Передача и трансформация данных | Управление data-flows в реальном времени |
*Apache Airflow является независимым проектом оркестрации общего назначения и не входит в ядро экосистемы Hadoop, но широко используется для управления пайплайнами, включающими Hadoop-компоненты.
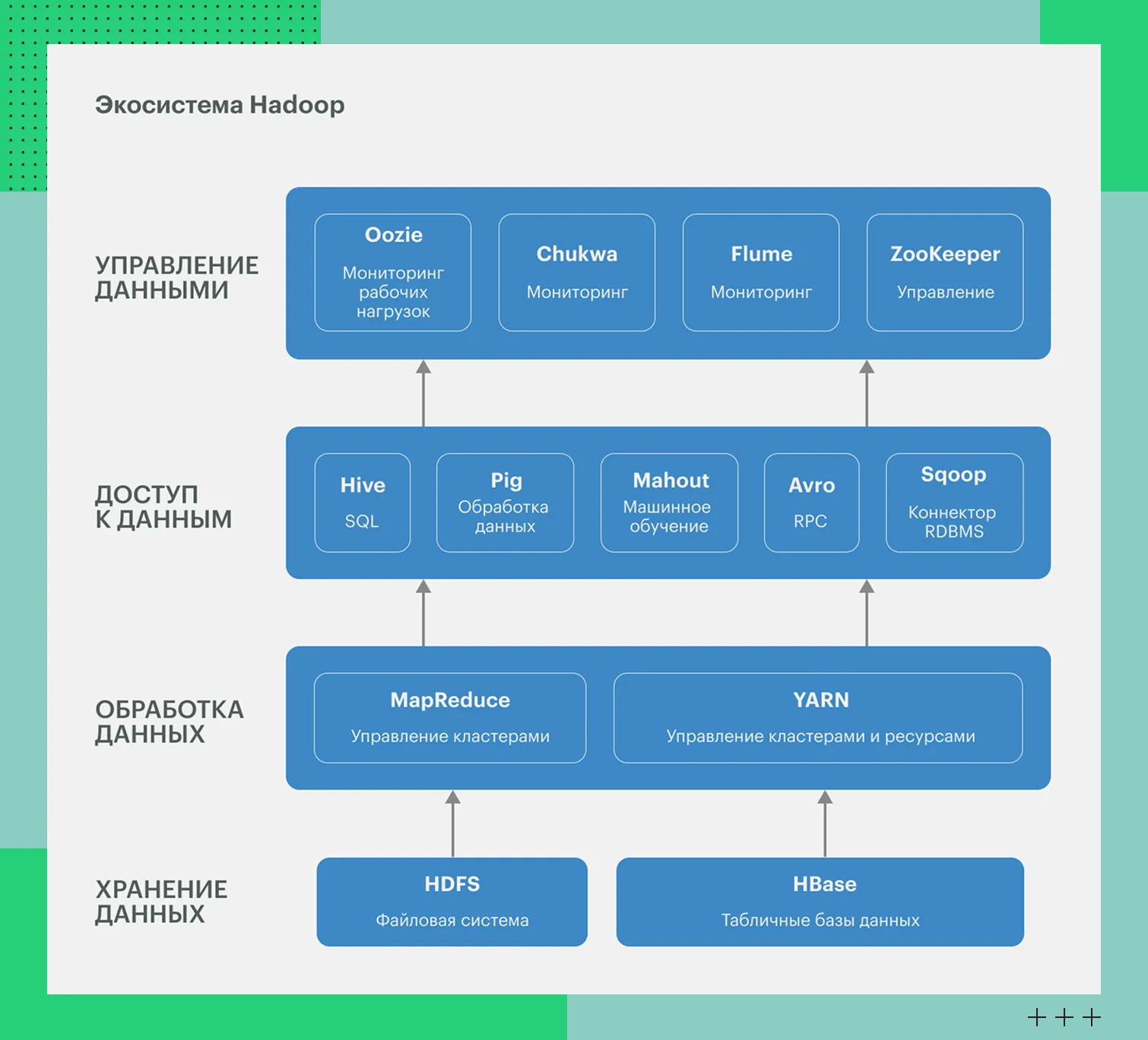 Инструменты проекта
Инструменты проектаСфера применения: для чего использовался и используется Hadoop
Hadoop служил основой для создания «озера данных» — места, где собирались «сырые» данные компании. Можно было без предварительной подготовки загружать сведения любого формата в HDFS. Структуризация выполнялась уже непосредственно перед анализом.
Hadoop стал одной из первых широко распространенных платформ для хранения и обработки больших объемов логов... Исторически эти данные часто обрабатывались с помощью MapReduce и Hive (который изначально транслировал SQL-запросы в цепочки MapReduce-задач). С развитием экосистемы для этих целей стали активно применяться более производительные инструменты, такие как Apache Spark.
Еще одна задача Hadoop — создание ETL-конвейеров для извлечения, преобразования и загрузки данных. Решение выступало в роли промежуточного звена для очистки, объединения и подготовки информации перед отправкой их в BI-системы или аналитические хранилища.
HDFS использовали для хранения неструктурированных данных: документов JSON, сообщений, текстов, лог-файлов и архивов. Это позволяло централизованно хранить информацию в разных форматах без жестких требований к структуре.
