DWH: что это такое и как организовано хранилище данных Data Warehouse
Аналитические данные компаний поступают из разрозненных систем, из-за чего сложно проводить анализ и получать достоверные результаты. Проблему можно решить с помощью Data Warehouse. Это хранилище, которое позволяет привести сведения к единому формату и объединить их в одном месте. Разберемся, как оно устроено и работает.

- Что такое Data Warehouse
- Архитектура хранилища данных: классическая 3-уровневая модель
- Сравнение DWH с операционными базами данных и Data Lake
- Моделирование данных в DWH: схемы «Звезда» и «Снежинка»
- Технологический стек и популярные платформы DWH
- Процесс проектирования и внедрения DWH
- Преимущества и недостатки внедрения DWH
- Современные тенденции: от DWH к Data Lakehouse
- Заключение
Что такое Data Warehouse
DWH — это, согласно классическому определению Билла Инмона, предметно-ориентированное, интегрированное, неизменяемое хранилище исторических данных. В современных реалиях некоторые принципы (особенно неизменяемость) могут интерпретироваться более гибко для поддержки актуальных бизнес-сценариев. Оно предназначено для аналитики и позволяет облегчить принятие управленческих решений.
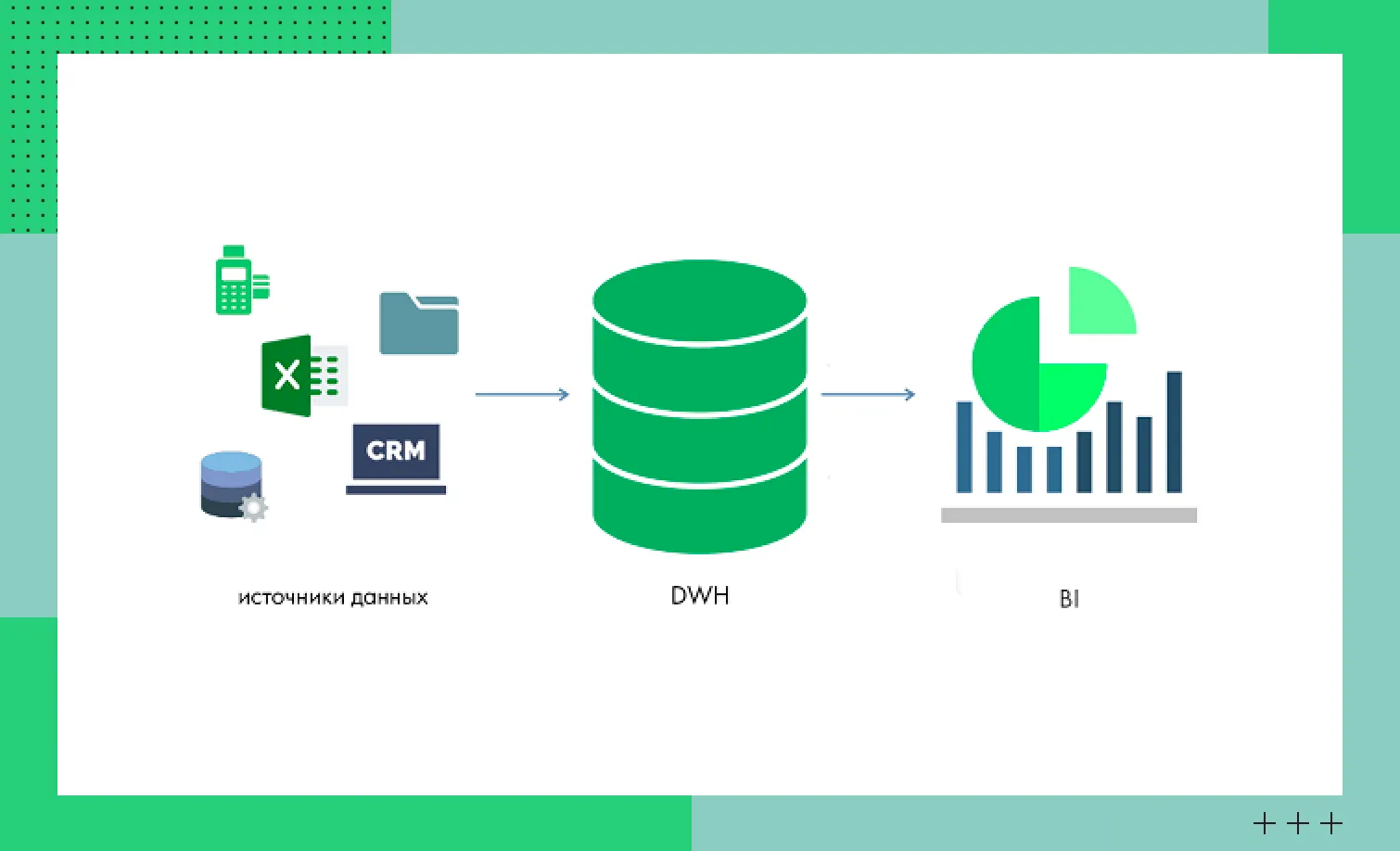
В хранилище стекаются данные из внутренних и внешних систем. Информация очищается, приводится к одному стандарту и хранится с учетом хронологии. Но Data Warehouse — не только хранилище. Это единый источник аналитической истины для компании.
