Managed Spark — движок для распределенной обработки больших данных разного типа: структурированных, полуструктурированных, неструктурированных данных.
Managed Spark позволяет:
обрабатывать данные из Object Storage;
обрабатывать данные из внешнего S3;
обрабатывать данные из реляционных и нереляционных баз данных (БД);
обучать ML-модели.
Managed Spark позволяет разворачивать инстансы Spark с необходимой конфигурацией и управлять ими. Также можно создать инстанс с графическим процессором GPU для высоконагруженных систем и требовательных задач. Инстанс разворачивается на кластере Kubernetes и может интегрироваться с другими продуктами через общую клиентскую сеть VPC. Вы можете создать несколько инстансов, например один для тестирования и один для рабочих задач.
Существует несколько вариантов запуска задачи в Managed Spark:
запуск скрипта из S3;
запуск кастомного образа.
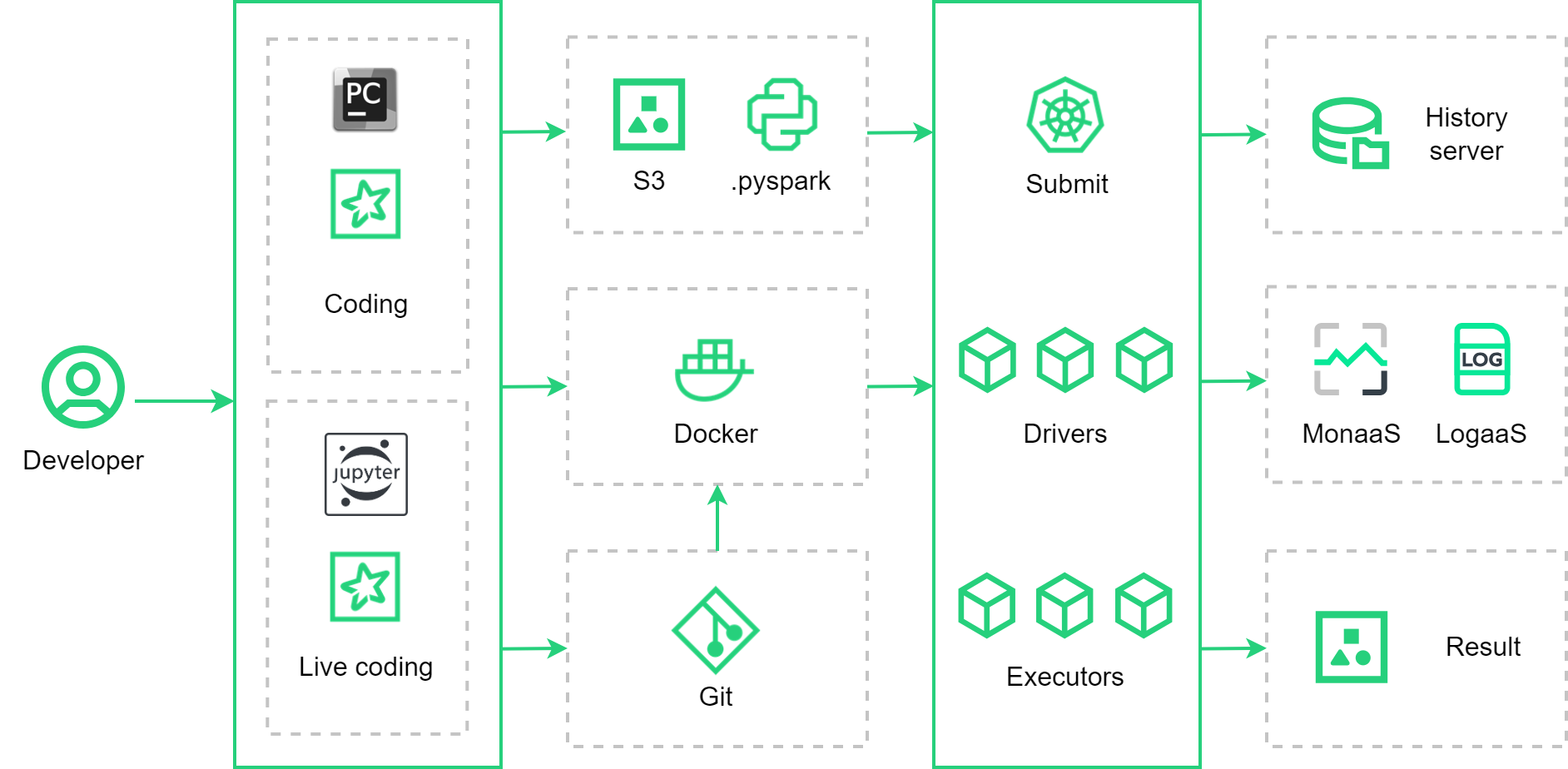
Источники данных
Spark поддерживает большинство БД, файловых систем и файлов. Главное требование — наличие у БД или системы API Spark (Spark SQL), либо протокола JDBC. Подробнее об источниках данных читайте в документации Apache Spark.
Задачи Spark
Managed Spark позволяет запускать задачи Spark и отслеживать ход их выполнения.
Распределение ресурсов для выполнения задач Spark контролируется с помощью механизма планирования Gang Scheduling. Все запущенные задачи выполняются одновременно или остаются в очереди до освобождения необходимого объема ресурсов. Это предотвращает взаимную блокировку (deadlock) ресурсов.
При создании задачи вы можете определить необходимые аргументы и параметры в интерфейсе. Ознакомиться со списком параметров, которые определяются по умолчанию или при заполнении формы создания задачи, можно на странице Параметры задач Spark.
Скрипт задачи Spark может быть написан на одном из языков программирования:
Java
Python
Scala
R
Графический процессор GPU
При создании инстанса можно подключить графический процессор GPU. Он необходим для задач, которые требуют высокую производительность, например:
машинное обучение;
компьютерное зрение;
большие данные.
Доступны следующие модели GPU: