Elasticsearch: что это такое, как работает и где применяется
В условиях растущих объемов информации компаниям нужны инструменты для быстрого поиска и анализа нужных сведений. Для этих целей можно использовать проверенное надежное решение Elasticsearch, способное работать с неструктурированными данными. Рассказываем, зачем оно нужно, в какие сценарии впишется и чем поможет бизнесу.


- Что такое Elasticsearch
- Архитектура и понятия: как организованы данные
- Для чего нужен Elasticsearch: сценарии использования
- Возможности и «умные» функции поиска
- Сравнение с реляционными базами данных и другими решениями
- Экосистема Elastic Stack (ранее ELK Stack)
- Преимущества и недостатки Elasticsearch
- Как начать работать с Elasticsearch: первые шаги
- Тренды и будущее: Machine Learning, Observability, Security (SIEM)
- Заключение
Что такое Elasticsearch
Это распределенный поисковый и аналитический движок на базе библиотеки Apache Lucene. Он предназначен для хранения, поиска и анализа больших объемов данных в реальном времени. Построен на открытом коде, легко масштабируется и быстро работает.
Особенности решения:
Распределенная архитектура. Данные хранятся в формате индексов, разбитых на сегменты и распределенных по узлам кластера.
Полнотекстовый сложный поиск. Ранжирование по релевантности, учет морфологии и синонимов, исправление опечаток.
Работа с Big Data. Оптимизация для поиска по огромному количеству данных, анализ метрик и логов, мониторинга состояния инфраструктуры.
JSON REST API. Хранение данных в формате JSON, операции через HTTP-запросы.
Решение часто работает в стеке Elastic Stack в связке с такими инструментами, как Beats для сбора данных из источников, Logstash для обработки и Kibana для визуализации.
 Интерфейс системы
Интерфейс системыФилософия: извлечение смысла из неструктурированных данных
Elasticsearch подходит для работы с полуструктурированными и неструктурированными данными. Это информация, которая разрозненно хранится в разных форматах. Форматы заранее неизвестны, как и формулировки пользовательских запросов. В таком случае стоит задача не просто сопоставить строки, но и интерпретировать результаты.
Elasticsearch адаптирован для анализа таких данных. Информация проходит лингвистическую обработку — текст нормализуется, приводится к определенным форматам, разбивается на термины. Это позволит искать нужные документы по смыслу даже при различиях формы слов в данных пользовательских запросов.
Также реализованы механизмы нечеткого поиска, которые позволяют сопоставлять термины по сходству даже с учетом неточного ввода и опечаток. Поддерживается работа с альтернативными выражениями и синонимами в запросах. Elasticsearch автоматически расширяет запросы связанными терминами и рассматривает документы с похожими словами как релевантные.
Результаты поиска ранжируются в соответствии с моделью релевантности. Elasticsearch оценивает приоритет каждого документа в зависимости от запроса с учетом веса полей, частоты терминов и других факторов. В результате система не только ищет данные, а проверяет, насколько они соответствуют запросу.
Смысл философии — извлекать смысл из неструктурированных данных и в условиях неоднородности информации обеспечивать релевантный поиск в соответствии с пользовательскими запросами.
Архитектура и понятия: как организованы данные
Рассмотрим пять сущностей, связанных с Elasticsearch — документы, индексы, шарды, кластеры и инвертированные индексы.
Документ (Document): единица хранения (JSON-объект)
Документ — это JSON-объект, куда включен набор полей с данными. Как он может выглядеть:
У каждого документа есть свой идентификатор _id, который позволяет быстро искать нужные объекты.
Индекс (Index): коллекция документов
Индекс — это логическая коллекция документов, которая объединена по назначению или структуре. Это аналог таблиц в классических базах данных. С помощью индекса можно выполнять поиск и агрегацию информации среди документов.
Шарды (Shards): горизонтальное партиционирование индекса для распределения и масштабирования
Для масштабирования и отказоустойчивости Elasticsearch разбивает индекс на шарды. Есть основной Primary Shard и его копия — Replica Shard. Копия нужна для обеспечения отказоустойчивости системы и балансировки нагрузки. Шарды могут находиться на любом узле кластера. При появлении новых узлов Elasticsearch их перераспределяет.
