Регрессия и классификация в машинном обучении
Когда мы просим Алису включить что-то позитивное или записываемся к врачу через бота в телеграм-канале клиники, то даже не задумываемся, как это происходит. Но за этими простыми, на первый взгляд, действиями, стоит комплексный процесс, возможный благодаря машинному обучению.
Что такое машинное обучение (Machine Learning, ML)? По сути это совокупность методов, нужных для того, чтобы обучить ML-алгоритмы думать как человек на основе загруженных данных. Такие методы бывают трех основных типов: с учителем (Supervised Learning), без учителя (Unsupervised Learning) и с подкреплением (Reinforcement Learning). При этом каждый из них решает свои задачи.
О двух классических задачах машинного обучения с учителем — регрессии и классификации — поговорим в этой статье. Расскажем, что это за задачи, зачем нужны и как применяются на практике.


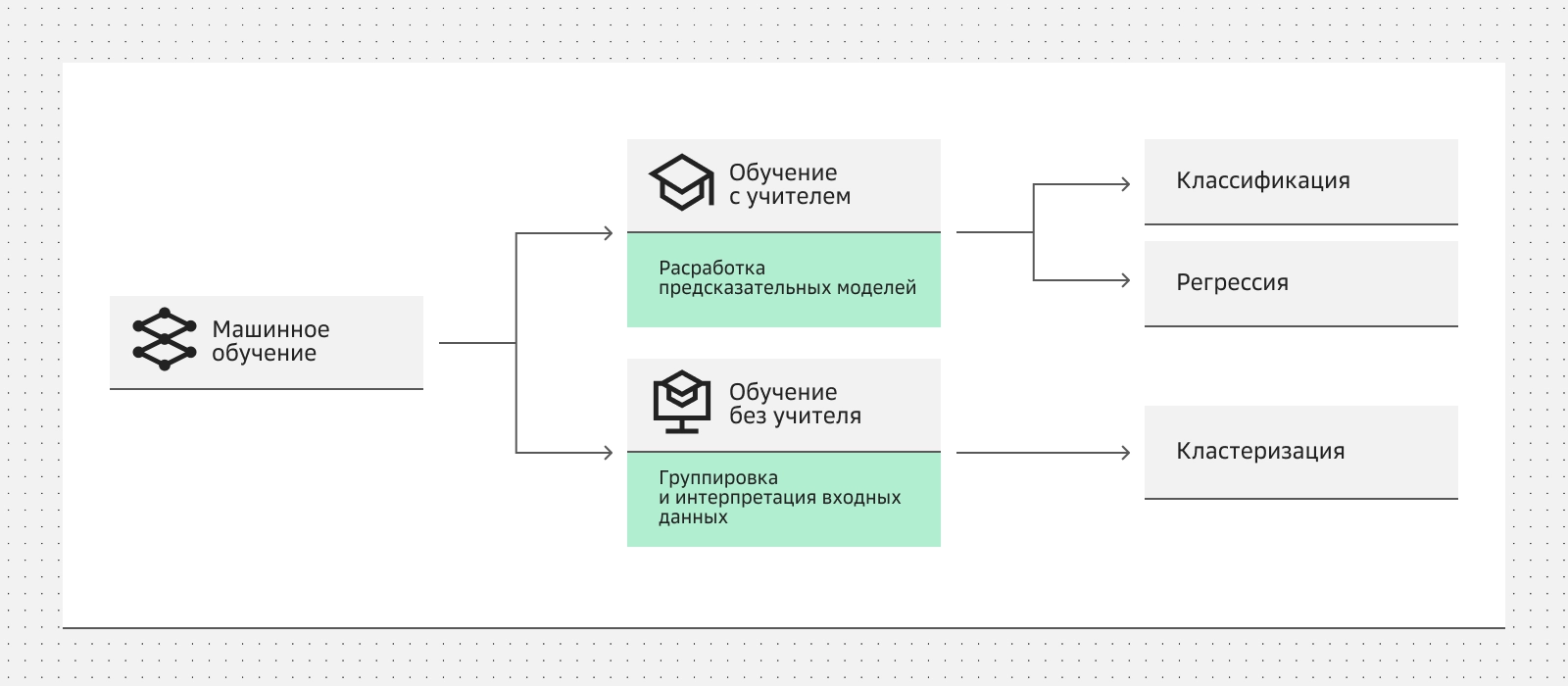 Базовые типы машинного обучения и их задачи
Базовые типы машинного обучения и их задачиВведение
Как в результате машинного обучения вышеупомянутая Алиса обретает понимание, какую музыку стоит предложить в ответ на тот или иной запрос? Здесь нет никакой магии — только грамотное применение ML-методов и инструментов для решения разных типов задач. Среди них особые места занимают регрессия и классификация.
