Apache Kafka: руководство по брокеру сообщений для начинающих
Традиционные очереди сообщений — не всегда хороший вариант, особенно если речь об обработке больших потоков данных. На помощь придет брокер Apache Kafka. Он не ставит сообщения в очередь, а хранит их в журнале событий, откуда пользователи могут читать данные. Давайте разберемся, как работает решение и в каких случаях его использовать.


- Что такое Apache Kafka и его основная роль
- Основные компоненты архитектуры Kafka
- Принцип работы брокера сообщений Kafka
- Модель хранения данных в Kafka
- Где и для чего применяется Apache Kafka
- Преимущества и недостатки Kafka
- Простые примеры использования команд Kafka
- Сравнение с другими брокерами сообщений (RabbitMQ, NATS)
- Как начать работу с Kafka: первые шаги
- Заключение
Что такое Apache Kafka и его основная роль
Apache Kafka — распределенная платформа для потоковой передачи данных и событий. Она позволяет приложениям передавать и читать сообщения как в момент поступления, так и позже. Платформа работает по модели publish–subscribe. Что это значит:
Производители (producers) отправляют данные в топики — определенные категории, куда распределяются сообщения.
Потребители (consumers) могут читать данные из этих топиков независимо друг от друга.
Apache Kafka поддерживает обе модели обмена сообщениями:
Очередь – благодаря группам потребителей (consumer groups) каждое сообщение обрабатывается только одним потребителем внутри группы.
Публикация-подписка – несколько независимых групп потребителей могут читать одни и те же сообщения, каждая со своей скоростью.
Журнал транзакций (commit log) как центральная концепция
Ключевая идея Kafka — это журнал commit log, куда последовательно записываются события. Пользователи обрабатывают сообщения оттуда — каждый со своей позиции. Можно сравнить это с книгой, которую одновременно читают несколько человек, делают закладки на страницах и потом продолжают с нужной страницы. Такой подход позволяет приложениям обрабатывать данные в своем темпе.
Логовая структура делает Kafka не просто брокером, а полноценным масштабируемым хранилищем событий. Потребители могут обращаться к данным не только в реальном времени, но и ретроспективно.
Основные компоненты архитектуры Kafka
В архитектуре Kafka шесть основных компонентов. Чтобы проектировать Kafka-кластеры, нужно понимать, как они работают. Коротко рассказываем о каждом компоненте.
Брокер (Broker): сервер, хранящий данные
Брокер — сервер Kafka, который принимает, хранит и отдает сообщения. Брокеров несколько, и каждый из них отвечает за хранение данных конкретных партиций и обрабатывает запросы пользователей.
Топик (Topic): категория или поток сообщений
Топик — логическая категория, куда продюсеры направляют свои сообщения и откуда их берут пользователи. Каждый топик содержит поток данных одного типа. Например, это могут быть метрики, логи, заказы, сведения о работе систем и прочее. Важно, что топики сами по себе не хранят сообщения — они только объединяют партиции.
Партиция (Partition): часть топика для параллельной обработки
Партиция — упорядоченная последовательность данных в топике. Разделение топика на такие «части» позволяет вести параллельную обработку сообщений и горизонтально масштабировать кластер.
Данные внутри партиции всегда читаются в том порядке, в котором были записаны, при условии, что каждый потребитель читает партицию последовательно. Не следует назначать несколько потребителей из одной группы на одну партицию, если важен строгий порядок обработки.
Производитель (Producer): приложение, отправляющее сообщения
Producer — приложение или сервис, который отправляет сообщения в Kafka. Он создает записи с ключами/значениями и определяет, в какой топик передавать данные. Опционально продюсеры могут настраивать подтверждение доставки сообщений.
Потребитель (Consumer): приложение, читающее сообщения
Consumer — приложение, которое подписывается на топики и читает оттуда сообщения. Потребители иногда объединяются в consumer group.
Количество потребителей в одной группе не может превышать количество партиций в топике – лишние потребители будут простаивать. Это позволяет гибко масштабировать обработку: добавление новых потребителей увеличивает параллелизм только до числа партиций.
