As business expands, and data volumes and access requests grow exponentially, a monolithic architecture where a single cluster handles both write and query requests faces typical challenges like resource contention and overload. To address these challenges, CSS introduces read/write splitting between Elasticsearch clusters.
Elasticsearch read/write splitting works by having leader and follower clusters collaborate together. The feature delivers the following benefits:
- Decoupled read and write loads: The leader cluster ensures data ingestion performance, while the follower clusters deliver scalable, high-concurrency query performance. There is no more resource contention, and peak loads are reduced.
- Flexible scalability: The write and query clusters can be scaled horizontally and independently. Cross-region cluster deployment is supported.
- Data consistency guarantee: Data can be synchronized in real time, with low latency. Incremental synchronization is also supported.
Scenario
How read/write splitting between Elasticsearch clusters works:
- Data writes: Users send write requests, and the leader cluster handles these requests.
- Data synchronization.
The leader synchronizes data changes to the follower through a REST API. Two synchronization methods are supported:
- Exact match: synchronization of a specified index
- Match by wildcard: batch synchronization of indexes matching a wildcard expression
- Query processing: Users send query requests. The follower cluster handles these requests and returns the results.
Figure 1 illustrates how read/write splitting works.
Figure 1 How read/write splitting works
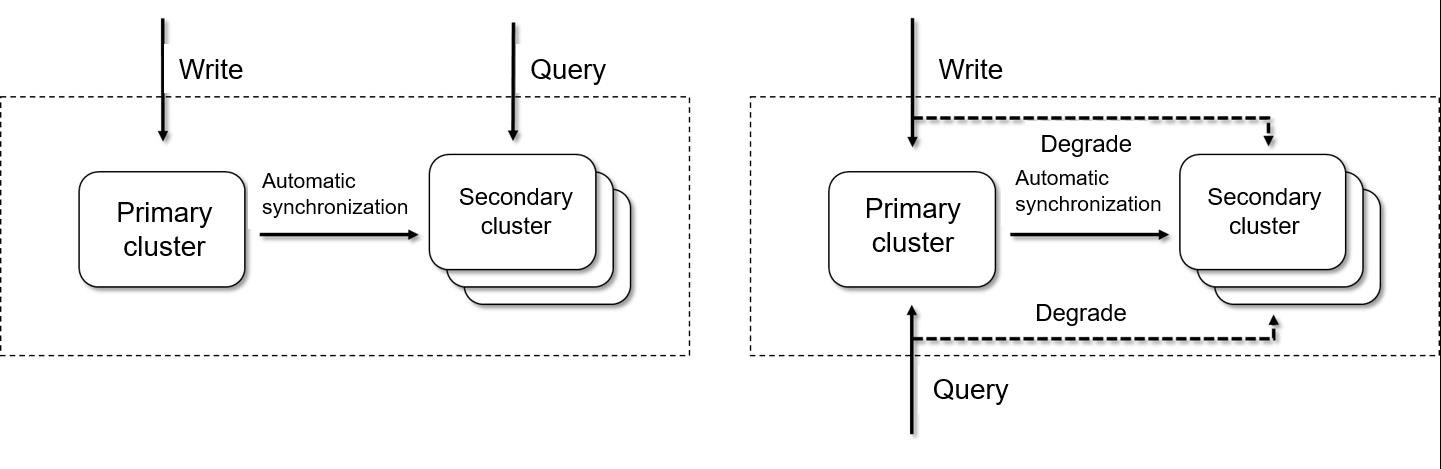
- Read and write split when both clusters are available (left): The leader handles writes, and the follower handles queries.
- Leader-to-follower switchover when the leader fails (right): If the leader becomes unavailable, the follower automatically upgrades to leader to ensure service continuity. For details, see Switching the Roles of the Leader and Follower Clusters.
Constraints
- Only Elasticsearch 7.6.2 and Elasticsearch 7.10.2 clusters support read/write splitting.
- The versions of the leader and follower clusters must be kept consistent, or errors may occur.
Prerequisites
Two clusters of the same version have been created. One functions as the leader cluster, and the other the follower cluster. The follower cluster must be able to access the REST API (default port: 9200) of the leader cluster.