Кластер (Cluster): совокупность узлов (Nodes) Elasticsearch
Кластер объединяет узлы, которые хранят данные и обслуживают запросы. У каждого узла может быть одна или несколько ролей:
Master Node — управляет состоянием кластера, распределением шардов и изменениями конфигурации;
Data Node — хранит данные и обрабатывает запросы;
Ingest Node — отвечает за предварительную обработку сведений перед индексированием;
Coordinating Node — принимает запросы и направляет их к другим узлам.
Все узлы по умолчанию могут выполнять роль Coordinating Node.
Инвертированный индекс (Inverted Index): секрет скорости поиска
На инвертированном индексе построен поиск в Elasticsearch. Каждому слову соответствует список документов, где оно встречается. При поиске Elasticsearch не проверяет все документы, а обращается к конкретному слову и его списку. Таким образом удается быстро обнаруживать нужную информацию даже среди больших объемов.
Для чего нужен Elasticsearch: сценарии использования
Система применяется во многих сценариях аналитики. Для понимания принципов работы опишем распространенные.
Умный поиск в e-commerce и веб-сайтах
Elasticsearch часто служит поисковым движком для сайтов, интернет-магазинов и маркетплейсов. Система позволяет выполнять автодополнение поисковых запросов, исправлять неточный ввод и обрабатывать опечатки. Также с ее помощью можно осуществлять сложную фильтрацию по многочисленным параметрам и ранжировать результаты по релевантности.
Благодаря механизму скоринга учитываются популярность товаров, предпочтения клиентов, бизнес-правила и другие параметры. Это положительно влияет на пользовательский опыт и повышает конверсию.
Анализ и визуализация логов (Elastic Stack)
Централизованный сбор и анализ логов осуществляются с помощью связки инструментов Elastic Stack (ранее ELK Stack). Elasticsearch отвечает за хранение и оперативный поиск данных, Logstash или Beats за сбор информации, обогащение и обработку, Kibana — за визуальное представление и анализ.
Такой сценарий позволяет с помощью Elasticsearch в реальном времени анализировать поведение систем, находить аномалии и ошибки в работе, строить дашборды. Решение можно горизонтально масштабировать и адаптировать под микросервисную архитектуру и распределенную инфраструктуру.
Мониторинг приложений и инфраструктуры (APM)
Elasticsearch участвует в мониторинге производительности приложений и инфраструктуры. За сбор данных и трассировку запросов отвечают агенты, такие, как Elastic APM и Metricbeat.
Мониторинг позволяет контролировать нагрузку, отслеживать задержки и ошибки. По результатам создаются отчеты о проблемах и настраиваются алерты.
Поиск по документам и контенту
Elasticsearch часто используется для поиска по неструктурированным и полуструктурированным данным разных форматов. Например, PDF-документам, файлам Word, HTML-страницам, электронным письмам и сообщениям в мессенджерах.
С помощью Ingest Pipelines можно извлекать контент и метаданные, выполнять нормализацию и обогащение информации. Эти возможности делают Elasticsearch востребованным решением для систем электронного документооборота, корпоративных баз знаний и порталов.
Геопространственный поиск (Geo Search)
Elasticsearch может работать с геоданными и предоставляет инструменты для геопространственного поиска. Например, система фильтрует объекты по принципу «рядом со мной», помогает искать координаты и объекты в заданном радиусе.
Эти возможности Elasticsearch пользуются спросом в сферах логистики, аналитики, навигации, доставки и других отраслях. Везде, где нужно быстро обрабатывать запросы, связанные с местоположением объектов.
Возможности и «умные» функции поиска
Система выполняет не только поиск, но и другие сопутствующие операции. Разберем востребованные в разных отраслях.
Токенизация и анализ текста (Analyzers)
Анализ выступает одним из ключевых этапов обработки данных при индексации и выполнении запросов. Для удобства текст разбивается на токены, которые затем подвергаются нормализации, то есть очищаются и приводятся к единому формату. Возможные этапы:
приведение к нижнему регистру;
удаление стоп-слов;
стемминг или лемматизация.
