По мере расширения бизнеса и экспоненциального роста объёма данных и количества запросов, монолитная архитектура, в которой один кластер обслуживает как запросы на запись, так и запросы на чтение, сталкивается с типичными проблемами, такими как конкуренция за ресурсы и перегрузка. Чтобы решить эти проблемы, CSS вводит read/write splitting между кластерами Elasticsearch.
Работа Elasticsearch read/write splitting осуществляется совместной работой кластеров‑лидера и кластера‑потомка. Функция предоставляет следующие преимущества:
- Разделённые нагрузки чтения и записи: кластер‑лидер обеспечивает производительность ввода данных, тогда как кластеры‑потомки предоставляют масштабируемую, высококонкурентную производительность запросов. Конкуренция за ресурсы исчезает, а пиковые нагрузки снижаются.
- Гибкая масштабируемость: кластеры записи и запросов могут масштабироваться горизонтально и независимо. Поддерживается развертывание кластеров в разных регионах.
- Гарантия согласованности данных: данные могут синхронизироваться в реальном времени с низкой задержкой. Также поддерживается инкрементальная синхронизация.
Сценарий
Как работает read/write splitting между кластерами Elasticsearch:
- Запись данных: Пользователи отправляют запросы на запись, и ведущий кластер обрабатывает эти запросы.
- Синхронизация данных.
Ведущий синхронтизирует изменения данных с репликой через REST API. Поддерживаются два метода синхронизации:
- Exact match: синхронизация указанного индекса
- Match by wildcard: пакетная синхронизация индексов, соответствующих выражению с подстановочным знаком
- Query processing: Пользователи отправляют запросы. Кластер‑реплика обрабатывает эти запросы и возвращает результаты.
Рис. 1 иллюстрирует, как работает разбиение чтения/записи.
Рис. 1 Как работает разбиение чтения/записи
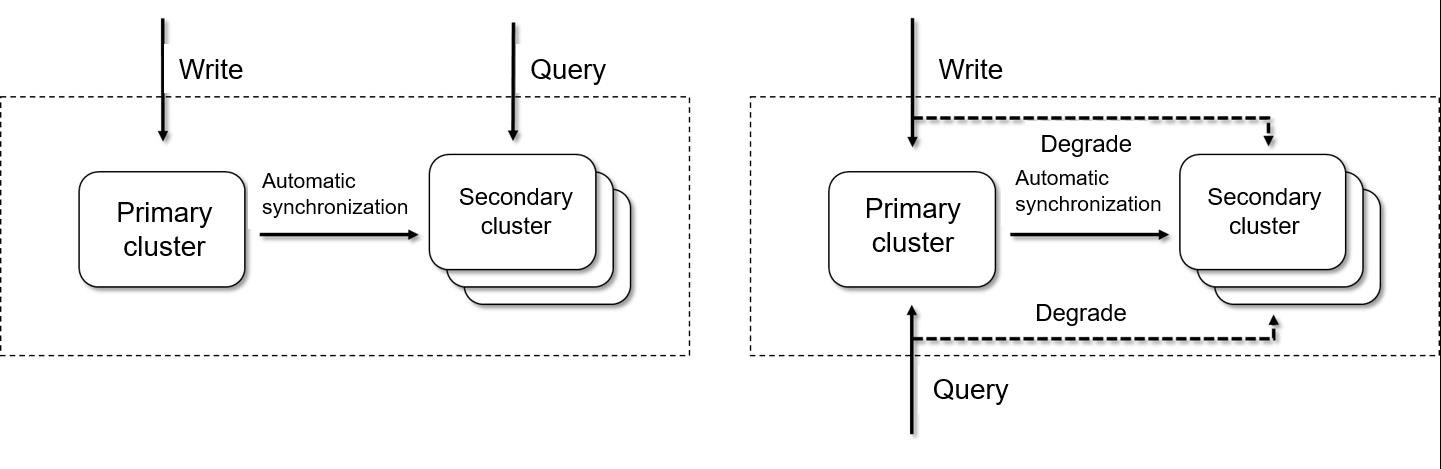
- Разделение чтения и записи, когда оба кластера доступны (слева): Ведущий обрабатывает записи, а реплика обрабатывает запросы.
