Базы данных SQL: как правильно связывать таблицы с JOIN и ключами
Если вы работаете с реляционными базами данных, то должны уметь правильно связывать таблицы. Это необходимо для оптимизации запросов, структурирования информации и поддержания ее целостности. Связывать таблицы можно с помощью ключей и специальных команд. В статье разберем самые распространенные подходы.

 Работа с базой данных
Работа с базой данныхЧто такое реляционные базы данных
Реляционными называют базы данных, где информация хранится в виде таблиц. На скрине — пример.
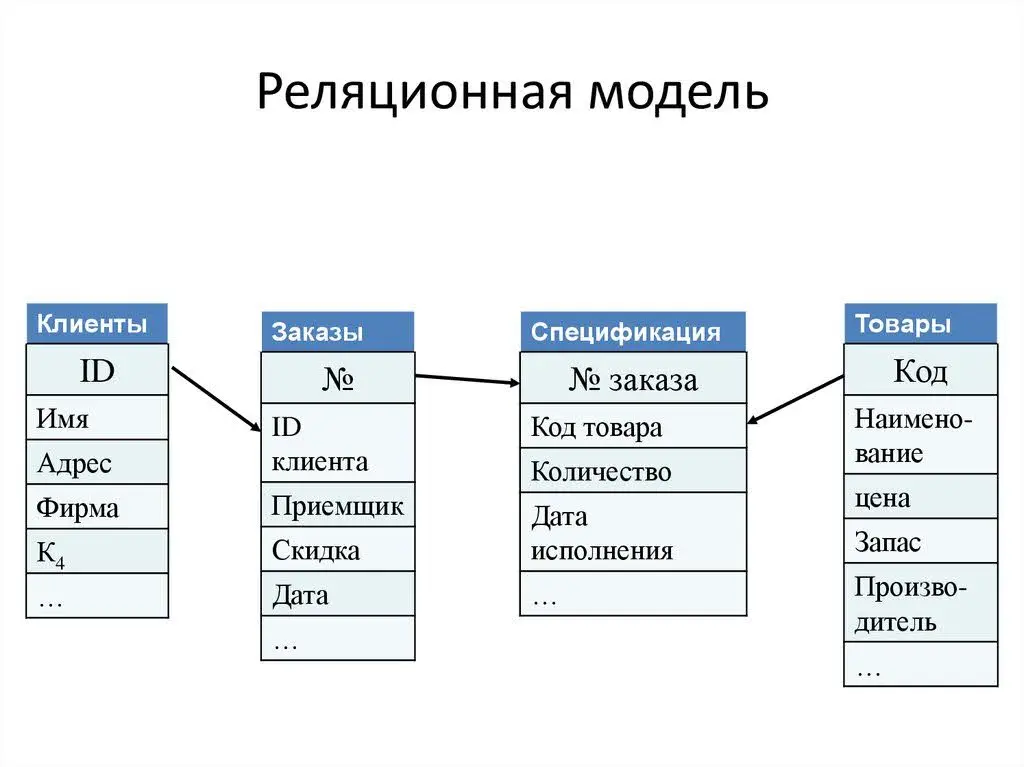 Реляционная база данных
Реляционная база данныхРеляционными такие базы назвали потому, что хранение данных в них организовано на принципах реляционной алгебры и теории отношений. Это позволяет связывать таблицы между собой и за счет этого легко искать и сопоставлять информацию.
Основные элементы структуры реляционной базы данных:
Таблицы — двухмерные структуры для упорядоченного хранения информации.
Столбцы — вертикальные поля, описывающие типы хранимых данных.
Строки — горизонтальные поля, содержащие основные сведения.
Ключи — атрибуты для идентификации и связывания сведений из разных таблиц.
Причин популярности реляционных базы данных много, в их числе:
Строгая структура данных: информация четко распределена, поэтому в ней удобно ориентироваться.