Анализ выполняется с помощью анализатора, действующего по заранее заданному алгоритму. Например, текст может быть предварительно очищен от лишних символов и HTML, затем разбит на отдельные слова и приведен к базовой форме. Этот же анализатор применяется при индексации и обработке запросов, благодаря чему можно сопоставлять документы не только по совпадению текста, но и по смыслу.
Поиск с учетом морфологии и нечеткий поиск (Fuzzy Search)
Elasticsearch поддерживает поиск с учетом морфологии и опечаток. Это значит, что разные формы слова могут приводиться к общей основе, что позволяет сопоставлять запросы и данные не только по точному написанию, но и по смыслу.
Примеры: поле → полевой, кофэ → кофе.
Механизмы нечеткого поиска позволяют находить запрошенные документы даже при условии опечаток и неточного ввода.
Автодополнение (Autocomplete) и предложения (Search-as-you-type)
Elasticsearch поддерживает поиск по мере ввода текста и автодополнение. Данные могут разбиваться на части с помощью n-грамм и edge n-gram. При индексации сохраняются не только целые слова, но и начальные фрагменты. Благодаря этому система может подбирать релевантные варианты и мгновенные подсказки тогда, когда пользователь ввел запрос не до конца.
Ранжирование по релевантности (TF и IDF, BM25)
Это свойство помогает определять порядок документов в результатах поиска. Elasticsearch с использованием разных алгоритмов проверяет, точно ли обнаруженные документы соответствуют запросу. Система учитывает, насколько часто присутствуют указанные термины в документе и во всем индексе. По умолчанию используется модель ранжирования BM25, которая позволяет сравнивать короткие и длинные тексты.
Агрегации (Aggregations): аналитика поверх поиска
Агрегации позволяют поверх результатов поиска выполнять аналитические операции. Например, вычисление числовых метрик (avg, sum), группировку документов (terms), построение гистограмм по времени. Это помогает формировать статистику без использования отдельной аналитической системы.
Сравнение с реляционными базами данных и другими решениями
Elasticsearch отличается от классических реляционных баз и других поисковых систем. Различия по значимым параметрам:
Параметр | Elasticsearch | Реляционные БД (MySQL, PostgreSQL) | Apache Solr |
Поиск | Полнотекстовый с анализом морфологии, синонимов, релевантности | LIKE '%text%' или полнотекстовый модуль (FTS). В современных СУБД (например, PostgreSQL) FTS поддерживает лемматизацию и ранжирование, но уступает Elasticsearch в скорости на больших объемах и горизонтальном масштабировании | Полнотекстовый поиск на базе Lucene, схож с Elasticsearch |
Схема | Гибкая (dynamic mapping, JSON-документы) | Строгая, таблицы и колонки | XML и JSON-конфигурации, требует настройки схемы |
Масштабирование | Горизонтальное «из коробки», шардирование, реплики | Горизонтальное — шардирование вручную, репликация через слейвы | Горизонтальное, требует ручной настройки |
Оптимизация | Для поиска, агрегаций и аналитики | Для транзакций, целостности и согласованности данных | Для полнотекстового поиска, менее развит аналитический функционал |
Экосистема | Elastic Stack: Kibana, Beats, Logstash, ML, Observability | SQL-клиенты, BI-инструменты, слабые аналитические расширения | Слабые инструменты визуализации, меньше интеграций |
Использование | Старт через Docker, Elastic Cloud и единые API | Требуется настройка схем, индексов и связей | Требует ручной конфигурации и интеграции, сложнее в масштабировании |
Elasticsearch подходит не для всех сценариев. Систему нецелесообразно использовать как источник истины без внешнего бэкапа, для работы со сложными связями и там, где действуют строгие требования ACID.
Экосистема Elastic Stack (ранее ELK Stack)
Elastic Stack — это стек инструментов для сбора, обработки, анализа и хранения данных. Он полезен при работе с большими объемами информации. Раньше компоненты стека решали свои задачи, теперь они объединились в экосистему. Рассказываем назначение ключевых инструментов.
