Как создать сетевую архитектуру для размещения межсетевых экранов на платформе Облако VMware
Для защиты IT-инфраструктуры в облаке от кибератак необходимы
межсетевые экраны — специализированные программные или программно-аппаратные комплексы, которые защищают корпоративные сети от вредоносного трафика. О том, как выстроить сетевую архитектуру для их размещения на платформе Облако VMware от Cloud.ru, расскажу в этой статье.
Работать мы будем на платформе Облако VMware — гибком решении от лидера индустрии VMware, построенном по модели IaaS (Infrastructure-as-a-Service). А чтобы упростить защиту ресурсов и гарантировать их безопасность, будем внедрять архитектуру с выделенными NSX Т0 и централизованными межсетевыми экранами. Для этого перед развертыванием разработаем комплект документов HLD и LLD.


Архитектура платформы Облако VMware
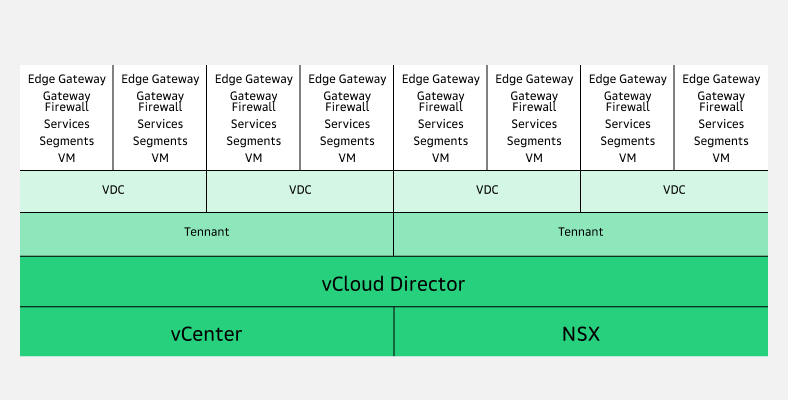
Логически платформа Облако VMware состоит из трех компонентов:
vCloud Director;
vSphere;
NSX.
Давайте разберемся, как эти компоненты взаимодействуют между собой при работе на платформе.
 Архитектура платформы Облако VMware
Архитектура платформы Облако VMwareПрямо из личного кабинета Cloud.ru можно получить доступ к vCloud Director — платформе для организации виртуальных ЦОД на физической инфраструктуре.
→ vCloud Director позволяет разделить единый пул ресурсов облачного провайдера на изолированные тенанты, которые выдаются в пользование заказчикам.
vCloud Director непосредственно связан с vCenter и NSX:
отвечающая за вычислительные ресурсы консоль vCenter транслирует все настройки тенанта в vCloud Director через API;
платформа виртуализации и обеспечения безопасности сетевых сервисов NSX управляет сетью.
Так как наша статья посвящена выстраиванию сетевой архитектуры для размещения межсетевых экранов, далее детально поговорим про NSX.
NSX и ее базовые компоненты
NSX — это платформа сетевой виртуализации и сервисов безопасности, которая строится по принципам программно-определяемых сетей SDN, тесно интегрирована с vSphere:
в качестве Management Plane и Centralized Control Plane в NSX выступает NSX Manager — кластер из трех виртуальных машин;
Localized Control Plane находится на ESXi хостах, также как и Data Plane;
в качестве Data Plane в NSX используются также специальные сервера NSX Edge, на которых размещены разные сервисы и виртуальные машины.
Давайте рассмотрим базовые компоненты NSX — так будет проще разобраться в схемах сетевой архитектуры для размещения межсетевых экранов, которые обсудим дальше.
С точки зрения сетевых функций в NSX выделяется два логических компонента NSX T0 (Tier-0 Gateway) и NSX T1 (Tier-1 Gateway):
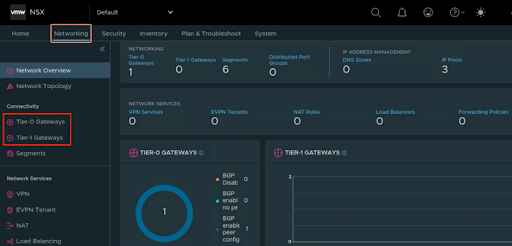 NSX T0 (Tier-0 Gateway) и NSX T1 (Tier-1 Gateway) в консоли NSX
NSX T0 (Tier-0 Gateway) и NSX T1 (Tier-1 Gateway) в консоли NSXNSX T0 отвечает за маршрутизирующие функции.