ZooKeeper/KRaft: координация работы кластера
ZooKeeper в устаревших версиях или KRaft в новых — компонент, который отвечает за управление метаданными и координацию Kafka-кластера. Он мониторит состояние брокеров, распределяет партиции и выбирает контроллер.
ZooKeeper усложнял инфраструктуру и создавал ограничения масштабирования, поэтому сообщество Kafka разработало собственный модуль координации KRaft (KIP-500). Начиная с версии 3.3.1 KRaft готов к использованию в производственных средах для новых кластеров, а поддержка ZooKeeper сохраняется для обратной совместимости. Постепенный переход на KRaft позволяет упростить архитектуру и улучшить управление метаданными.
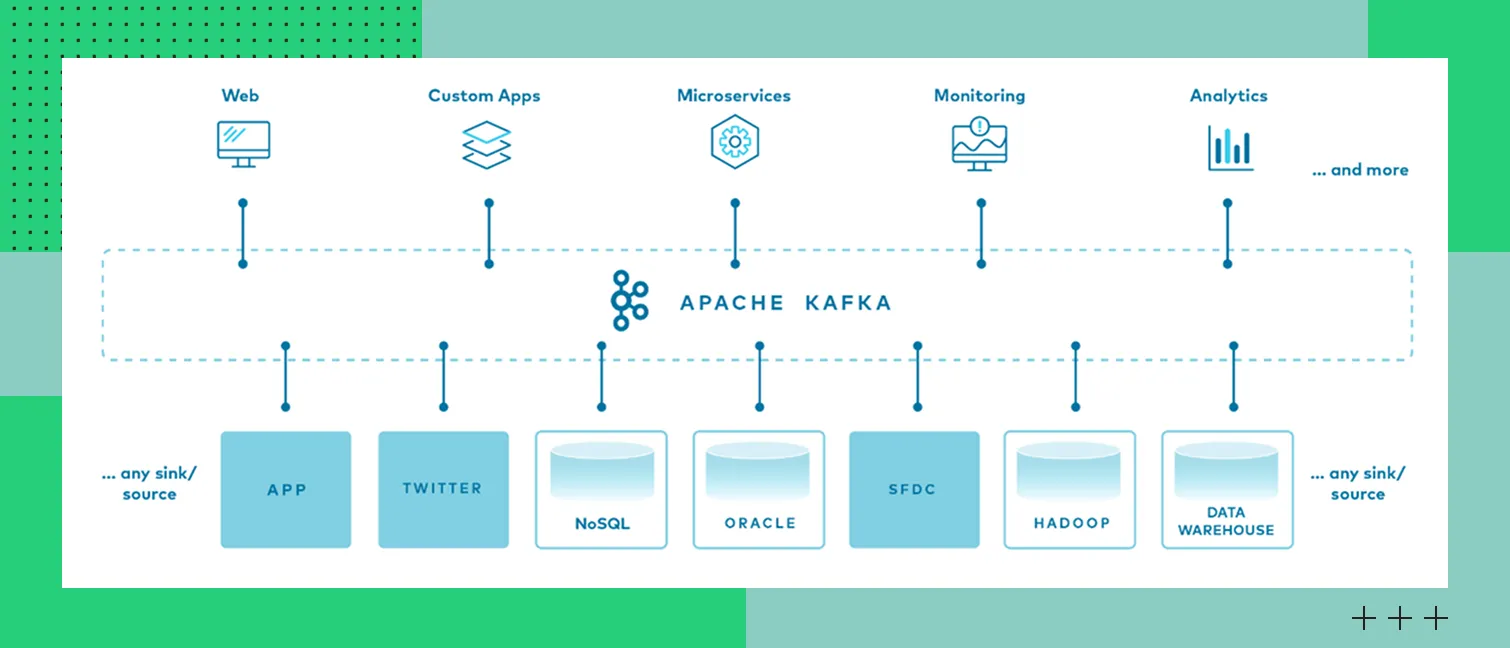 Экосистема Kafka
Экосистема KafkaПринцип работы брокера сообщений Kafka
Kafka справляется с большим количеством сообщений, обрабатывая их с минимальными задержками. Разберемся, что происходит внутри платформы и как взаимодействуют компоненты.
