A Large Number of Blocks Are Lost in HDFS due to the Time Change Using ntpdate
Symptom
- A user uses ntpdate to change the time for a cluster that is not stopped. After the time is changed, HDFS enters the safe mode and cannot be started.
- After HDFS exits the safe mode and starts, about 1 TB data is lost during the hfck check.
Cause Analysis
- A large number of blocks are lost on the native NameNode page.
Figure 1 Block loss
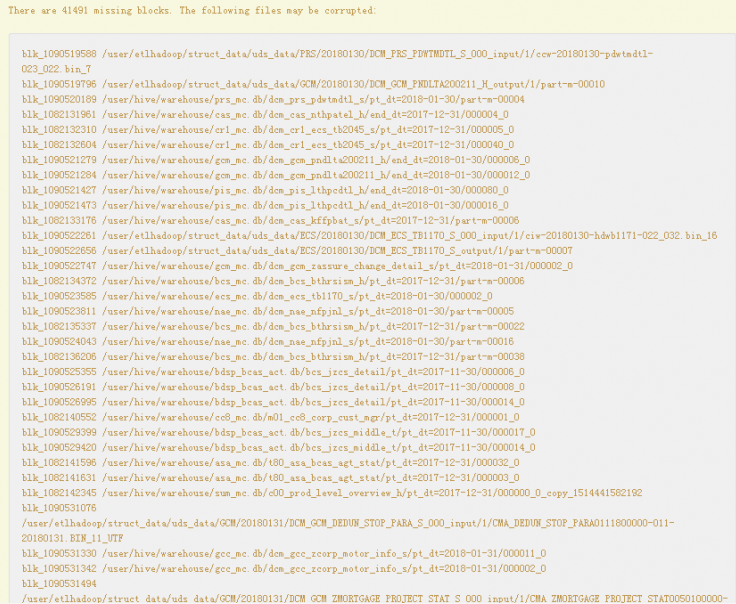
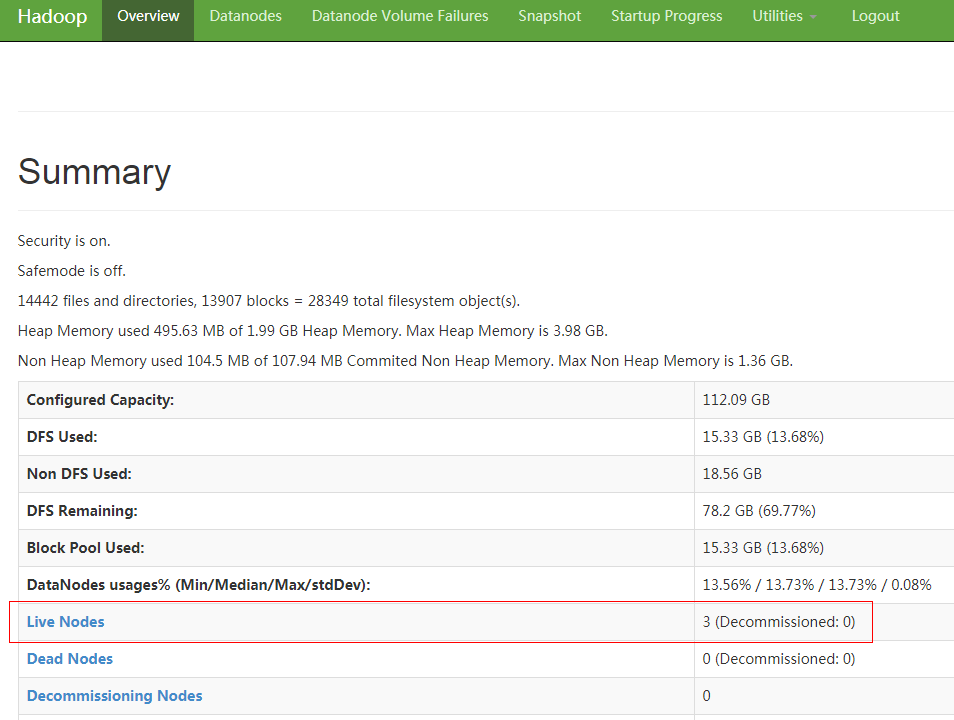
- DataNode information on the native page shows that the number of displayed DataNodes is 10 less than that of actual DataNodes.
Figure 2 Checking the number of DataNodes
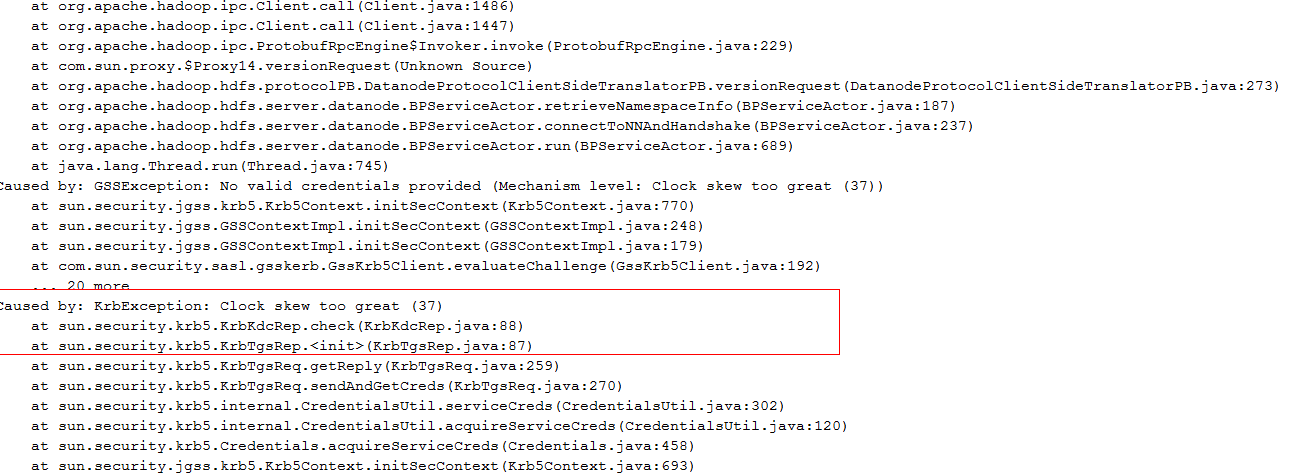
- Check the DataNode run log file /var/log/Bigdata/hdfs/dn/hadoop-omm-datanode-hostname.log. The following error information is displayed:
Major error information: Clock skew too great
Figure 3 DataNode run log error
Solution
- Change the time of the 10 DataNodes that cannot be viewed on the native page.
- On Manager, restart the DataNode instances.
Parent topic: Using HDFS
- Symptom
- Cause Analysis
- Solution