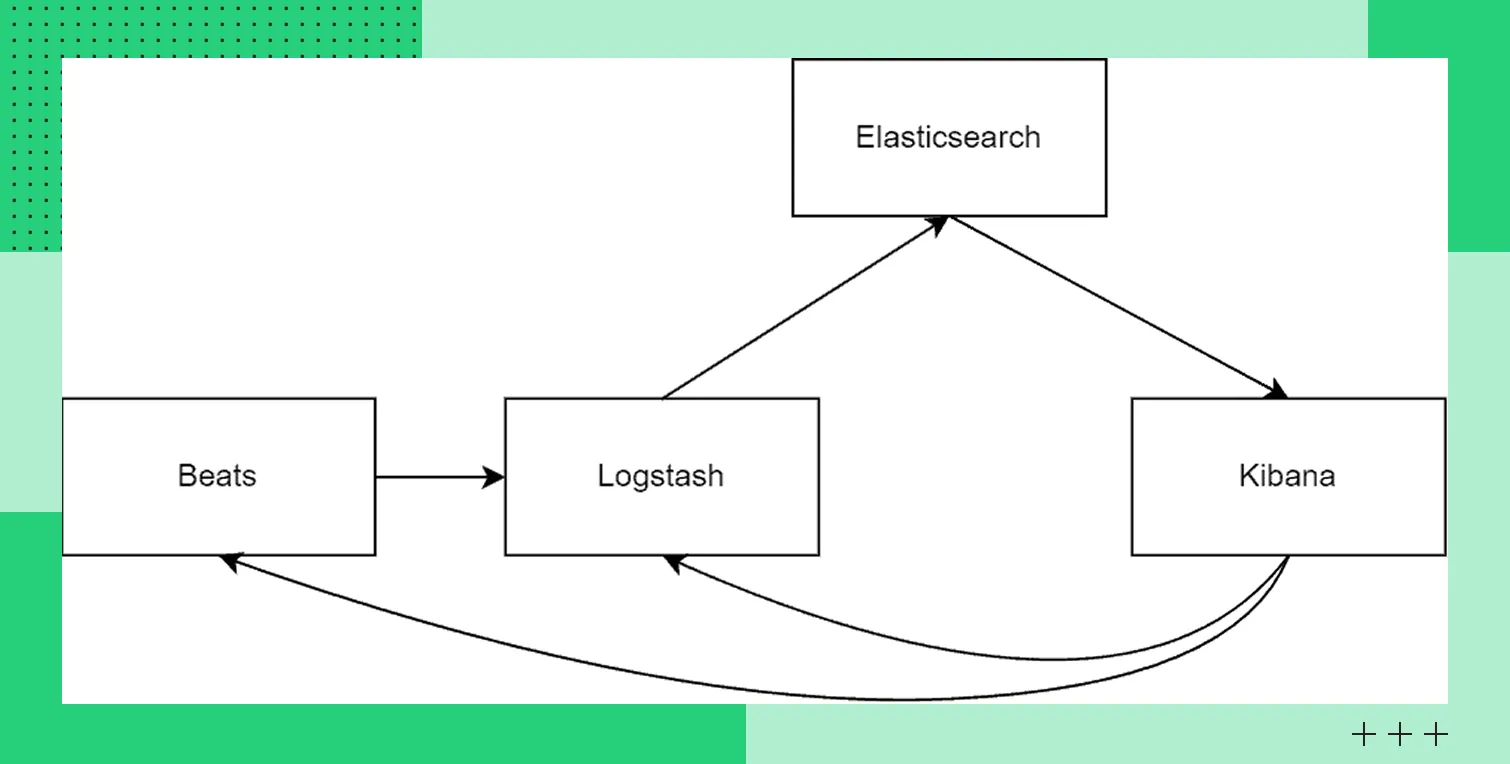 Экосистема инструментов
Экосистема инструментовBeats: легковесные агенты для отправки данных
Beats — это набор агентов для отправки данных из источников в Elasticsearch или Logstash. Агенты оптимизированы под разные типы данных, например:
Filebeat работает с лог-файлами приложений, системными логами и журналами событий. Поддерживает фильтрацию и многопоточную обработку.