Data Warehouse, в отличие от транзакционных систем, не предназначен для операционной работы — частых записей и обновлений. Решение применяется для сложных аналитических запросов, анализа тенденций и создания отчетности.
 Структура DWH
Структура DWH4 свойства DWH (по Биллу Инмону)
Хранилище базируется на четырех принципах — Subject-Oriented, Integrated, Nonvolatile, Time-Variant. Расшифруем, что это значит и чем полезно бизнесу:
Subject-Oriented — предметная ориентация. Данные в хранилище структурированы вокруг бизнес-сущностей, а не отдельных систем и процессов. Например, к сущностям относятся клиенты, сотрудники, продажи, товары и прочее. Такая ориентация позволяет анализировать данные в бизнес-контексте и упрощает создание отчетности.
Integrated — интегрированность. Данные из разных источников приводятся к единым стандартам. Это позволяет согласовать информацию между собой и представить ее в нужном для анализа формате.
Nonvolatile — неизменяемость. Данные добавляются, но редко обновляются и удаляются. Если это происходит, то по специальным процедурам. Суть в том, что новые данные добавляются поверх существующих. Это снижает риски потери информации, упрощает ретроспективный анализ и гарантирует достоверную отчетность.
Time-Variant — зависимость от времени. Каждая запись в хранилище имеет временную метку, чтобы можно было анализировать данные с привязкой к конкретному периоду и отслеживать изменение показателей.
Сочетание свойств делает Data Warehouse аналитическим хранилищем. Предметная ориентация отвечает за представление бизнес-контекста, интегрированность обеспечивает согласованность информации, неизменяемость — сохранность сведений и стабильность результатов аналитики, а зависимость от времени — возможность ретроспективного анализа.
Архитектура хранилища данных: классическая 3-уровневая модель
Трехуровневая архитектура хранилища обеспечивает своевременную интеграцию, упорядоченную обработку и логичное представление информации для аналитики и отчетности. Рассказываем, как процессы распределяются по уровням.
Нижний уровень: источники данных (Data Sources)
Это уровень систем, откуда данные поступают в хранилище и затем используются в аналитике. Примеры источников:
ERP и CRM;
OLTP‑базы;
бухгалтерские программы;
лог‑файлы;
текстовые и табличные файлы, экспортированные из приложений;
API сервисов;
сторонние базы данных.
На этом уровне идет сбор исходных данных в первоначальном виде. Затем происходят обработка и интеграция в хранилище.
Промежуточный уровень: область подготовки данных (Staging Area), ETL и ELT
Этот уровень — буфер между источниками информации и хранилищем. Компоненты — зоны Staging и процессы обработки данных.
Staging Area — область «сырых» данных. Информация временно хранится в том виде, в котором поступила из источников. Это позволяет собрать данные из разных систем и получить историю изменений до старта нормализации и обработки. Затем происходят процессы ETL и ELT:
ETL (Extract, Transform, Load) — классический подход, в котором сведения извлекаются из источников, затем трансформируются. Происходят очистка и нормализация, приведение к единому формату, добавление бизнес‑логики. После этого данные загружаются в DWH.
ELT (Extract, Load, Transform) — альтернативный подход, который стал особенно популярен с появлением облачных хранилищ данных. При этом данные загружаются в хранилище в исходном виде, а затем преобразуются внутри DWH или Lakehouse‑среды.