Logging In to Kibana
Log in to Kibana and go to the command execution page. Elasticsearch clusters support multiple access methods. This topic uses Kibana as an example to describe the operation procedures.
- Log in to the CSS management console.
- In the navigation pane on the left, choose Clusters > Elasticsearch.
- In the cluster list, find the target cluster, and click Kibana in the Operation column to log in to the Kibana console.
- In the left navigation pane, choose Dev Tools.
The left part of the console is the command input box, and the triangle icon in its upper-right corner is the execution button. The right part shows the execution result.
Connecting the Leader and Follower Clusters
- Run the following command to configure information about the leader cluster in the follower cluster:PUT /_cluster/settings{"persistent" : {"cluster" : {"remote.rest" : {"leader1" : {"seeds" : ["http://10.0.0.1:9200","http://10.0.0.2:9200","http://10.0.0.3:9200"] ,"username": "elastic","password": "*****"}}}}}
Table 1 Request body parameters Parameter
Description
leader1
Name of the leader cluster configuration task, which is user-defined and will be used for configuring read/write splitting later.
seeds
Address for accessing the leader cluster. When HTTPS is enabled for the cluster, the URL schema must use HTTPS.
username
Username of the leader cluster. This parameter is required only when security mode is enabled for the leader cluster.
password
Password of the leader cluster. This parameter is required only when security mode is enabled for the leader cluster.
Example response:
{"acknowledged" : true, //Whether the operation is successful"persistent" : {"cluster" : {"remote" : {"rest" : {"leader1" : {"seeds" : ["http://10.0.0.1:9200","http://10.0.0.2:9200","http://10.0.0.3:9200"] ,"username": "elastic","password": "*****"}}}}},"transient" : { }} - After the configuration is complete, run the following command in the follower cluster to check the connection between the follower and leader clusters:GET _remote/rest/info
Example response:
{"leader1" : {"connected" : true //The two clusters are connected.}}
Index Synchronization
There are two ways to synchronize indexes: specified index synchronization and matching index synchronization.
During synchronization, indexes in the follower cluster become read-only. The synchronization is performed periodically. The default synchronization interval is 30 seconds. For how to change it, see Changing the Synchronization Interval.
Synchronizing Specified Indexes
- Run the following command in the follower cluster to synchronize a single index from the leader cluster to the follower cluster without modifying index settings:PUT start_remote_sync{"remote_cluster": "leader1","remote_index": "data1_leader","local_index": "data1_follower"}
- Run the following command in the follower cluster to synchronize a single index from the leader cluster to the follower cluster while modifying some of the index settings—enabling synchronization of index settings:PUT start_remote_sync{"remote_cluster": "leader1","remote_index": "data1_leader","local_index": "data1_follower","settings": {"number_of_replicas": 4},"settings_sync_enable": true,"settings_sync_patterns": ["*"],"settings_sync_exclude_patterns": ["index.routing.allocation.*"],"alias_sync_enable": true,"state_sync_enable": true}Note
The following index configuration items cannot be modified: number_of_shards, version.created, uuid, creation_date, and soft_deletes.enabled.