Поддержка SQL: стандартный язык запросов SQL позволяет делать выборки, вставки, обновлять и удалять данные.
Целостность данных: информация остается точной, неизменной и непрерывной на всех этапах работы с ней.
Моделирование сложных структур данных: благодаря связям между таблицами можно структурировать информацию, избегая дублирования и ошибок.
Удобство интеграции: реляционные базы данных интегрируются с различными приложениями, фреймворками и аналитическими инструментами.
Поддержка индексов: быстрое выполнение запросов даже при больших объемах данных.
Реляционные базы данных бывают локальными и облачными. Локальные находятся на компьютерах пользователей, а облачные — в облачных инфраструктурах, которые поддерживаются провайдерами. Например, использование управляемых решений, таких как Evolution Managed PostgreSQL от Cloud.ru, позволяет сосредоточиться на проектировании структур данных и написании запросов, полностью делегируя вопросы установки, обновления, резервного копирования и масштабирования базы данных провайдеру.

Ключи в SQL
Для идентификации записей в базе данных и связывания таблиц применяются так называемые ключи. Они бывают первичными, составными, внешними и уникальными.
Первичный ключ
Primary Key условно считается цифровым паспортом табличных записей. Он представляет собой поле/несколько полей, которое позволяет идентифицировать записи и дает гарантии, что они будут уникальными.
У первичного ключа БД есть особенности:
Значение Primary Key в таблице всегда уникально. Двух записей с одним параметром первичного ключа не бывает.
Всем записям присвоены уникальные идентификаторы, поэтому исключается пустое значение ключа.
Все сведения в базах данных упорядочены в соответствии с Primary Key.
Первичный ключ — важный элемент таблицы, поскольку он помогает ее индексировать и тем самым повышает производительность запросов. Также Primary Key способствует целостности данных.
На скрине — пример таблицы с именами студентов.
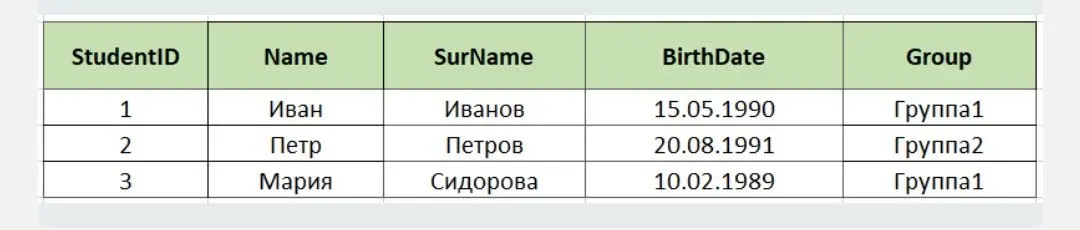 Таблица с первичным ключом
Таблица с первичным ключомВ этой таблице StudentID — первичный ключ. Применяя ключ для конкретного учащегося, можно вывести все данные о нем.
А чтобы создать первичный ключ нужно действовать следующим образом:
 Алгоритм создания таблицы с первичным ключом
Алгоритм создания таблицы с первичным ключомСоставной ключ
По сути составной — это первичный ключ, только из двух и более столбцов. Следовательно, функции у него такие же.
Особенности составного ключа:
В ключе присутствуют значения из нескольких столбцов.
Уникальность составного ключа достигается за счет комбинации содержимого и привязанных к нему столбцов.
Значения в ключе не бывают нулевыми.
В таблице ниже составным ключом будут столбцы StudentID и CourseID.
 Таблица с составным ключом
Таблица с составным ключомА создается составной ключ так:
 Алгоритм создания таблицы с составным ключом
Алгоритм создания таблицы с составным ключомУникальный ключ
Unique Key ключ тоже связывает уникальные значения с данными из таблицы. Его отличия от первичного такие:
В одной таблице может быть не один уникальный ключ.
Такой ключ состоит из значений одного или нескольких столбцов, но комбинации этих значений всегда уникальны.