Основы машинного обучения
Итак, машинное обучение позволяет алгоритмам учиться на данных, чтобы в дальнейшем делать прогнозы, находить закономерности и принимать решения на их основе.
Классификация, регрессия, кластеризация, уменьшение размерности и выявление аномалий — основные типы задач машинного обучения, которые служат фундаментальными инструментами для анализа данных.
Обучение с учителем
С учителем — распространенный и хорошо изученный тип машинного обучения. При его использовании нейросети предоставляется датасет с пояснениями, что означают добавленные в него данные. А «учителем» в данном случае выступает человек или группа людей, которые собирают, отсматривают и размещают этот датасет.
Основными задачами обучения с учителем выступают регрессия и классификация. При это регрессия нужна, чтобы прогнозировать непрерывные числовые значения (например, цену недвижимости), а классификация — для назначения объекту одной из категорий (например, «спам» или «не спам»).

Регрессия
Вернемся к примеру с Алисой: когда мы просим ее включить что-то позитивное, она не просто выбирает случайную песню из базы. Она анализирует наши прошлые запросы, время суток и даже настроение, чтобы спрогнозировать, какой трек нам понравится.
Цели и задачи регрессии
Регрессия — это тип задачи обучения с учителем, целью которой является прогнозирование непрерывной количественной величины. В отличие от классификации, где ответ — это категория, например, «да» или «нет», регрессия предсказывает число. Это может быть цена на дом, объем продаж на следующий квартал, температура воздуха, вероятность клика по рекламе или время, которое пользователь проведет на сайте.
Таким образом, регрессионные модели помогают отвечать на вопросы «сколько?» и «насколько?», находя математическую зависимость между входными данными (признаками) и целевой числовой переменной.
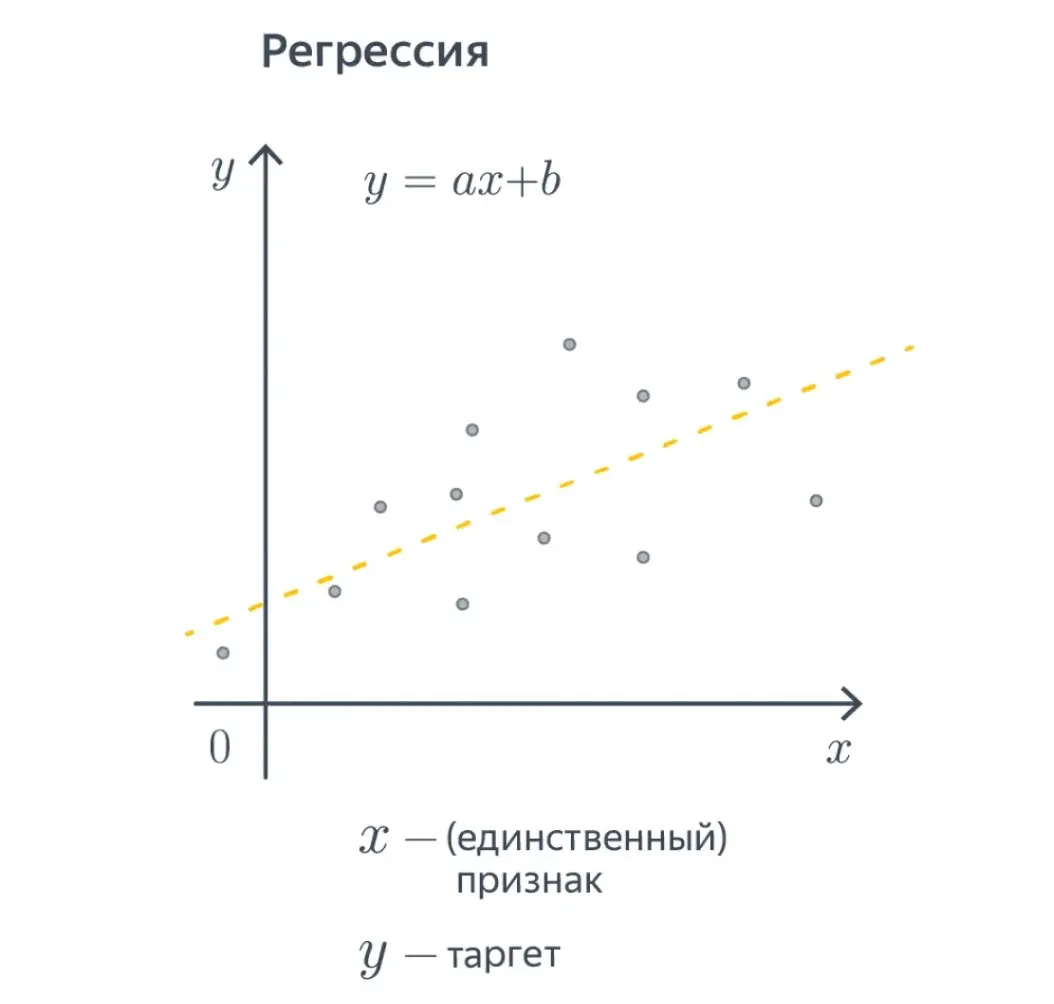 Пример линии, построенной с использованием регрессии
Пример линии, построенной с использованием регрессииОсновные методы регрессии
