MRS provides Hadoop-based high-performance big data components, such as Spark, HBase, Kafka, and Storm.
This section describes how to use Hadoop to submit a wordcount job through the GUI and a cluster node, respectively. A wordcount job is a classic Hadoop job that counts words in massive amounts of text.
More details steps are as follows:
- Buy an MRS cluster.
- Configure software.
- Configure hardware.
- Set advanced options.
- Confirm the configuration.
- Prepare the Hadoop sample program and data files.
- Upload data to OBS.
- Submit a job on the GUI.
- Submit a job through a cluster node.
- Query job execution results.
Procedure
- Create a cluster.
- Log in to the management console.
- Choose EI Enterprise Intelligence > MapReduce Service . The MRS management console is displayed.
- Click Buy Cluster, the Buy Cluster page is displayed.
- Click the Custom Config tab.
- Configure software.
- Region : Select a region.
- Billing Mode : Select Pay-per-use .
- Cluster Name : Enter mrs_demo or use another name following the naming rules.
- Cluster Type : Select Analysis cluster .
- Cluster Version : Select MRS 3.1.0 .
- Component : Select all components required for an analysis cluster.
- Click Next .
- Configure hardware.
- AZ : Select AZ2 .
- Enterprise Project : Select default .
- VPC and Subnet : Retain their default values or click View VPC and View Subnet to create new ones.
- Subnet : Retain the default value.
- Security Group : Use the default option Auto create .
- EIP : Retain the default option Bind later .
- Cluster Nodes : Retain the default settings. Do not add new Task nodes.
- Click Next .
- Set advanced options.
- Kerberos Authentication : Trun off this function.
- Username : admin is used by default.
- Password and Confirm Password : Set them to the password of the FusionInsight Manager administrator.
- Login Mode : Select Password . Enter a password and confirm the password for user root .
- Hostname Prefix : Retain the default value.
- Select Configure for Set Advanced Options , and set Agency to MRS_ECS_DEFAULT_AGENCY .
- Click Next .
- Confirm the configuration.
- Configure : Confirm the settings configured on the Configure Software , Configure Hardware , and Set Advanced Options pages.
- Enable Secure Communications .
- Click Buy Now. A page is displayed showing that the task has been submitted.
- Click Back to Cluster List . You can view the status of the newly created cluster on the Active Clusters page. Wait for the cluster creation to complete. The initial status of the cluster is Starting . After the cluster is created, the cluster status becomes Running .
- Prepare the Hadoop sample program and data files.
- Prepare the wordcount program.
- Log in to the Master1 node as user root .
- Run the following commands to go to the client installation directory, configure environment variables, and create an HDFS directory, for example, /user/example :
cd /opt/Bigdata/client
source bigdata_env
hdfs dfs -mkdir /user/example
- Run the following commands to upload the /opt/Bigdata/client/HDFS/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1-*.jar file to the /user/example directory: Replace the * with the JAR version you are using.
cd HDFS/hadoop/share/hadoop/mapreduce
hdfs dfs -put hadoop-mapreduce-examples-3.1.1-*.jar /user/example
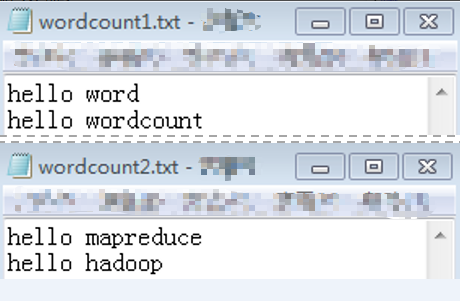
- Prepare data files.
There is no requirement on the format of the data files. Prepare two .txt files. For example, files wordcount1.txt and wordcount2.txt .
Figure 1 Preparing data files
- Prepare the wordcount program.
- Upload files to OBS.
- Log in to the OBS console and choose Parallel File Systems . On the Parallel File Systems page, click Create Parallel File System . On the displayed page, create a file system named mrs-word01 .
- Click the name of the mrs-word01 file system. In the navigation pane on the left, choose Files. On the page that is displayed, click Create Folder to create two folders: program and input .
- Go to the input folder and upload the wordcount1.txt and wordcount2.txt files prepared in 6.
- In the navigation pane of the MRS console, choose . On the Active Clusters page, click the mrs_demo cluster.
- In the cluster list, click a cluster name and click the Files tab on the cluster details page. On the displayed page, click Export Data . In the Export Data from HDFS to OBS dialog box, set the following parameters and click OK :
- HDFS Path : Select the path of the prepared JAR package, that is, /user/example/hadoop-mapreduce-examples-3.1.1-*.jar / .
- OBS Path : Select the path of the program folder, that is, obs://mrs-word01/program . Select the check box for confirming script security and click OK .
- To submit a job on the GUI, go to 8. To submit a job through a cluster node, go to 9.
- Submit a job on the GUI.
- On the cluster information page, click the Jobs tab then Create to create a job.
- In the Create Job dialog box, set the following parameters:
- Type : Choose MapReduce .
- Job Name : Enter wordcount .
- Program Path : Click OBS and select the Hadoop sample program uploaded in 7.
- Parameters : Enter wordcount obs://mrs-word01/input/ obs://mrs-word01/output/ .
obs://mrs-word01/output/ indicates the output path, which is a directory that does not exist.
- Service Parameter : Leave it blank.
- Click OK to submit the job. After a job is submitted, it is in the Accepted state by default. You do not need to manually execute the job.
- Go to the Jobs tab to view the job status and logs. Then go to 10 to view the job execution result.
- Submit a job through a cluster node.
- Log in to the MRS console and click the cluster named mrs_demo to go to its details page.
- Click the Nodes tab. In this tab, click the name of the master1 node to go to the ECS management console.
- Click Remote Login in the upper right corner of the page.
- Enter the username and password of the master node as prompted. The username is root and the password is the root password configured during cluster creation.
- Run the following command to configure environment variables:
cd /opt/Bigdata/client
source bigdata_env
- Run the following command to submit the wordcount job, read data from OBS, and output the execution result to OBS:
hadoop jar HDFS/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1-*.jar wordcount "obs://mrs-word01/input/*" "obs://mrs-word01/output/"
obs://mrs-word01/output/ indicates a path for storing job output files on OBS and needs to be set to a directory that does not exist.
- Query job execution results.
- Log in to OBS console and click the name of the mrs-word01 parallel file system.
- On the page that is displayed, choose Files in the navigation pane on the left. Go to the output path in the mrs-word01 bucket specified during job submission, and view the job output file. You need to download the file to a local computer and open it in .txt format.
- Procedure