Разработка и эксплуатация ML‑моделей

Что мы предлагаем
Платформенные сервисы для обучения ML- и DL-моделей на базе облачной инфраструктуры, которые позволяют повысить эффективность процесса обучения за счет интуитивно-понятного интерфейса и преднастроенного окружения, а также оптимизировать весь MLOps-цикл для непрерывного обновления моделей в продуктовой среде.
Какие проекты можно создавать с ML-моделями
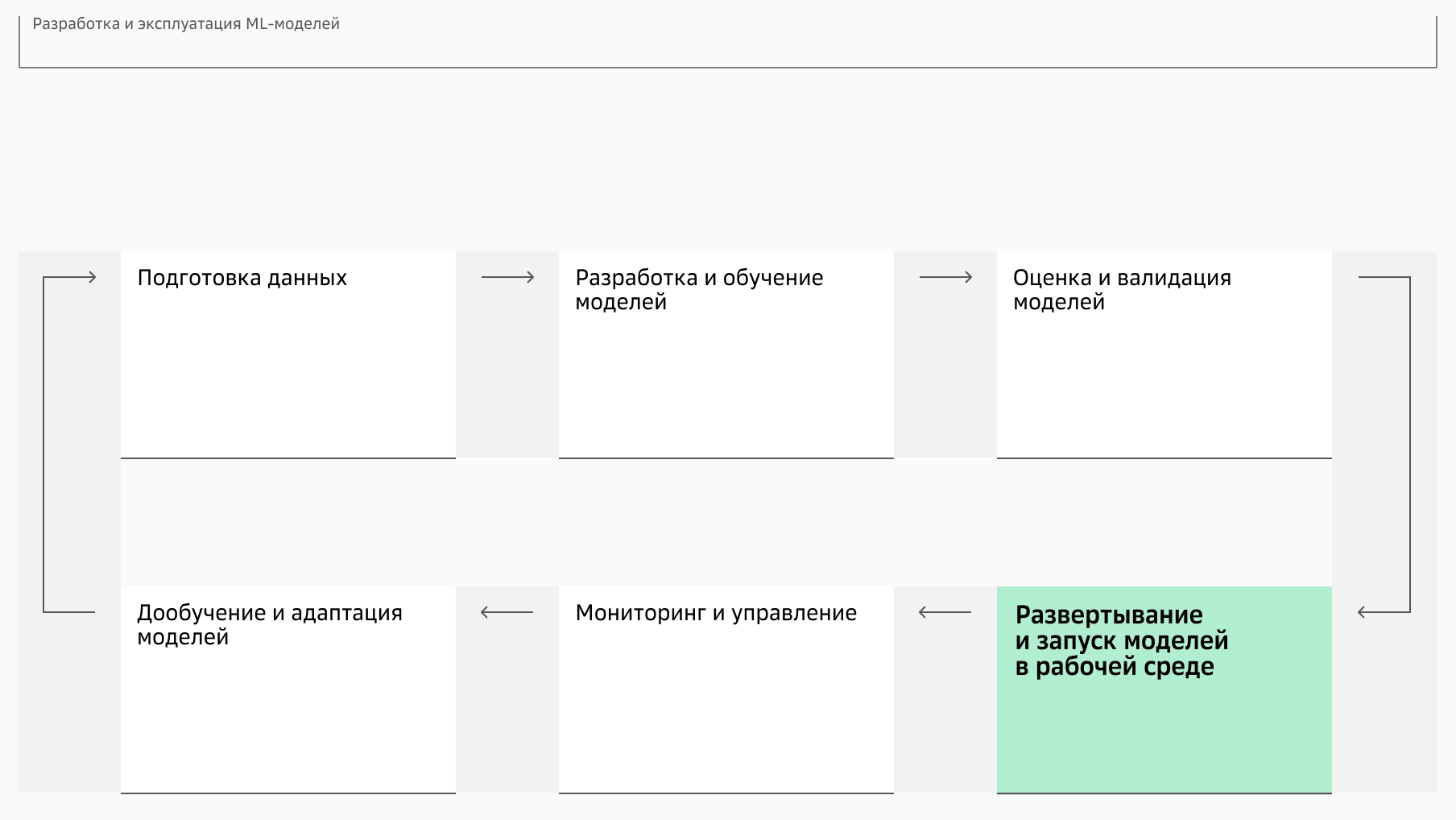
Разработка ML-моделей проходит по общепринятому MLOps-циклу — набору практик, который позволяет последовательно и эффективно внедрять и поддерживать модели машинного обучения для решения задач бизнеса.