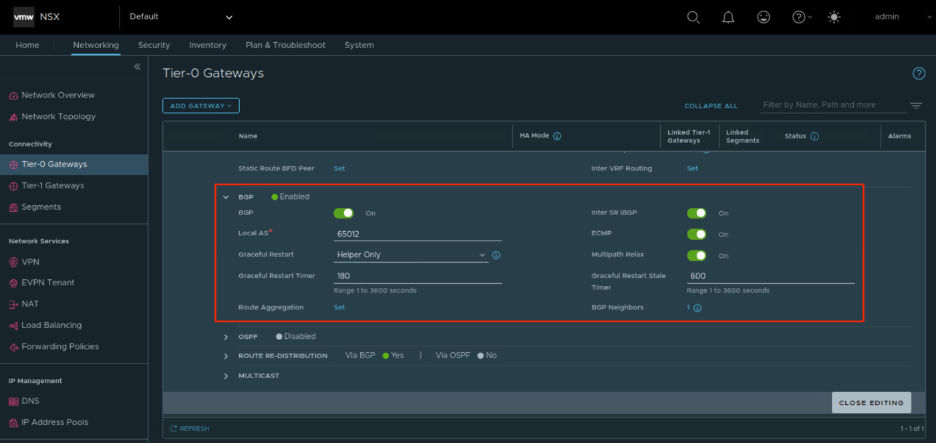 Функциональность компонента NSX T0 (Tier-0 Gateway)
Функциональность компонента NSX T0 (Tier-0 Gateway)На логическом компоненте NSX T1 реализованы маршрутизирующие и сервисные функции. Например, c его помощью через vCloud Director можно настраивать сервисы IPSEC, NAT, FW или прописывать статическую маршрутизацию.
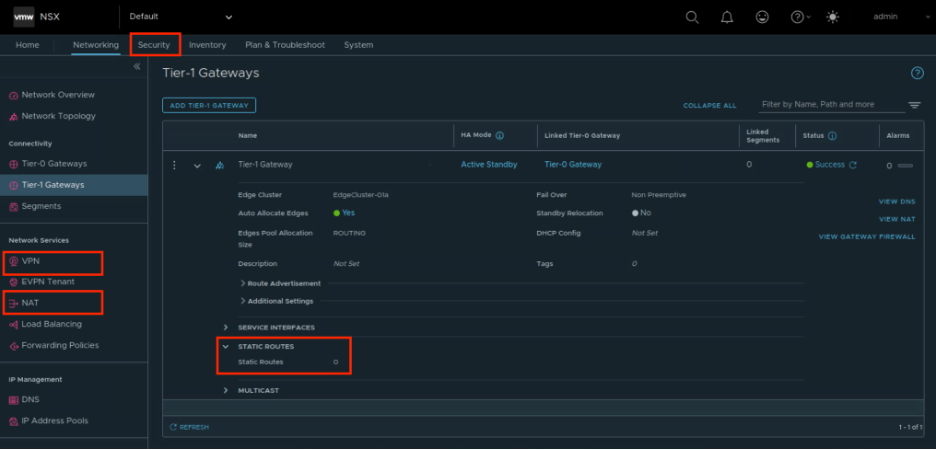 Функциональность компонента NSX T1 (Tier-1 Gateway)
Функциональность компонента NSX T1 (Tier-1 Gateway)Также для понимания схемы размещения межсетевого экрана в сетевой архитектуре облака нам пригодится понятие «сегмент». Каждый сегмент в NSX — это презентация одного L2 широковещательного домена на все транспортные узлы, через которые проходит L2 трафик. В сегментах размещаются виртуальные машины для обеспечения их сетевой связности. А организуются сегменты с помощью оверлейной технологии и инкапсуляции GENEVE.
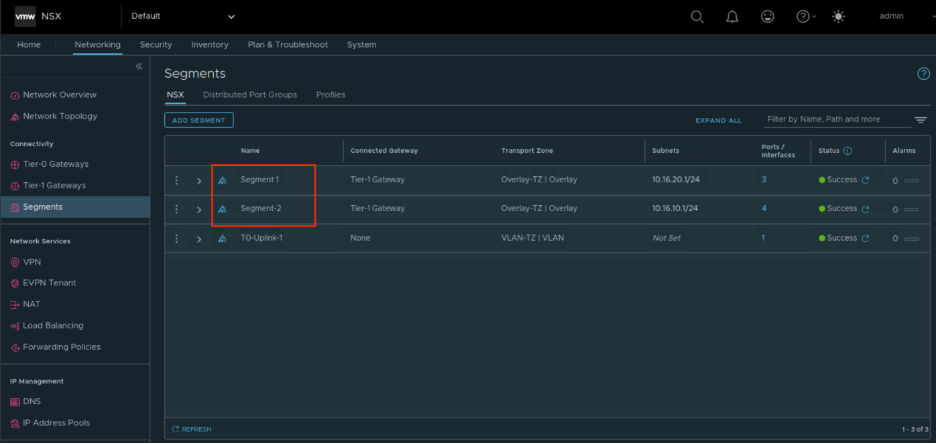 Сегменты в консоли NSX
Сегменты в консоли NSXКак спроектировать сетевую архитектуру: готовое решение
Для установки межсетевого экрана в облако первом делом нужно сформировать два документа — High Level Design (HLD) и Low Level Design (LLD):
HLD-документация позволяет верхнеуровнево определиться с потоками трафика, которые должны быть обеспечены сетью;
LLD-документация детально описывает настройки сети.