Уникальный ключ иногда содержит значения NULL.
В таблице-примере первичным ключом является OrderID, двумя комбинированными уникальными — OrderNumber+OrderDate и CustomerID+TotalAmount:
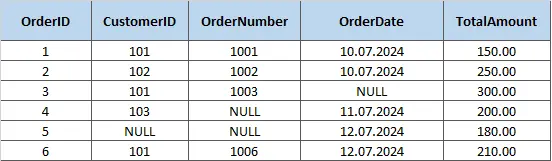 Таблица с уникальным ключом
Таблица с уникальным ключомСоздается уникальный ключ с помощью алгоритма:
 Создание уникального ключа
Создание уникального ключаВнешний ключ
Foreign Key связывает записи в первой таблице с записями во второй. Это происходит через поле, которое служит первичным ключом в главной таблице. Внешний ключ позволяет добиться четкой структуры базы данных и обеспечить ссылочную ценность, то есть согласованность сведений из двух таблиц.
Нюансы, связанные с внешним ключом в базах данных SQL:
В таблице бывает несколько Foreign Key.
Во внешнем ключе допустимы нулевые значения, если это не противоречит правилам организации хранения данных.
Ключ не определяет структуру таблицы и порядок хранения информации.
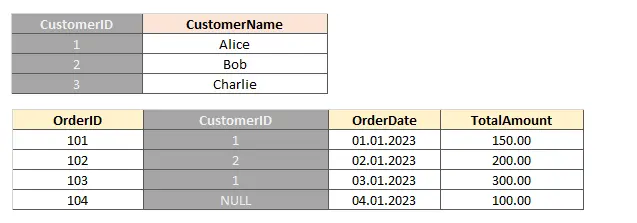 Таблица с внешним ключом
Таблица с внешним ключомЧтобы создать внешний код, нужно ввести:
 Создание таблицы с внешним ключом
Создание таблицы с внешним ключомВиды связи в базах данных
Есть три варианта связи таблиц в базах данных: «один к одному», «один ко многим», «многие ко многим». Разбираемся, как установить такие связи, на примере таблиц MySQL.
Один к одному
Подход One-to-One описывает связь между двумя таблицами, где каждая запись в первой таблице имеет одну соответствующую запись во второй. Схема позволяет организовать данные по логическим группам, избежать дублирования и повысить производительность запросов.
Чтобы установить такую связь, нужны первичный и внешний ключи. Как действовать:
Установите в одной из связываемых таблиц Primary Key, идентифицирующий нужную запись.
В другой таблице, с которой устанавливаете связь, создайте Foreign Key. Он будет ссылаться на первичный ключ в родительской таблице.
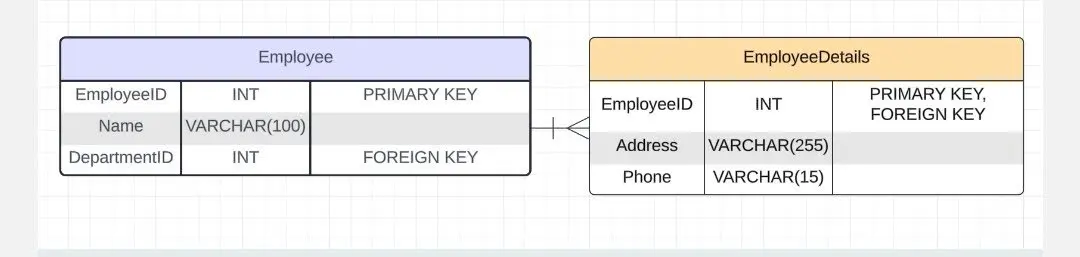 Визуализация связи «один к одному»
Визуализация связи «один к одному»На скринах — код в MySQL для каждой из связываемых таблиц.
 Родительская таблица и дочерняя таблицы
Родительская таблица и дочерняя таблицыВ дочерней таблице есть первичный ключ EmployeeID. Он же — внешний в родительской таблице. Именно EmployeeID позволяет установить связь между записями.