В числе основных методов регрессии значатся линейная, полиномиальная и множественная:
Линейная регрессия — простой и интуитивно понятный метод. Он предполагает, что между признаками (X) и целевой переменной (Y) существует линейная зависимость. Эту зависимость модель и старается найти, положив наилучшую прямую линию (или гиперплоскость в многомерном пространстве) — такую, которая минимизирует разницу между предсказанными и реальными значениями.
Полиномиальная регрессия применяется, когда зависимость между признаком и целью носит нелинейный характер (например, параболический). То есть с ее помощью можно моделировать более сложные, изогнутые зависимости за счет добавления в уравнение степеней признака.
Множественная регрессия используется, когда на целевую переменную влияет не один, а множество факторов. Например, цена квартиры может зависеть не только от площади, но и от числа комнат, этажа и удаленности от метро.
Методы оценки и улучшения модели
Чтобы оценить, насколько хорошо работает модель, построенная с помощью линейной регрессии, используются специальные метрики. Например:
коэффициент детерминации R² (R-квадрат) демонстрирует, какую долю дисперсии (изменчивости) целевой переменной можно объяснить с помощью созданной модели;
среднеквадратичная ошибка (MSE) показывает средний квадрат разницы между предсказанным и реальным значениями. Чем она меньше, тем лучше. Ее главный недостаток — она в квадратных единицах измерения (например, доллары²), что не всегда удобно для интерпретации.
среднеквадратичная ошибка (RMSE — Root Mean Square Error) является производной от MSE и вычисляется как квадратный корень из нее.
средняя абсолютная ошибка (MAE) демонстрирует среднее значение ошибок.
Классификация
В то время как регрессия предсказывает числа, классификация отвечает на вопросы категориального характера. Она позволяет отличить спам от важного письма, распознать кошку среди собак на фотографии или диагностировать заболевание по результатам анализов. То есть, если регрессия говорит «сколько», то классификация — «что».