- Переключение с ведущего на реплику при отказе ведущего (справа): Если ведущий становится недоступен, реплика автоматически повышается до ведущего, чтобы обеспечить непрерывность сервиса. Для подробностей см. Переключение ролей лидирующего и ведомого кластеров.
Ограничения
- Только кластеры Elasticsearch 7.6.2 и Elasticsearch 7.10.2 поддерживают разделение чтения/записи.
- Версии лидирующего и ведомого кластеров должны быть согласованы, иначе могут возникнуть ошибки.
Предварительные требования
Созданы два кластера одной версии. Один функционирует как лидирующий кластер, а другой — как ведомый кластер. Ведомый кластер должен иметь доступ к REST API (порт по умолчанию: 9200) лидирующего кластера.
Вход в Kibana
Войдите в Kibana и перейдите к странице выполнения команд. Кластеры Elasticsearch поддерживают несколько методов доступа. В данном материале в качестве примера используется Kibana.
- Войдите в консоль управления CSS.
- В левой навигационной панели выберите Кластеры > Elasticsearch.
- В списке кластеров найдите целевой кластер и щелкните Kibana в Операция столбец для входа в консоль Kibana.
- В левой навигационной панели выберите Dev Tools.
Левая часть консоли — это поле ввода команды, а треугольный значок в её правом верхнем углу — кнопка выполнения. Правая часть отображает результат выполнения.
Подключение Leader и Follower кластеров
- Выполните следующую команду, чтобы настроить информацию о leader кластере в follower кластере:PUT /_cluster/settings{"persistent" : {"cluster" : {"remote.rest" : {"leader1" : {"seeds" : ["http://10.0.0.1:9200","http://10.0.0.2:9200","http://10.0.0.3:9200"] ,"username": "elastic","password": "*****"}}}}}
Таблица 1 Параметры тела запроса Параметр
Описание
leader1
Имя задачи конфигурации лидирующего кластера, задаваемой пользователем и которое будет использоваться для настройки разделения чтения/записи позже.
посевы
Адрес для доступа к лидирующему кластеру. Когда для кластера включён HTTPS, схема URL должна использовать HTTPS.
имя пользователя
Имя пользователя лидирующего кластера. Этот параметр обязателен только когда для лидирующего кластера включён режим безопасности.
пароль
Пароль лидирующего кластера. Этот параметр обязателен только когда для лидирующего кластера включён режим безопасности.
Example response:
{"acknowledged" : true, //Whether the operation is successful"persistent" : {"cluster" : {"remote" : {"rest" : {"leader1" : {"seeds" : ["http://10.0.0.1:9200","http://10.0.0.2:9200","http://10.0.0.3:9200"] ,"username": "elastic","password": "*****"}}}}},"transient" : { }} - После завершения конфигурации выполните следующую команду в кластере‑подписчике, чтобы проверить соединение между кластерами‑подписчиками и лидирующими кластерами:GET _remote/rest/info
Example response:
{"leader1" : {"connected" : true //The two clusters are connected.}}
Index Synchronization
Существует два способа синхронизации индексов: указанная синхронизация индексов и синхронизация по совпадению индексов.
Во время синхронизации индексы в кластере‑подписчике становятся только для чтения. Синхронизация выполняется периодически. Интервал синхронизации по умолчанию составляет 30 секунд. Как изменить его, см. Изменение интервала синхронизации.
