Switching Between Hot and Cold Storage for an OpenSearch Cluster
In an OpenSearch cluster that has cold data nodes, index data can switch between cold and hot storage. This helps optimize storage costs and improve query performance.
Hot/cold storage switchover is about allocating data to different types of data nodes in terms of their performance and costs based on how frequent data is expected to be accessed. Hot data nodes store real-time data that is frequently updated and queried. Typically, they use high-performance hardware (such as SSDs) to ensure fast read/write and retrieval. Cold data nodes store historical data that is seldom accessed. Typically, cold data nodes use lower-cost hardware to store data.
How It Works
Figure 1 How cold/hot storage switchover works
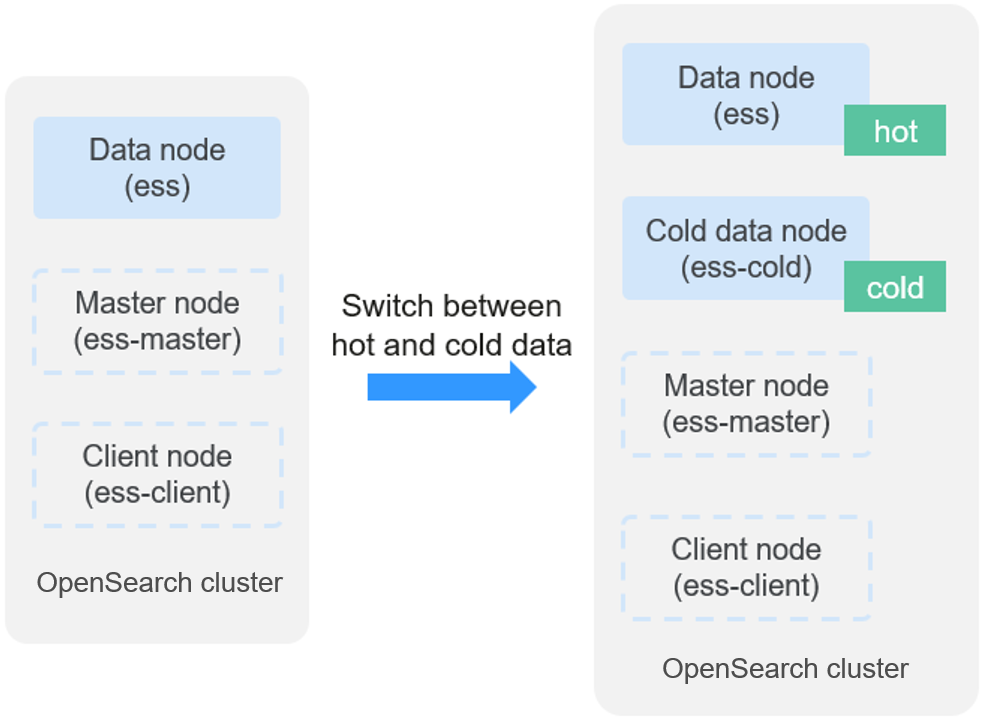
When a cluster is created, cold data nodes are tagged cold for cold storage, whereas regular data nodes are tagged hot for hot storage. Within a cluster, you can configure to have the less frequently accessed data of specified indexes stored on cold data nodes. Compared with regular data nodes, cold data nodes offer lower query performance, but also lower storage costs. Regular data nodes will be tagged hot only when there are cold data nodes.
You can scale cold data nodes by adding or reducing nodes or their storage capacity. For details, see Scaling an OpenSearch Cluster.
Constraints
Only clusters that have cold data nodes support switchover between cold and hot data storage. Cold data nodes can be enabled only when a cluster is created. You cannot enable cold data nodes for an existing cluster. If your cluster does not have cold data nodes but you want to cut storage costs, you can try using storage-compute decoupling. For details, see Configuring Storage-Compute Decoupling for an OpenSearch Cluster.
Switching Over Between Hot and Cold Storage
- Log in to the CSS management console.
- Check whether cold data nodes are enabled in a cluster.
On the Clusters page, select the cluster that you want to enable storage-compute decoupling, click the cluster name to go to the cluster information page. In the Node area, check whether there is information about cold data nodes.
Figure 2 Cold data node information
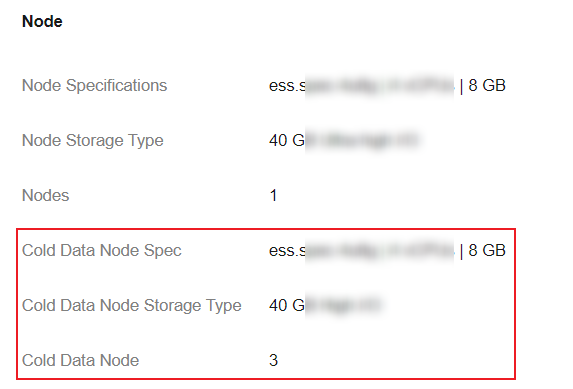
- If there is information about cold data nodes, the cluster has cold data nodes. Go to the next step.
- Otherwise, the cluster does not have cold data nodes, in which case, you cannot switch between cold and hot data storage.
- Click Access Kibana in the Operation column to log in to OpenSearch Dashboards.
- Click Dev Tools in the navigation tree on the left.
- On OpenSearch Dashboards, set an index template to store index data to cold or hot data nodes.
For example, run the following command to set a template to store indexes that start with myindex to cold data nodes:
PUT _template/test{"order": 1,"index_patterns": "myindex*","settings": {"refresh_interval": "30s","number_of_shards": "3","number_of_replicas": "1","routing.allocation.require.box_type": "cold"}}Or you can simply specify cold or hot storage for existing indexes.
For example, run the following command store index myindex to cold data nodes:
PUT myindex/_settings{"index.routing.allocation.require.box_type": "cold"}myindex indicates the index name. You can change cold to hot if you need hot storage.
- When necessary, run the following command to cancel cold or hot storage configuration. After that, index data will be randomly and evenly distributed across cold and hot data nodes.PUT myindex/_settings{"index.routing.allocation.require.box_type": null}
myindex indicates the index name.
- How It Works
- Constraints
- Switching Over Between Hot and Cold Storage