Что такое Deep Learning, или глубокое обучение нейросетей
Глубокое обучение — разновидность машинного обучения, при котором многослойные нейросети сами учатся распознавать сложные паттерны в данных. Модели глубокого обучения, или DL-модели, лежат в основе голосовых помощников, систем рекомендаций, медицинской диагностики и навигации беспилотных автомобилей.
В статье расскажем, что такое глубокое обучение, чем оно отличается от машинного, из чего состоят DL-модели и с какими вызовами сталкиваются разработчики и пользователи нейросетей.


Что такое глубокое обучение
Глубокое обучение (Deep Learning, или DL) — это подраздел машинного обучения (Machine Learning, или ML), в котором используются многослойные искусственные нейронные сети. Эти сети самостоятельно учатся находить сложные закономерности в больших объемах данных.
Главное отличие DL от ML заключается в способе обработки данных. Приведем пример на модели, которая учится распознавать на картинках кошек и собак:
Традиционное машинное обучение
Инженер-разработчик сам выбирает признаки, которые помогут модели различать кошек и собак. Например, можно указать примерный размер ушей разных животных, форму носа, длину хвоста, отличия пород. А еще дать изображения с метками класса: на каждой картинке отмечено, где «кошка», а где «собака».
Результат обучения зависит от того, насколько хорошо человек подобрал и разметил отличительные признаки животных.
Глубокое обучение
Вы так же собираете для модели обучающую выборку из изображений, на каждом из которых есть метка класса: «кошка» или «собака».
Среди тысячи и даже миллионов изображений модель сама найдет критерии, по которым животные отличаются друг от друга. То есть разработчику не надо описывать признаки. К примеру, модель сначала увидит углы и края, потом скомбинирует их в формы ушей и глаз, а затем — в мордочки и туловища.
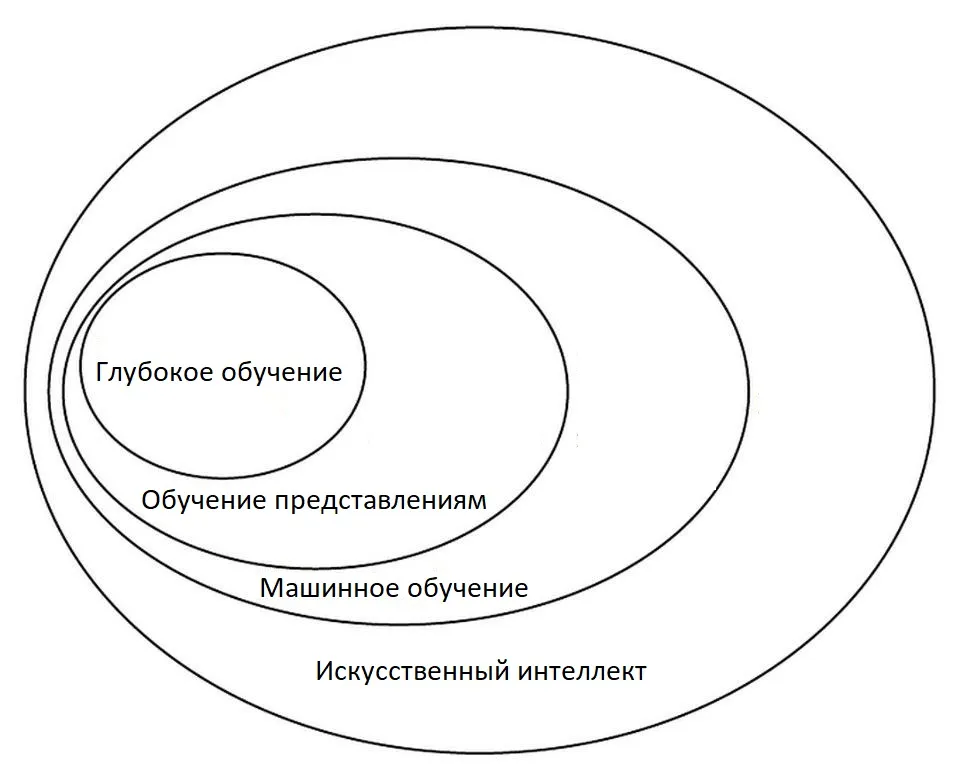 Глубокое обучение — это часть машинного обучения
Глубокое обучение — это часть машинного обученияИстория и эволюция DL
Термин «глубокое обучение» официально появился в 1986 году, но ключевые концепции DL зародились раньше. Еще в 1965 году советские ученые Алексей Ивахненко и Валентин Лапа создали, возможно, первую работающую глубокую нейросеть — восьмислойный перцептрон. А в 1980 году японец Кунихико Фукусима предложил архитектуру неокогнитрона — это была первая в мире сверточная нейронная сеть, которая распознавала рукописные символы.
К концу 2000-х сошлись три критических фактора, которые позволили совершить скачок в развитии глубокого обучения:
Большие данные
Появились огромные наборы размеченных данных для обучения. Например, ресурс ImageNet, который содержит миллионы изображений в тысячах категорий.
Графические процессоры (GPU)
Мощности видеокарт оказались подходящими для параллельных матричных вычислений. Это ускорило обучение в десятки раз.
Алгоритмические улучшения
Появление таких функций активации, как ReLU, помогло решить проблему «исчезающего градиента»: она заключалась в том, что со временем модели быстро забывали информацию, на которой учились.
