Команда grep в Linux: как искать строки и шаблоны
Чтобы быстро находить ошибки и отслеживать предупреждения в лог-файлах Linux-приложений или самой системы, администраторы и разработчики используют команду grep. Она упрощает просмотр и анализ логов, позволяя эффективно искать и обрабатывать текстовые шаблоны в файлах. В этой статье рассмотрим задачи, которые можно решать с помощью grep.


- Синтаксис команды grep
- Как применять команду grep в Linux
- Регулярные выражения в grep
- Примеры регулярных выражений grep
- Как сопоставить отдельные символы
- Как сопоставить только точку (.)
- Как использовать якоря
- Как сопоставить набор символов с помощью grep
- Какие универсальные символы существуют
- Как проверить последовательность
- Коротко о команде grep в Linux
Синтаксис команды grep
Основной синтаксис команды grep выглядит следующим образом:
В нее входят:
[опции] — флаги командной строки, которые изменяют поведение grep;
шаблон — регулярное выражение, которое нужно найти;
[<путь к файлу или папке>] — имя одного или нескольких файлов, в которых необходимо выполнить поиск.
Как применять команду grep в Linux
Приведем примеры использования grep на практике, а также обсудим, какие флаги командной строки используются:
-i — ищем строку без учета регистра в указанном файле. Например, найдем строки с UNIX, Unix, unix командой:
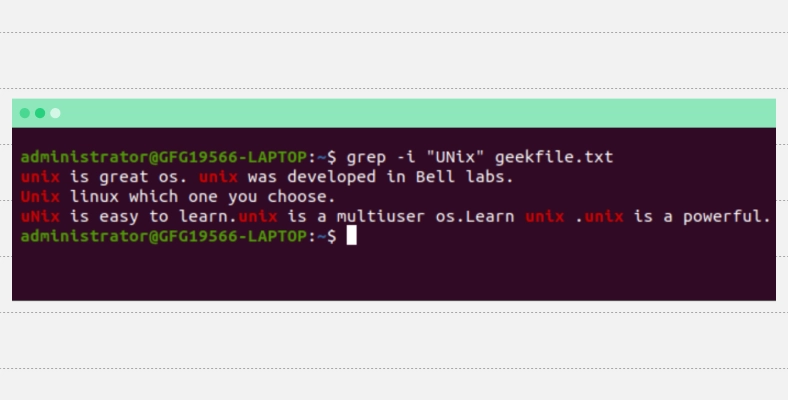 Использование опции -i
Использование опции -i-c — находим количество строк, которые соответствуют заданному шаблону:
-l — отображаем файлы, которые содержат заданную строку или шаблон:
-w — по умолчанию grep сопоставляет нужную строку, даже если она найдена как подстрока в файле. А параметр -w позволяет отображать только целые слова:
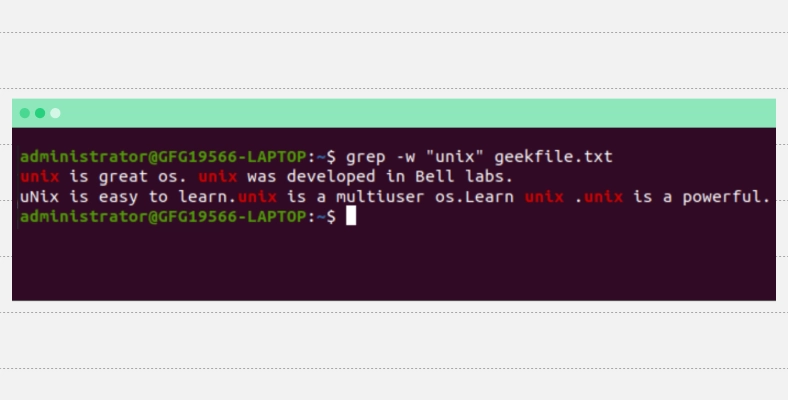 Применение параметра -w
Применение параметра -w-o — по умолчанию grep показывает всю строку, которая совпала по запросу. Но при помощи опции -o можно выбрать только определенное словосочетание:
-n — отображаем номер строки файла с совпавшей строкой:
-v — находим строки, которые не соответствуют указанному шаблону строки поиска:
^ — этот параметр определяет начало строки. В grep его можно использовать для сопоставления строк, которые начинаются с заданного шаблона:
$ — используется как якорь конца строки, позволяя искать строки, заканчивающиеся на определенный шаблон или набор символов:
-e — задаем выражение с этой опцией, которое можно использовать несколько раз:
-f — берем шаблоны из файла по одному на строку:
«-A», «-B», «-C» — извлекаем строку с текстовым совпадением, включая некоторое количество строк (n), предшествующих и следующих за ней:
-A — строки после вхождения;
-B — строки до вхождения;
-C — строки до и после вхождения.