Один ко многим
One-to-Many применяется, когда каждая запись в первой таблице может иметь отношение к нескольким записям второй таблицы. Но при этом каждая запись второй таблицы может относиться только к одной записи первой.
Связь One-to-Many отвечает за моделирование зависимости в данных. Например, в одном подразделении компании числятся десятки сотрудников, но каждый работник относится только к одному подразделению.
Чтобы получить отношение «Один-ко-многим», в главной таблице сформируйте первичный ключ, а в другой — внешний ключ, который будет отсылкой на первичный.
В результате каждая запись во второй таблице будет соотнесена с одной записью в главной. Зато у записи в родительской может быть несколько связанных записей в дочерней.
На скрине пример связи между тремя таблицами — одной родительской и двумя дочерними.
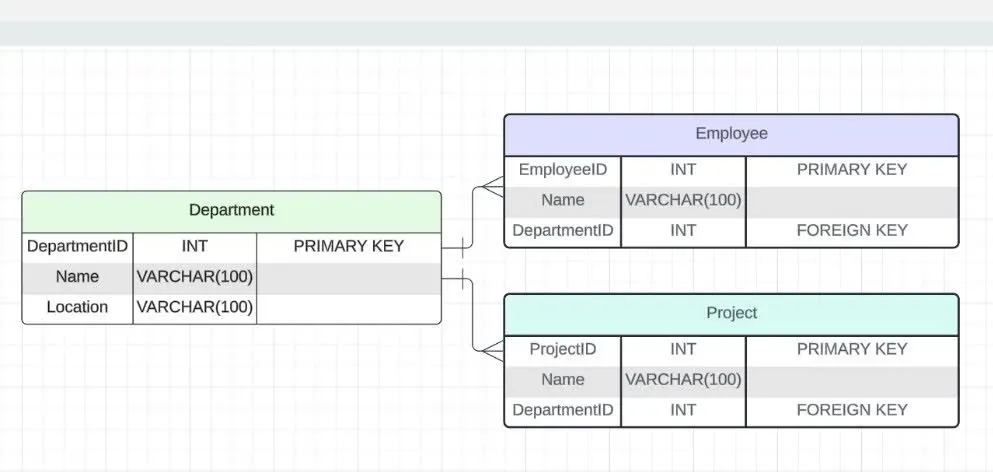 Визуализация связи «один ко многим»
Визуализация связи «один ко многим»Чтобы создать такую связь, используйте:
 Родительская таблица Department
Родительская таблица Department  Дочерние таблицы Employee и Project
Дочерние таблицы Employee и Project Многие-ко-многим
Many-to-Many применяется, если каждая запись в главной таблице может соотноситься с несколькими записями в дочерней, и наоборот.
Чтобы получилась связь «Многие-ко-многим», сделайте две таблицы с первичным ключом в каждой. Затем подготовьте еще одну таблицу для хранения внешних ключей из основных таблиц и установите через нее связи с помощью внешних ключей.
На скрине — наглядное представление связи:
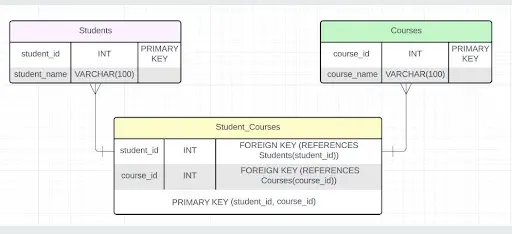 Визуализация связи «многие ко многим»
Визуализация связи «многие ко многим»Создается связь «многие ко многим» с помощью кода:
 Код для связи «многие ко многим»
Код для связи «многие ко многим»Соединение таблиц с помощью JOIN
Чтобы связать данные из разных таблиц, можно использовать команды JOIN в SQL. Рассмотрим варианты JOIN-команд и их применение.