Цель уровня — обеспечить готовность сведений к интеграции и аналитике, организовать процессы контроля качества и консистентности данных перед загрузкой в хранилище.
Верхний уровень: представление для доступа (Presentation Area)
Здесь информация становится доступна конечному пользователю или аналитическому инструменту. Пример представления — витрины данных (Data Marts), оптимизированные под типичные запросы пользователей. Они предоставляют доступ к информации, связанной с конкретной областью, например, финансами или маркетингом.
На этом уровне работают сервисы доступа, например, BI‑инструменты и дашборды для визуального представления информации. Исторически важную роль играли OLAP‑кубы, однако современные BI-системы чаще работают напрямую с витринами данных через SQL-запросы к схемам «Звезда» или «Снежинка».
Готовое облачное решение для организации аналитического хранилища — сервис Advanced Data Warehouse Service от Cloud.ru. Он позволяет интегрировать данные из разных источников, масштабировать ресурсы и выполнять сложные запросы.
Сравнение DWH с операционными базами данных и Data Lake
Разные типы хранилищ и баз данных решают свои задачи, поэтому не будут взаимозаменяемыми — скорее они дополняют друг друга. Чтобы понять разницу в логике и функционале, сравним Data Warehouse с OLTP-базы и Data Lake.
OLTP ( Online Transaction Processing) — транзакционная система обработки. Она работает с небольшими транзакциями и обеспечивает непрерывную запись информации в БД. Сравнение с Data Warehouse:
Критерий | DWH | OLTP |
Назначение | Анализ данных и поддержка принятия управленческих решений | Обработка бизнес-транзакций |
Тип операций | Чтение больших объемов данных | Частые операции записи и чтение небольших порций данных |
Характер запросов | Сложные аналитические запросы, агрегации | Небольшие транзакции |
Структура данных | Специальные схемы, оптимизированные для аналитики («Звезда», «Снежинка») | Нормализованные схемы, оптимизированные для целостности транзакций |
Временные рамки | Исторические данные за долгий период | Поддержка актуальности данных |
Использование | Глобальная аналитика, BI-системы | Приложения, операционные сервисы |

Data Lake — централизованное хранилище для больших объемов структурированных, полуструктурированных и неструктурированных сведений в исходном формате без очистки и нормализации. Сравнение с Data Warehouse:
Критерий | DWH | Data Lake |
Тип данных | Структурированные и нормализованные | Любые — «сырые», структурированные и неструктурированные |
Подход к схеме | Schema-on-Write — схема при загрузке | Schema-on-Read — схема при чтении |
Качество данных | Стандартизированные и очищенные сведения | Очистка проводится редко |
Пользователи | В первую очередь бизнес-аналитики и менеджеры, но также инженеры данных для подготовки данных | Инженеры данных, data scientists, аналитики |
Цель использования | Отчетность и регламентная аналитика | Исследовательский анализ, ML и эксперименты |
Гибкость | При изменениях данных нужны доработки схемы | Можно хранить любые сведения без доработок |
Data Lake дешевле для хранения неструктурированных данных любого объема, но требует значительных усилий по их последующей обработке и обеспечению качества. DWH обеспечивает предсказуемую производительность и высокое качество данных для бизнес-аналитики, но менее гибок для работы с сырыми данными и требует более тщательного проектирования.
Моделирование данных в DWH: схемы «Звезда» и «Снежинка»
Модель организации напрямую влияет на параметры аналитического хранилища. В Data Warehouse ставка сделана не на минимизацию информации, а на удобство анализа. Два распространенных подхода к моделированию — «Звезда» и «Снежинка».
Денормализация как главный принцип
Денормализация — состояние структуры базы данных, которое достигается путем добавления избыточных сведений и объединения таблиц. Это позволяет уменьшить количество JOIN-операций при выполнении аналитических запросов к хранилищу и увеличить скорость обработки больших объемов информации.
В классических БД избыточность структуры будет мешать, поэтому идет разделение на таблицы. Например, будет две отдельные таблицы — клиенты и продажи. В аналитическом хранилище имя клиента сразу вносится в таблицу продаж. Это ускоряет аналитику и убирает необходимость при каждом запросе объединять таблицы для получения полных сведений.
Важно отметить, что схемы «Звезда» и «Снежинка» являются не просто денормализованными, а специально спроектированными структурами, где таблица фактов содержит числовые показатели (меры), а таблицы измерений — описательные атрибуты.