В итоге команда может выглядеть так:
-R (или -r) — ищем текстовое вхождение во всех файлах внутри директории и ее поддиректорий.
При этом:
--color позволяет отображать вывод в цвете и упрощает чтение кода.
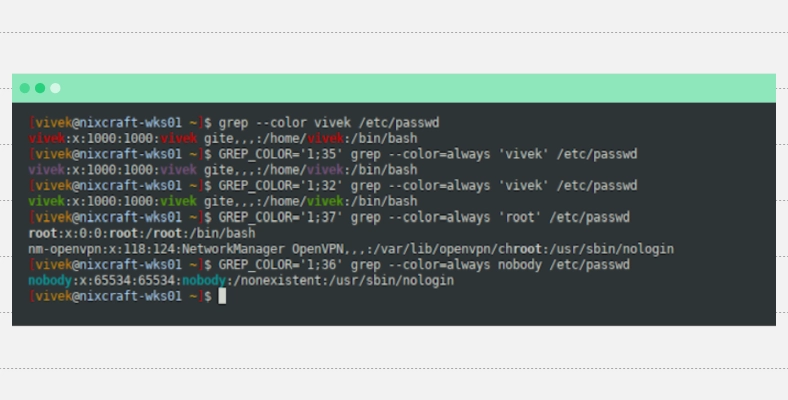 Применение опции --color
Применение опции --color
В дополнение к красному по умолчанию для вывода можно определять цвета с помощью переменной оболочки GREP_COLOR.
Сохранение вывода grep в файл
Допустим, вам необходимо выполнить поиск по ключевому слову cloud и сохранить вывод в файле с именем my-cloud.txt. Тогда вводим такую команду:
Также можно выполнить ограниченный поиск, включив в него строки, которые начинаются с ключевого cloud:
Поиск специальных символов с помощью grep
Если нужно найти определенный символ, можно попросить grep обрабатывать ваш ввод как фиксированную строку с помощью опции -F или команды fgrep.
Например:
Подавление сообщений об ошибках
С помощью grep можно не выводить на экран ошибки о несуществующих или нечитаемых файлах через использование параметра -s:
Например:
Регулярные выражения в grep
Регулярные выражения — инструмент для определения общих шаблонов поиска, расширяющий спектр возможностей обработки текстовой информации. Они представляют собой некую последовательность символов. Например, ^w1, w1|w2, [^ ], foo, bar, [0-9].
Команда grep располагает базовыми и расширенными выражениями:
Базовые (BRE) выражения предоставляют набор символов: ., *, [], [^], ^ и $.
Расширенные (ERE) выражения в дополнение к базовым поддерживают следующие символы: +, ?,{n,m},|.