Прорывом считается создание нейросети AlexNet, которую в 2012 году представила команда из Университета Торонто. В ней были Алекс Крижевский, Илья Суцкевер и Джеффри Хинтон. Модель победила на конкурсе ImageNet и достигла ошибки в 15,3%, тогда как у алгоритма, который занял второе место, ошибка составляла 26,2%. Победа AlexNet доказала, что глубокое обучение — мощный инструмент, который превосходит существовавшие до этого методы.
В 2017 году исследователи Google представили архитектуру нейросети Transformer, которая произвела революцию в обработке естественного языка (NLP). Она позволила моделям анализировать связи между всеми словами в предложении, а не только между теми, что идут друг за другом. На основе Transformer построены современные большие языковые модели (LLM), включая GPT.
Архитектура нейронных сетей
Здесь мы расскажем, как устроены AI-модели: из каких блоков они построены, что делает каждый из них, что такое слои и какие у них есть разновидности.
Устройство AI-моделей
В нейросетях есть несколько составляющих: нейроны, слои и веса. В этом разделе разберемся, что они из себя представляют и зачем нужны.
Нейрон — элементарная вычислительная единица, или узел. Он берет все входные данные, например, сигналы от других нейронов, взвешивает их важность, суммирует и решает, насколько сильный сигнал передать дальше.
Предположим, вы думаете, выйти ли сегодня на пробежку. Вы анализируете, холодно ли на улице, как вы себя чувствуете и сколько есть свободного времени.
Мысленно вы придаете каждому из факторов свой вес. Предположим, фактор «болит колено» для вас важнее, чем «на улице минус десять». Если разболелась нога, бегать вы не пойдете, а если с ногой все хорошо, можно надеть термобелье и выйти на пробежку в холод. Где-то посередине фактор «есть свободный час»: в таком случае можно потренироваться.
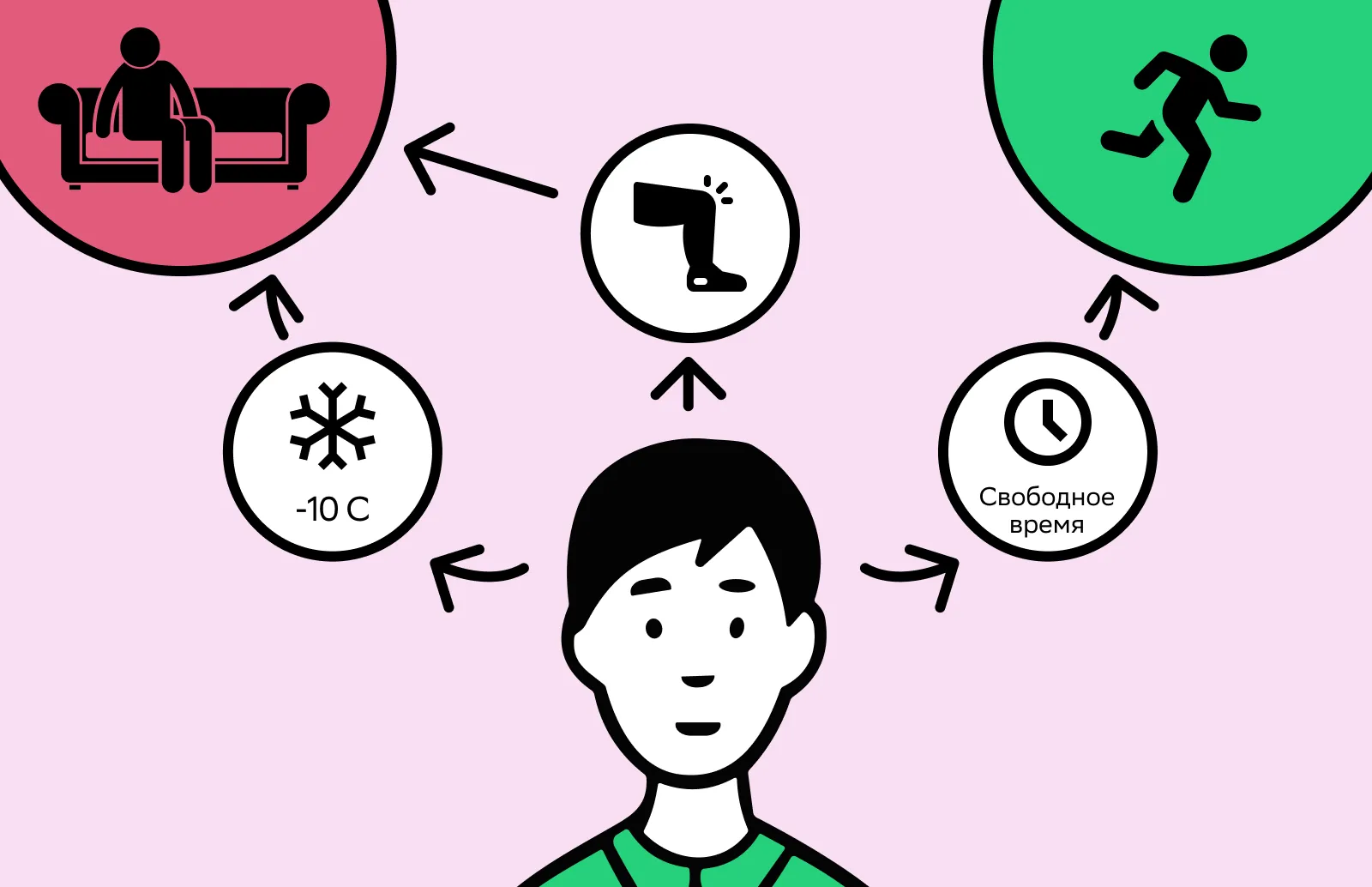 Сошлось больше негативных факторов, и вы решили не бегать
Сошлось больше негативных факторов, и вы решили не бегатьВ этой ситуации вы — «нейрон», который обрабатывает входные сигналы. Эти сигналы для вас — погода за окном, самочувствие и распорядок дня. Вы анализируете все сигналы, придаете каждому из них свой вес и «передаете дальше» итоговое решение: бегать сегодня или нет.
