Машинное обучение на Python: гайд для начинающих
Рынок машинного обучения (Machine Learning, ML) уверенно растет: по прогнозам аналитиков уже к концу 2025 года он будет оцениваться в 93.73 миллиарда долларов США. ML-технологии уже стали частью нашей повседневности — например, используются в голосовых помощниках, рекомендательных алгоритмах стриминговых сервисов и онлайн-поддержке популярных сервисов.
В этой статье поговорим о том, как обучать AI-модели на Python — самом популярном языке программирования 2024 года по версии GitHub. Узнаем, что требуется для начала обучения, сделаем обзор основных ML-моделей, рассмотрим методы их оценки и улучшения а также рассмотрим примеры их применения.


Основы работы с Python для машинного обучения
Python подходит для старта в ML благодаря простому и логичному синтаксису, который позволяет сосредоточиться на сути алгоритмов, а не на сложностях языка. В этом разделе подготовим рабочее окружение и освоим элементы языка, без которых не обходится ни один ML-проект.
Установка Python и настройка окружения
Правильная настройка среды программирования избавит от сложностей в будущем. Чтобы упростить работу, рекомендуем использовать Anaconda Navigator.
Anaconda Navigator — графический интерфейс дистрибутива Anaconda Python, который предоставляет доступ к инструментам и пакетам для анализа данных, машинного обучения и научных вычислений. Включает в себя Python и все ключевые библиотеки для Data Science, — такие как NumPy, Pandas, Scikit-learn, упрощает управление виртуальными окружениями.
Для работы с кодом на Python, также подходит среда разработки Jupyter Notebook, которая предустановлена в Anaconda. С ее помощью можно создавать ноутбуки с кодом, текстом и визуализациями, что незаменимо для поэтапного анализа данных и экспериментов.
 Интерфейс Anaconda Navigator
Интерфейс Anaconda NavigatorОсновы синтаксиса Python
Прежде чем переходить к сложным алгоритмам машинного обучения, необходимо освоить базовые элементы Python, которые составляют основу любого скрипта. К ним относятся переменные для хранения данных и типы данных (числа, строки, списки), условные операторы для принятия решений, циклы для многократного выполнения действий и функции для организации кода. Рассмотрим их подробнее.
Переменные в Python — это своего рода контейнеры для хранения информации. Они бывают трех видов:
Числа (int — целые, float — дробные): для математических операций;
Строки (str): для работы с текстом;
Списки (list): для хранения наборов данных.
Формат переменной задается после значения переменной с помощью символа #.
Например:
Условные операторы — конструкции if-elif-else позволяют управлять логикой программы в зависимости от условий.
Оператор elif используется вместо else if для обозначения следующего условия в последовательности равнозначных условий.
Циклы помогают автоматизировать повторяющиеся задачи — в машинном обучении они часто используются для обработки данных, а функции группируют код в логические блоки для многократного использования.
В официальном руководстве TensorFlow по предобработке данных наглядно показано, как именно циклы и функции применяются в реальном ML-пайплайне для нормализации числовых признаков и кодирования категориальных переменных.
Библиотеки Python для машинного обучения
После того, как базовый синтаксис освоен, пора знакомиться с главными инструментами ML-разработчика — специализированными библиотеками. Они избавляют от необходимости писать сложные алгоритмы с нуля, предоставляя готовые, оптимизированные решения для работы с данными и построения моделей.
NumPy и Pandas
Эти две библиотеки — фундамент любого проекта по анализу данных и машинному обучению. Они предназначены для работы с большими объемами информации.
NumPy (Numerical Python) — библиотека для работы с массивами и матрицами. Ее главный объект — многомерный массив, который позволяет хранить и обрабатывать большие наборы чисел гораздо быстрее, чем стандартные списки Python.
Pandas — мощный инструмент для работы со структурированными табличными данными. Его ключевой объект — DataFrame, который можно представить как электронную таблицу в памяти компьютера.
 Интерфейс Pandas
Интерфейс PandasMatplotlib и Seaborn
При работе над ML-проектом библиотеки Matplotlib и Seaborn используются для визуализации данных. Они помогают выявлять закономерности и аномалии, а также понимать структуру данных до начала обучения модели.
Matplotlib — это библиотека для создания статических, анимированных и интерактивных визуализаций. С ее помощью можно строить линейные графики, гистограммы, диаграммы рассеяния и многое другое.
Seaborn построена на основе Matplotlib и предлагает высокоуровневый и лаконичный интерфейс для создания статистических графиков. Она хороша для визуализации сложных взаимосвязей в данных — например, с помощью тепловых карт (heatmaps) для отображения корреляций или парных графиков (pairplots).