Схема «Звезда» (Star Schema)
В этой схеме центральное место занимает таблица фактов (Sales_Fact), куда стекаются огромные объемы данных. Содержит числовые метрики, такие, как количество клиентов, суммы продаж и прочее. Они отображают показатели бизнеса или события внутри инфраструктуры. Также таблица фактов содержит внешние ключи для связи с таблицами измерений.
Таблицы измерений содержат сведения, описывающие контекст появления фактов. Например, такие атрибуты, как регион, название магазина, канал продаж, дата сделки и другие. Информация позволяет детализировать аналитические запросы.
Схема «Звезда» используется в BI-системах и построении витрин данных. Она популярна благодаря простой и наглядной структуре, минимальному количеству связей между таблицами и высокой скорости выполнения запросов.
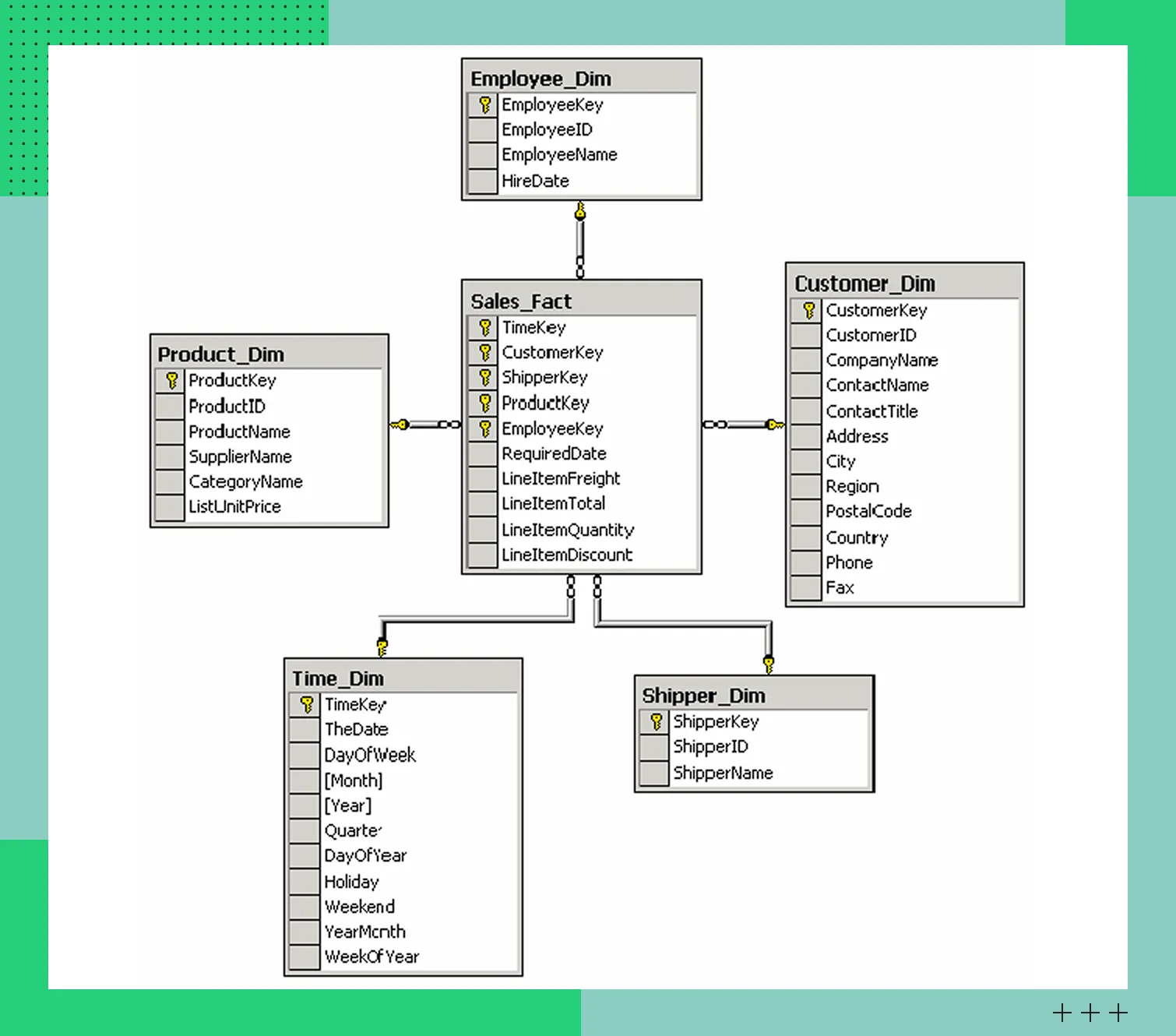 Пример схемы «Звезда»
Пример схемы «Звезда»Схема «Снежинка» (Snowflake Schema)
В этой схеме тоже есть таблицы фактов и измерений. Отличие от предыдущей схемы в том, что здесь измерения разбиваются на несколько таблиц, что позволяет вынести в отдельные сущности повторяющиеся атрибуты. Подход позволяет систематизировать большие объемы информации и сэкономить дисковое пространство. Но есть весомый минус — из-за многочисленных таблиц снижается производительность запросов.