Веса — числовые коэффициенты, которые умножаются на входные данные. Именно веса определяют, насколько сильно нейрон будет учитывать каждый пришедший к нему сигнал. Большой положительный вес означает: «этот сигнал очень важен». Отрицательный вес говорит: «если этот сигнал есть, скорее всего, ответ будет "нет"». Вес, близкий к нулю, означает: «игнорируй эту информацию, она несущественна».
Продолжим аналогию с пробежкой и придадим веса факторам «болит колено», «на улице минус десять» и «есть свободный час». Предположим, что фактор «болит колено» для вас будет с большим негативным весом −5, и бегать вы вряд ли пойдете. У фактора «на улице минус десять» вес −3, а у «есть свободный час» вес +2. Нейрон суммирует эти числа и складывает: в сумме получается отрицательный коэффициент, и нейрон решает, что тренироваться сегодня не стоит.
С другими факторами дела обстоят по-другому. Если есть «легкая усталость», вы можете решить, что для вас это фактор с малым отрицательным весом −0,5. «Теплая погода» будет с весом +5, а «есть время до обеда» с весом +3. В таком случае вы, или нейрон, сложите эти коэффициенты и пойдете тренироваться.
 У более значимых факторов — более высокий вес, и они вносят больший вклад в формирование финального ответа
У более значимых факторов — более высокий вес, и они вносят больший вклад в формирование финального ответаВ продвинутых DL-моделях миллиарды и триллионы параметров. Магия правильной работы моделей заключается в том, чтобы тонко их все настроить и натренировать — и тогда нейросеть выдаст хорошие результаты.
Слои — это группы нейронов, объединенные по общему признаку для решения конкретной задачи.
В случае с пробежкой процесс принятия решения можно разложить на несколько слоев:
Первый слой (входной) — просто констатация фактов без какой-либо оценки. Входной слой собирает сырые данные: «на улице минус десять», «легкая боль в колене», «свободный час с 14 до 15». Этот слой не анализирует, а лишь фиксирует и передает факты дальше.
Второй слой (скрытый) — это ваше аналитическое мышление. Один нейрон взвешивает важность погоды, другой — самочувствия, третий — графика. Они обмениваются сигналами и формируют промежуточные выводы: «холодно, но это решаемо», «колено побаливает, но не критично».
Третий слой (выходной) — это итоговое решение. Выходной слой получает выводы от предыдущего слоя и выдает вердикт. Если вы решили потренироваться, один нейрон активируется и говорит: «да, я пойду». А другой, который отвечает за отказ, молчит.
Это был пример неглубокой нейронной сети, у нее один или два скрытых слоя. Такие нейросети подходят для решения несложных задач. А вот у более продвинутых моделей скрытых слоев десятки или даже сотни. Например, по мере развития LLM количество их слоев планомерно увеличивалось: у GPT-1 их было 12, а у GPT-4 предположительно больше 100. Точные цифры привести сложно, потому что компании-разработчики стараются не разглашать эту информацию.
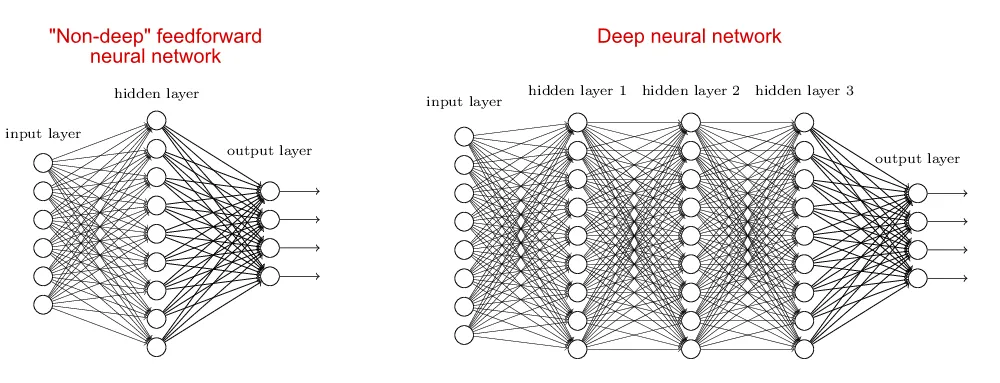 Разница в составе слоев у глубоких и неглубоких нейросетей. Чем сложнее архитектура и размер модели, тем более сложные и абстрактные зависимости между словами и понятиями она может выучить.
Разница в составе слоев у глубоких и неглубоких нейросетей. Чем сложнее архитектура и размер модели, тем более сложные и абстрактные зависимости между словами и понятиями она может выучить.Типы слоев
Расскажем о некоторых типах слоев, которые есть в нейросетях. Оговоримся, что затронем не все: остановимся на одних из самых распространенных.
Линейный слой (dense layers)
Каждый нейрон в таком слое соединен с каждым нейроном из предыдущего. Так можно рассматривать всю информацию целиком, без разбора. Линейные слои отлично подходят для заключительных выводов. Например, после того как другие слои выделили признаки кошки (уши, глаза, усы), линейный слой взвешивает всю эту информацию и выдает ответ: «Это на 98% кошка».
