Порядок проверки работоспособности системы
Команды для проверки работоспособности системы:
storage stat;
storage top.
Создайте том для тестирования с выбранными параметрами:
$ storage volume make --size 100GB --storage-class erasureVolume 0xbf89676ba3e4fc2e addedЗапустите Fio для созданного тома с плагином sbd.
fio -ioengine=/usr/lib/libfio_sbd.so -name=test -bs=4k -direct=1 -iodepth=128 -rw=write -size=1G -volume=bf89676ba3e4fc2eГде:
--volume bf89676ba3e4fc2e — id тома в hex формате.
Опциональные параметры плагина sbd:
client-id 111 — client id (default: random);
tout 3 — io timeout (default: 3s);
ram — run fio over ram block device (default: 0);
log-level [trace, debug, info, warn, error] — уровень логирования (default: error);
log-to-file — параметр для включения логирования sbd в файл. По умолчанию все логи sbd пишутся в stdout;
log-dir /dir — ддиректория логирования sbd (default: /var/log/storage).
Важно! Данная команда должна быть выполнена без ошибок. Для дальнейших проверок используйте storage stat или storage top.
При включенном log-level уровня debug или подробнее, а также при высокой задержке запросов, в лог сохранятся записи, по которым можно судить о времени выполнения:
DEBUG 2025-03-26 11:24:08,058 [shard 0:main] sds/client/remote_block_device - 0x176fb73dfb685fd1: write [1] 0x4000+0x2000DEBUG 2025-03-26 11:24:08,058 [shard 0:main] sds/client/chunk_server - call [1] [0ae8d6baf7318a65;2] WriteReq f:0x29 {0x29} (0x4000+0x2000) sn: 0 1 frags: [35..] -> cs: 3, timeout: 60000msDEBUG 2025-03-26 11:24:08,059 [shard 0:main] sds/client/remote_block_device - 0x176fb73dfb685fd1: write [1] done in 1122us; lats D:{cs#3:[944,129]}; I:{cs#2:[575,135]; cs#4:[631,107]}DEBUG 2025-03-26 13:43:05,363 [shard 0:main] sds/client/remote_block_device - 0x176fb73dfb685fd1: read_fragments [1] 0x4000+0x2000DEBUG 2025-03-26 13:43:05,363 [shard 0:main] sds/client/chunk_server - call [1] [0a426c4feaa2f9ee;3] ReadReq f:0x1 {0x29} vol 1 (0x4000+0x1000) -> cs: 4, timeout: 60000msDEBUG 2025-03-26 13:43:05,363 [shard 0:main] sds/client/chunk_server - call [1] [0a426c4feaa2f9ee;4] ReadReq f:0x1 {0x29} vol 1 (0x5000+0x1000) -> cs: 2, timeout: 60000msDEBUG 2025-03-26 13:43:05,364 [shard 0:main] sds/client/remote_block_device - 0x176fb73dfb685fd1: sparse_read [1]: [0a426c4feaa2f9ee;3] ReadReq f:0x1 {0x29} vol 1 (0x4000+0x1000), read_request_offset: 0x0, chunk_idx: 0, strip_idx: 0, result: [0: [off: 0x0, size: 0x1000, crc_sz: 0x0]]DEBUG 2025-03-26 13:43:05,364 [shard 0:main] sds/client/remote_block_device - 0x176fb73dfb685fd1: sparse_read [1]: [0a426c4feaa2f9ee;4] ReadReq f:0x1 {0x29} vol 1 (0x5000+0x1000), read_request_offset: 0x1000, chunk_idx: 0, strip_idx: 1, result: [0: [off: 0x0, size: 0x1000, crc_sz: 0x0]]DEBUG 2025-03-26 13:43:05,364 [shard 0:main] sds/client/remote_block_device - 0x176fb73dfb685fd1: sparse_read [1]: issued 2 requests, got 2 fragments, glued to 1DEBUG 2025-03-26 13:43:05,364 [shard 0:main] sds/client/remote_block_device - 0x176fb73dfb685fd1: read [1] done in 1296us; lats D:{cs#2:[766,154]; cs#4:[1113,130]}
Например:
write [1] done in 1122us
Общее время выполнения составило 1122 микросекунд.
lats D:{cs#3:[944,129]}; I:{cs#2:[575,135]; cs#4:[631,107]}
Где:
lats D (direct): — latency чанк-серверов, на которые поступают запросы от пользователя. Мастер чанк-сервера используется для записи, дата чанк-сервера — для чтения. Данные выводятся в следующем порядке:
CS id;
время выполнения на чанк-сервере в микросекундах;
сетевая задержка — RTT, полное время запроса минус время локального выполнения. Если чанк-сервер перегружен запросами, к задержке добавляется время ожидания в RPC очереди.