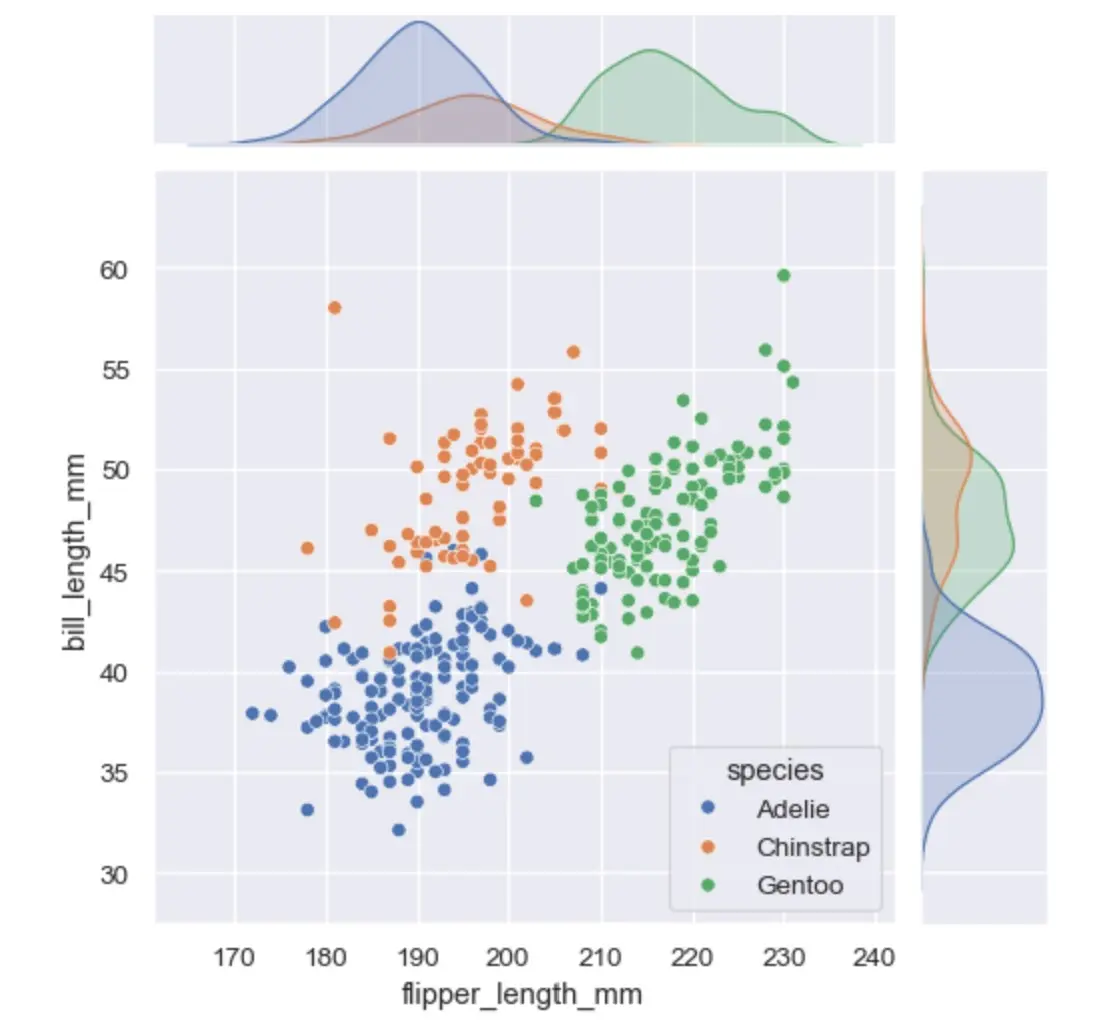 С помощью Seaborn на Python можно строить графики
С помощью Seaborn на Python можно строить графикиScikit-learn
Если NumPy и Pandas подготавливают данные, а Matplotlib и Seaborn их визуализируют, то Scikit-learn — это библиотека для создания, обучения и оценки самих моделей машинного обучения. Ее главные преимущества — это последовательный и понятный API, подробная документация и обширные возможности для реализации большого количества алгоритмов.
Основы машинного обучения
Прежде чем переходить к практике, важно понять фундаментальные принципы машинного обучения. Их знание поможет осознанно выбирать подходы для решения конкретных задач.
Основные задачи машинного обучения
Машинное обучение — это обучение нейросети на примерах. В ходе обучения алгоритм, изучая данные, выявляет скрытые в них правила и закономерности, чтобы в дальнейшем применять их на практике самостоятельно.
В число основных ML-задач входят: классификация и регрессия, а также кластеризация, уменьшение размерности и выявление аномалий.
Чтобы понять, как устроен процесс машинного обучения, рассмотрим задачу регрессии на примере линейной регрессии — одного из самых простых и интуитивно понятных ML-алгоритмов. Ее суть в том, чтобы найти линейную зависимость между признаками объектов и целевой переменной.
Например, нам нужно предсказать цену автомобиля по его пробегу. У нас есть данные: цены других автомобилей с соответствующим пробегом. Тогда, используя их, с помощью алгоритма линейной регрессии, модель построит прямую линию, которая отразит зависимость между этими параметрами.
Пример: линейная регрессия
Как же выглядит процесс построения модели по алгоритму линейной регрессии на Python с помощью Scikit-learn? Он состоит из нескольких логичных шагов:
Подготовка данных: их загрузка, например, из CSV-файла с помощью Pandas.
Разделение данных на обучающую и тестовую выборки.
Создание и обучение модели: создание объекта класса LinearRegression и вызов метода fit() с передачей обучающих данных;
Прогнозирование и оценка: использование обученной модели и метода predict() при предсказании цены для тестовой выборки.
Пайплайн «подготовка -> разделение -> обучение -> оценка» является универсальным для большинства задач машинного обучения.
Построение моделей машинного обучения
После знакомства с базовыми ML-задачами стоит познакомиться с самыми популярными алгоритмами машинного обучения.
Логистическая регрессия
Главная задача алгоритма логистической регрессии — оценка вероятности того, что объект принадлежит к определенному классу. Например, результатом его работы может быть вывод «вероятность того, что это письмо — спам, равна 90%».
Метод k-ближайших соседей (K-Nearest Neighbors или KNN)
Этот метод основан на принципе «скажи мне, кто твой сосед, и я скажу, кто ты»: при классификации нового объекта он ищет k похожих на него объектов (соседей) в обучающей выборке и присваивает ему тот класс, который встречается среди этих соседей чаще всего.
Деревья решений и случайный лес
Дерево решений — это алгоритм, который строит модель в виде древовидной структуры. В процессе обучения он задает последовательность вопросов о признаках объекта (например, «возраст клиента > 30 лет?»), чтобы в итоге прийти к решению (например, «выдать кредит»).
Случайный лес (Random Forest) — ансамблевый метод, который строит множество деревьев решений на случайных подвыборках данных и признаков, а итоговый прогноз получает путем усреднения (для регрессии) или голосования (для классификации) всех деревьев.
Метод опорных векторов и кластеризация k-средних
Метод опорных векторов (SVM) — алгоритм для классификации и регрессии. Его цель — найти оптимальную границу, которая будет максимально удалена от ближайших точек каждого класса. Эти ближайшие точки и называются опорными векторами.
А кластеризация k-средних (k-means) — это самый известный алгоритм для задач кластеризации без учителя. Он группирует объекты в кластеры (наборы) на основе схожести.
Алгоритм k-средних функционирует циклически: на начальном этапе выбираются центроиды кластеров, далее каждый элемент распределяется к ближайшему ядру, после чего положения центров обновляются путем вычисления средних координат всех объектов внутри соответствующих групп. Итерации продолжаются до достижения устойчивого состояния кластерных границ.
Оценка и улучшение моделей
Создание модели — это только половина дела. Не менее важный этап — объективная оценка того, насколько хорошо она работает и как ее улучшить при необходимости.
Разделение данных: train_test_split
Ключевой принцип машинного обучения — оценка модели на данных, которые она еще не видела. Ведь если проверять модель на тех же примерах, на которых она обучалась, она может показать идеальную, но обманчивую точность. Чтобы этого избежать, исходный набор данных всегда разделяют на две части:
Обучающая выборка (Training Set): на этих данных модель учится, находя закономерности. Обычно это 70-80% всех данных.
Тестовая выборка (Test Set): эта часть откладывается до оценки и используется только для финальной проверки качества модели.
Используя библиотеку Scikit-learn, разделить датасет на выборки можно с помощью функции train_test_split. Она случайным образом перемешивает данные и делит их в заданной пропорции.
Оценка качества моделей
После прогнозирования на тестовой выборке, предсказанные значения нужно сравнить с реальными. Для этого используются специальные метрики: для регрессии это средняя квадратичная ошибка (MSE) и коэффициент детерминации R², а для классификации — точность (Accuracy) и матрица ошибок (Confusion Matrix).
Метрики для оценки качества регрессии:
MSE показывает среднюю величину ошибок предсказаний в квадрате: чем она ближе к нулю, тем лучше. Под величиной ошибки здесь понимается разница между предсказанным значением и фактическим значением.