Сверточный слой (convolutional layers)
Вместо того, чтобы смотреть на все изображение, каждый слой применяет операцию свертки. Она работает как условный фильтр и находит в данных только нужные признаки, например формы, текстуры, углы. Сверточные слои идеально подходят для анализа изображений, видео и данных с пространственной структурой.
Рекуррентный слой (recurrent layers)
В отличие от других слоев, у реккурентного есть «память». Он обрабатывает данные последовательно, например слова в тексте или временные точки, и передает информацию о предыдущих шагах на следующий слой. Идеально для решения задач, где важны зависимости между данными. Это, к примеру, работа с естественным языком: машинный перевод, анализ тональности текста, распознавание речи.
Слой пулинга (Pooling layers)
Этот слой следует за сверточным и упрощает полученную информацию, оставляя только самое главное. Он уменьшает объем данных для последующих слоев, что ускоряет работу, предотвращает переобучение, делает модель более устойчивой. А еще экономит вычислительные ресурсы: допустим, на входной картинке очень много пикселей, а слой пулинга сократит количество ресурсов, которые применятся для обработки. Также слой выделит самое важное и сделает модель более устойчивой к шуму.
Эмбеддер (Embedding)
Превращает привычные для человека данные (слова, изображения) в векторы — списки чисел. Получается, эмбеддеры переводят входные данные с человеческого языка на тот, что «поймет» нейросеть.Слова с близким смыслом, например «король» и «королева», получают схожие векторы, так как семантическое значение слов схожее. В памяти модели есть матрица эмбеддингов, где для каждого известного ей слова хранится свой числовой вектор. Когда вы вводите промпт, модель просто подставляет соответствующие векторы из этой таблицы.
Принципы работы и обучения
У DL-моделей много слоев, они работают со сложными взаимосвязями, да еще и самостоятельно учатся их находить. Расскажем, какие есть подходы в развитии нейросетей, как именно они «понимают», как ответить правильно, и поговорим о важных терминах глубокого обучения.
Прямой проход (forward propagation)
Когда вы используете модель, то сначала даете ей какие-то входные данные, к примеру промпт, изображение или видео. С этими данными нейросеть будет работать: генерировать стихотворение, картинку, расшифровывать видео. А по итогу вы получите результат работы модели.
Весь этот путь данных от входного слоя к выходному и есть прямой проход. AI-модель в этот момент не учится, а следует уже выученным правилам, чтобы выдать ответ или решить нужную задачу.
Рассмотрим, как реализуется прямой проход на примере генерации стихотворения в LLM:
1. Вы вводите промпт: «Напиши смешное стихотворение про университет». Входной слой принимает ваш запрос и передает его на следующий.
2. Промпт разбивается на токены, а слова из промпта преобразуются в эмбеддинги — векторы в виде массива чисел, которые LLM использует для работы с текстами.
Токенизация — это разрезание текста на понятные для нейросети кусочки. У каждой модели есть свой словарь токенов, у каждого из которых есть свой числовой идентификатор.
3. На каждом слое эмбеддинги умножаются на веса — коэффициенты, которые показывают, насколько конкретный сигнал важен для принятия решения. Затем добавляется вектор смещений, который делает модель более гибкой. А к полученному результату применяется функция активации, например ReLU или GELU. Она нелинейно преобразует входной сигнал и передает его дальше на следующий слой. Именно это позволяет AI-моделям следовать сложным паттернам: нейросети приближенно, но очень точно воспроизводят сложные зависимости, при этом сохраняя их суть.
4. Получившиеся эмбеддинги передаются следующему слою, и так слой за слоем.
5. На выходном слое получается набор чисел, который декодируется в осмысленный текст. Как итог — вы читаете забавное стихотворение о вузе. А если получилось прямо хорошо, скидываете его друзьям, чтобы посмеяться.
Обратное распространение ошибки (Backpropagation)
Это алгоритм обучения нейросети, который вычисляет, как нужно изменить миллионы и миллиарды ее весов, чтобы минимизировать ошибку.
Представим, что по методу обратного распространения ошибки учим AI-модель находить кошек на картинках. Как это будет происходить:
Даем нейросети фотографию красивого мейнкуна. Нейросеть анализирует изображение и выносит вердикт: «на фото собака». Но на нем большой пушистый кот, так что ответ неверный.
Алгоритм сравнивает ответ модели с правильным, понимает, что нейросеть ответила неверно, и вычисляет функцию потерь — количественное выражение ошибки.
Система определяет, какие веса сильнее повлияли на то, что нейросеть ответила неверно. Для этого вычисляются градиенты — показатели того, насколько нужно изменить каждый вес, чтобы уменьшить ошибку.
Все веса одновременно корректируются в направлении, которое позволит модели лучше распознавать кошек. Часто веса меняются после анализа не одной фотографии, а мини-батча — небольшой группы примеров.
Весь процесс повторяется на тысячах, а если надо — миллионах изображений.
После множества итераций веса корректируются, и модель отвечает правильно. Теперь нейросеть спутает мейнкуна с собакой с минимальной вероятностью.
Оптимизация и функция потерь
Важные понятия в обучении нейросетей — функция потерь, градиентный спуск и оптимизаторы. Расскажем, что это такое и какие у них задачи.
Функция потерь (Loss Function) — это мера того, насколько предсказания модели отличаются от реальных значений. Ее также называют функцией стоимости или ошибки. В процессе обучения модель обрабатывает данные и делает прогноз, а функция потерь вычисляет разницу между этим прогнозом и истинным ответом. Полученное значение используют, чтобы обновлять веса модели.
Основная цель обучения любой DL-модели — минимизировать функцию потерь, то есть уменьшить разрыв между истиной и прогнозом модели.