Обработка естественного языка и речевые технологии
Чат-боты и AI-ассистенты
Обработка больших данных
Генеративные модели
Предиктивные модели (Classical ML)
Кому необходимы сервисы для обучения ML-моделей
Дата-сайентистам
Большой набор полезных и полностью готовых к использованию инструментов для быстрого прототипирования и нахождения инсайтов
ML-инженерам
Масштабируемая инфраструктура позволяет ускорить обучение моделей, а несколько видов инференса дают возможность легко и дешево встроить модель в бизнес-процессы
AI-исследователям
Большие вычислительные кластеры и суперкомпьютеры для обучения моделей
Дата-инженерам
Интегрированные инструменты и сервисы помогают создавать устойчивые конвейеры данных
MLOps-инженерам
Платформенные ML-сервисы на базе облака позволяют оптимизировать весь цикл управления моделями за счет автоматизации и мониторинга
Решаемые ML-задачи
Подготовка данных
Сбор и очистка данных, а также трансформация их форматов. Создание фичей для моделей и оценка качества датасета.
Разработка и обучение моделей
Создание моделей и их обучение на выбранном наборе данных с подбором оптимальных гиперпараметров.
Оценка и валидация моделей
Тестирование моделей на контрольной выборке данных с использованием различных метрик (Accuracy, Precision, Recall, F1-score). Оценка качества методом кросс-валидации.
Развертывание и запуск моделей в рабочей среде
Квантизация, Docker-контейнеризация и настройка API для обработки входящих данных в реальном времени.
Мониторинг и управление
Мониторинг метрик моделей (латентность, дрифт), а также запись логов и уведомления об изменениях на основе поведения моделей.
Дообучение и адаптация моделей
Регулярное дообучение моделей на новых данных с выстраиванием автоматического пайплайна этого процесса.
Ключевые сценарии использования ML-моделей в Cloud.ru
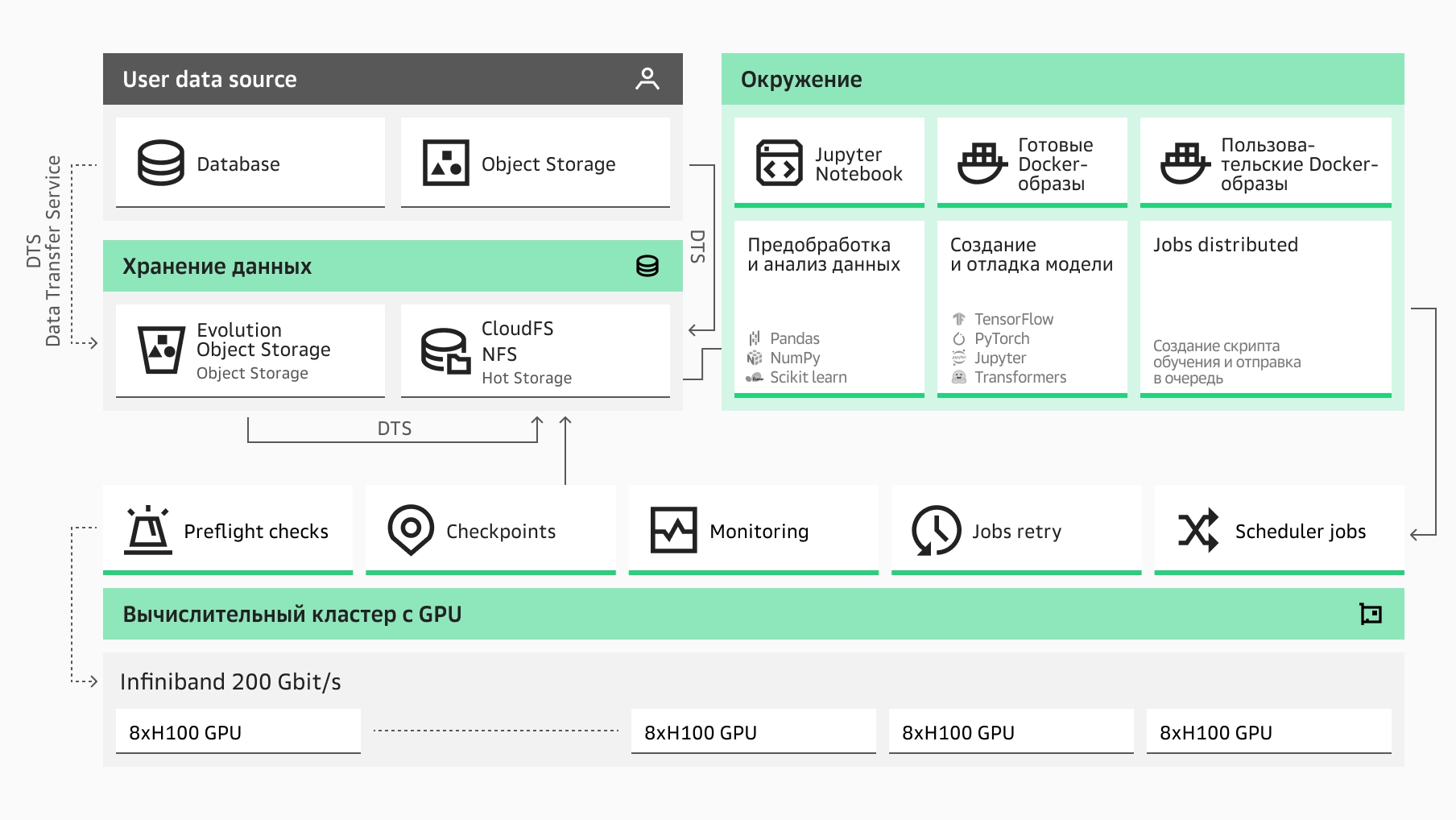
Запуск обучения ML-модели на высокопроизводительном кластере позволяет распараллелить вычисления между множеством узлов с GPU.
