DWS — это онлайн-база данных для анализа и обработки данных, построенная на облако инфраструктуре и платформе. Она предлагает масштабируемые, готовые к использованию и полностью управляемые аналитические сервисы баз данных и совместима с синтаксисом ANSI/ISO SQL-92, SQL-99 и SQL:2003. Кроме того, DWS взаимодействует с другими экосистемами баз данных, такими как PostgreSQL, Oracle, Teradata и MySQL. Это делает её конкурентоспособным вариантом для аналитики больших данных в петабайт‑масштабе в различных отраслях.
Логическая архитектура кластера
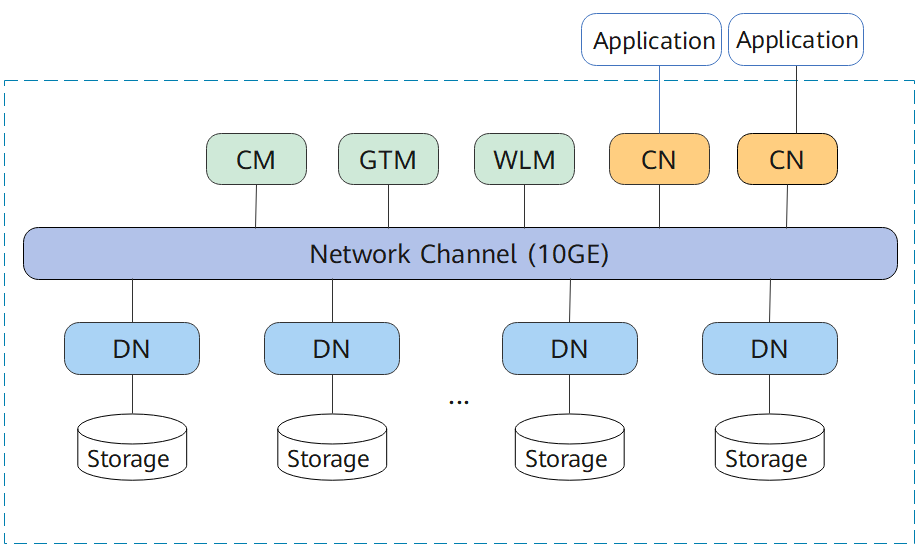
Рис. 1 показывает логическую архитектуру кластера DWS. Для получения подробностей об экземпляре см. Таблица 1.
Рис. 1 Логическая архитектура кластера
Имя | Функция | Описание |
|---|---|---|
Менеджер кластера (CM) | Менеджер кластера. Он управляет и контролирует состояние работы функциональных единиц и физических ресурсов в распределённой системе, обеспечивая стабильность системы. | CM состоит из CM Agent, OM Monitor и CM Server.
CM Servers развернуты в парах основной/резервной для обеспечения высокой доступности системы. CM Agent подключается к основному CM Server. Если основной CM Server неисправен, резервный CM Server повышается до основного, чтобы предотвратить единичную точку отказа (SPOF). |
Менеджер глобальных транзакций (GTM) | Генерирует и поддерживает глобально уникальную информацию, такую как идентификатор транзакции, снимок транзакции и метка времени. | Кластер включает только одну пару GTM: один основной GTM и один резервный GTM. |
Менеджер нагрузки (WLM) | Менеджер нагрузки. Он контролирует распределение системных ресурсов, чтобы предотвратить перегрузку сервисов и сбой системы, вызванный чрезмерной нагрузкой. | Вам не нужно указывать имена хостов, где должны быть развернуты WLM, поскольку программа установки автоматически устанавливает WLM на каждый хост. |
