С помощью этого руководства вы научитесь использовать TensorBoard с PyTorch Profiler для выявления узких мест производительности моделей машинного обучения.
Вы создадите нейронную сеть для классификации изображений и обучите ее с применением инструментов профилирования. Научитесь анализировать результаты для оптимизации производительности.
В результате вы получите практические навыки работы с инструментами визуализации и анализа производительности моделей PyTorch.
Вы будете использовать следующие сервисы и библиотеки:
Notebooks — сервис для запуска сред ML и работы DS-специалистов в ноутбуках на платформе Evolution.
PyTorch — оптимизированная библиотека для глубокого обучения с использованием GPU и CPU.
Matplotlib — комплексная библиотека для создания статических, анимированных и интерактивных визуализаций.
TensorBoard — инструмент для визуализации и отладки процесса обучения нейронных сетей.
Шаги:
Перед началом работы
Зарегистрируйтесь в личном кабинете Cloud.ru.
Если вы уже зарегистрированы, войдите под своей учетной записью.
На верхней панели слева нажмите
 и убедитесь, что сервис Notebooks в разделе AI Factory подключен.
Если сервис Notebooks не подключен, оставьте заявку на подключение.
и убедитесь, что сервис Notebooks в разделе AI Factory подключен.
Если сервис Notebooks не подключен, оставьте заявку на подключение.
1. Подготовьте среду
Создайте ноутбук со следующими параметрами:
Конфигурация — GPU nv100.xlarge.16.
Образ — Cloud.ru Jupyter (Conda).
Дождитесь пока ноутбук перейдет в статус «Запущен».
Нажмите JupyterLab в строке созданного ноутбука.
В ноутбуке выберите TensorBoard в разделе Other.
Вернитесь на вкладку ноутбука для дальнейшей работы.
2. Обучите нейронную сеть с использованием PyTorch
На этом шаге вы обучите нейронную сеть для классификации изображений на датасете CIFAR-10 — 10 классов. Модель научится распознавать объекты на картинках 32x32 пикселя.
Для учебных целей мы создаем четыре типа проблем производительности:
Частые синхронизации CPU и GPU нарушают поток вычислений и замедляют обучение.
Лишние операции с памятью расходуют ресурсы на ненужные копирования и доступы.
Неэффективное использование памяти увеличивает нагрузку на видеопамять и ограничивает масштаб моделей.
Избыточное количество прямых и обратных проходов удлиняет обучение и выполняет лишнюю работу.
Эти проблемы позволяют PyTorch Profiler сгенерировать реальные рекомендации по оптимизации, которые можно увидеть, изучить и применить.
Установите необходимые библиотеки, выполняя команды в отдельных ячейках ноутбука:
pip install torchpip install torchvisionpip install tensorboardpip install matplotlibИмпортируйте библиотеки PyTorch для создания нейронных сетей:
# Import main PyTorch libraries for creating neural networksimport torch # Main framework for deep learningimport torch.nn as nn # Module for creating neural network layersimport torch.optim as optim # Optimizers for model trainingimport torch.nn.functional as F #Activation functions and other useful functionsimport torch.backends.cudnn as cudnn # CUDA optimizations for accelerating computations# Imports for TensorBoard --- visualization of metrics and graphsfrom torch.utils.tensorboard import SummaryWriter# Imports for profiling --- performance analysisfrom torch.profiler import profile, record_function, ProfilerActivityУкажите путь до папки с датасетом:
Нажмите правой кнопкой мыши по папке, которую вы создали для датасета.
Нажмите Copy Path.
Вставьте путь в переменную data_dir в код ниже.
Настройте конфигурационные параметры и директории:
# Configuration parametersresume = False # Flag for resuming training from checkpoint# Directory with CIFAR10 data and path to dataset folderdata_dir = </home/jovyan/runs> # Directory for saving checkpointscheckpoint_dir = f"{os.path.expanduser('~')}/checkpoint/" # All logs will be saved to this folder and accessible via TensorBoard# Set up directory for TensorBoard logslog_dir = f"{os.path.expanduser('~')}/runs/cifar10_experiment"if not os.path.isdir(log_dir):os.makedirs(log_dir)# Create directory if it doesn't existif not os.path.isdir(checkpoint_dir):os.mkdir(checkpoint_dir)checkpoint_file = f"{checkpoint_dir}/ckpt.pth" # Path to checkpoint fileГде </home/jovyan/runs> путь к папке с датасетом.