INNER JOIN
Команда INNER JOIN в SQL позволяет объединять таблицы на основе общего столбца. Она выбирает только те записи, которые есть в обеих таблицах и соответствуют условию соединения. Если совпадений нет — строка не попадает в результат.
Чтобы было понятнее, разберем пример с двумя таблицами. У нас есть:
Таблица Users
user_id | username | email |
1 | Ivan | ivan@mail.com |
2 | Anna | anna@mail.com |
3 | Sergey | sergey@mail.com |
Таблица Orders
order_id | order_date | amount | user_id |
101 | 2023-09-01 | 250.00 | 1 |
102 | 2023-09-02 | 180.50 | 2 |
103 | 2023-09-03 | 90.00 | 4 |
Тогда пример запроса для их объединения:
Результатом выполнения команды будет таблица:
user_id | username | order_id | amount |
1 | Ivan | 101 | 250.00 |
2 | Anna | 102 | 180.50 |
В таблице мы видим, что пользователь Ivan связан с заказом №101. Anna — с заказом №102. Пользователь Sergey в таблице заказов отсутствует, поэтому он не попал в результат. Заказ №103 с user_id=4 тоже не учитывается, поскольку пользователя нет в таблице Users.
LEFT JOIN и RIGHT JOIN
LEFT JOIN возвращает все записи из левой таблицы, даже если для них нет соответствий в правой. RIGHT JOIN действует по тому же принципу, но наоборот — возвращает записи из правой таблицы и добавляет данные из левой, если они есть. Если совпадений не найдется, то на месте «пустых» значений будет NULL.
Пользователи (users):
id | name |
1 | Иван |
2 | Мария |
3 | Алексей |
Заказы (orders):
id | user_id | product |
1 | 1 | Телефон |
2 | 2 | Ноутбук |
3 | 3 | Планшет |
Пример кода для связывания таблиц LEFT JOIN:
Результат:
name | product | |
Иван | Телефон | |
Мария | Ноутбук | |
Алексей | NULL |
Клиент все равно выводится, даже если он ничего не заказывал.
Пример кода для связывания таблиц RIGHT JOIN:
Результат:
name | product |
Иван | Телефон |
Мария | Ноутбук |
NULL | Планшет |
Заказ с планшетом есть, но пользователь с id=4 отсутствует в таблице users.
FULL OUTER JOIN
FULL OUTER JOIN объединяет строки из обеих таблиц, даже если нет совпадений по условию соединения. Если совпадение найдено — строки объединяются, если нет — команда ставит NULL.
Таблица Users
user_id | username | email |
1 | Ivan | ivan@mail.com |
2 | Anna | anna@mail.com |
3 | Sergey | sergey@mail.com |
Таблица Orders
order_id | order_date | amount | user_id |
101 | 2023-09-01 | 250.00 | 1 |
102 | 2023-09-02 | 180.50 | 4 |
Запрос для связывания FULL OUTER JOIN:
Что получается:
user_id | username | order_id | amount |
1 | Ivan | 101 | 250.00 |
2 | Anna | NULL | NULL |
3 | Sergey | NULL | NULL |
NULL | NULL | 102 | 180.50 |
Пользователь Ivan совпал с заказом №101, поэтому данные из обеих таблиц объединились. Anna и Sergey есть в таблице Users, но заказов у них нет, поэтому в полях Orders стоит NULL. Для заказа №102 с user_id = 4 не нашлось пользователя, поэтому в полях Users будет NULL.
CROSS JOIN
CROSS JOIN в SQL это команда, которая объединяет две таблицы, создавая все возможные комбинации строк между ними. Каждая строка из первой таблицы объединяется со всеми строками из второй. Условия соединения в этом случае не нужны — команда просто перемножает строки. Например, если в первой таблице 3 строки, а во второй 4, то на выходе получится 12 строк.