Шаг 1. HLD-документация: создание верхнеуровневого дизайна решения
Внутри NSX все компоненты тесно связаны. Поэтому обычная логическая конструкция, которую сетевые архитекторы выстраивают в облаке, выглядит примерно так:
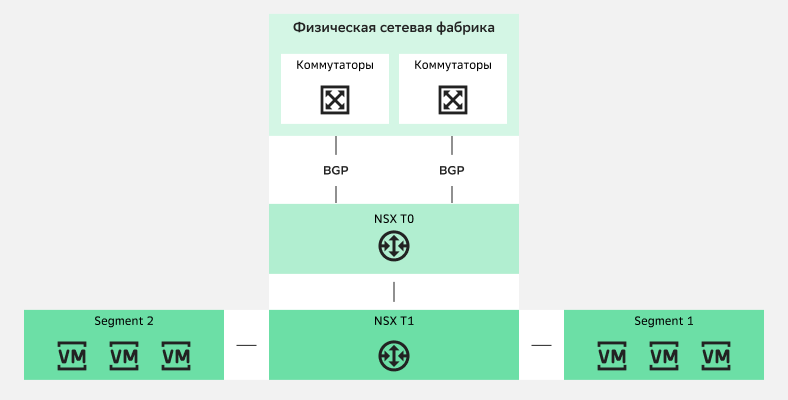 HLD-документация сетевой архитектуры в облаке
HLD-документация сетевой архитектуры в облакеNSX T0 и NSX T1 соединяются между собой через технологический сегмент и что-либо «врезать» между ними невозможно. Этот сегмент не видно из веб-консолей, а потому его нельзя использовать для настройки системы. Как же встроить в эту архитектуру межсетевой экран?
На платформе Облако VMware есть встроенные в NSX средства безопасности — Gateway Firewall и Distributed Firewall:
Gateway Firewall — межсетевой экран, который расположен на NSX T1 и может использоваться для фильтрации трафика Север-Юг.
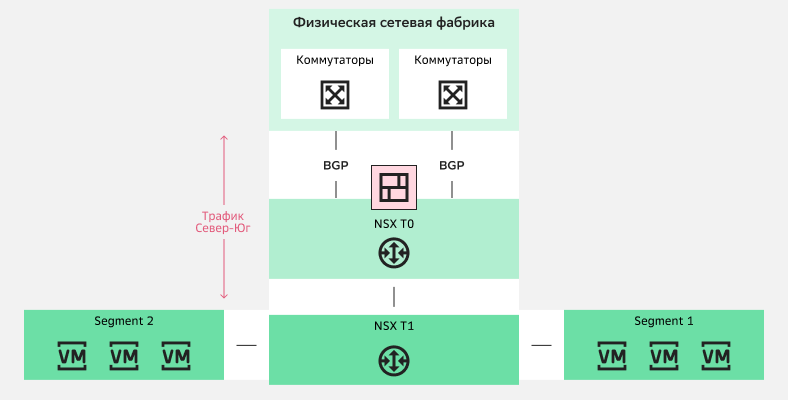 Использование Gateway Firewall для фильтрации трафика Север-Юг
Использование Gateway Firewall для фильтрации трафика Север-ЮгРаспределенный межсетевой экран Distributed Firewall находится на сетевом адаптере виртуальной машины. Он позволяет организовать микросегментацию:
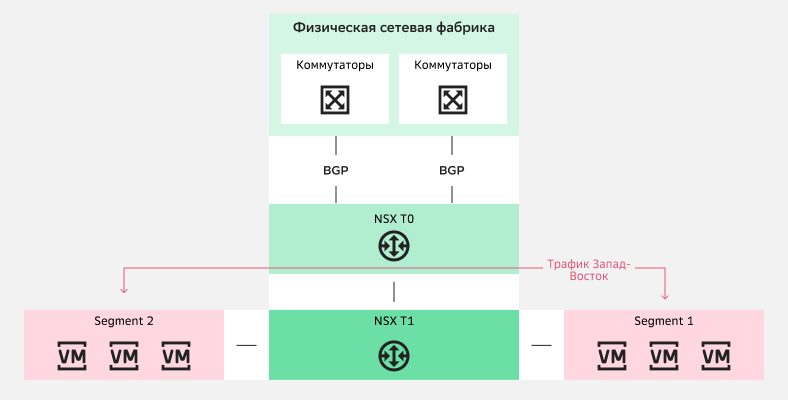 Использование Distributed Firewall для фильтрации трафика Запад-Восток
Использование Distributed Firewall для фильтрации трафика Запад-ВостокНо если к межсетевому экрану предъявляются особые требования — например, если важно разместить межсетевые экранов российского производства, то использование Gateway Firewall и Distributed Firewall не всегда возможно. Тогда можно пойти другим путем: расположить межсетевой экран между двумя NSX T0. Схема будет выглядеть так:
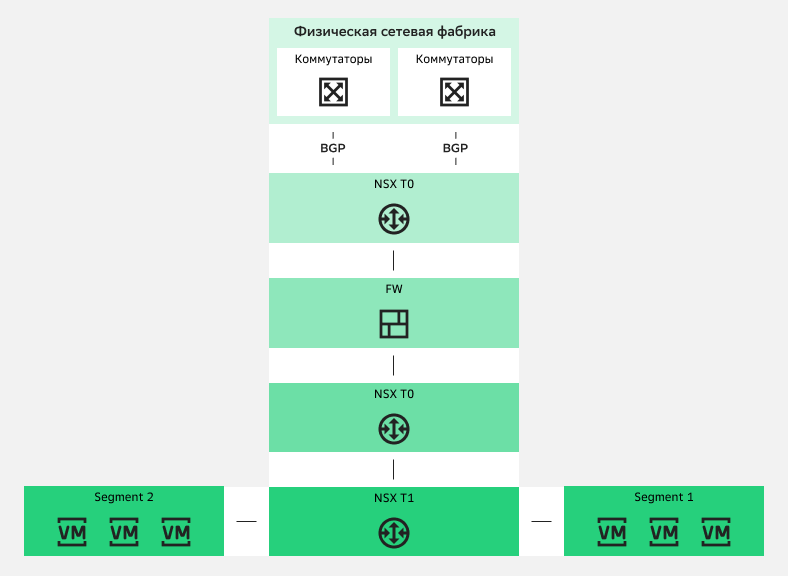 Межсетевой экран между NSX T0 и NSX T1
Межсетевой экран между NSX T0 и NSX T1Для выбора такой схемы работы есть причины:
Причина 1. Ограничение платформы VMware на количество сетевых адаптеров виртуальной машины. Конечно, вы можете встроить виртуальную машину межсетевого экрана прямо в VDC пользователя — подключить ее к NSX T1 — но только при работе с небольшой инфраструктурой. Также нужно учесть и то, что в случае, если межсетевой экран собирается в кластер, то количество сегментов, которые можно к нему можно подключить, снижается до восьми.