Отраслевые примеры применения
Hadoop применялся в отраслях, где важно обрабатывать и хранить большие массивы данных. В частности, и для того, чтобы выполнять аналитику в «пакетном» режиме. Вот примеры:
Ритейл. Анализ покупок, построение моделей персонализации и сегментации клиентов, обработка данных из касс и онлайн-магазинов.
Телеком. Обработка CDR-записей и сетевой телеметрии. На основе данных можно выполнять анализ нагрузки, выявлять аномалии и планировать ресурсы.
Финансы. Скоринг и фрод-аналитика, хранение транзакций и запуск специальных алгоритмов для обнаружения подозрительных операций.
Интернет-сервисы и медиа. Анализ логов и поведения аудитории, чтобы оценивать популярность контента.
Hadoop сегодня: эволюция и переход в облако
Hadoop прошел путь от главной платформы Big Data к технологическому наследию, на котором основаны многие аналитические системы. Такие изменения связаны с развитием облачной инфраструктурой.
Почему «классический» on-premise Hadoop теряет популярность
Популярность классических локальных Hadoop-кластеров (on premise) снижается по нескольким ключевым причинам:
Во-первых, это операционная сложность управления: для поддержки HDFS, YARN, мониторинга, обновлений и безопасности необходима отдельная квалифицированная команда.
Во-вторых, облачная экономическая модель (OpEx) и эластичность часто оказываются выгоднее больших капитальных затрат (CapEx) на железо и его обслуживание.
В-третьих, развитие управляемых облачных сервисов (EMR, Dataproc, HDInsight) предлагает аналогичные возможности «из коробки». Наконец, бизнес-требования сместились от пакетной обработки к аналитике с минимальными задержками и потоковой обработке, где классический Hadoop с архитектурой, ориентированной на MapReduce, не всегда оптимален.
Сейчас развиваются облачные сервисы, такие, как AWS EMR, Azure HDInsight и Google Dataproc. Они дают практически те же возможности, что и Hadoop, но без проблем с развертыванием и обслуживанием инфраструктуры.
Также анализ данных сместился от пакетной обработки к мгновенной. Бизнесу нужны минимальные задержки и потоковая обработка. Классический Hadoop с пакетной архитектурой не может обеспечить этого на должном уровне.
Современное наследие: что осталось актуальным
Hadoop уже не тот, что раньше, но многие его технологии еще задают тон в индустрии. Например, файловые форматы Parquet, ORC и Avro появились в Hadoop и стали основой для хранения аналитической информации. Они популярны, поскольку хорошо сжимают данные и работают с колоночной структурой.
Принципы обработки данных, заложенные в MapReduce и YARN, теперь используются и в новых системах вроде Apache Spark и Apache Flink. В основе те же идеи, но решения быстрее работают и поддерживают вычисления в оперативной памяти.
Концепция распределенного хранения данных эволюционировала. В облачных архитектурах Data Lake в качестве основного хранилища сырых данных часто используются объектные хранилища, благодаря их практически неограниченной масштабируемости и экономической модели. Однако HDFS по-прежнему широко применяется в локальных (on premise) развертываниях, а также в облачных кластерах для рабочих нагрузок, критичных к высокой пропускной способности и низкой задержке, например, для хранения промежуточных данных в процессе вычислений. Современные системы умеют работать с обоими типами хранилищ.
В общем, принципы и инструменты экосистемы Hadoop продолжают жить, но часто в новой, облачной форме. Такие инструменты, как Hive, Spark и Presto, теперь могут работать напрямую с облачными хранилищами (S3, GCS), становясь основой современных архитектур Data Lake и Lakehouse. Для построения таких архитектур зачастую не требуется развертывание и обслуживание полноценного классического on-premise Hadoop-кластера, что значительно снижает операционные издержки.
Изучать ли Hadoop сегодня: рекомендации для специалистов
Hadoop уже не считается незаменимым инструментом, но идеи по-прежнему в основе продвинутых распределенных систем. Их нужно знать, что вникнуть в принципы обработки больших данных.
Что обязательно понимать
Сначала освойте принципы распределенных систем — отказоустойчивость, репликацию, горизонтальное масштабирование и работу с отказами. Классическая архитектура HDFS и YARN до сих пор служит отличным учебным примером реализации этих принципов, даже если в современных системах используются другие технологии.
Изучение MapReduce поможет понять эволюцию вычислительных моделей и причины развития Spark и других in-memory решений.
На чем фокусироваться вместо bare-metal Hadoop
Изучите Apache Spark. Это один из наиболее популярных и универсальных фреймворков для распределенной аналитики, ETL и машинного обучения, ставший фактическим стандартом для многих сценариев пакетной обработки.
Рассмотрите для своих задач управляемые облачные Big Data-сервисы: Amazon EMR, Databricks, Google Dataproc. В экосистеме российских облачных провайдеров также существуют аналогичные решения, например, Advanced MapReduce Service от Cloud.ru, который предоставляет управляемый сервис для выполнения распределенных вычислений.
Разберитесь, как задачи Big Data интегрируются с контейнеризацией и платформой Kubernetes, которая применяется для запуска Spark-приложений и сервисов, заменяя в новых архитектурах классические Hadoop-кластеры.
Выводы
Hadoop был стандартом обработки больших данных и до сих пор влияет на современные системы. Теперь навык развертывания on-premise-кластера не слишком востребован. Важнее понимать экосистему и принципы работы облачных альтернатив. Это поможет освоить «сегодняшние» инструменты.