Metricbeat — отвечает за метрики ОС и различных сервисов, такие, как CPU, память, сетевая активность, состояние веб-серверов и другие.
Packetbeat — работает с сетевым трафиком, протоколами, производительностью приложений и в реальном времени формирует метрики.
Beats имеют минимальную конфигурацию, поэтому потребляют мало ресурсов. Благодаря этому их можно развернуть на множестве серверов.
Logstash: конвейер для обработки данных
Logstash — это серверный компонент ELK-стека, предназначенный для централизованной обработки потоков данных перед отправкой в Elasticsearch. Он позволяет собирать информацию из различных источников, применять трансформации и фильтры, маршрутизировать и передавать сведения в конечные пункты. Не только в Elasticsearch, а, например, в Kafka или другие хранилища. Logstash полезен, если нужны корреляция событий или предварительная агрегация данных.
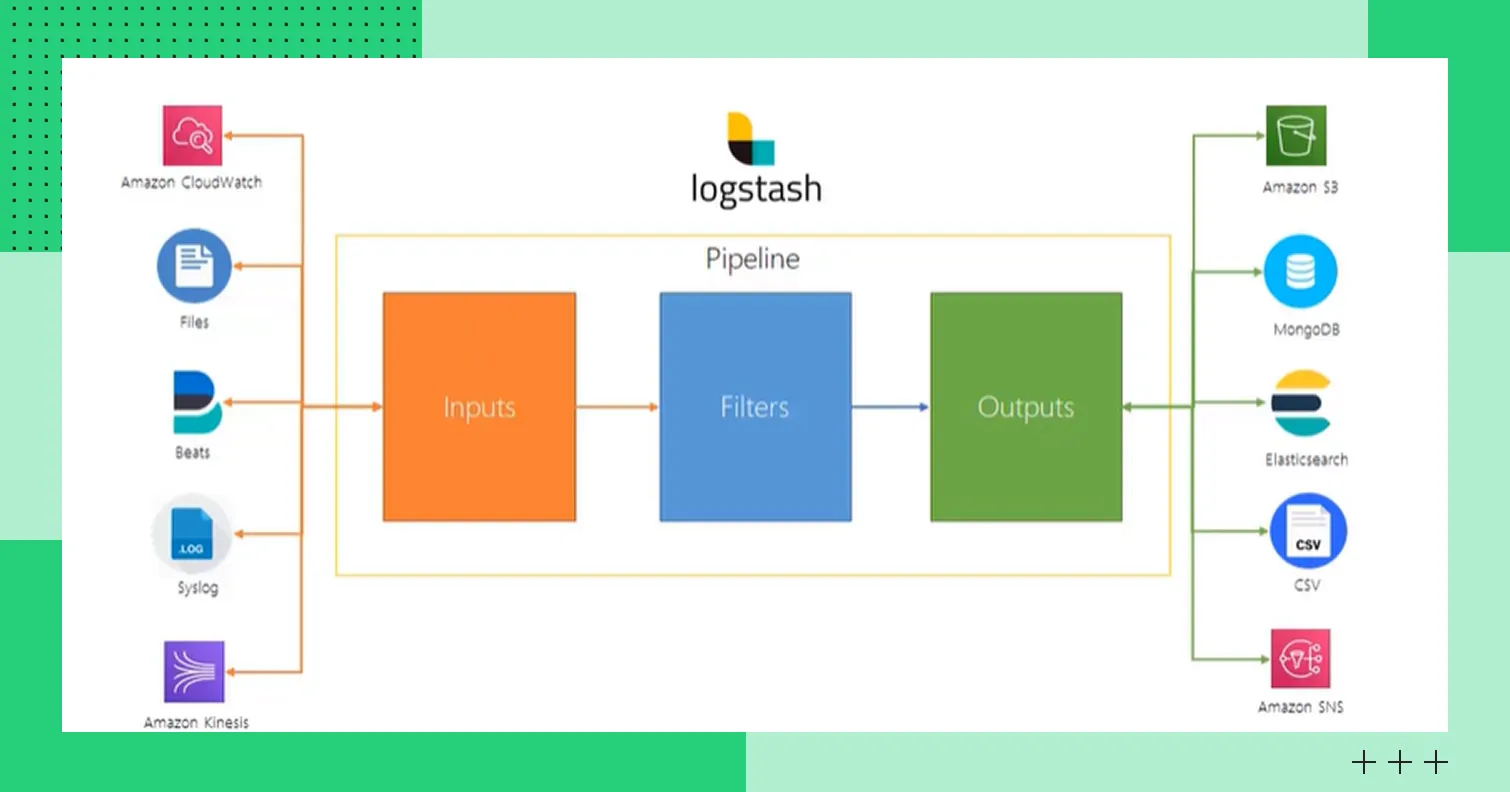 Принцип работы Logstash
Принцип работы LogstashKibana: веб-интерфейс для поиска, визуализации и управления
Kibana предоставляет графический интерфейс для работы с данными. Он позволяет создавать дашборды для визуализации логов и данных, презентации с визуальными элементами, графики и диаграммы. Kibana также применяется для управления индексами, создания алертов и настройки политик безопасности.
 Пример графического интерфейса
Пример графического интерфейсаПреимущества и недостатки Elasticsearch
У Elasticsearch много сильных сторон, но есть и недостатки, связанные с особенностями архитектуры и возможностями эксплуатации. Для наглядности преимущества и минусы приведем в таблице:
Преимущества | Недостатки |
Высокая скорость полнотекстового поиска и аналитических агрегаций | Сложная настройка и тонкая оптимизация для продакшена |
Горизонтальная масштабируемость и механизмы отказоустойчивости | Система — не источник истины, данные поступают из первичных хранилищ |
Развитая экосистема программного комплекса Elastic Stack — Kibana, Beats, Logstash и другие инструменты | Риск потери данных при неправильной конфигурации, из-за чего необходимы регулярные бэкапы |