Координатор (CN) | CN получает запросы доступа от приложений и возвращает результаты выполнения клиенту; делит задачи и распределяет фрагменты задач между различными DN для параллельной обработки. | CNs в кластере имеют эквивалентные роли и возвращают одинаковый результат для одинакового DML‑запроса. Балансировщики нагрузки могут быть добавлены между CNs и приложениями, чтобы обеспечить прозрачность CNs для приложений. Если CN неисправен, балансировщик нагрузки автоматически подключает приложение к другому CN. Для подробностей см раздел "Associating and Disassociating ELB". CNs должны соединяться друг с другом в архитектуре распределенных транзакций. Чтобы снизить большую нагрузку, вызванную избыточными потоками на GTMs, в кластере должно быть настроено не более 10 CNs. DWS обрабатывает глобальную нагрузку ресурсов в кластере, используя Central Coordinator (CCN) для адаптивного динамического управления нагрузкой. При первом запуске кластера CM выбирает CN с наименьшим ID в качестве CCN. Если CCN неисправен, CM заменяет его новым. |
Datanode (DN) | DN хранит данные в row-store, column-store или гибридном режиме, выполняет задачи запросов данных и возвращает результаты выполнения CNs. | В кластере присутствует несколько DN. Каждый DN хранит часть данных. DWS обеспечивает высокую доступность DN: активный DN, резервный DN и вторичный DN. Принципы работы этих трех компонентов следующие:
Вторичный DN служит исключительно резервной копией и никогда не переходит в статус активного или резервного в случае сбоев. Он экономит место, удерживая только данные Xlog, переданные от нового активного DN, и данные, реплицированные во время отказов исходного активного DN. Такой эффективный подход экономит одну треть объёма хранения по сравнению с традиционными методами тройного резервирования. |
Хранилище | Функционирует как локальные ресурсы хранения сервера для постоянного сохранения данных. | - |
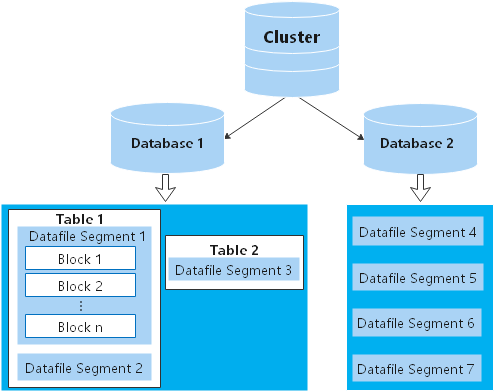
DN в кластере хранят данные на дисках. Рисунок 2 Логически описывает объекты на каждом DN и взаимосвязи между ними.
- База данных управляет различными объектами данных и изолирована от других баз данных.
- Сегмент файла данных хранит данные только в одной таблице. Таблица, содержащая более 1 ГБ данных, хранится в нескольких сегментах файлов данных.
- Таблица принадлежит только одной базе данных.
- Блок является базовой единицей управления базой данных, имея размер по умолчанию 8 КБ.