- I (indirect): — latency чанк-серверов, на которые пересылался запрос.
Предоставляет данные также, как и lats D (direct):.
В примере выше запрос был отправлен на чанк-сервер CS#3. Он переслал его на чанк-сервера CS#2 и CS#4. Локальное выполнение на них заняло 575 и 631 мкс соответственно. Пересылка с CS#3 и обратно заняла 135 и 107 мкс соответственно. На CS#3 локальная фаза заняла 944 мкс, передача данных с клиента и обратно заняла 129 мкс.
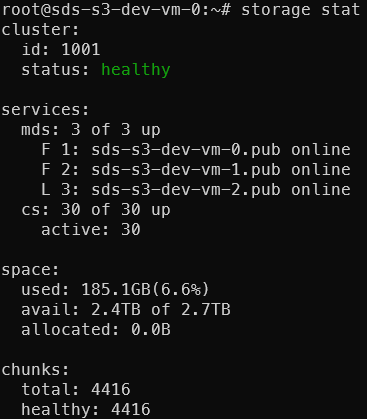
Команда storage stat
Введите команду:
storage stat
Утилита отображает статистику работоспособности кластера. На рисунке ниже представлены показатели:
status (при отображении статуса healthy — система работает без ошибок);
mds (при отображении 3 of 3 up — все лидеры кластера доступны и работоспособны);
cs (при отображении 30 of 30 up, active: 30 — все чанк-сервера доступны и активны).
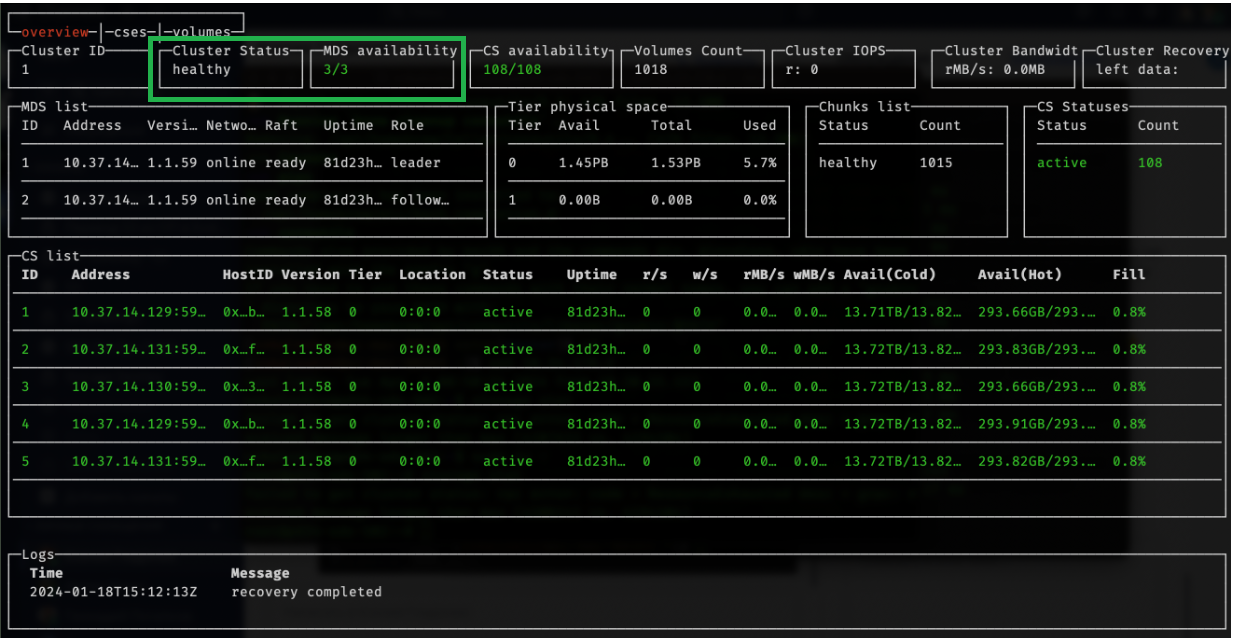
Команда storage top
Введите команду:
storage top
Storage top отображает статистику работоспособности кластера, а также информацию, используемую для обслуживания кластера и его настройки. На рисунке ниже представлены показатели:
Cluster Status (при отображении статуса healthy — система работает без ошибок);
MDS availability (отображает 3/3 — все лидеры кластера доступны и работоспособны).
При изменении статуса healthy на degraded проверьте сеть для репликации SDS.
- Команда storage stat
- Команда storage top