R² демонстрирует, насколько признаки объясняют изменение целевой переменной. Значение 1 — идеальная модель, 0 — модель, которая предсказывает не лучше, чем среднее значение.
Метки для оценки качества классификации:
Точность (Accuracy) — показывает долю правильных ответов модели.
Матрица ошибок (Confusion Matrix) — демонстрирует, сколько объектов каждого класса были предсказаны правильно, а сколько — перепутаны с другими классами.
Визуализация и интерпретация результатов
Для глубокого понимания работы модели цифровые метрики важно дополнять визуализацией. Например:
при визуализации регрессии чаще всего используется диаграмма рассеяния (scatter plot), где по одной оси откладываются реальные значения, а по другой — предсказанные;
матрица ошибок при классификации часто визуализируется в виде тепловой карты (heatmap), где цветом выделяются ячейки: чем ярче цвет на диагонали (где реальный класс совпадает с предсказанным), тем лучше работает модель.
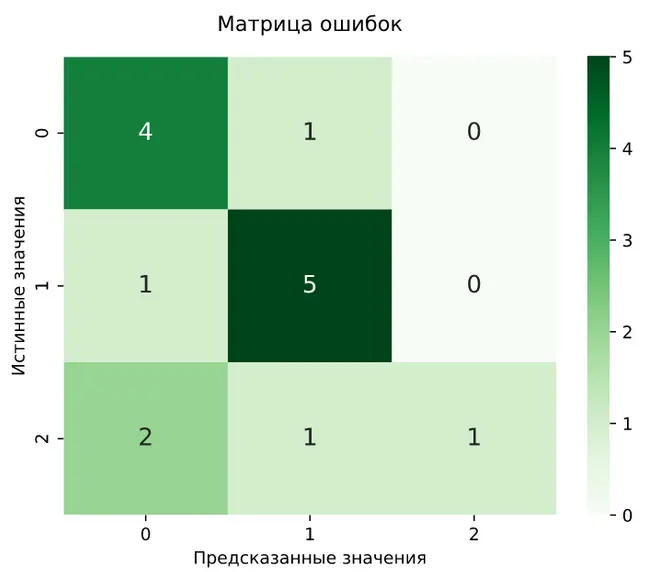 Пример матрицы ошибок в виде тепловой карты
Пример матрицы ошибок в виде тепловой картыПрактические примеры и проекты
Лучший способ закрепить теорию — применить ее на практике. Для этого рекомендуем использовать наши практические руководства для сервиса Evolution Notebooks. Например, с их помощью можно создать Telegram-бота для поиска информации из Jira или провести классификацию изображений с использованием предобученной модели ResNet18.
А теперь рассмотрим два типовых проекта, которые наглядно демонстрируют работу машинного обучения.
Прогнозирование цен на жилье
Прогнозирование цен на жилье — это классический пример реализации задачи регрессии. При ее решении алгоритм работы будет следующим:
Сбор данных: используйте датасет с историческими объявлениями о продажах.
Предобработка: с помощью библиотек Pandas и NumPy очистите данные, обработайте пропуски и преобразуйте категориальные признаки в числовые.
Обучение модели: выберите алгоритм и обучите его на подготовленных данных.
Оценка результата: проверьте точность модели на тестовой выборке, используя метрики MSE или R².
Чтобы увидеть практическую реализацию такого алгоритма, изучите проект House Price Prediction на GitHub. В нем вы найдете пример работы с данными по недвижимости — от анализа и очистки данных до сравнения эффективности различных алго
Классификация изображений и анализ текстов
С помощью Python можно решать комплексные задачи классификации, требующие специальной подготовки данных. Например:
В компьютерном зрении библиотеки типа TensorFlow анализируют пиксели изображений, самостоятельно находя признаки для распознавания объектов или рукописного текста.
А для обработки естественного языка (NLP) тексты сначала преобразуются в числа методами вроде TF-IDF (Term Frequency-Inverse Document Frequency), а затем классифицируются алгоритмами Scikit-learn для фильтрации спама или анализа sentiment.
Заключение
Машинное обучение на Python открывает возможности для решения практических задач из самых разных областей, а старт в ML требует понимания базовых принципов, знакомства с ключевыми библиотеками и соблюдения четкого workflow: от подготовки данных до оценки и интерпретации модели.
Все перечисленные задачи и модели вы можете реализовать с Evolution ML Inference, используя популярные фреймворки вроде Transformers и vLLM для работы с современными языковыми моделями — от компактных решений для специфичных задач до мощных LLM для сложных когнитивных процессов.