Схема «Снежинка» используется реже, чем «Звезда». Ее выбирают в тех случаях, когда нормализация данных важнее скорости выполнения аналитических запросов.
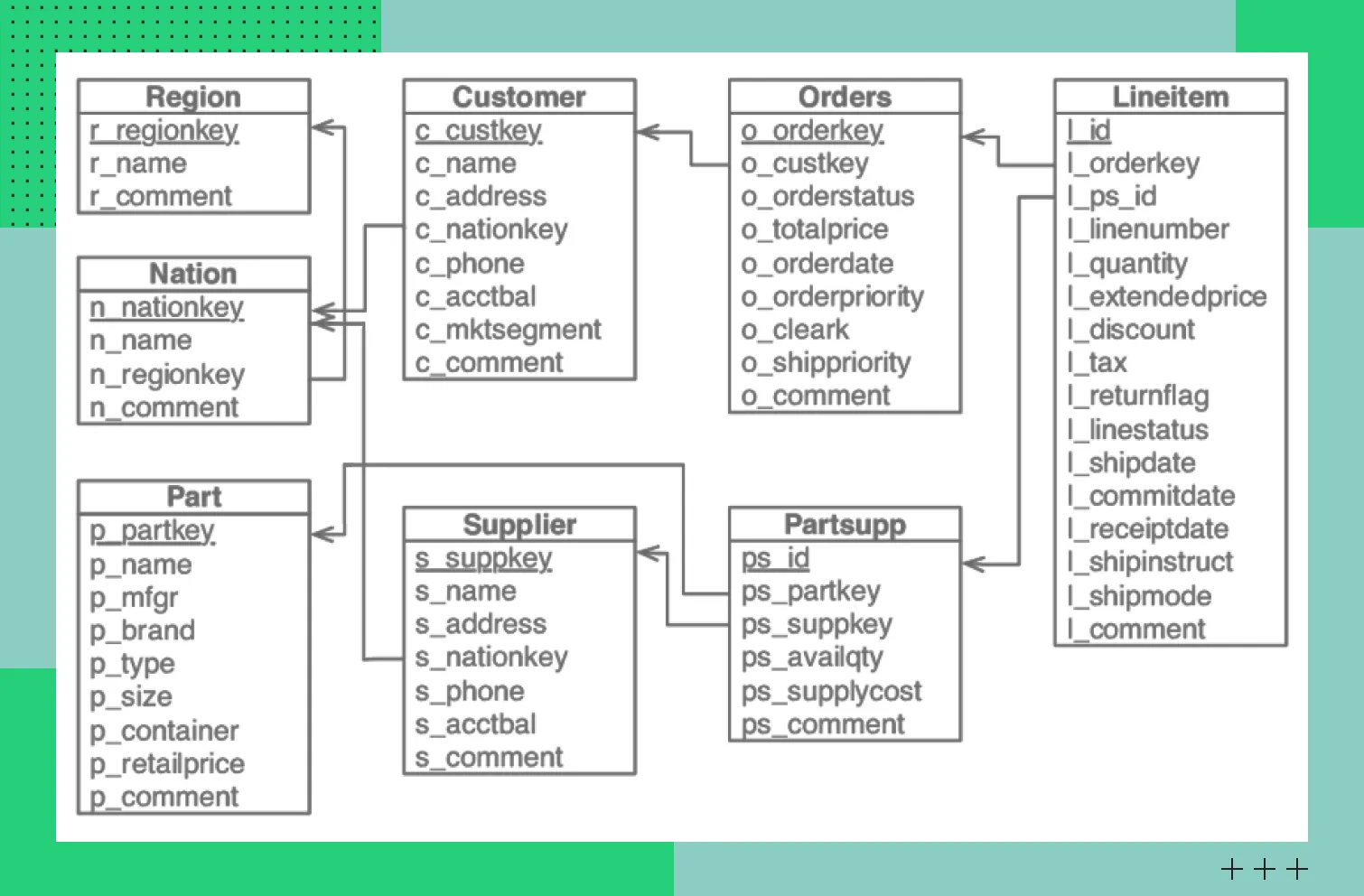 Пример схемы «Снежинка»
Пример схемы «Снежинка»Технологический стек и популярные платформы DWH
Современные корпоративные хранилища базируются на разных технологических подходах — от традиционных on premise СУБД до облачных и lakehouse-архитектур. Описываем классы технологий и их значение в DWH-ландшафте.