Синхронизация указанных индексов
- Выполните следующую команду в кластере‑подписчике, чтобы синхронизировать отдельный индекс из кластера‑лидера в кластер‑подписчик без изменения настроек индекса:PUT start_remote_sync{"remote_cluster": "leader1","remote_index": "data1_leader","local_index": "data1_follower"}
- Выполните следующую команду в кластере‑подписчике, чтобы синхронизировать отдельный индекс из кластера‑лидера в кластер‑подписчик, изменяя некоторые настройки индекса—включая синхронизацию настроек индекса:PUT start_remote_sync{"remote_cluster": "leader1","remote_index": "data1_leader","local_index": "data1_follower","settings": {"number_of_replicas": 4},"settings_sync_enable": true,"settings_sync_patterns": ["*"],"settings_sync_exclude_patterns": ["index.routing.allocation.*"],"alias_sync_enable": true,"state_sync_enable": true}Note
Следующие параметры конфигурации индекса нельзя изменять: number_of_shards, version.created, uuid, creation_date, и soft_deletes.enabled.
Параметр | Описание |
|---|---|
remote_cluster | Имя задачи настройки конфигурации лидирующего кластера, которое было задано в Подключение лидирующего и последующего кластеров. leader1 было задано в нашем примере. |
remote_index | Имя индекса, который будет синхронизирован в лидирующем кластере |
local_index | Имя индекса в последующем кластере |
settings | Настройки индекса для синхронизации |
settings_sync_enable | Следует ли включить синхронизацию настроек индекса в лидирующем кластере. Значение по умолчанию false. |
settings_sync_patterns | Префикс настроек индекса лидирующего кластера, которые следует синхронизировать. Значение по умолчанию *. Этот параметр применяется, когда settings_sync_enable установлен в true. Настройки индекса, сконфигурированные в settings не будут синхронизированы. |
settings_sync_exclude_patterns | Префикс настроек индекса лидирующего кластера, которые не следует синхронизировать. Значение по умолчанию пустое. Этот параметр действителен только когда settings_sync_enable установлен в true. |
alias_sync_enable | Whether to enable index alias synchronization in the leader cluster. The default value is false. |
state_sync_enable | Whether to enable index status synchronization in the leader cluster. The default value is false. |
Matching Index Synchronization
- Run the following command in the follower cluster to create a pattern-matching index synchronization policy, which synchronizes matched indexes from the leader cluster to the follower cluster:PUT auto_sync/pattern/${PATTERN}{"remote_cluster": "leader1","remote_index_patterns": "log*","local_index_pattern": "{{remote_index}}-sync","apply_exist_index": true}
- Run the following command in the follower cluster to create a pattern-matching index synchronization policy, which synchronizes matched indexes from the leader cluster to the follower cluster, with some of the index settings modified—enabling synchronization of index settings:PUT auto_sync/pattern/${PATTERN}{"remote_cluster": "leader1","remote_index_patterns": "log*","local_index_pattern": "{{remote_index}}-sync","apply_exist_index": true,"settings": {"number_of_replicas": 4},"settings_sync_enable": true,"settings_sync_patterns": ["*"],"settings_sync_exclude_patterns": ["index.routing.allocation.*"],"alias_sync_enable": true,"state_sync_enable": true}Note
The following index configuration items cannot be modified: number_of_shards, version.created, uuid, creation_date, и soft_deletes.enabled.