Цели и задачи классификации
Классификация — это фундаментальная задача обучения с учителем, которая позволяет отнести объект к одной из заранее заданных категорий (классов) на основе его признаков. Входные данные — это вектор характеристик (например, размер, цвет, текстура для изображения), а выход — метка класса (например, «кошка», «собака»).
Основные методы классификации
Есть несколько методов классификации, в числе которых:
В то время, как линейная регрессия предсказывает число, логистическая регрессия — вероятность принадлежности объекта к определенному классу (например, вероятность того, что письмо — спам). Для этого она использует специальную логистическую функцию (сигмоиду), которая «сжимает» линейный вывод любого значения в интервал от 0 до 1.
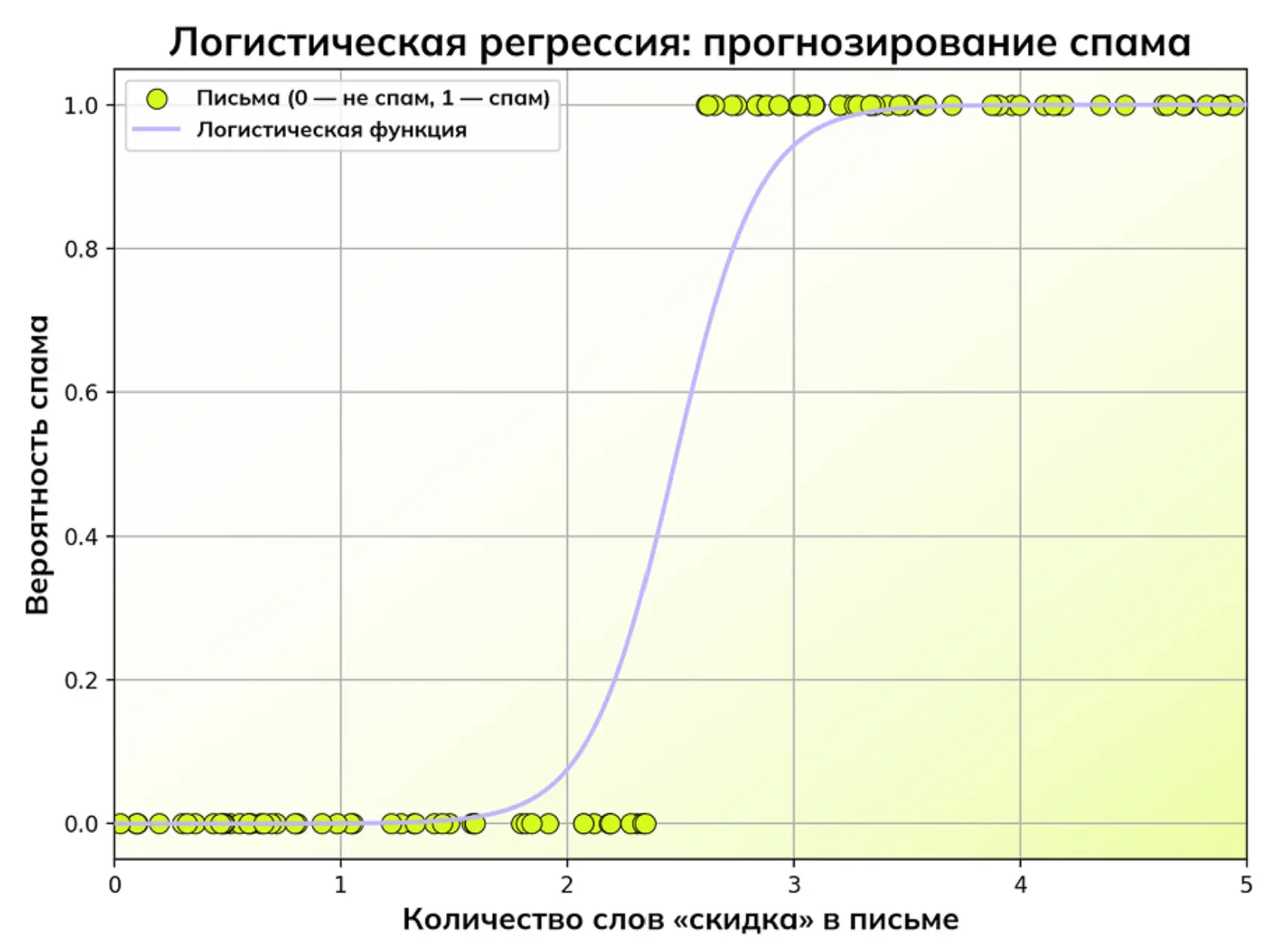 Прогнозирование спама методом логистической регрессии
Прогнозирование спама методом логистической регрессииDecision Trees (деревья решений) — алгоритм, последовательно разделяющий данные по признакам, образуя структуру правил «если → то». Главное преимущество — прозрачность и интерпретируемость решений, а недостаток — склонность к переобучению.