Классические (MPP) СУБД
Классические DWH-платформы строятся на MPP-архитектуре (Massively Parallel Processing). Это значит, что аналитические запросы параллельно выполняются на нескольких узлах. Таким образом удается добиться желаемой производительности и избежать задержек.
Примеры MPP-СУБД — Greenplum, Vertica и Teradata. Контент в системах четко структурирован, запросы — оптимизированы. Эти решения обеспечивают предсказуемую производительность в сложных сценариях. Только используются они в основном в компаниях со сложившимися процессами аналитики. В остальных случаях их внедрять нецелесообразно из-за дорогостоящей лицензии, сложности сопровождения и масштабирования.
Облачные хранилища данных (Cloud DWH)
Cloud DWH — доминирующий тренд и рекомендуемый выбор для новых аналитических проектов. От классических СУБД многие перешли к облачным, например, Google BigQuery, Snowflake и Amazon Redshift.
Идея облачных хранилищ — разделение хранения и вычислений. Это значит, что сведения будут храниться отдельно, а вычислительные ресурсы масштабироваться под текущую нагрузку. Это позволяет бизнесу не думать о развитии инфраструктуры и сосредоточиться на аналитике.
Такие решения подходят для быстрорастущих компаний и аналитических команд, у которых в приоритете гибкость. Они быстро внедряются и легко эксплуатируются. Оплата происходит по модели pay-as-you-go — бизнес платит только за объем данных и выполненные запросы, что позволяет избежать нецелевых расходов. Весомый минус у решений один — зависимость от облачного провайдера.
Аналитические платформы на базе Hadoop и Spark
Для аналитической работы с большими данными используются распределенные вычислительные движки, такие как Apache Spark. Spark SQL предоставляет SQL-интерфейс для работы с различными форматами данных. В современных архитектурах эти технологии чаще выступают как вычислительный слой поверх облачных хранилищ (S3, GCS) в парадигме Lakehouse, чем как самостоятельные платформы для DWH.
Минусы использования аналитических платформ: сложные настройка и поддержка, зависимость производительности от форматов сведений и необходимость в зрелой инженерной экспертизе.
Инструменты ETL и ELT
ETL и ELT-инструменты отвечают за интеграцию контента в хранилище и его преобразование. ETL — классический подход, в рамках которого информация преобразуется еще до загрузки в целевую систему. ELT подразумевает интеграцию «сырых» сведений в хранилище и трансформацию внутри него.
Распространенные ETL и ELT-инструменты и их задачи:
Apache Airflow — решение для оркестрации пайплайнов. Отвечает за управление расписаниями, задачами и зависимостями. Инструмент не трансформирует данные, а координирует процессы.
Informatica и Talend — enterprise-решения, которые предоставляют визуальные интерфейсы и готовые коннекторы для синхронизации сведений. Они подходят для бизнеса с большим количеством разрозненных источников информации.
dbt — инструмент, который позволяет инженерам данных и аналитикам с помощью SQL-запросов преобразовывать, тестировать и документировать информацию внутри.
В современном стеке данных часто используется разделение ответственности: разные инструменты решают разные задачи (оркестрация, трансформация, репликация). Например, типичный стек может включать Apache Airflow (оркестрация), dbt (трансформация) и Fivetran (репликация). Такой комплекс обеспечивает повторяемость, управляемость и надежность потоков данных в DWH.
Процесс проектирования и внедрения DWH
Чтобы создать масштабируемое хранилище, нужно поэтапно подойти к внедрению. Опишем пять этапов.