Параметр | Описание |
|---|---|
PATTERN | Имя шаблона для сопоставления индекса. |
remote_cluster | Имя задачи конфигурации лидирующего кластера, которое было установлено в Подключение лидирующего и ведомого кластеров. В нашем примере, leader1 используется. |
remote_index_patterns | Шаблон для сопоставления индексов, которые будут синхронизированы в лидирующем кластере. Поддерживается подстановочный знак (*) |
local_index_pattern | Шаблон индекса в кластере‑подписчике. Шаблон индекса может быть заменён. Например, если этот параметр установлен в {{remote_index}}-sync, индекс log1 изменения в log1-sync после синхронизации. Если переключение лидера/подписчика вероятно, установите этот параметр в {{remote_index}} чтобы гарантировать, что кластеры лидера и подписчика используют одинаковые имена индексов. |
apply_exist_index | Нужно ли синхронизировать существующие индексы в лидирующем кластере. Значение по умолчанию true. |
настройки | Настройки индекса для синхронизации |
settings_sync_enable | Необходимо ли включать синхронизацию настроек индекса в лидирующем кластере. Значение по умолчанию false. |
settings_sync_patterns | Префикс настроек индекса лидирующего кластера для синхронизации. Значение по умолчанию *. Этот параметр действует, когда settings_sync_enable установлен в true. Настройки индекса, сконфигурированные в settings не будут синхронизированы. |
settings_sync_exclude_patterns | Префикс настроек индекса лидирующего кластера, которые не следует синхронзировать. Значение по умолчанию — пусто. Этот параметр действует только когда settings_sync_enable установлен в true. |
alias_sync_enable | Включать синхронизацию alias индекса в ведущем кластере. Значение по умолчанию false. |
state_sync_enable | Включать синхронизацию статуса индекса в ведущем кластере. Значение по умолчанию false. |
Stopping Index Synchronization
Выполните следующую команду в кластере‑подписчике, чтобы остановить задачи синхронизации для указанных индексов. Последующие изменения индексов в ведущем кластере не будут синхронизированы в кластер‑подписчик. Состояние только‑для‑чтения индексов в кластере‑подписчике будет отменено, чтобы в них можно было записывать новые данные.
PUT log*/stop_remote_sync
В этой команде, log* указывает имя индекса. Вы можете указать несколько имен индексов (разделённых запятыми) или использовать подстановочный символ. В данном примере задачи синхронизации для всех индексов, начинающихся с лог остановлены.
Querying and Deleting Created Patterns
- Выполните следующую команду в кластере‑подписчике, чтобы запросить созданные шаблоны:
- Запросите список шаблонов.GET auto_sync/pattern
- Запросите указанный шаблон по имени.GET auto_sync/pattern/{PATTERN}
Ниже приведён пример ответа:
{"patterns" : [{"name" : "pattern1","pattern" : {"remote_cluster" : "leader","remote_index_patterns" : ["log*"],"local_index_pattern" : "{{remote_index}}-sync","settings" : { }}}]} - Запросите список шаблонов.
- Выполните следующую команду в кластере‑подписчике, чтобы удалить указанный шаблон по имени:DELETE auto_sync/pattern/{PATTERN}
Enabling Forcible Synchronization
По умолчанию Плагин определяет, следует ли синхронизировать метаданные, исходя из того, изменилось ли количество документов в индексе ведущего кластера. Если ведущий кластер только обновляет документы и количество документов остаётся неизменным, Плагин не синхронит обновления с подчинённым кластером. Конфигурацию можно изменить. После включения принудительной синхронизации метаданные индекса ведущего кластера принудительно синхронятся с подчинённым кластером в каждом цикле синхронизации.
Ниже приведён пример включения принудительной синхронизации:
PUT _cluster/settings{"persistent": {"remote_sync.force_synchronize": true}}
Изменение интервала синхронизации
Интервал синхронизации между ведущим и подчинённым кластерами по умолчанию составляет 30 секунд и может быть изменён.
Пример запроса ниже изменяет интервал синхронизации до 2 секунд:
PUT {index_name}/_settings{"index.remote_sync.sync_interval": "2s"}
Изменение скорости синхронизации
Вы можете изменить скорость синхронизации данных между ведущим и подчинённым кластерами, настроив параметры на уровне кластера.
Ниже приведён пример запроса: установить размер блока — 2 МБ, количество блоков — 20 и максимальный объём синхронизационного трафика — 100 МБ/сек.