Основные регулярные выражения:
Параметр | Что означает |
|---|---|
. | Соответствует любому отдельному символу |
? | Предыдущий элемент — необязательный и будет сопоставлен максимум один раз |
* | Предыдущий элемент будет совпадать ноль или более раз |
+ | Предыдущий элемент будет сопоставлен один или несколько раз |
{N} | Предыдущий элемент совпадает ровно N раз |
{N,} | Предыдущий элемент совпадает N или более раз |
{N,M} | Предыдущий элемент совпадает не менее N раз, но не более M раз |
- | Представляет диапазон, если он не является первым или последним в списке, или конечной точкой диапазона в списке |
^ | Соответствует пустой строке в начале строки. Также представляет символы, не входящие в диапазон списка |
$ | Соответствует пустой строке в конце строки |
\b | Соответствует пустой строке на окончании слова |
\B | Соответствует пустой строке, если она не находится на окончании слова |
\< | Найти пустую строку в начале слова |
\> | Найти пустую строку в окончании слова |
Примеры регулярных выражений grep
Чтобы продемонстрировать, как работают регулярные выражения grep, найдем слово с именем cloud в файле /etc/passwd:
Как вывод получим:
Далее найдем слово с именем cloud в любом регистре:
И после этого выполним поиск двух слов clou» или raj в любом регистре:
Теперь найдем слова Linux или UNIX в любом регистре с применением команды egrep:
Важно учесть, что последняя версия egrep покажет предупреждение, что команда устарела и нужно использовать grep -E. Чтобы этого избежать, следует обновить скрипты и команды. Правильный запрос будет выглядеть так:
Как сопоставить отдельные символы
Символ . (точка) соответствует одному элементу. То есть его можно использовать в качестве замены любого другого символа.
Чтобы показать, как это выглядит на практике, возьмем файл demo.txt:
Найдем все имена файлов, которые начинаются с purchase:
После чего выделим все имена файлов, которые начинаются с purchase и заканчиваются на db:
А также, для примера, найдем все имена файлов, которые начинаются с purchase, но заканчиваются на db:
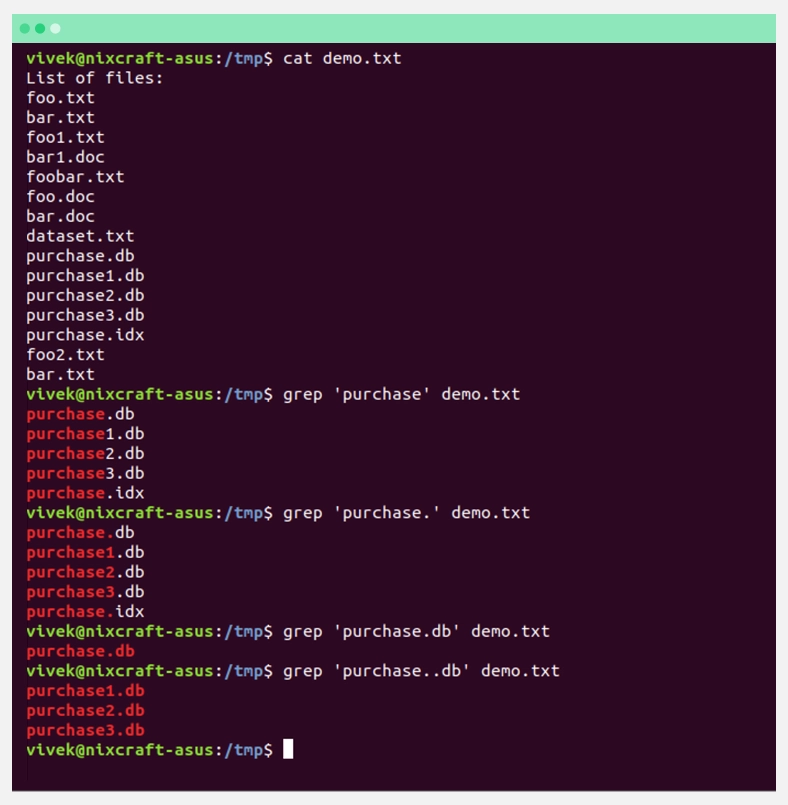 Список файлов с определенным началом имени и окончанием
Список файлов с определенным началом имени и окончаниемКак сопоставить только точку (.)