Parameter | Description |
|---|---|
remote_cluster | Name of the leader cluster configuration task, which was set in Connecting the Leader and Follower Clusters. leader1 was set in our example. |
remote_index | Name of the index to be synchronized in the leader cluster |
local_index | Index name in the follower cluster |
settings | Index settings to be synchronized |
settings_sync_enable | Whether to enable synchronization of index settings in the leader cluster. The default value is false. |
settings_sync_patterns | Prefix of leader cluster index settings to be synchronized. The default value is *. This parameter takes effect when settings_sync_enable is set to true. The index settings configured in settings will not be synchronized. |
settings_sync_exclude_patterns | Prefix of leader cluster index settings not to be synchronized. The default value is empty. This parameter is valid only when settings_sync_enable is set to true. |
alias_sync_enable | Whether to enable index alias synchronization in the leader cluster. The default value is false. |
state_sync_enable | Whether to enable index status synchronization in the leader cluster. The default value is false. |
Matching Index Synchronization
- Run the following command in the follower cluster to create a pattern-matching index synchronization policy, which synchronizes matched indexes from the leader cluster to the follower cluster:PUT auto_sync/pattern/${PATTERN}{"remote_cluster": "leader1","remote_index_patterns": "log*","local_index_pattern": "{{remote_index}}-sync","apply_exist_index": true}
- Run the following command in the follower cluster to create a pattern-matching index synchronization policy, which synchronizes matched indexes from the leader cluster to the follower cluster, with some of the index settings modified—enabling synchronization of index settings:PUT auto_sync/pattern/${PATTERN}{"remote_cluster": "leader1","remote_index_patterns": "log*","local_index_pattern": "{{remote_index}}-sync","apply_exist_index": true,"settings": {"number_of_replicas": 4},"settings_sync_enable": true,"settings_sync_patterns": ["*"],"settings_sync_exclude_patterns": ["index.routing.allocation.*"],"alias_sync_enable": true,"state_sync_enable": true}Note
The following index configuration items cannot be modified: number_of_shards, version.created, uuid, creation_date, and soft_deletes.enabled.
Parameter | Description |
|---|---|
PATTERN | Name of the pattern for index matching. |
remote_cluster | Name of the leader cluster configuration task, which was set in Connecting the Leader and Follower Clusters. In our example, leader1 is used. |
remote_index_patterns | Pattern for matching indexes to be synchronized in the leader cluster. The wildcard (*) is supported. |
local_index_pattern | Index pattern in the follower cluster. The index template can be replaced. For example, if this parameter is set to {{remote_index}}-sync, the index log1 changes to log1-sync after synchronization. If leader/follower switchover is likely to happen, set this parameter to {{remote_index}} to ensure that the leader and follower clusters use identical index names. |
apply_exist_index | Whether to synchronize existing indexes in the leader cluster. The default value is true. |
settings | Index settings to be synchronized |
settings_sync_enable | Whether to enable synchronization of index settings in the leader cluster. The default value is false. |
settings_sync_patterns | Prefix of leader cluster index settings to be synchronized. The default value is *. This parameter takes effect when settings_sync_enable is set to true. The index settings configured in settings will not be synchronized. |
settings_sync_exclude_patterns | Prefix of leader cluster index settings not to be synchronized. The default value is empty. This parameter is valid only when settings_sync_enable is set to true. |
alias_sync_enable | Whether to enable index alias synchronization in the leader cluster. The default value is false. |
state_sync_enable | Whether to enable index status synchronization in the leader cluster. The default value is false. |
Stopping Index Synchronization
Run the following command in the follower cluster to stop synchronization tasks for specified indexes. Subsequent changes to the indexes in the leader cluster will not be synchronized to the follower cluster. The read-only state of the indexes in the follower cluster will be cancelled, so that new data can be written into them.
PUT log*/stop_remote_sync
In this command, log* indicates the index name. You can specify multiple index names (separated by commas) or use a wildcard. In this example, synchronization tasks for all indexes that start with log are stopped.
Querying and Deleting Created Patterns
- Run the following command in the follower cluster to query created patterns:
- Query the list of patterns.GET auto_sync/pattern
- Query a specified pattern by name.GET auto_sync/pattern/{PATTERN}
The following is an example of the response:
{"patterns" : [{"name" : "pattern1","pattern" : {"remote_cluster" : "leader","remote_index_patterns" : ["log*"],"local_index_pattern" : "{{remote_index}}-sync","settings" : { }}}]} - Query the list of patterns.
- Run the following command in the follower cluster to delete a specified pattern by name:DELETE auto_sync/pattern/{PATTERN}
Enabling Forcible Synchronization
By default, the plug-in determines whether to synchronize metadata based on whether the number of documents in the index of the leader cluster changes. If the leader cluster only updates documents and the number of documents remains unchanged, the plug-in does not synchronize the updates to the follower cluster. The configuration can be modified. After forcible synchronization is enabled, the index metadata of the leader cluster is forcibly synchronized to the follower cluster in each synchronization cycle.