По причине ограничения в десять сетевых адаптеров при работе с большой инфраструктурой размещение межсетевого экрана прямо в VDC пользователя будет неэффективно: число размещаемых в ней межсетевых экранов будет быстро расти, что сделает администрирование инфраструктуры проблемным.
Причина 2. Число VDC и тенантов пользователя. Часто их число довольно велико, что с учетом причины 1 делает размещение файрволов в каждый VDC неудобным. То есть приводит к тому, что их количество растет, что сильно увеличивает нагрузку на департамент безопасности.
→ С учетом причин 1 и 2 вариант с размещением межсетевого экрана между двумя NSX T0 наиболее предпочтителен. Он подводит нас к классической архитектуре построения дата-центров: Border периметр + межсетевой экран и DMZ + Ядро (Core). К тому же, за счет использования vCloud Director мультитенантность гарантируется прямо «из коробки».
Тут важно отметить, что кроме правил прохождения трафика на межсетевых экранов настраивается и NAT (Network Address Translation).
Шаг 2. LLD-документация: описываем компоненты
При разработке детальной схемы размещения межсетевых экранов в облачной инфраструктуре особое внимание нужно обратить на отказоустойчивость. При развертывании межсетевого экрана между двумя NSX T0 она достигается за счет дублирования всех компонентов, а также использования динамического протокола маршрутизации BGP. К тому же, на уровне vSphere физические серверы собираются в кластеры: для них работают свои средства отказоустойчивости и распределения нагрузки.
1. Кластеры
Компоненты NSX T0 и NSX T1 работают на специальных серверах NSX Edge, которые могут быть как виртуальными, так и физическими машинами:
виртуальные машины NSX Edge разворачиваются через интерфейс NSX, который уже содержит в себе образ;
для физических серверов нужно скачать отдельный ISO-файл, установить его на сервер и подключить к NSX Manager.
В нашем случае речь будет идти о NSX T0 и NSX T1, работающих на виртуальных машинах. Но при необходимости в облаке можно развернуть и физические серверы.
Виртуальные машины NSX Edge объединяются в кластеры, на которых размещаются логические компоненты NSX T0 и NSX T1. Они могут находиться на одном или на разных кластерах. В каждом из кластеров располагаются от одного до десяти NSX Edge, но согласно принципам отказоустойчивости не меньше двух.
→ Большинство межсетевых экранов работают в Active-Standby по принципу: одна нода — рабочая, а вторая находится в режиме ожидания, но реплицирует конфигурацию на себя. В NSX все устроено иначе: обе ноды кластера являются рабочими, но нода становится Standby, когда с нее анонсируются ухудшенные при помощи механики AS-Path Prepend BGP маршруты.
Как же происходит переключение downlink NSX T0? И NSX T0, и NSX T1 состоят из SR (Service Router) и DR (Distributed Router):
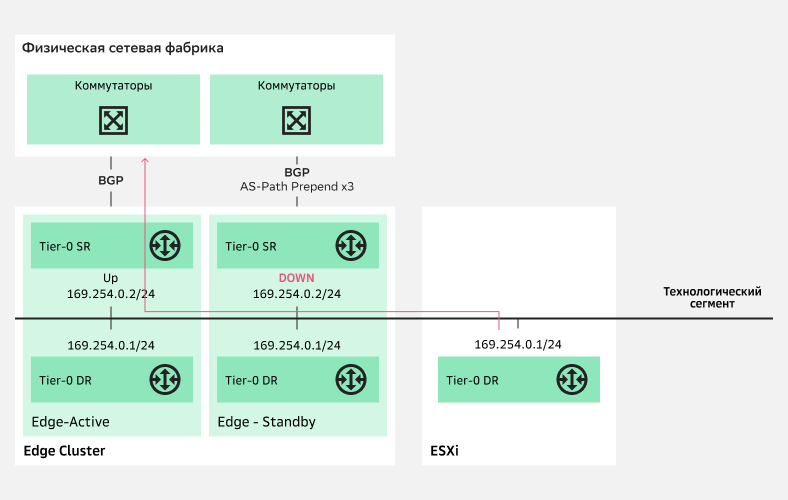 Переключение downlink NSX T0
Переключение downlink NSX T0Коммуникация SR и DR происходит через технологический сегмент. На NSX T0 DR Standby ноды находится в состоянии «Down» до того момента, пока не сработает триггер на переключение. Таким триггером может быть:
падение Uplink-ов активной ноды;
падение самой ноды;
падение Management интерфейса;
падение всех туннельных интерфейсов.