Поддерживаются фреймворки PyTorch Distributed и Elastic Learning, Horovod, Hugging Face Accelerate.
Сервисы для решения ML-задач
Вычислительные мощности с GPU
Аренда виртуальных машин, серверов и ML-платформа с графическими ускорителями
Задачи обучения Jobs
Запуск задач обучения на кластерах без взаимодействия с Jupyter, настройка ресурсов для каждой задачи и формирование очереди задач.
Jupyter Server
Среды разработки для удобной записи, передачи и запуска кода при работе в ML-моделями.
Data transfer service
Сервис для миграции данных вручную или автоматически, по правилам или расписанию.
Evolution Object Storage
Масштабируемое хранилище S3 для всех типов данных
Advanced Object Storage Service
Объектное хранилище, полностью совместимое с S3
Почему лучше в облаке
Гибкость и масштабируемость
Платформа в облаке предоставляет современные инструменты для ML-разработки — в том числе мощные графические процессоры (GPU), возможности распределенной работы и автоматизации создания, обучения и внедрения моделей, а также гибкие схемы оплаты для сокращения затрат.
Удобная работа ML-команд
Для эффективной командной работы на платформе доступны: совместные Jupyter-ноутбуки, сервисы запуска экспериментов и мониторинга MLflow и TensorBoard, интеграция с удобными VCS-системами, гибкая ролевая модель для разграничения прав специалистов и готовые окружения для препроцессинга и обучения.
Почему лучше в Cloud.ru
Сразу доступно удобное ML-окружение и знакомые образы
Готовое ML-окружение и набор образов для работы с ML-моделями позволяют ускорить начальный этап разработки и быстрее приступить к экспериментам за счет сокращения времени на настройку и конфигурацию.
Работа с привычными инструментами и средами разработки (IDE)
Не нужно тратить время на осваивание новых инструментов — используйте Jupyter-ноутбуки для анализа данных и визуализации, MLFlow для управления экспериментами и версионирования, TensorBoard для мониторинга обучения.
Единая платформа для управления данными
Доступен полный набор инструментов для обработки данных: современные сервисы хранения (S3, NFS), инструменты для пакетной и потоковой обработки данных (Managed Spark, Managed Trino).
Современные GPU с NVLink
Ускорение обучения обеспечивается за счет современных графических ускорителей NVIDIA H100 и A100. А в конфигурациях с несколькими картами поддерживается шина NVLink.
Инструменты автозамены серверов с GPU
Чтобы обеспечить доступность и минимизировать простои в процессе обучения, при возникновении ошибок узлы в кластере заменяются автоматически, а инструменты автозамены перераспределяют нагрузку.
Распределенное обучение с Infiniband
Сеть InfiniBand позволяет масштабировать обучение больших моделей и мультимодальных нейронных сетей на кластерах. Она поддерживает удаленный прямой доступ к памяти (RDMA), что ускоряет передачу данных между GPU и снижает время обучения в распределенных вычислениях.
Мониторинг процесса обучения
Мониторинг обучения позволяет отслеживать ключевые метрики модели в реальном времени, выявлять неиспользуемые ресурсы и оптимизировать производительность для повышения эффективности процесса.
Гибкая модель тарификации
Оплата за фактическое время обучения/инференса модели или работу сервера позволяет оптимизировать расходы. Это особенно выгодно для динамичных проектов с переменной нагрузкой.
Совместная работа ML-команды
При совместной работе на ML-платформе все участники в режиме реального времени могут разрабатывать, обучать и тестировать модели, а также делиться данными и кодом для ускорения процесса и улучшения результатов.

Истории успеха наших клиентов
Ответы на вопросы
Больше чем просто поддержка