Random Forest (случайный лес) — ансамблевый метод, использующий множество деревьев решений. При его применении каждое дерево строится на случайной подвыборке данных и признаков, а итоговое решение определяется голосованием. Это снижает риск переобучения, повышает точность и устойчивость прогнозов.
Метод опорных векторов (SVM) — алгоритм, который ищет не просто разделяющую классы линию, а наилучшую границу (гиперплоскость) с зазором (margin) между классами. Эффективен в высокомерных пространствах и когда классов много.
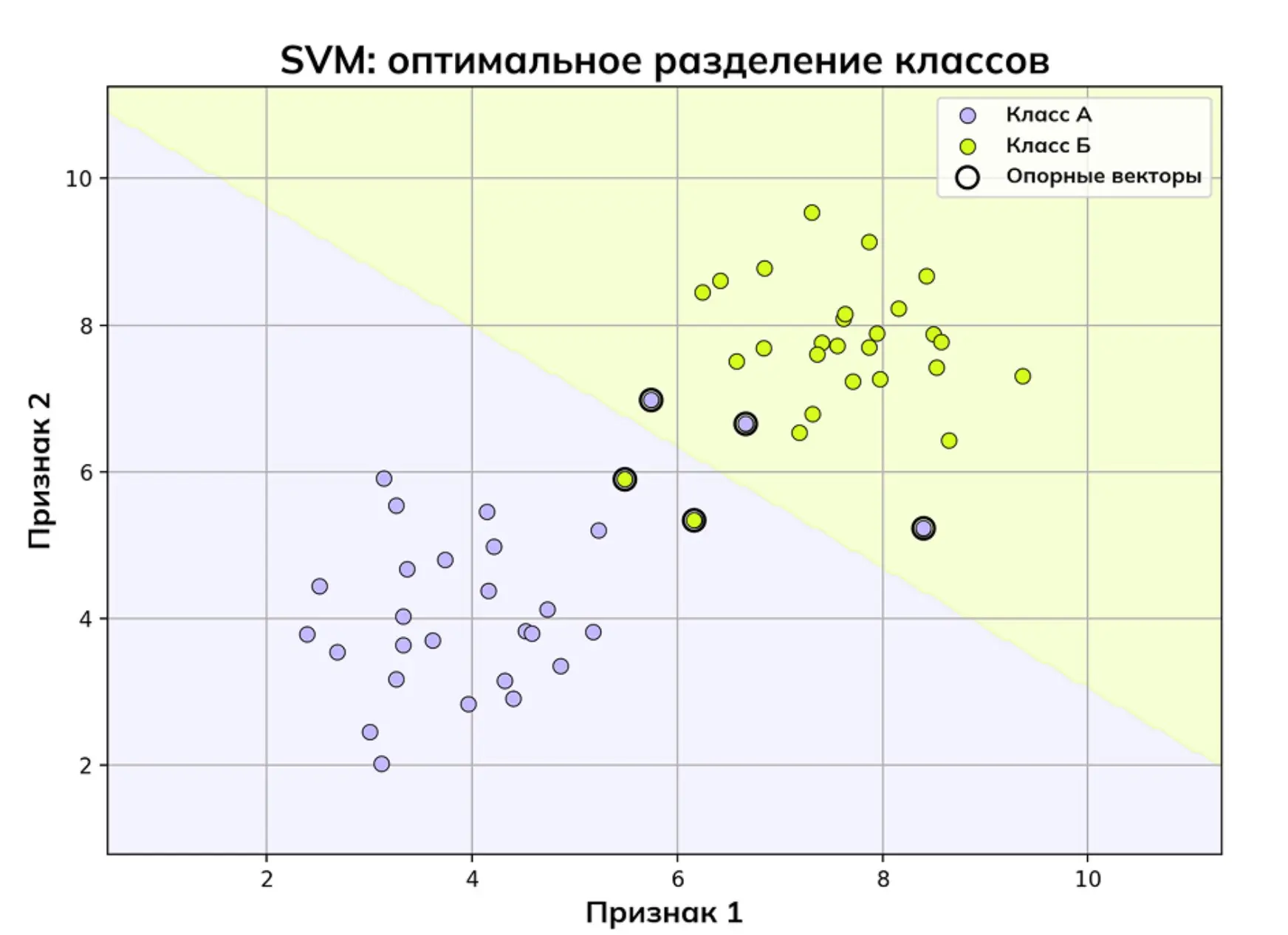 Поиск границы методом опорных векторов
Поиск границы методом опорных векторовСравнение регрессии и классификации
Регрессия и классификация не являются взаимозаменяемыми инструментами. Они решают разные типы задач: первая работает с непрерывными числовыми величинами, вторая — с категориальными метками. Выбор между ними определяется не предпочтениями ML-инженера, а исключительно тем, на какой вопрос необходимо ответить в рамках проекта.
Когда выбирать регрессию, а когда – классификацию
Выбор между регрессией и классификацией базируется на грамотном анализе задачи и формулировке правильного вопроса к данным.
Задача | Вопрос | Формат ответа | Пример задачи |
Регрессия | Сколько/Насколько | Число | • Сколько единиц товара будет продано в следующем месяце? • Насколько увеличится конверсия после изменения дизайна? • Сколько времени пользователь проведет на сайте? |
Классификация | Что/К какому классу/Да или нет | Категория | • Есть ли у пациента заболевание? • Является ли это письмо спамом или нет? • Этот отзыв позитивный, негативный или нейтральный? |