The following is an example of enabling forcible synchronization:
PUT _cluster/settings{"persistent": {"remote_sync.force_synchronize": true}}
Changing the Synchronization Interval
The default synchronization interval between the leader and follower clusters is 30 seconds and can be changed.
The example request below changes the synchronization interval to 2 seconds:
PUT {index_name}/_settings{"index.remote_sync.sync_interval": "2s"}
Changing the Synchronization Speed
You can change the data synchronization speed between the leader and follower clusters by configuring cluster-level settings.
The following is an example request: set the block size to 2 MB, the number of blocks to 20, and the maximum synchronization traffic to 100 MB per second.
PUT _cluster/settings{"persistent": {"remote_sync.chunk_size": "2MB","remote_sync.max_concurrent_file_chunks": 20,"remote_sync.max_bytes_per_sec": "100MB"}}
Parameter | Description |
|---|---|
remote_sync.chunk_size | Block size for index synchronization. Default value: 1 MB Format: a string of characters |
remote_sync.max_concurrent_file_chunks | Number of blocks for concurrent index synchronization. Default value: 10 Format: a number |
remote_sync.max_bytes_per_sec | Maximum data synchronization traffic per second. Default value: 40 MB Format: a string of characters |
Querying Index Synchronization Status
Obtain the auto synchronization status of a specified index.
An example request is as follows:
GET {index_name}/sync_stats
The following is an example of the response:
{"indices" : {"data1_follower" : {"shards" : {"0" : [{"primary" : false, // Whether it is a primary shard"total_synced_times" : 27, // Total synchronization times"total_empty_times" : 25, // Total number of times when no data is synchronized between the leader and follower clusters because they have identical shards and data"total_synced_files" : 4, // Number of synchronized files"total_synced_bytes" : 3580, // Total size of synchronized files"total_paused_nanos" : 0, //Duration of synchronization pauses due to traffic throttling"total_paused_times" : 0, //Number of synchronization pauses due to traffic throttling"current" : {"files_count" : 0, //Number of files that are being synchronized"finished_files_count" : 0, //Number of files that have been synchronized"bytes" : 0, //Size of files that are being synchronized"finished_bytes" : 0 //Size of files that have been synchronized}},{"primary" : true, // Whether it is a primary shard"total_synced_times" : 28, // Total synchronization times"total_empty_times" : 26, // Total number of times when no data is synchronized between the leader and follower clusters because they have identical shards and data"total_synced_files": 20, // Number of synchronized files"total_synced_bytes": 17547, // Total size of synchronized files"total_paused_nanos" : 0, //Duration of synchronization pauses due to traffic throttling"total_paused_times" : 0, //Number of synchronization pauses due to traffic throttling"current" : {"files_count" : 0, //Number of files that are being synchronized"finished_files_count" : 0, //Number of files that have been synchronized"bytes" : 0, //Size of files that are being synchronized"finished_bytes" : 0 //Size of files that have been synchronized}}]}}}}
Switching the Roles of the Leader and Follower Clusters
When the leader cluster becomes faulty, perform a leader/follower switchover to have the follower cluster take over services. The steps are as follows:
Leader/follower switchover won't work unless the leader and follower clusters use identical index names.
- Determine the index synchronization method between the leader and follower clusters. Check whether pattern-matching index synchronization policies have been configured in the follower cluster. For the command to use, see Querying and Deleting Created Patterns.
- If there are no such policies, synchronization is performed for specified indexes between the leader and follower clusters. In this case, go to 3.
- If there are such policies, index synchronization between the leader and follower clusters is based on index patterns. In this case, go to 2.
- Delete pattern-matching index synchronization policies in the follower cluster. For the command to use, see Querying and Deleting Created Patterns.
- Perform Stopping Index Synchronization in the follower cluster. Then redirect read and write traffic to it. If the leader and follower clusters synchronize indexes based on index patterns, use a wildcard to match indexes when running the command that stops index synchronization.
- After the leader cluster recovers, configure information about the follower cluster in the leader cluster, and connect the leader and follower clusters again. For details, see Connecting the Leader and Follower Clusters.
- Under the leader cluster, perform Index Synchronization to synchronize data from the follower cluster to the leader cluster, and then perform a leader/follower switchover to switch back.