В случае срабатывания триггера активная нода становится Standby, если доступна по management, а весь трафик переключается на ту ноду, которая была в режиме ожидания.
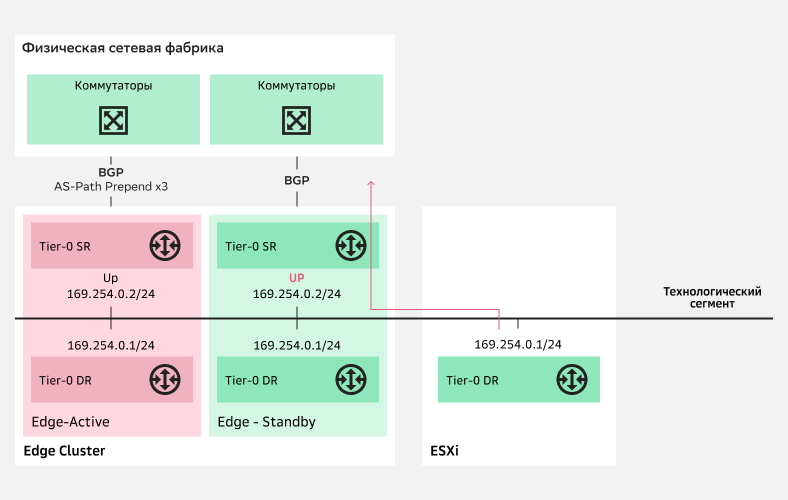 Переключение трафика на Standby-ноду
Переключение трафика на Standby-нодуПри настройке NSX T0 и NSX T1 можно выбрать режим работы Failover - Preemptive/Non Preemptive. Это позволит вернуть роль Active на NSX Edge, который и был Active изначально:
При выборе Preemptive после восстановления Active-ноды трафик снова переключится на нее со Standby-ноды.
При выборе Preemptive восстановления Active-ноды трафик продолжит идти через Standby-ноду.
2. Маршруты
Теперь давайте рассмотрим, как может быть устроена маршрутизация. На схеме видим, что каждый кластер NSX T0 принадлежит своей автономной системе.
Между кластером NSX T0-Border и коммутаторами транспортной сети строится eBGP и происходит анонсирование публичных префиксов, а публичные префиксы через транспортную сеть попадают на интернет-бордеры, где уже организованы BGP-пиринги с интернет-провайдерами.
Между кластерами NSX-T0 поверх межсетевого экрана строится eBGP Multihop. Он строится на Loopback-интерфейсах, расположенных на всех виртуальных машинах Edge. Межсетевой экран не участвует в BGP, а потому аллокация публичных IP-адресов идет через vCloud Director, а их анонсирование происходит с NSX T0-Core.
Между межсетевым экраном и NSX T0 настраивается статическая маршрутизация, что позволяет обеспечить возможность построения eBGP Multihop. Она прописывается на кластерах межсетевых экранов и NSX T0. Таким образом, выход из строя одной виртуальной машины в кластере межсетевого экрана или NSX T0 не приводит к отказу схемы. Также статическая маршрутизация прописывается в сторону NSX T0-Core на VDC-префиксы, в которых находятся ресурсы заказчика.