Публикация сообщений: как Producer отправляет данные в топик
Producer отправляет данные в конкретный топик и может указать ключ сообщения. По ключу Kafka определяет целевую партицию (обычно хешированием), что гарантирует попадание сообщений с одинаковым ключом в одну партицию. Если ключ не задан, распределение происходит по алгоритму Round‑Robin или Sticky Partitioner для равномерной нагрузки.
Хранение сообщений: структура партиции и смещение (offset)
Данные в партициях хранятся в виде неизменяемых логов. Каждому сообщению назначается числовой идентификатор, определяющий его позицию в партиции. Этот идентификатор (смещение, offset) позволяет потребителям отслеживать прогресс чтения. Consumer сам управляет своим смещением и может периодически сохранять его (commit) после обработки сообщений. При перезапуске или сбое потребитель продолжает чтение с последнего сохраненного смещения, что гарантирует ровно одну обработку (при правильной настройке) или хотя бы одну.
Потребление сообщений: как Consumer читает данные из топика
Consumer запрашивает у брокера сообщения, указывая нужный числовой идентификатор для конкретной партиции. Один пользователь последовательно читает и обрабатывает данные, независимо от других. Благодаря offset можно повторно возвращаться к сообщениям или продолжать чтение с последнего обработанного сообщения.
Репликация партиций: обеспечение отказоустойчивости
Каждая партиция может иметь несколько реплик, которые распределяются между разными брокерами. Одна реплика назначается лидером, остальные — фолловерами. Лидер обрабатывает все запросы пользователей на чтение и запись. Фолловеры занимают его место в случае сбоя.
Группы потребителей (Consumer Groups): модель параллельной обработки
Consumer Group — это группа потребителей, совместно читающих один и тот же топик. Каждая партиция назначается только одному consumer внутри группы, что предотвращает дублирование обработки. Такая модель позволяет масштабировать потребление данных за счет добавления новых потребителей.
Модель хранения данных в Kafka
Брокер хранит сообщения независимо от того, были ли они обработаны потребителями. Это возможно благодаря модели хранения, основанной на неизменяемом журнале событий. Разберем ее некоторые принципы.
Append-only log: запись только в конец
В Kafka сообщения отправляются в партиции по принципу append-only — то есть в конец лога. Уже записанные данные не редактируются и не перезаписываются. Благодаря этому обеспечиваются прозрачное хранение сообщений и высокая производительность системы.
Стратегии удержания данных: по времени и по размеру
Kafka не удаляет сообщения после того, как они были прочитаны. Брокер хранит их согласно настроенным правилам удержания. Например, данные могут оставаться в журнале 7 или 30 дней, либо удаляться, когда лог превысит заданный объем. Можно выбрать собственную стратегию, чтобы контролировать использование дискового пространства.
Сохранение сообщений после чтения (в отличие от очередей)
Kafka хранит данные даже после того, как они были прочитаны, в течение всего срока действия политики удержания (retention). Благодаря этому потребители могут повторно обращаться к уже обработанным сообщениям, менять смещение (offset) и перечитывать события – в отличие от классических очередей, где сообщения удаляются сразу после подтверждения.
Где и для чего применяется Apache Kafka
Брокер Apache Kafka незаменим там, где нужно с минимальными задержками обрабатывать большие потоки данных, за секунды принимать миллионы сообщений и распределять их между серверами. Примеры применения в реальных сценариях:
Обработка потоковых данных в реальном времени. Брокер отдает пользователям данные сразу после их появления, что дает возможность быстро прочитать сообщения и отреагировать на изменения.
Декомпозиция монолита и интеграция микросервисов. Kafka используется в роли событийной шины между сервисами. Приложения и микросервисы могут асинхронно обмениваться событиями без привязки друг к другу.
Сбор и агрегация логов и метрик. Брокер собирает системные события из разных источников и централизованно их хранит, благодаря чему пользователям проще получать исчерпывающую информацию.
Change Data Capture (CDC). Kafka позволяет передавать в виде потока событий изменения из баз данных. Например, фиксируются добавление или редактирование записей в таблицах. Это полезно для аналитики, репликации данных и синхронизации серверов.