Определение бизнес-требований и KPI
Необходимо сформировать цели внедрения DWH и определить показатели эффективности. Для грамотного проектирования хранилища нужно составить список источников, откуда будут поступать данные. Также важно придумать уровень детализации и обозначить требования к периодичности обновления информации.
Проектирование модели данных
Исходя из бизнес-требований нужно выбрать схему моделирования и спроектировать таблицы фактов и измерений. На этом этапе задаются требования к хранению истории и обработке изменений в табличных записях.
Разработка и настройка ETL и ELT-процессов
На этом этапе реализуются процессы извлечения данных из источников, очистки, нормализации и загрузки в хранилище. После настроек следует продумать методы контроля качества представления информации и обработки ошибок.
Реализация витрин данных и инструментов доступа
Поверх ядра DWH нужно создать витрины данных, которые должны быть оптимизированы под конкретные аналитические задачи и пользователей. Настраиваются инструменты доступа к информации, например, BI-платформы, и аналитические панели. Они обеспечивают безопасную работу со сведениями.
Мониторинг, оптимизация и сопровождение
После ввода хранилища в эксплуатацию нужно постоянно контролировать качество и целостность данных, производительность и скорость выполнения запросов. С этой целью организовывается непрерывный мониторинг работы DWH.
Чтобы хранилище поддерживало новые аналитические сценарии, нужно периодически дорабатывать модель данных и ETL-процессы с учетом бизнес-требований.
Преимущества и недостатки внедрения DWH
Внедрение традиционных on premise DWH — дорогостоящий, трудоемкий процесс. Однако облачные управляемые сервисы значительно снизили порог входа, перенося сложность инфраструктуры на провайдера.
Корпоративное хранилище данных несет бизнесу как преимущества, так и серьезные издержки. Сильные и слабые стороны:
Преимущества DWH | Недостатки и сложности |
Получение единого источника структурированных данных | Немалая стоимость внедрения |
Выполнение сложной аналитики | Длительные сроки реализации |
Повышение качества данных за счет очистки и соблюдения стандартов работы с информацией | Требуется команда Data Engineers для внедрения и сопровождения хранилища |
Легкий доступ к данным | Отсутствие гибкости из-за сложной адаптации решения к частым изменениям требований |
Современные тенденции: от DWH к Data Lakehouse
Классическое корпоративное хранилище Data Warehouse подходит для структурирования данных и аналитики, но не отличается гибкостью при работе с разными типами информации и плохо адаптируется к изменениям в бизнесе. На смену пришла концепция Lakehouse, объединяющая преимущества DWH и Data Lake. Разберемся, чем она лучше.
Суть концепции Lakehouse
Концепция подразумевает хранение «сырых» данных как в Data Lake, транзакционность и управление схемой как в DWH. Идеи:
Хранение структурированных, полуструктурированных и неструктурированных сведений в одной платформе.
Обеспечение консистентности и надежности операций за счет ACID-транзакций и управления схемой данных.
Приближение производительности к DWH-уровню за счет оптимизации запросов и индексации.
Использование единого хранилища для аналитики и ML-задач.
Такая архитектура позволяет сочетать в одном решении гибкость и масштабируемость Lake с последовательностью, управляемостью и оптимизацией запросов DWH.
Технологии: Delta Lake, Apache Iceberg, Apache Hudi поверх облачных хранилищ (S3, GCS)
Концепцию Lakehouse удается реализовать за счет стека инструментов, которые обеспечивают поддержку аналитики, BI- и ML-нагрузок в одной системе. Что чаще всего используют:
Технология | Суть внедрения |
Delta Lake | Добавляет ACID-транзакции, управление схемой и концепцию time travel поверх облачного хранилища |
Apache Iceberg | Поддержка транзакций и управление метаданными |
Apache Hudi | Поддержка версионирования, потоковой обработки и инкрементальных обновлений данных |
Облачные хранилища (S3, GCS) | Реализация линейно масштабируемых систем хранения, которые ложатся в основу Lakehouse-таблиц |
Заключение
С помощью DWH можно устранить проблему разрозненных данных в компании, организовать централизованное хранилище с единой логикой и обеспечить ретроспективный анализ. Внедрять технологию дорого и трудоемко, поэтому решение подходит не для всех. Оно используется большими компаниями, где важны качество сведений, достоверная аналитика и принятие управленческих решений.