NSX T1-Core привязан к NSX T0-Core за счет внутренней механики NSX. Посмотрим, как это работает на примере двух T1 и одного T0. Схема соединения выглядит так:
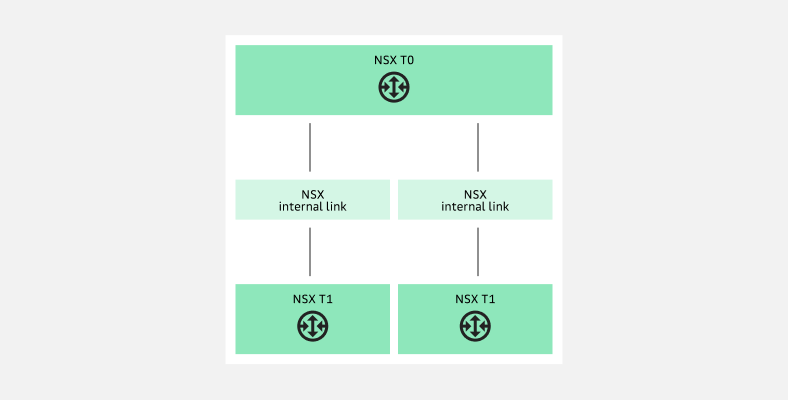 Схема соединения NSX T1-Core и NSX T0-Core
Схема соединения NSX T1-Core и NSX T0-CoreВ консоли NSX в настройках NSX T0 можно увидеть подсети, которые используются как технологические:
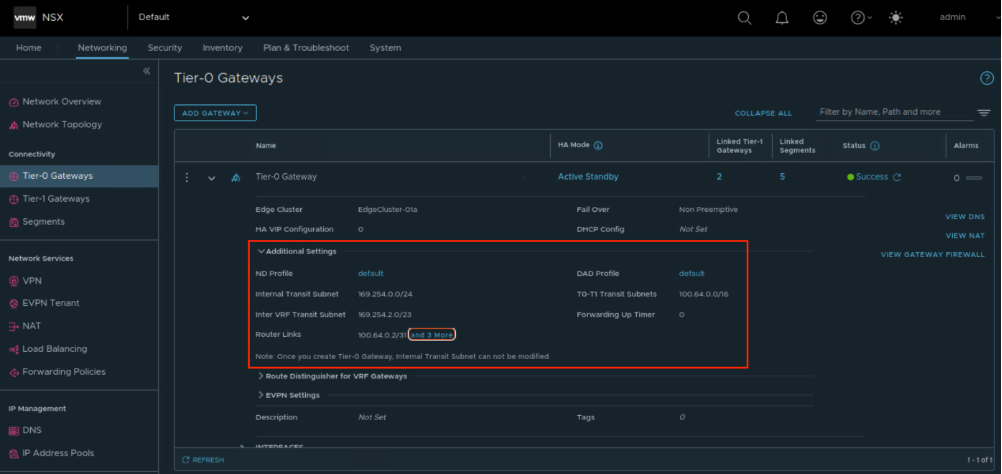 Технологические подсети в настройках NSX T0
Технологические подсети в настройках NSX T0Подсеть 100.64.0.0/16 разбивается на сегменты /31 и выделяется на стыки NSX T1 и NSX T0:
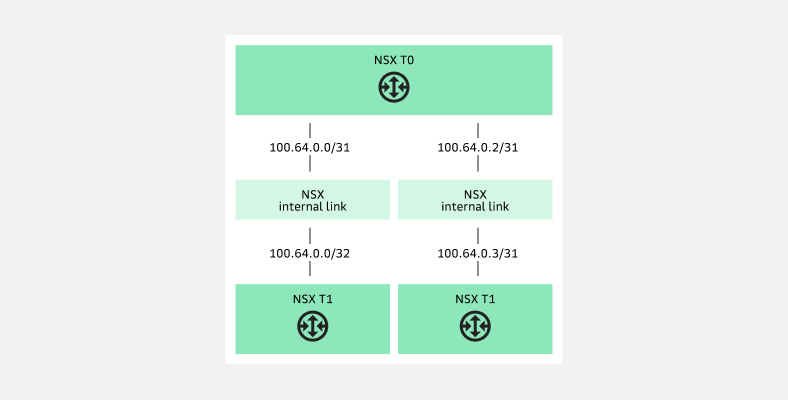 Разбивка подсети 100.64.0.0/16 на сегменты /31
Разбивка подсети 100.64.0.0/16 на сегменты /31В консоли NSX в настройках NSX Т1 можно увидеть, какие IP-адреса назначены:
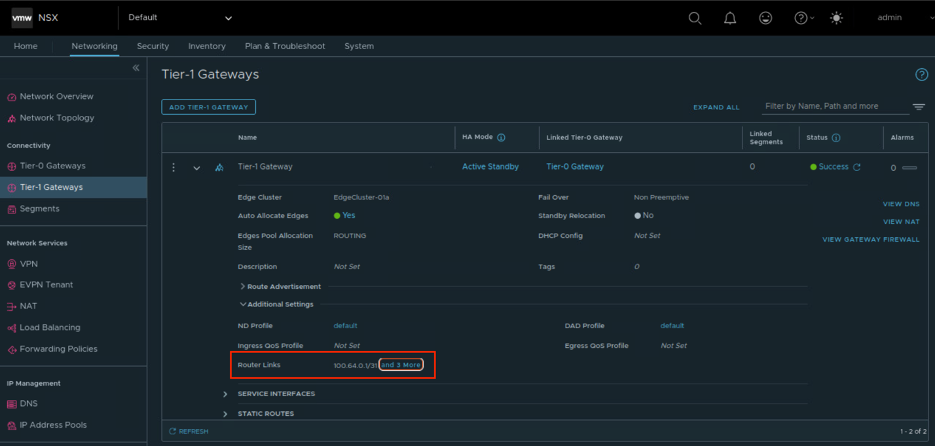 Здесь можно увидеть назначенные IP-адреса
Здесь можно увидеть назначенные IP-адресаВесь трафик с NSX T1 по умолчанию направляется на NSX T0 через технологический сегмент /31 — манипулировать его дефолтным маршрутом нельзя. В отличие от NSX T0, на котором работает и статика, и BGP, NSX T1 поддерживает только статическую маршрутизацию. При необходимости за NSX T1 можно поставить, например, виртуальный роутер.
3.Публичное адресное пространство пользователя
Пользователи облачной инфраструктуры Cloud.ru могут использовать собственное адресное пространство. При этом неважно, есть ли у них автономная BGP-система:
При наличии собственной BGP AS анонсирование префиксов осуществляется от имени автономной системы заказчика, а сеть Cloud.ru становится транзитной автономной системой.
При отсутствии собственной BGP AS публичные префиксы заказчика анонсируются от имени автономной системы Cloud.ru.