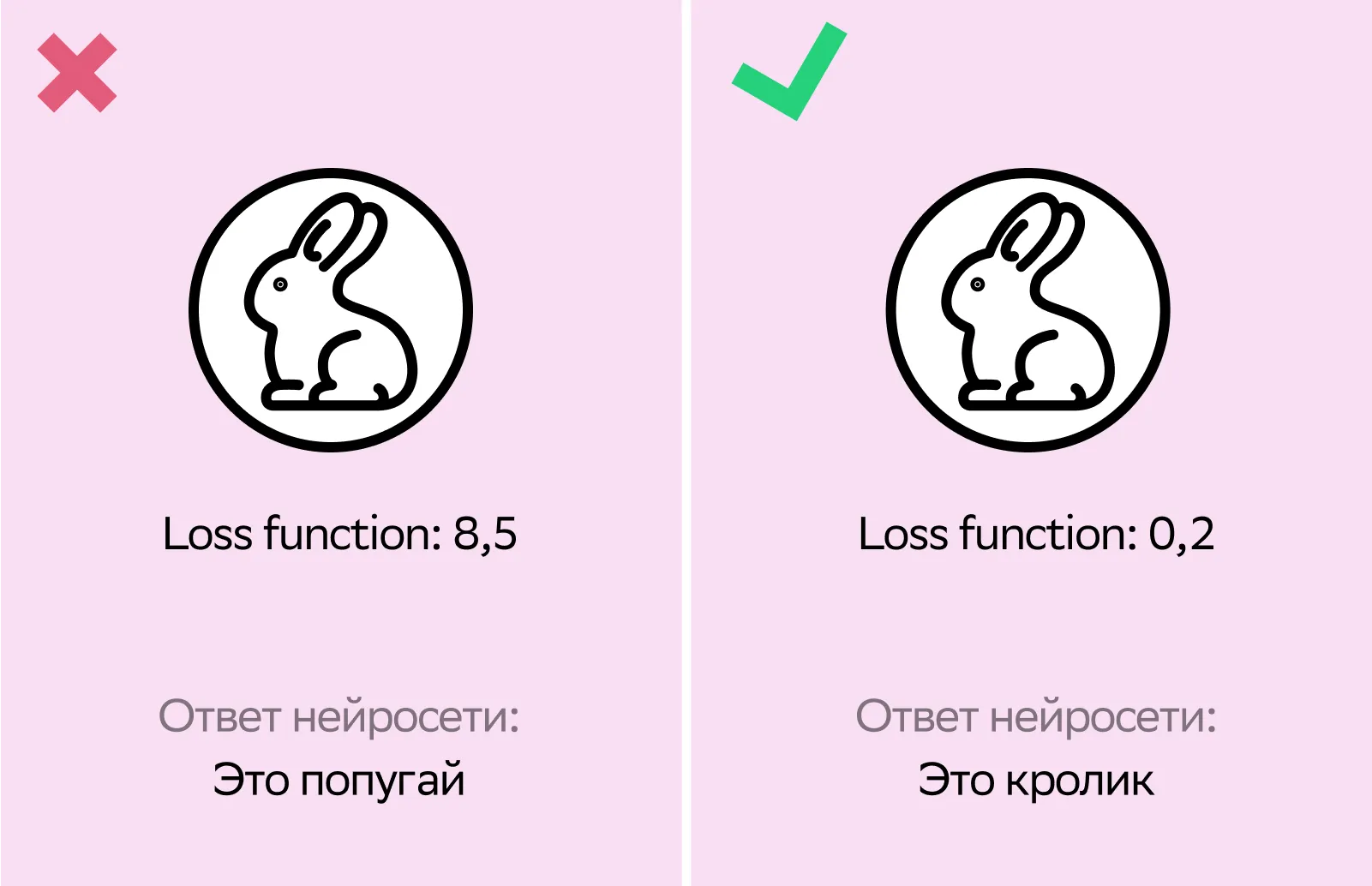 Рассмотрим пример с нейросетью, которая распознает животных на фото. В модель загрузили фото кролика, а она ответила, что это попугай. В таком случае у функции потерь будет высокое значение, так как прогноз модели далек от правильного ответа.
Рассмотрим пример с нейросетью, которая распознает животных на фото. В модель загрузили фото кролика, а она ответила, что это попугай. В таком случае у функции потерь будет высокое значение, так как прогноз модели далек от правильного ответа.Градиентный спуск (Gradient Descent) — алгоритм оптимизации, который по итерациям обновляет веса модели в направлении, которое уменьшает ошибку. Для этого он использует алгоритм обратного распространения ошибки, который вычисляет градиент — сведения о том, какой вес и в какую сторону изменить, чтобы функция потерь уменьшилась.

Оптимизаторы — это алгоритмы, которые реализуют градиентный спуск, делают его более эффективным и стабильным. Приведем примеры оптимизаторов:
SGD (Stochastic Gradient Descent) применяет постоянную скорость обучения ко всем параметрам, обновляет веса прямо пропорционально градиенту. Скорости обучения для разных весов никак не адаптируются, и это может замедлять развитие модели.
Momentum добавляет инерцию, основываясь на предыдущих градиентах. Это сокращает количество шагов и времени, которые нужны для обучения модели, так как она увереннее движется к минимуму ошибки.
Adam — самый популярный оптимизатор, который сам подбирает размер шага для каждого параметра. Хорошо работает «из коробки» на большинстве задач.
Как же функция потерь, градиент, оптимизация участвуют в глубоком обучении? Если кратко, следующий процесс повторяется на разных данных тысячи и миллионы раз:
Прямой проход (Forward Pass)
Нейросеть получает входные данные и последовательно преобразует их через слои: переводит слова в векторы, ищет их значения в векторной матрице, выстраивает прогнозы и декодирует финальный ответ.