Настройте устройство:
# Device setupdevice = 'cuda' if torch.cuda.is_available() else 'cpu' # Determine the device for computations (GPU/CPU)# Initialization of variables to track the best accuracybest_acc = 0 # Best accuracy achievedstart_epoch = 0 # Starting epoch, can be changed when resumingmax_epoch = 20 # Maximum number of epochs for training# Initialization of Tensorboard Writer# Create SummaryWriter for writing logs to TensorBoard# This object will be used for logging all metricswriter = SummaryWriter(log_dir=log_dir)Подготовьте данные:
print('==> Preparing data..')# Transformations for training data (with augmentation)transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4), # Randomly crop the image with paddingtransforms.RandomHorizontalFlip(), # Random horizontal fliptransforms.ToTensor(), # Convert image to tensortransforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), # Normalize RGB channels])# Transformations for test data (without augmentation)transform_test = transforms.Compose([transforms.ToTensor(), # Convert image to tensortransforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), # Normalize RGB channels])# Create datasets and data loaderstrainset = torchvision.datasets.CIFAR10(root=data_dir, train=True, download=True, transform=transform_train)trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2) # Data loader for trainingtestset = torchvision.datasets.CIFAR10(root=data_dir, train=False, download=True, transform=transform_test)testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2) # Data loader for testing# CIFAR10 classesclasses = ('plane', 'car', 'bird', 'cat', 'deer','dog', 'frog', 'horse', 'ship', 'truck')print('==> Loading model..')Определите архитектуру модели:
# Basic ResNet blockclass BasicBlock(nn.Module):expansion = 1 # Expansion factor for channel dimensiondef __init__(self, in_planes, planes, stride=1):super(BasicBlock, self).__init__()# First convolutional layerself.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(planes) # Batch normalization# Second convolutional layerself.conv2 = nn.Conv2d(planes, planes, kernel_size=3,stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(planes)# Shortcut connection for residual connectionsself.shortcut = nn.Sequential()if stride != 1 or in_planes != self.expansion*planes:self.shortcut = nn.Sequential(nn.Conv2d(in_planes, self.expansion*planes,kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(self.expansion*planes))def forward(self, x):# Forward pass through residual blockout = F.relu(self.bn1(self.conv1(x))) # ReLU after first convolutionout = self.bn2(self.conv2(out)) # Second convolutionout += self.shortcut(x) # Add shortcut connectionout = F.relu(out) # Final ReLUreturn out# Root block for DLA architectureclass Root(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=1):super(Root, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, kernel_size,stride=1, padding=(kernel_size - 1) // 2, bias=False)self.bn = nn.BatchNorm2d(out_channels)def forward(self, xs):x = torch.cat(xs, 1) # Concatenate inputsout = F.relu(self.bn(self.conv(x))) # Convolution and ReLUreturn out# Tree block for hierarchical DLA structureclass Tree(nn.Module):def __init__(self, block, in_channels, out_channels, level=1, stride=1):super(Tree, self).__init__()self.root = Root(2*out_channels, out_channels) # Root blockif level == 1:# Level 1: basic blocksself.left_tree = block(in_channels, out_channels, stride=stride)self.right_tree = block(out_channels, out_channels, stride=1)else:# Recursive tree constructionself.left_tree = Tree(block, in_channels,out_channels, level=level-1, stride=stride)self.right_tree = Tree(block, out_channels,out_channels, level=level-1, stride=1)def forward(self, x):out1 = self.left_tree(x) # Left subtreeout2 = self.right_tree(out1) # Right subtreeout = self.root([out1, out2]) # Root combines outputsreturn out# Full SimpleDLA architectureclass SimpleDLA(nn.Module):def __init__(self, block=BasicBlock, num_classes=10):super(SimpleDLA, self).__init__()# Base layersself.base = nn.Sequential(nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1, bias=False),nn.BatchNorm2d(16),nn.ReLU(True))# Sequential layersself.layer1 = nn.Sequential(nn.Conv2d(16, 16, kernel_size=3, stride=1, padding=1, bias=False),nn.BatchNorm2d(16),nn.ReLU(True))self.layer2 = nn.Sequential(nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1, bias=False),nn.BatchNorm2d(32),nn.ReLU(True))# Hierarchical Tree blocksself.layer3 = Tree(block, 32, 64, level=1, stride=1)self.layer4 = Tree(block, 64, 128, level=2, stride=2)self.layer5 = Tree(block, 128, 256, level=2, stride=2)self.layer6 = Tree(block, 256, 512, level=1, stride=2)# Classification layerself.linear = nn.Linear(512, num_classes)def forward(self, x):# Forward pass through the entire networkout = self.base(x)out = self.layer1(out)out = self.layer2(out)out = self.layer3(out)out = self.layer4(out)out = self.layer5(out)out = self.layer6(out)out = F.avg_pool2d(out, 4) # Global average poolingout = out.view(out.size(0), -1) # Flattenout = self.linear(out) # Linear layer for classificationreturn outСоздайте и настройте модель:
net = SimpleDLA()net = net.to(device) # Move the model to the specified device (CPU or GPU)# If using GPU, wrap the model in DataParallel to utilize multiple GPUsif device == 'cuda':net = torch.nn.DataParallel(net)cudnn.benchmark = True # Optimize performance for CUDA# