Вы можете создать индивидуальные и публичные Jupyter Servers различных конфигураций.
Для работы с Jupyter Server:
Шаг 1. Сконфигурируйте и создайте Jupyter Server
Перейдите в Environments → Jupyter Servers.
Нажмите Создать Jupyter Server. Откроется окно, в котором необходимо заполнить параметры сервера.
В поле Название введите название нового сервера c учетом регистра. Разрешается применять следующие символы: строчные латинские буквы от a до z, цифры от 0 до 9, дефис (–).
(Опционально) Нажмите Добавить описание и заполните поле Описание.
Выберите Тип задачи:
Обучение моделей на GPU. Обучение моделей на фреймворках PyTorch, TensorFlow на GPU.
Обучение на GPU запускается путем отправки задач в регион. При этом оплачивается фактическое время исполнения задачи: от старта до окончания обучения. При обучении из Jupyter Server на выделенных GPU взимается оплата с момента создания Jupyter Server до удаления, даже если он не используется.
Управление распределенными задачами. Запуск и мониторинг распределенных GPU-задач.
ПримечаниеБесплатные Jupyter Server создаются с этим типом задач.
При работе с архивами, содержащими более 10 000 файлов размером менее 1 МБ, время распаковки на конфигурации Управление распределенными задачами будет значительно выше, чем на конфигурации с выделенными GPU и hardware CPU. Подробнее о других особенностях.
Обучение моделей на CPU. Подготовка данных, обучение моделей на классическом стеке Data Science.
Установите требуемую конфигурацию Jupyter Server.
Для использования другой конфигурации создайте Jupyter Server повторно.
Выберите один из доступных регионов размещения ресурсов и задайте параметры нового Jupyter Server. Список регионов размещения ресурсов.
ПримечаниеПосле создания изменить конфигурацию вычислительных ресурсов не получится. Вы можете создать Jupyter Server с новой конфигурацией заново.
Выберите Ресурсы.
Ориентируйтесь на цвет индикатора рядом с названием конфигурации:
Зеленый — свободных ресурсов достаточно для запуска сервера в выбранной конфигурации.
Желтый — свободных ресурсов мало для запуска серверов в этой конфигурации. Если планируете создать несколько таких серверов, ресурсов может не хватить.
Серый — свободных ресурсов не осталось. Выбрав эту конфигурацию, вы попадаете в очередь на высвобождение ресурсов. Jupyter Server будет иметь статус «Запускается».
Чтобы не ждать, выберите другой регион или конфигурацию.
Выберите образ для запуска Jupyter Server.
Для выбора доступны образы Distributed Train и образы из Artifact Registry.
Distributed Train содержит:
DataHub — базовые образы Distributed Train.
Docker Registry — образы, загруженные пользователем в Docker Registry.
Для выбора образа:
Нажмите Выбрать образ.
Перейдите в одну из вкладок DataHub или Docker Registry и выберите образ.
Набор образов зависит от региона, выбранного на предыдущем шаге.
Рекомендуется использовать для работы образ jupyter-server версии 0.0.96 и выше, так как в нем уже предварительно установлена Conda.
Нажмите Продолжить и выберите настройки для сервера.
Укажите тип доступа:
Совместный — доступен всем участникам воркспейса;
Индивидуальный — доступен только пользователю, создавшему Jupyter Server.
ПримечаниеТип доступа задается при создании Jupyter Server, изменить его нельзя.
Обновите воркспейс или создайте новый, если индивидуальные Jupyter Servers недоступны.
(Опционально) Настройте автоматическое выключение.
(Опционально) Подключите хранилища S3.
Нажмите Создать Jupyter Server и дождитесь инициализации сервера. Как только она завершится, статус Jupyter Server изменится с «Запускается» на «Подключен».
ПримечаниеЗапуск Jupyter Server, находящегося в очереди в статусе «Запускается», может произойти в том числе и ночью. При этом тарификация начнется с момента запуска.
Шаг 2. Подключитесь к Jupyter Server
Подключитесь к Jupyter Server, выбрав предпочитаемый способ.
Чтобы подключиться к Jupyter Server из списка:
Перейдите в Environments → Jupyter Servers.
Нажмите кнопку подключения к требуемому Jupyter Server, выбрав Jupyter или JupyterLab.
В колонке Создатель отображается пользователь, создавший Jupyter Server. Если не было возможности сохранить создавшего пользователя, то будет указан неизвестный создатель.
Логи Jupyter Server можно посмотреть, выбрав соответствующий пункт из меню  .
.
Для отправки запросов из Jupyter Server в интернет можно использовать любые TCP-порты. Доступ в интернет не ограничен.
Использование Jupyter Server из интернета невозможно без интерфейса Distributed Train или SSH-соединения с Jupyter Server.
Шаг 3. Начните работу в Jupyter Server
Выберите New Launcher, нажав +.
Запустите необходимый инструмент.
Инструменты, общие для всех образов
В Jupyter и JupyterLab можно использовать терминал. Он работает как стандартная Linux-консоль с интерпретатором bash. В командной строке терминала можно исполнять привычные Linux-команды, такие, как ls, wget, git, pip list, pip install --user и др.
В интерфейсе JupyterLab нажмите +, затем Terminal.

Откроется терминал.
Плагины для образа jupyter-server версии 0.0.96 и выше
Позволяет добавить вкладку файлового браузера для любой директории.
По умолчанию создается браузер для каталогов /workspace и /home/jovyan.
Для директорий действуют лимиты на отображение: до 100 каталогов и до 1000 файлов. Чтобы убрать ограничения и отобразить все каталоги и файлы, отключите опцию Enable files overflow в разделе Settings. При отключении опции отобразятся все элементы, кроме скрытых.
Отключение опции Enable files overflow может значительно замедлить работу интерфейса и затруднить навигацию по проектам с большим количеством каталогов и файлов.
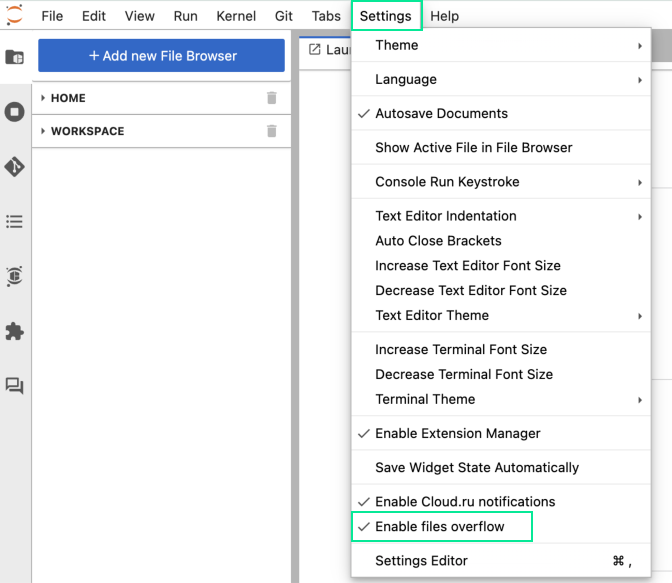
Для добавления новой вкладки файлового браузера:
Нажмите Add new File Browser.