Вычисление функции потерь (Loss Calculation)
Ответ нейросети сравнивается с истинным значением. Чем дальше прогноз модели от правды, тем выше значение функции потерь.
Обратное распространение ошибки (Backpropagation)
Алгоритм обратного распространения вычисляет градиент функции потерь по каждому весу. Градиент показывает величину и направление для изменения каждого веса, чтобы улучшить точность ответов.
Обновление весов (Optimization Step)
Оптимизатор, например SGD, Momentum, Adam, использует градиент, чтобы обновить веса сети. Конкретный способ обновления зависит от выбранного оптимизатора.
Функции активации, регуляризация и избегание переобучения
Правильный подбор функций активации и методов регуляризации напрямую влияет на качество работы модели. Первые позволяют нейросети быть более гибкой, а вторые предотвращают переобучение.
Функции активации — это нелинейные преобразования, которые добавляют нейросети способность обучаться сложным зависимостям. Некоторые типы:
ReLU (Rectified Linear Unit) обнуляет отрицательные значения и оставляет положительные без изменений. Простая и эффективная функция, но может «умирать» при больших градиентах.
GELU (Gaussian Error Linear Unit) — сглаженная версия ReLU, лучше подходит для трансформеров и больших языковых моделей.
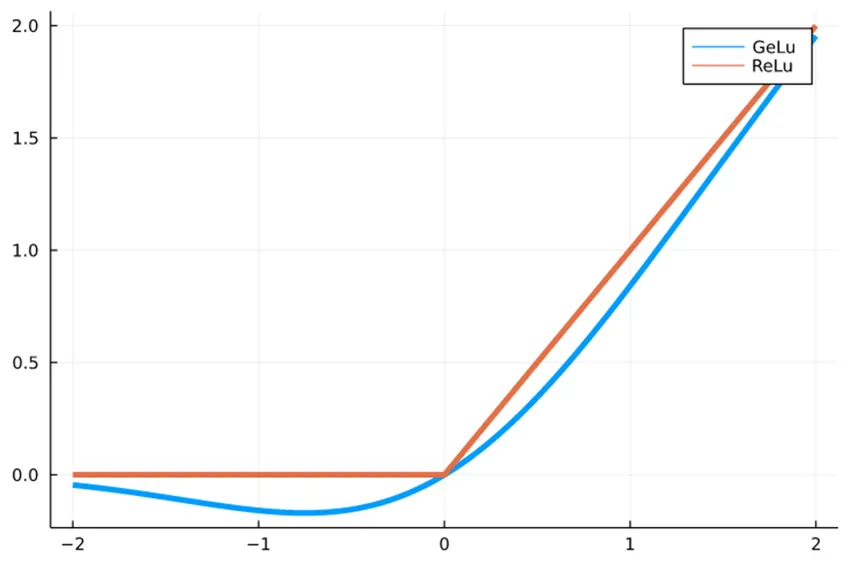 С ReLU вычисления идут быстрее, а с GELU модель качественнее обучается. Плавная работа GELU помогает нейросети лучше улавливать сложные закономерности.
С ReLU вычисления идут быстрее, а с GELU модель качественнее обучается. Плавная работа GELU помогает нейросети лучше улавливать сложные закономерности.Регуляризация и борьба с переобучением. Переобучение возникает, когда модель запоминает неважные детали из обучающих данных вместо более важных общих закономерностей. Методы регуляризации помогают этого избежать. Среди них:
Dropout во время обучения случайным образом «отключает» часть нейронов в слое. Это предотвращает чрезмерную зависимость между нейронами, помогает нейросети меньше зависеть от помех и изменений во входных данных.
L1- и L2-регуляризация добавляет штраф к функции потерь, если у весов большие значения. В итоге более простые модели поощряются, и это помогает избежать переобучения.
Batch Normalization нормализует выходы слоев, что ускоряет обучение и улучшает стабильность.
Early Stopping останавливает обучение, когда качество ответов модели упирается в потолок.
Трансформеры и автокодировщики
Оба подхода — и трансформеры, и автокодировщики — могут использовать архитектуру кодер-декодер, но решают разные задачи. Трансформеры работают с последовательностями, а автокодировщики фокусируются на эффективном представлении данных.
Трансформеры — архитектура нейросетей, которая работает с помощью самовнимания (Self-Attention) — механизма, который помогает модели анализировать контекст и понимать, какие слова в предложении наиболее тесно связаны друг с другом независимо от расстояния между ними. Трансформеры лежат в основе GPT, GigaChat и других современных языковых моделей.
Среди ключевых компонентов трансформеров:
Механизм самовнимания позволяет модели анализировать взаимосвязи между всеми элементами последовательности одновременно.
Позиционное кодирование передает информацию о порядке элементов в последовательности.
Encoder-only, decoder-only и encoder-decoder архитектуры — у модели может быть какая-нибудь из них. Энкодер переводит входные данные в тот вид, который может воспринимать модель, например, в векторы. А декодер переводит все обратно.
Автокодировщики — это нейросети, которые учатся сжимать данные и восстанавливать их обратно с минимальными потерями. Автокодировщики используют, чтобы снизить размерность данных и находить в них повторы и ошибки.
Где используется глубокое обучение
DL-модели — не абстрактная технология, а практический инструмент, который уже сегодня меняет мир. Они повышает точность и скорость диагностики, следят за финансами, автоматизируют рутину на производстве. Расскажем подробнее, в каких областях применяется глубокое обучение.