Таблица Products
product_id | product_name |
1 | Laptop |
2 | Phone |
Таблица Colors
color_id | color_name |
1 | Black |
2 | White |
3 | Silver |
Запрос с CROSS JOIN:
Результат выполнения:
product_name | color_name |
Laptop | Black |
Laptop | White |
Laptop | Silver |
Phone | Black |
Phone | White |
Phone | Silver |
Практические примеры SQL-запросов с JOIN
В некоторых проектах приходится использовать сложные запросы, состоящие из нескольких команд. Приведем два примера.
1 пример: INNER JOIN + LEFT JOIN
Допустим, у нас есть 3 таблицы:
Customers — клиенты.
Orders — заказы.
Payments — платежи.
Делаем такой запрос:
INNER JOIN связывает клиентов и заказы. LEFT JOIN добавляет информацию о платежах. Если платежа еще нет, будет значение NULL.
2 пример: RIGHT JOIN + INNER JOIN
Имеем три таблицы:
Employees — сотрудники.
Departments — отделы.
Projects — проекты.
Запрос:
RIGHT JOIN гарантирует, что каждый сотрудник попадает в результат, даже если не числится ни в одном отделе. INNER JOIN оставляет только тех сотрудников, которые участвуют в проектах.
Агрегатные функции и групповые операции
Агрегатные функции в базах данных — это функции, которые работают не с отдельными строками, а с наборами данных, позволяя обобщать и группировать информацию.
Некоторые агрегатные функции в SQL:
COUNT() — количество строк.
SUM() — сумма значений.
AVG() — среднее значение.
MIN() — минимальное значение.
MAX() — максимальное значение.
Групповые операции реализуются с помощью GROUP BY. Она объединяет строки по какому-то признаку, чтобы к каждой группе применить агрегатные функции.
Например, нужно подсчитать количество заказов у каждого клиента. Есть две таблицы — Customers (customer_id, name) и Orders (order_id, customer_id, amount).
Применяем команду:
Этот запрос покажет всех клиентов и количество их заказов. Даже если заказов нет, благодаря команде LEFT JOIN клиент все равно попадет в результат, но с нулевым значением.
Оптимизация данных с помощью индексов
Чтобы повысить производительность запросов в базах данных, можно использовать индексы. Это дополнительные структуры, которые помогут оперативно искать нужные записи. Они особенно полезны, если вы объединяете таблицы с большим количеством данных. Индексы будут выполнять роль указателей.
Типов индексов для баз данных SQL много. Основные классификации:
Кластеризованные и некластеризованные. Первые определяют порядок хранения данных в таблице. Вторые — создают отдельную структуру данных с указателями на табличные строки.
Уникальные и неуникальные. Первые гарантируют уникальность всех значений в столбце таблицы. Вторые — допускают, что значения могут повторяться.
Bitmap — индекс для столбцов, где много повторяющихся значений. Для представления табличных данных он использует битовые карты.
Хеш — индекс, позволяющий искать данные по точным совпадениям.
Полнотекстовый — индекс, который позволяет быстро ориентироваться в текстовых данных и поддерживает сложные запросы.
Синтаксис простейшего индекса: CREATE INDEX index_name ON table_name (column_name). Уникальный индекс создается по такому алгоритму: CREATE UNIQUE INDEX unique_order_idx.
Если нужно изменить или удалить индекс, пригодится алгоритм:
При работе с индексами учитывайте, что у каждой базы данных своя специфика и свои синтаксисы. Доступные возможности оптимизации лучше уточнять из документации по вашей базе.
Заключение
Правильное связывание таблиц с помощью ключей и операторов JOIN — фундаментальный навык для работы с реляционными базами данных. Освоение этих инструментов позволяет не только эффективно извлекать и объединять разрозненные данные в целостную информацию, но и закладывать основы производительности, целостности и масштабируемости вашей системы.
Понимание различий между типами связей и JOIN-операций превращает сложные задачи по работе с данными в структурированный и предсказуемый процесс, что в конечном итоге является ключом к созданию надежных и мощных приложений.