Тяжелые очереди задач и событий. Брокер подходит для задач, где нужна возможность повторного чтения. Классические очереди ее не предоставляют, поскольку сообщения удаляются после обработки.
Преимущества и недостатки Kafka
Apache Kafka, как и любое решение для обработки данных, имеет сильные и слабые стороны. Оцените их, чтобы понять, подходит ли платформа для ваших задач.
Сильные стороны: пропускная способность, масштабируемость, надежность
В первую очередь Kafka выбирают за способность платформы обрабатывать большие потоки и возможность возвращаться к чтению данных. Какие еще преимущества есть у брокера:
Высокая пропускная способность — благодаря распределенной архитектуре и эффективной записи на диск Kafka способна обрабатывать миллионы сообщений в секунду (при размере сообщения ~1 КБ и достаточных ресурсах кластера). В тестах Aiven кластер из 6 узлов достигал пропускной способности 1 ГБ/с на запись. Реальная производительность зависит от конфигурации, аппаратного обеспечения и настроек пакетирования.
Масштабируемость — за счет добавления новых брокеров можно увеличивать мощность кластера, не останавливая систему. Партиции будут автоматически распределяться между брокерами, что позволяет управлять нагрузкой.
Отказоустойчивость и надежность — сообщения и их реплики сохраняются на диске, распределяются между брокерами. Если даже произойдет сбой узлов, данные будут доступны для потребителей.
Поддержка множества потребителей — потребители независимо друг от друга могут читать одни и те же сообщения. Это удобно для микросервисных архитектур, аналитики и мониторинга.
Историческое хранение событий — Kafka позволяет хранить данные в течение настроенного периода времени (retention period) или до достижения определенного объема. Это дает возможность повторно обрабатывать события в пределах этого окна, что полезно для аналитики, восстановления после сбоев и аудита.
Слабые стороны: сложность операционного сопровождения, зависимость от дисков и другие
Минусы в основном связаны с технической реализацией и настройками платформы. Главные недостатки брокера:
Сложность настройки и сопровождения — чтобы работать с Kafka, нужно уметь управлять кластерами, настраивать партиций и репликации. Задача усложняется, если система будет масштабироваться.
Зависимость от дисковой подсистемы — на производительность Kafka напрямую влияют скорость дисков и стабильность сети.
Избыточность для небольших проектов — платформа сложна в эксплуатации, поэтому для простых очередей и малых объемов данных ее использовать нецелесообразно.
Kafka может работать со сверхнизкими задержками (субмиллисекундными) при соответствующей настройке (например, отключение буферизации). Однако для достижения максимальной пропускной способности часто используется пакетная обработка, которая неизбежно увеличивает задержку. Таким образом, платформа позволяет балансировать между задержкой и пропускной способностью в зависимости от задач.
Простые примеры использования команд Kafka
Если только начинаете работать с Kafka, изучите команды для создания топиков, отправки и получения данных. Удобно, что их можно с помощью встроенных утилит выполнять из командной строки.
Создание топика
Пример команды:
Что тут указано:
--topic my-first-topic — имя топика, который вы создаете;
--bootstrap-server localhost:9092 — адрес брокера Kafka;
--partitions 3 — количество разделов топика;
--replication-factor 1 — количество копий данных, которые будут автоматически создаваться.
Отправка сообщения через консольный Producer
Сначала проверьте, работает ли брокер:
Если все в порядке, появится поле для ввода сообщений. Учтите, что каждая строка будет отправляться в топик отдельно. Пример, как это выглядит:
Чтение сообщений через консольный Consumer
Чтобы проверить все сообщения, которые вы отправили, примените команду:
Что это значит:
--from-beginning — можно прочитать все сообщения, не только новые;
--topic my-first-topic — указание топика, откуда вы берете данные;
--bootstrap-server localhost:9092 — адрес брокера Kafka.