Можно сказать, что однозначным критерием выбора служит тип ответа: если требуется предсказать число — применяйте регрессию, если категорию — классификацию.
Применение на практике
Регрессионные и классификационные алгоритмы находят применение в бизнес-задачах и научных исследованиях. Их практическая реализация напрямую зависит от типа решаемой проблемы и формата ожидаемого результата.
Практические примеры регрессии
Числовое прогнозирование остается инструментом финансовой аналитики и стратегического планирования, позволяя:
прогнозировать цены на недвижимость, стоимость акций и сырьевых товаров на основе данных и рыночных индикаторов;
анализировать временные ряды для предсказания спроса в ритейле, скорости загрузки серверов и энергопотребления;
оценивать курсы валют с учетом макроэкономических показателей и геополитических факторов.
Практические примеры классификации
Категоризация объектов и явлений используется:
при анализе текстовых и метаданных для автоматической сортировки сообщений;
в диагностике заболеваний по медицинским изображениям, результатам анализов и симптомам пациента;
при распознавании изображений в системах безопасности, автономного транспорта и промышленной автоматизации.
Заключение
Регрессия и классификация представляют собой два фундаментальных подхода в машинном обучении с учителем, каждый из которых служит конкретной цели. Регрессионные модели прогнозируют непрерывные числовые значения, отвечая на вопросы типа «сколько стоит» или «какой объем», в то время как классификационные алгоритмы определяют категориальную принадлежность, решая задачи распознавания и категоризации.