PUT _cluster/settings{"persistent": {"remote_sync.chunk_size": "2MB","remote_sync.max_concurrent_file_chunks": 20,"remote_sync.max_bytes_per_sec": "100MB"}}
Параметр | Описание |
|---|---|
remote_sync.chunk_size | Размер блока для синхронизации индекса. Значение по умолчанию: 1 MB Формат: строка символов |
remote_sync.max_concurrent_file_chunks | Количество блоков для параллельной синхронизации индекса. Значение по умолчанию: 10 Формат: число |
remote_sync.max_bytes_per_sec | Максимальный трафик синхронизации данных в секунду. Значение по умолчанию: 40 MB Формат: строка символов |
Запрос статуса синхронизации индекса
Получить статус автоматической синхронизации указанного индекса.
Пример запроса выглядит следующим образом:
GET {index_name}/sync_stats
Ниже пример ответа:
{"indices" : {"data1_follower" : {"shards" : {"0" : [{"primary" : false, // Whether it is a primary shard"total_synced_times" : 27, // Total synchronization times"total_empty_times" : 25, // Total number of times when no data is synchronized between the leader and follower clusters because they have identical shards and data"total_synced_files" : 4, // Number of synchronized files"total_synced_bytes" : 3580, // Total size of synchronized files"total_paused_nanos" : 0, //Duration of synchronization pauses due to traffic throttling"total_paused_times" : 0, //Number of synchronization pauses due to traffic throttling"current" : {"files_count" : 0, //Number of files that are being synchronized"finished_files_count" : 0, //Number of files that have been synchronized"bytes" : 0, //Size of files that are being synchronized"finished_bytes" : 0 //Size of files that have been synchronized}},{"primary" : true, // Whether it is a primary shard"total_synced_times" : 28, // Total synchronization times"total_empty_times" : 26, // Total number of times when no data is synchronized between the leader and follower clusters because they have identical shards and data"total_synced_files": 20, // Number of synchronized files"total_synced_bytes": 17547, // Total size of synchronized files"total_paused_nanos" : 0, //Duration of synchronization pauses due to traffic throttling"total_paused_times" : 0, //Number of synchronization pauses due to traffic throttling"current" : {"files_count" : 0, //Number of files that are being synchronized"finished_files_count" : 0, //Number of files that have been synchronized"bytes" : 0, //Size of files that are being synchronized"finished_bytes" : 0 //Size of files that have been synchronized}}]}}}}
Переключение ролей лидирующего и ведомого кластеров
Когда лидирующий кластер выходит из строя, выполните переключение лидирующего/ведомого кластера, чтобы ведомый кластер принял на себя обслуживание. Шаги выглядят следующим образом:
Переключение лидирующего/ведомого кластера не сработает, если лидирующий и ведомый кластеры не используют одинаковые имена индексов.
- Определите метод синхронизации индексов между лидирующим и ведомым кластерами. Проверьте, были ли настроены политики синхронизации индексов по шаблону в ведомом кластере. Команда, которую следует использовать, см Запрос и удаление созданных шаблонов.
- Если таких политик нет, синхронизация выполняется для указанных индексов между лидирующим и ведомым кластерами. В этом случае перейдите к 3.
- Если такие политики имеются, синхронизация индексов между лидирующим и ведомым кластерами осуществляется на основе шаблонов индексов. В этом случае перейдите к 2.
- Удалить политики синхронизации индексов по шаблону в кластере‑подписчике. Для используемой команды см Запрос и удаление созданных шаблонов.
- Выполнить Остановка синхронизации индексов в кластере‑подписчике. Затем перенаправьте чтение и запись трафика на него. Если кластер‑лидер и кластер‑подписчик синхронизируют индексы по шаблонам индексов, используйте подстановочный знак для сопоставления индексов при выполнении команды, останавливающей синхронизацию индексов.
- После восстановления кластера‑лидера настройте информацию о кластере‑подписчике в кластере‑лидере и снова подключите кластеры‑лидер и‑подписчик. Для подробностей см Подключение кластера‑лидера и кластера‑подписчика.
- В кластере‑лидере выполните Синхронизация индексов для синхронизации данных из кластера‑подписчика в кластер‑лидера, а затем выполнить переключение лидер/подписчик для возврата.