Точка играет особую роль в регулярных выражениях, так как соответствует любому символу. Однако, если необходимо не заменять, а искать именно фактическую точку, можно воспользоваться опцией экранирования.
Для этого перед . нужно поставить обратную косую черту \:
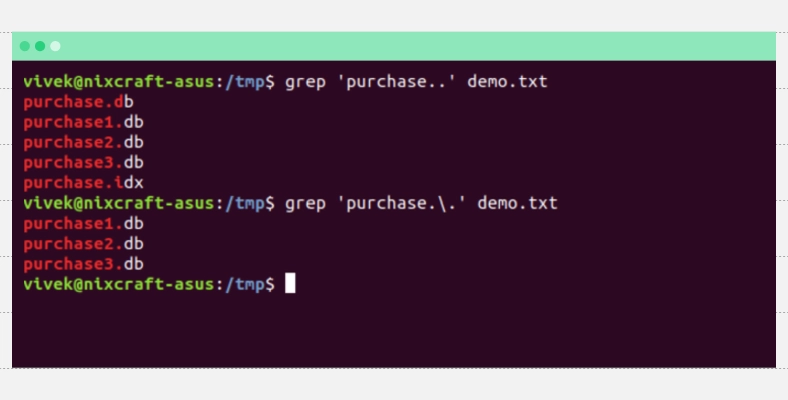 Сопоставление только точки
Сопоставление только точкиКак использовать якоря
Чтобы заставить регулярное выражение сопоставлять только начало или конец строки, можно применять якоря ^ и $. Чтобы отобразить строки, которые начинаются с cloud, нужно ввести:
Примеры выходных данных:
Также можно отобразить только строки, которые начинаются со слова cloud, то есть не выводить cloudgite, cloudg и т.д.:
Как сопоставить набор символов с помощью grep
Так как точка . соответствует любому отдельному символу, с помощью grep можно сопоставлять определенные символы и их диапазоны. Представим, что необходимо сопоставить Vivek и vivek: $ grep '[vV]ivek' filename или $ grep '[vV][iI][Vv][Ee][kK]' filename
Сопоставим цифры и символы верхнего и нижнего регистра. Например, попробуем посчитать слова, такие как vivek1, Vivek2 и так далее, с помощью:
Или сопоставив foo11, foo12, foo22 через:
Также можно использовать не только цифры, но и буквы: $ grep '[A-Za-z]' filename.
Например, отобразим все строки, в которых содержатся символы w или n:
Какие универсальные символы существуют
Помимо стандартных символов, у которых есть конкретные задачи, существуют и универсальные.
Поиск по шаблону с символом -
Найдем все строки, которые соответствуют –test– с использованием опции -e Без нее grep попытается проанализировать –test– как список опций. Например:
$ grep -e '--test--' filename
Операция OR
Если необходимо сопоставить несколько текстовых выражений, можно применить опцию OR. Используем следующий синтаксис:
Операция AND
Используем следующий синтаксис для отображения всех строк, в которых содержатся как word1, так и word2:
Как проверить последовательность
Чтобы проверить, как часто символ должен повторяться в последовательности, используйте следующий синтаксис: {N}, {N,}, {min,max}.
Например:
Сопоставляем символ v два раза:
Следующий пример будет соответствовать как словам co», так и cool:
Этот пример будет соответствовать любой строке из как минимум трех букв c:
Коротко о команде grep в Linux
В комьюнити разработчиков распространено слово «грепать» — то есть искать какое-либо регулярное выражение в большом объеме файлов. Делать это позволяет универсальная утилита grep, которую можно применять для работы с любыми доступными в Cloud.ru Linux-дистрибутивами.
Владение grep помогает искать файл с конкретной строкой в файловой системе или, наоборот, строки в файле, где содержатся определенные символы. А комбинируя все ее функциональные возможности, можно решать самые разные задачи поиска.