Оба случая требуют определенных стандартных действий со стороны заказчика в региональных реестрах интернета RIPE или APNIC для корректного анонсирования префиксов.
Давайте рассмотрим варианты того, как можно анонсировать публичные префиксы пользователя при отсутствии и наличии у него собственного адресного пространства в облачной инфраструктуре Cloud.ru. Для примера в качестве публичного префикса используем 1.1.1.0/24.
Схема 1. Анонсирование публичных префиксов пользователя при отсутствии у него собственной автономной системы.
Если у пользователя нет собственной автономной системы, то для организации BGP стыка NSX T0-Border с сетью Cloud.ru используются приватные номера автономных систем. При анонсировании префиксов заказчика в сторону провайдеров приватные номера BGP AS удаляются, а в качестве origin AS выступает автономная система Cloud.ru. NSX T0-Border маршрутизаторы получают от сети Cloud.ru маршрут по умолчанию.
При необходимости можно дополнительно управлять анонсами префиксов на стыках сети Cloud.ru с провайдерами. Например, с помощью BGP community можно разрешить анонсирование провайдеру 1 и 2 и запретить провайдеру 3 или разрешить провайдеру 3 с AS-Path Prepend.
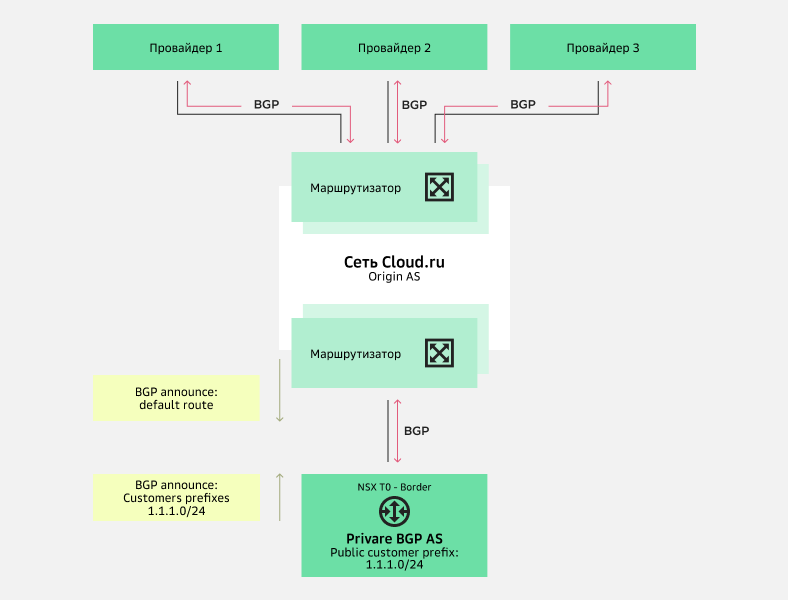 Схема анонсирования публичных префиксов пользователя при отсутствии у него собственной автономной системы
Схема анонсирования публичных префиксов пользователя при отсутствии у него собственной автономной системыСхема 2. Анонсирование публичных префиксов пользователя от имени его собственной автономной системы. Если у пользователя есть собственная автономная система, ее можно использовать на маршрутизаторах NSX T0-Border, выступая в роли origin AS. При этом сеть Cloud.ru выступит транзитной BGP AS, а маршрутизаторы NSX T0-Border получат от нее маршрут по умолчанию.
При работе по этой схеме тоже можно управлять анонсами префиксов на стыках сети Cloud.ru с провайдерами с помощью BGP community.
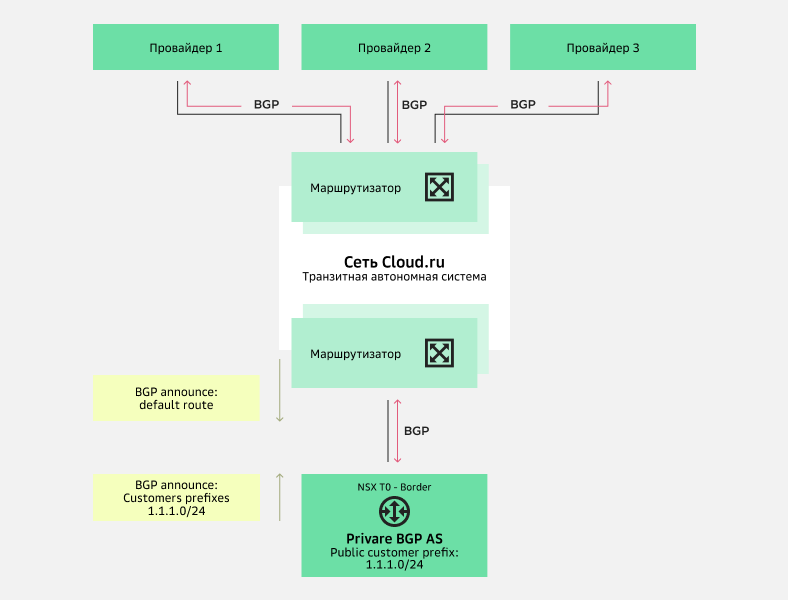 Схема анонсирования публичных префиксов пользователя от имени его собственной автономной системы
Схема анонсирования публичных префиксов пользователя от имени его собственной автономной системыСхема 3. Анонсирование публичных префиксов пользователя от имени его собственной автономной системы через сеть Cloud.ru или внешнюю сеть.