Медицина
Нейросети определяют новообразования и патологии на КТ, МРТ и рентген-снимках, чтобы помогать врачам быстрее диагностировать заболевания. Алгоритмы AI способны предсказывать свойства соединений и генерировать структуры молекул с нужными свойствами, что ускоряет разработку лекарств. А еще можно использовать AI для изучения анамнеза пациентов, классификации жалоб, чтобы назначать более корректное и эффективное лечение.
При этом все решения остаются за врачом. Только он может отловить галлюцинации AI-модели, вникнуть в анамнез и ситуацию пациента.
Интересный факт
В мае 2025 года нейросеть GigaChat прошла первичную аккредитацию по специальности «Лечебное дело». Она верно ответила на 83% тестовых вопроса и решила 20 ситуационных задач. Проходной балл — 70% в тесте и 17 правильных задач.
Также GigaChat сдал экзамен по кардиологии, педиатрии и неврологии. А еще получил четверку (83% правильных ответов) на выпускном экзамене для шестикурсников медицинского.
Финансовый сектор
AI анализирует транзакции на счетах клиентов, выявляют подозрительные действия и предотвращают мошенничество. Еще модели могут оценивать кредитоспособность заемщиков, искать неочевидные паттерны на финансовых рынках, чтобы прогнозировать изменения цен акций.
По данным НИУ ВШЭ и АНО «Диалог Регионы» за 2024 год, сотрудничество специалиста и AI помогает прогнозировать котировки на бирже с точностью 60%. А Сбер приводит в пример кейс, где инвестор применял нейросеть Perplexity AI с моделью Claude 3.5 и достиг доходности +14% за 4 месяца.
Важно понимать, что AI не всегда может учесть контекст: форс-мажоры или масштабные события, которые способны непредсказуемо влиять на стоимость активов.
Производство
Компьютерное зрение проверяет продукцию на конвейере, находя микротрещины, дефекты сборки или ошибки маркировки с точностью и скоростью, недоступной человеку. Еще такие системы есть в магазинах. Покупатель ставит на весы помидоры, а нейросеть понимает, что человек хочет взвесить — для этого не приходится искать товар в каталоге.
Также с AI можно автоматизировать какую-то часть производства, чтобы освободить людей для более творческих, ответственных задач или минимизировать человеческий фактор.
Наука
Глубокое обучение работает с огромными массивами данных. Модели трансформеров, подобные тем, что используются в языковых моделях, могут анализировать последовательность аминокислот в белках, снимки с телескопов, результаты физических опытов. Важный нюанс: результаты, полученные AI, требуют тщательной проверки учеными и экспертами.
Интересный факт
На одном из подкастов физик Алексей Семихатов задался интересным вопросом. Собственно, вопрос: если не загружать модель посторонними данными, а дать ей информацию по физике за все время развития этой науки, сможет ли AI сделать открытие? Алексей ответил, что этот вопрос может быть решен в будущем.
Социальные сети и маркетплейсы
AI-модели анализируют поведение пользователей: что они смотрели, сколько времени провели на конкретной странице, что лайкнули или добавили в корзину. На основе этого выстраиваются персональные рекомендации, например, какие сериалы, товары или спецпредложения порекомендовать, кого предложить добавить в друзья.
Геймдев и развлечения
Нейросети помогают создавать умных и реалистичных NPC, которые учатся на действиях игрока, или генерировать персонажей с естественной анимацией. AI можно подключать к генерации музыки, игровых механик или развлекательных роликов.
Образование
С помощью AI можно адаптировать сложность программы под уровень ученика или вовсе создавать ее с нуля. А еще автоматически проверять задания, находить места, которые стоит проработать с преподавателем, или генерировать тексты с картинками прямо на сайте или в приложении для учебы.
Проблемы и ограничения
Глубокое обучение — мощный инструмент, но у него есть ограничения, которые мешают использовать DL-модели повсеместно. Одни из главных вызовов — проблема объяснимости, большое потребление ресурсов и качество данных для обучения.
«Черный ящик» и проблема объяснимости
При работе с DL-моделями мы видим только входные данные и результат, но не понимаем логику, по которой искусственный интеллект принимает решения. Поэтому говорят, что DL-модели работают как «черный ящик», так как непонятно, что происходит на внутренних слоях.