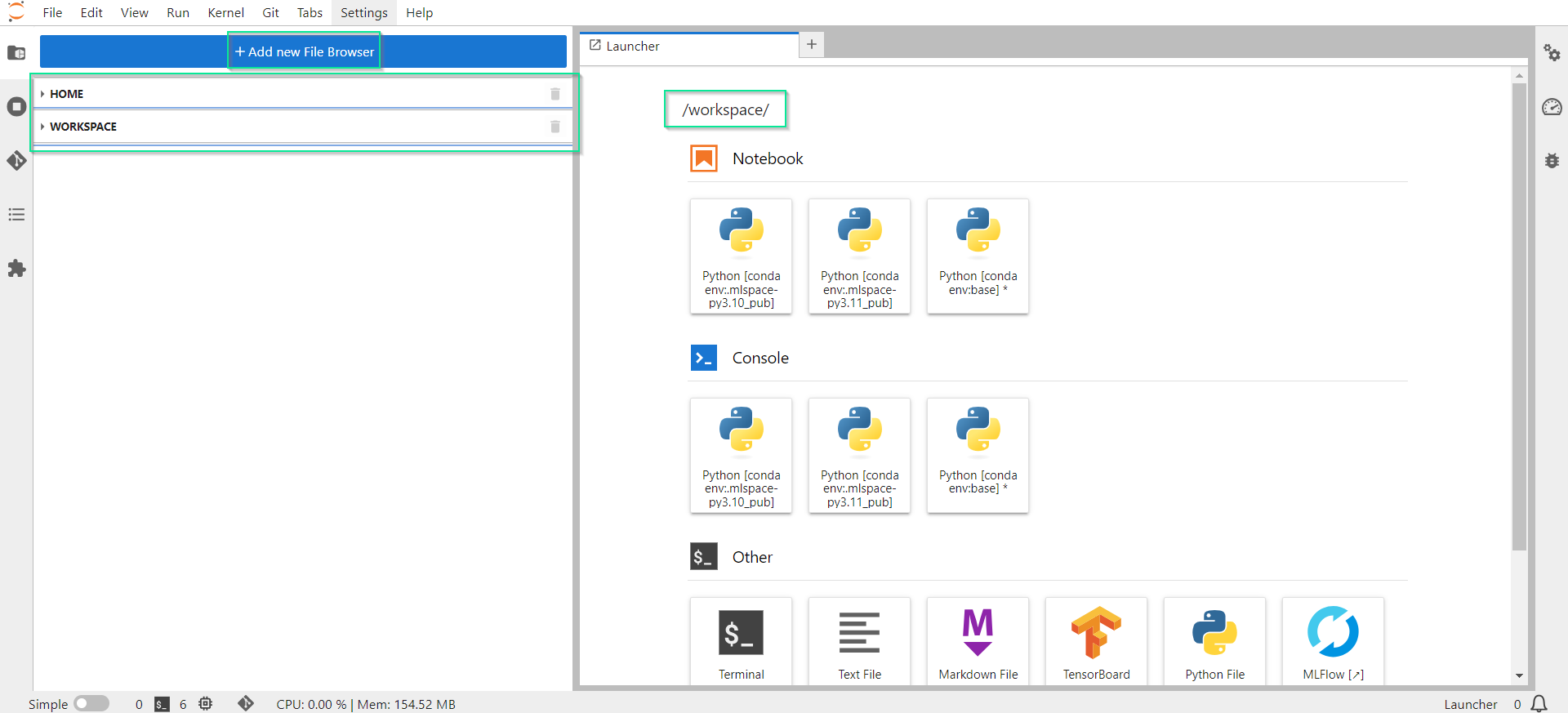
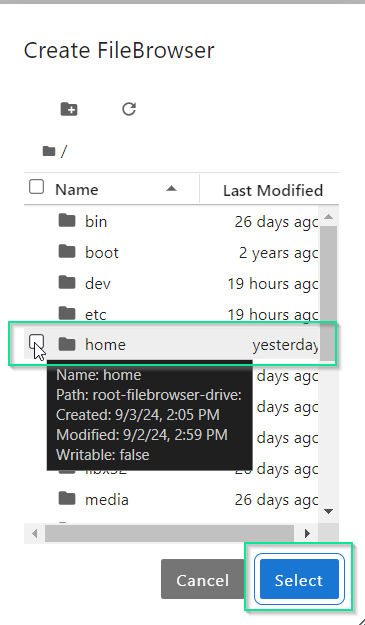
Выберите требуемый каталог.
Нажмите Select.
Для удаления созданной вкладки файлового браузера нажмите  возле вкладки, которую требуется удалить.
возле вкладки, которую требуется удалить.
Удалить вкладки для каталогов /workspace и /home/jovyan нельзя.
Что дальше
Создайте окружение в запущенном образе.