Гибкая схема данных и удобный RESTful API | Высокое потребление ресурсов, в частности, оперативной памяти |
Поддержка поиска по смыслу, определение релевантности и неполных совпадений | Лицензионные ограничения: базовая функциональность Elasticsearch доступна по лицензии Apache 2.0, однако расширенные функции (машинное обучение, расширенная безопасность, оповещения и др.) требуют платной подписки или входят в коммерческие продукты Elastic |
Как начать работать с Elasticsearch: первые шаги
Нужно разобраться, как быстро запустить поисковую систему и какие операции можно выполнять. Описываем базовые аспекты, которых достаточно для начала работы.
Локальный запуск через Docker
Разумный вариант — запустить Elasticsearch локально с помощью Docker. Воспользуйтесь командами:
После запуска проверьте доступность сервиса через браузер HTTP-запросом к http://localhost:9200. Вернется ответ с информацией о версии и состоянии кластера.
В этом режиме Elasticsearch будет работать в качестве одиночного узла, что подходит для локальной разработки и обучения. Порт 9200 применяется для REST API, порт 9300 — для внутреннего взаимодействия узлов.
Базовые операции через REST API (cURL или Kibana Dev Tools)
Elasticsearch управляется через REST API. В основе операций — HTTP-методы. Данные представляются в формате JSON.
Базовый набор действий включает:
Создание индекса — логического пространства для хранения документов. Если индекс явно не создан, Elasticsearch автоматически может его сформировать при первой записи документа.
Добавление документа — сохранение в индекс JSON-объекта. Каждому документу присваивается уникальный идентификатор. Также объекты индексируются для дальнейшего поиска.
Простой поиск — выполнение запроса через endpoint _search. Например, запрос вида GET /_search?q=test выполняет поиск документов, которые содержат термин test. Используется простой query string синтаксис.
Для работы с API можно использовать cURL командной строки. Однако удобнее Kibana Dev Tools — компонент Kibana, который предоставляет консоль для прямого взаимодействия с REST API.