Сравнение с другими брокерами сообщений (RabbitMQ, NATS)
Kafka — не единственный брокер сообщений. Чтобы было проще выбрать, изучите сравнительную таблицу:
Параметр | Apache Kafka | RabbitMQ | NATS |
Модель обмена | Publisher-Subscriber с хранением сообщений | Publisher-Subscriber, очереди | Publisher-Subscriber, очереди через JetStream |
Хранение сообщений | Долговременное хранение, сообщения не удаляются до применения политики retention | Сообщения после подтверждения удаляются | Сообщение по умолчанию быстро удаляются, но возможно хранение с помощью JetStream |
Пропускная способность | Высокая. Ее достаточно для обработки миллионов сообщений в секунду | Средняя, подходит для умеренных нагрузок | Высокая для своих задач |
Масштабируемость | Горизонтальная | Шардинг | Горизонтальная |
Гарантия доставки | At-least-once, Exactly-once (с настройкой) | At-most-once, at-least-once | At-most-once, at-least-once (с JetStream можно exactly-once) |
Задержки (latency) | Задержка настраиваемая: от долей миллисекунды до миллисекунд в зависимости от баланса с пропускной способностью | Низкие, брокер подходит для мгновенных задач | Низкие, поэтому решение подходит для работы в реальном времени |
Сценарии применения | Потоковые данные, аналитика, обработка событий в реальном времени | Очереди задач, обработка запросов, интеграции приложений | Real-time обмен сообщениями, IoT, микросервисы |
Если кратко: Kafka подходит для систем с большими потоками данных, где нужно последовательно обрабатывать события и хранить сообщения. Брокер RabbitMQ незаменим там, где в приоритете сложная маршрутизация и быстрая доставка. NATS подходит для работы в реальном времени, для ultra-low latency и микросервисных архитектур.
Как начать работу с Kafka: первые шаги
Начните с простых сценариев эксплуатации — запустите брокер через Docker Compose или облачные сервисы. Первый вариант подойдет для тестов, второй — для продакшена. Рассказываем, как работать.
Локальный запуск через Docker Compose
С помощью Docker Compose можно развернуть Kafka и все сопутствующие компоненты в виде контейнеров. Процесс займет буквально несколько минут. Это удобно, если вы собираетесь протестировать платформу и не хотите прибегать к настройкам на физическом сервере.
Как действовать:
Создайте файл docker-compose.yml с образами Kafka и Zookeeper.
Запустите контейнер командой docker-compose up -d.
Проверьте, что брокер работает. Это можно сделать через docker logs kafka или kafka-topics.sh --list --bootstrap-server localhost:9092.
Создайте пробную тему и отправьте несколько сообщений, чтобы убедиться, что платформа выполняет задачи.
Это быстрый и бесплатный вариант, к тому же, вы сможете контролировать работу брокера. Учтите, что в таком сценарии не будет автоматического масштабирования, поскольку нагрузка ограничивается ресурсами локального устройства.
Облачные управляемые сервисы
Если хотите сфокусироваться на разработке, не углубляясь в контроль инфраструктуры, выбирайте облачные сервисы. Например, Confluent Cloud и AWS MSK предоставляют управляемые кластеры Kafka, поддерживают репликацию, мониторинг и автоматическое масштабирование. В чем преимущества такого подхода:
Можно подключаться через готовые Kafka-клиенты без сложных ручных настроек.
За SLA и отказоустойчивость отвечает провайдер облачного сервиса.
Можно интегрировать платформу с другими облачными сервисами, настраивать права доступа, управлять темами и многое другое.
Из минусов — платное использование облачных сервисов, возможные ограничения провайдера и сетевые задержки. Чтобы минимизировать потенциальные сложности, изучите весь функционал доступных решений.
Можно использовать Apache Kafka в облаке Evolution Managed Kafka от Cloud.ru. Это легкий в управлении сервис со встроенным мониторингом.
Заключение
Apache Kafka — подходящий инструмент для работы с потоками данных и событий в распределенных системах. Брокер отличается высокой производительностью и надежностью, благодаря чему стал стандартом для больших объемов информации. Его можно использовать в аналитике, микросервисных и событийно-ориентированных архитектурах, где нужны повторное чтение и независимая обработка событий. Только учтите, что для работы с платформой требуются навыки по управлению кластерами и поддержке распределенной инфраструктуры.