DR Overview
To prevent service unavailability caused by regional faults, DRS provides disaster recovery to ensure service continuity. You can easily implement disaster recovery between on-premises and cloud, without the need to invest a lot in infrastructure in advance.
The disaster recovery architectures, such as two-site three-data-center and two-site four-data center, are supported.
Figure 1 Real-time DR switchover
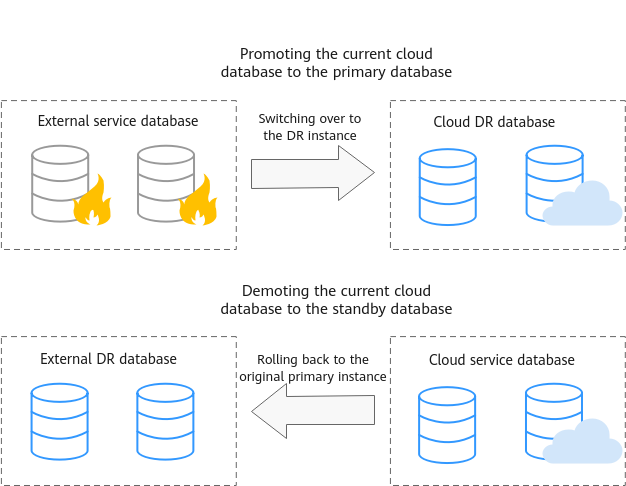
Figure 2 Dual-active DR principles
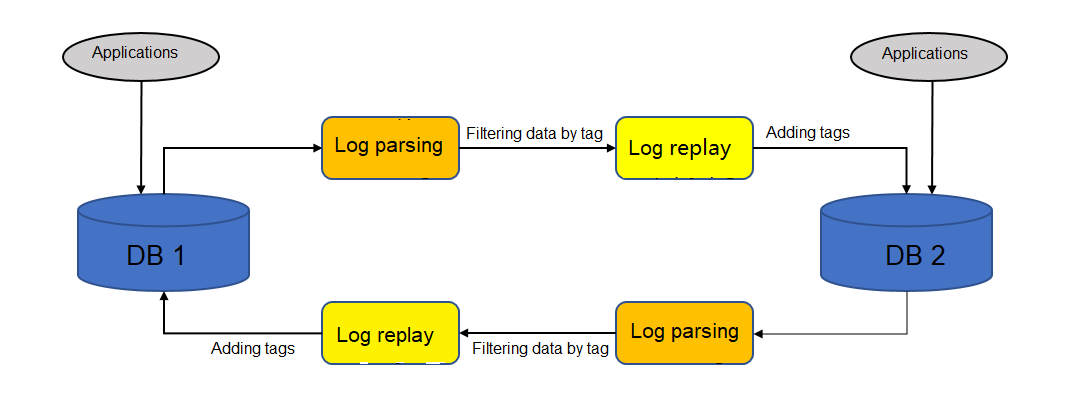
Loopback Prevention (DML)
- When logs are parsed from the source database, the parsed data may contain a certain tag. The data containing the tag is written to the source database through DRS. The data written by applications is not tagged. After the parsing, the data without the tag is filtered out.
- When data is replayed to the destination database, the data to be replayed is marked with a special tag, which is recorded in database logs.
- DRS ensures eventual consistency. The concurrency sequence of DRS is at the row level. That is, operations on the same row are executed based on the source database sequence, not based on the transactions of the source database.
Supported Database Types
The following table lists the database types supported by DRS.
Service Database | DR Database | Documentation |
|---|---|---|
| RDS for MySQL | |
GaussDB(for MySQL) | ||
GaussDB(for MySQL) | GaussDB(for MySQL) | |
| GeminiDB Cassandra |
Basic Principles of Real-Time Disaster Recovery
DRS uses the real-time replication technology to implement disaster recovery for two databases. The underlying technical principles are the same as those of real-time migration. The difference is that real-time DR supports forward synchronization and backward synchronization. In addition, disaster recovery is performed on the instance-level, which means that databases and tables cannot be selected.
- Supported Database Types
- Basic Principles of Real-Time Disaster Recovery