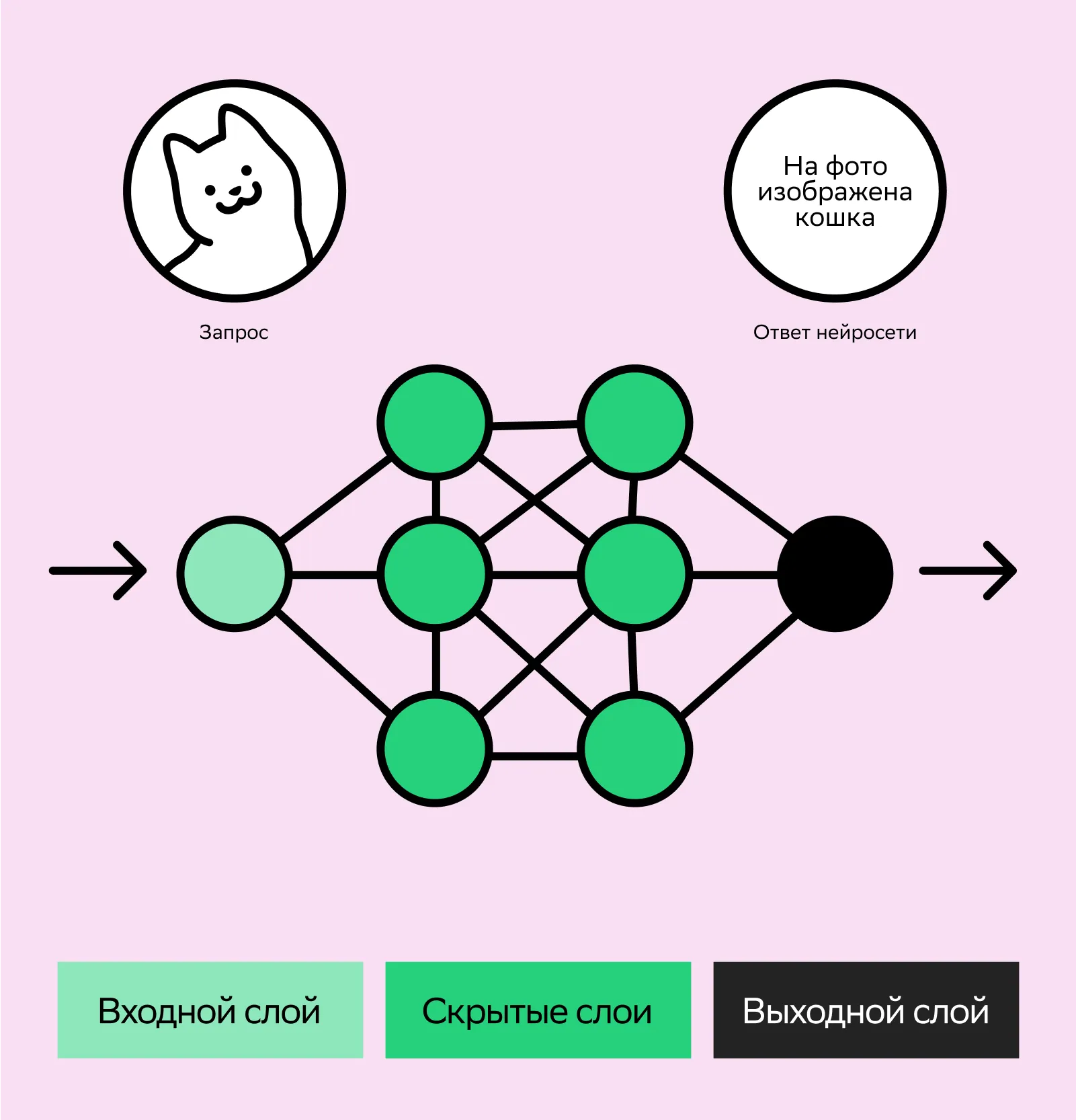 Неясно, что происходит во внутренних слоях и по каким признакам модель решает, что кошка — это кошка, а не собака
Неясно, что происходит во внутренних слоях и по каким признакам модель решает, что кошка — это кошка, а не собакаЭто создает трудности с тем, чтобы доверять AI ответственные решения:
Врачи не могут доверять диагнозу от нейросети, так как не понимают, на основание чего модель его поставила. Еще модели галлюцинируют, а некоторые пациенты не согласны с тем, чтобы в их лечении участвовал AI.
Бывает сложно объяснить, почему модель построила такой инвестиционный план или отказала в кредите конкретному человеку.
Юристам не всегда ясно, по каким критериям модель выносит вердикты, насколько знакома с судебной практикой или человеческой моралью, которая не отображена в законодательных актах.
Большое потребление ресурсов
Современные AI-модели требуют для работы невероятных вычислительных мощностей и энергии. Например, для обучения продвинутой LLM может понадобится более 62 3000 МВт·ч энергии — это столько же, сколько потребляют 20 000 российских квартир за целый год.
Нейросети влияют и на экологию. После обучения модели останется углеродный след в 200–300 тонн CO₂, что сопоставимо с выбросами автомобиля за 20–30 лет езды. Ежедневно модели потребляют тонны воды, а еще водой нужно охлаждать дата-центры, чтобы нейросеть не вышла из строя.
И, конечно, на разработку, развитие и обслуживание большой модели — это дорого.
Есть и другие ограничения:
Модели требуют огромных размеченных датасетов, к примеру, миллионы или миллиарды текстов, видео, изображений, аудиозаписей. Это усложняет работу разработчиков, так как им надо отобрать данные, избавиться от мусора или вообще найти информацию, что трудно для узкоспециализированных сложных областей.
Нейросети активно используются уже несколько лет, но в странах нет сильной правовой базы, которая регламентировала бы их работу. Могут появиться законы, которые ограничат материалы, которые можно использовать для обучения, или сферы деятельности, где допустимо применять AI. Это может усложнить поиск данных для обучения, которой порой и так не хватает.
Нейросети перенимают и усиливают человеческие предубеждения, так как обучаются на информации, которую создал человек.
AI склонен соглашаться с пользователем, даже если тот выражает не совсем корректную точку зрения. Это может подкреплять когнитивные искажения, но уже у самих людей.
Заключение
Несмотря на то, что у моделей есть ограничения и они тратят много ресурсов, команды работают над улучшениями: стараются снизить затраты на обучение и ежедневное обслуживание, уменьшить потребление воды и в целом снизить влияние на экологию. Кстати, и сами нейросети помогут в решении этих задач — возможно их «сотрудничество» со специалистами, чтобы понять, как все оптимизировать.
Но главное — глубокое обучение позволяет создавать нейросети, которые выступают отличными компаньонами. Они видят сложные закономерности, помогают в сложных вычислениях и важных сферах деятельности, например здравоохранении, науке, образовании. Помогают находить ошибки в производстве, ускорять разработки, строить прогнозы на основе данных и просто развлекаться, если вдруг захочется сочинить смешное стихотворение.