Данные могут распределяться в режимах репликации, round-robin или хеширования. Вы можете указать режим распределения при создании таблицы.
Рис. 2 Логическая архитектура базы данных
Архитектура совместного хранения и вычислений
DWS использует архитектуру shared-nothing и движок масштабно‑параллельной обработки (MPP), и состоит из множества независимых логических узлов, которые не разделяют системные ресурсы, такие как CPUs, память и хранилище. В такой системной архитектуре сервисные данные хранятся отдельно на многочисленных узлах. Задачи анализа данных выполняются параллельно на узлах, где данные хранятся. Масштабно‑параллельная обработка данных значительно повышает скорость отклика.
Рис. 3 Архитектура
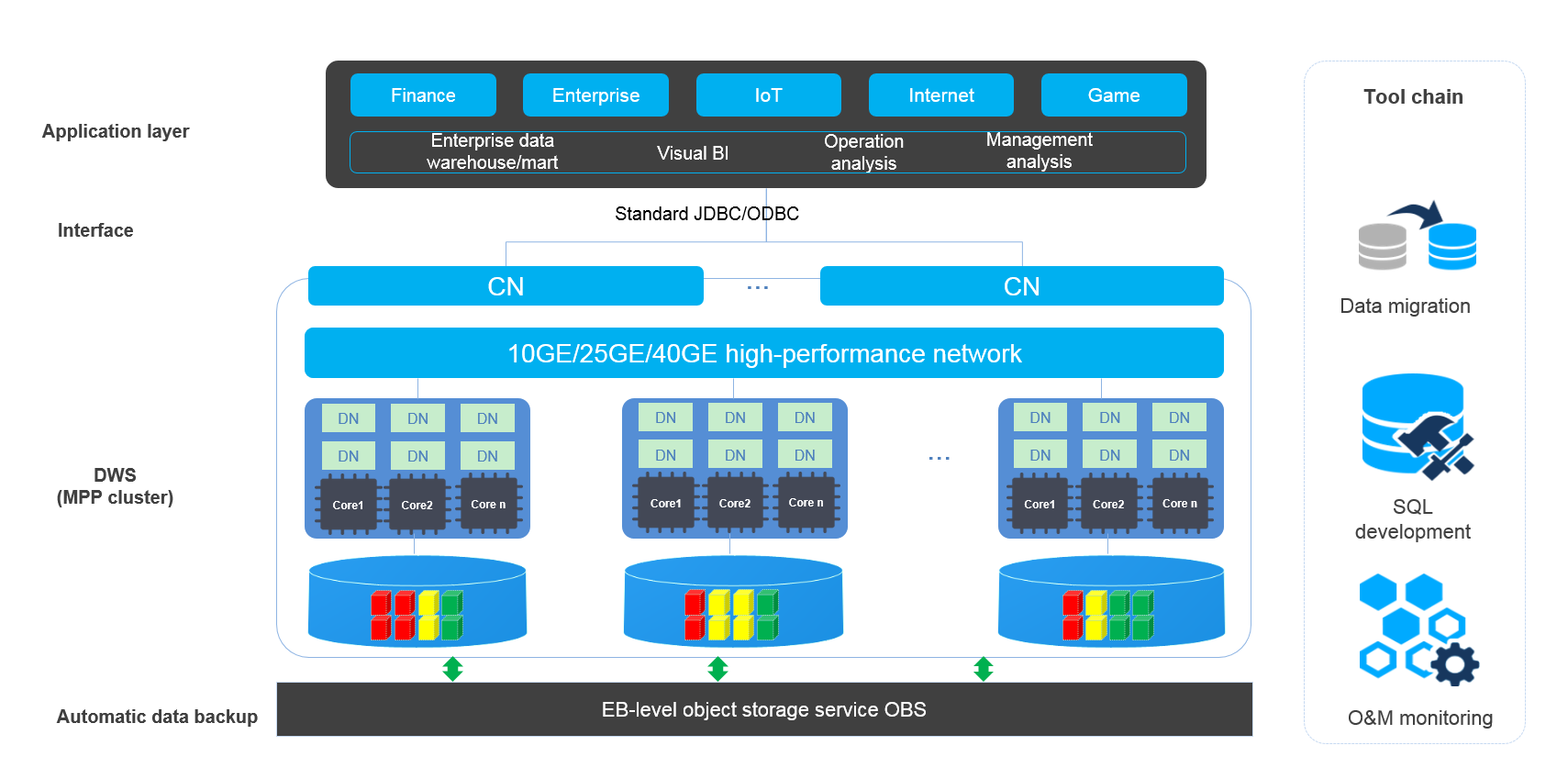
- Слой приложения
Инструменты загрузки данных, инструменты Extract-Transform-Load (ETL), инструменты Business Intelligence (BI), а также инструменты добычи и анализа данных могут быть интегрированы с DWS через стандартные интерфейсы. DWS совместим с экосистемой PostgreSQL, и синтаксис SQL совместим с Oracle и Teradata. Приложения могут быть плавно перенесены на DWS, внесив лишь небольшие изменения.
- API
Приложения могут подключаться к DWS через стандартные JDBC и ODBC.
- DWS
Кластер хранилища данных содержит узлы с одинаковым Флейвор в одной подсети. Эти узлы совместно предоставляют услуги. Datanodes (DNs) в кластере хранят данные на дисках. CNs, или Coordinators, получают запросы доступа от клиентов и возвращают результаты выполнения. Они также разбивают и распределяют задачи между Datanodes (DNs) для параллельного выполнения.
- Автоматическое резервное Бэкап
Снимки кластера могут быть автоматически бэкапированы в Object Storage Service (OBS) уровня EB, что облегчает периодический Бэкап кластера в непиковые часы, обеспечивая восстановление данных после возникновения исключения кластера.
Снапшот — это полный Бэкап DWS в указанный момент времени. Он фиксирует все конфигурационные данные и служебные данные кластера в указанный момент.
- Инструментальная цепочка
Предоставляются параллельный инструмент загрузки данных General Data Service (GDS), инструмент миграции синтаксиса SQL Database Schema Convertor (DSC) и инструмент разработки SQL Data Studio. O&M кластера можно мониторить в консоли.