Запросы на языке Query DSL
Для управляемого поиска Elasticsearch применяет свой язык запросов — Query DSL, основанный на JSON-синтаксисе. Какие бывают запросы:
match — применяется для полнотекстового поиска по документам. Подходит для работы с естественным языком.
term — обеспечивает поиск точных совпадений без анализа. Используется для фильтрации по идентификаторам документов, ключевым словам, статусом и другим заранее известным значениям.
range — нужен для поиска документов по диапазонному значению, например дат и чисел.
bool — позволяет комбинировать несколько типов запросов, задавать дополнительные условия и проводить фильтрацию, которая не повлияет на релевантность результатов.
Благодаря Query DSL можно строить сложные аналитические и поисковые запросы, что упрощает работу с большими объемами разноформатной информации.

Облачные managed-сервисы: Elastic Cloud, AWS OpenSearch
Если хочется обойтись без администрирования инфраструктуры, можно работать с помощью облачных управляемых сервисов. Например:
Elastic Cloud — решение от компании Elastic. Предлагает свежие версии Elasticsearch, интеграцию с Kibana, резервное копирование данных и автоматическое масштабирование системы поиска.
AWS OpenSearch — сервис от Amazon, основанный на OpenSearch. Его главное преимущество — простая интеграция с экосистемой AWS. Решение можно использовать для управления кластерами.
Оба облачных решения позволяют использовать Elasticsearch и сопутствующие инструменты без сложных настроек и ручных обновлений. Этот вариант подходит для новичков и небольших команд.
Можно использовать управляемый облачный сервис Advanced Cloud Search Service от Cloud.ru. Он позволяет быстро разворачивать и масштабировать поисковые кластеры на базе Elasticsearch без самостоятельной настройки серверов. Сервис подходит для реализации умного поиска на сайтах и в приложениях, анализа терабайтов данных.
Если же вам требуется больше гибкости или полный контроль над инфраструктурой, вы можете развернуть Elasticsearch на виртуальных машинах Evolution Compute. Сервис предлагает гибкие конфигурации CPU, RAM и дисков, управление через API и Terraform, безопасное подключение по SSH, а также оплату только за фактически использованные ресурсы — идеально для разработки, тестирования и production-сред.
Тренды и будущее: Machine Learning, Observability, Security (SIEM)
Elasticsearch находит применение во многих областях, таких, как автоматизация анализа данных с помощью машинного обучения, представление состояния корпоративных систем, информационная безопасность. Решение предстает в качестве масштабируемого хранилища, инструмента для поиска нужных сведений и корреляции событий. Примеры использования и польза для бизнеса:
Направление | Назначение | Роль Elasticsearch | Суть |
Machine Learning | Автоматическое выявление закономерностей и аномалий | Встроенные возможности машинного обучения (доступны по платной подписке) позволяют автоматически выявлять аномалии во временных рядах, прогнозировать поведение систем и обнаруживать угрозы безопасности без необходимости разработки собственных моделей. Elasticsearch выступает как хранилище данных и платформа для выполнения ML-задач | Обнаружение аномалий, прогнозирование, снижение количества ручных операций в пользу автоматизированной аналитики |
Observability | Детальная картина состояния систем и приложений | Единое хранилище логов и метрик, корреляция данных | Оперативное обнаружение причин неполадок и проблем производительности |
Security (SIEM) | Мониторинг и анализ событий безопасности | Централизованный сбор и корреляция логов, нормализация и обогащение данных | Поиск угроз и реагирование на инциденты |
Заключение
Elasticsearch позволяет извлекать смысл из потоков разрозненной информации и обеспечивать релевантный поиск по запросам. Чтобы использовать все возможности решения, нужно спланировать архитектуру с учетом масштабируемости и интеграции с другими инструментами. Например, Elasticsearch в связке с Kibana и Beats позволяет строить наглядные дашборды и контролировать состояние системы. Также позаботьтесь о регулярной оптимизации индексов и методов мониторинга метрик, чтобы обеспечить стабильность и производительность запросов.