Для организации внешнего подключения и построения сетевой связности внешней площадки с размещенными в Cloud.ru ресурсами, нужно воспользоваться услугой Direct Connect Cloud.ru.
В зависимости от архитектуры внешней сети пользователя BGP-сессии NSX T0-Border могут быть организованы с маршрутизаторами заказчика и/или непосредственно с маршрутизаторами провайдера внешней площадки. С помощью манипулирования BGP-атрибутами можно реализовать разные схемы балансировки и резервирования.
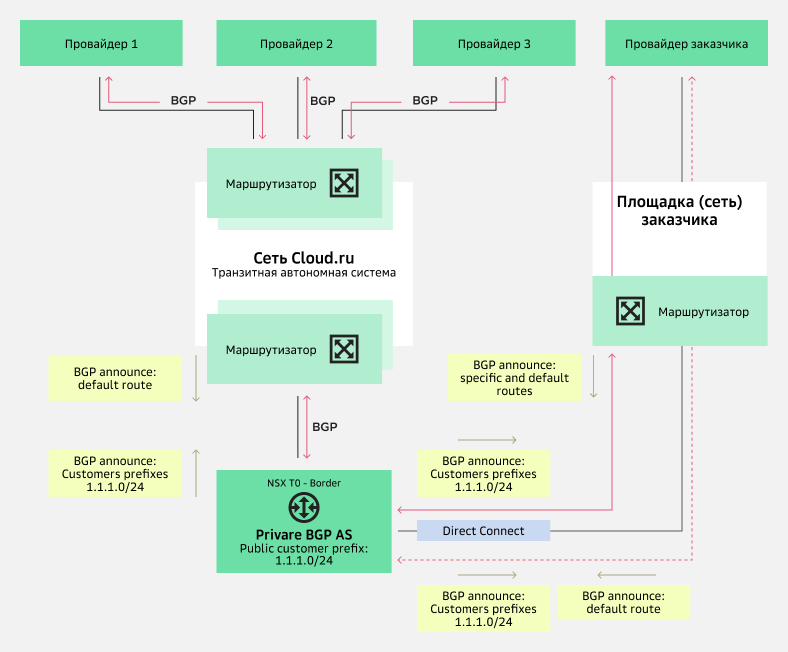 Схема анонсирования публичных префиксов пользователя от имени его собственной автономной системы через сеть Cloud.ru или внешнюю сеть
Схема анонсирования публичных префиксов пользователя от имени его собственной автономной системы через сеть Cloud.ru или внешнюю сетьТакже отметим, что есть и другие варианты использования собственного адресного пространства пользователя в облачной инфраструктуре Cloud.ru.
4. Размещение виртуальных машин на вычислительных ресурсах
Далее рассмотрим размещение виртуальных машин на вычислительных ресурсах. Посмотрим на один из вариантов размещения.
Что мы видим? На схеме четыре хоста ESXi. С точки зрения vSphere мы собираем два кластера по два хоста: один кластер для размещения Edge VM, второй — для размещения виртуальных машин и межсетевых экранов.
На кластере vSphere для размещения Edge VM располагается три кластера NSX: NSX T0-Border, NSX T0-Core, NSX T1-Core. На кластере NSX T1-Core может быть размещено несколько NSX T1. Их число зависит от модели использования ресурсов, которую определяет для себя пользователь. Например, каждый проект может выступать в роли отдельного VDC, в рамках которого размещается свой NSX T1.
Также можно отметить, что компоненты NSX T0-Core и NSX T1-Core на схеме разнесены по разным Edge кластерам. Такой вариант позволяет распределить нагрузку по разным вычислительным мощностям. Но можно размещать NSX T0 и NSX T1 и на одном кластере NSX Edge — например, если большая сервисная нагрузка не подразумевается.
5. Пропускная способность
Пропускная способность при размещении межсетевых экранов в облаке зависит от множества факторов и может быть разной. Для удобства при работе с ней стоит разделить ее на потоки трафика Север-Юг и Запад-Восток:
Для маршрутизации трафика Запад-Восток используется функционал Distributed Routing: маршрутизация обрабатывается самим гипервизором ESXi за счет модуля NSX, который устанавливается после интеграции NSX Manager и vSphere. Трафик перемещается между серверами в оверлейных сегментах.
В работе с трафиком Север-Юг пропускная способность зависит в первую очередь от межсетевого экрана. Иногда необходимо не просто фильтровать трафик на уровне L3-L4, а проводить более глубокую инспекцию. Из-за чего может снижать производительность.
Заключение
Выстроить эффективную сетевую архитектуру с целью размещения межсетевых экранов в облаке можно разными способами. Какой из них выбрать, сетевые архитекторы решают, опираясь на требования заказчиков. При этом на итоговое решение могут повлиять даже самые незначительные нюансы.
В этой статье мы предложили одну из рабочих схем создания такой сетевой архитектуры и описали настройку ее ключевых элементов. Если у вас есть опыт в размещении межсетевых экранов и вы готовы поделиться собственным оригинальным кейсом, свяжитесь с нами через форму ниже. Мы будем рады пообщаться и обменяться экспертизой.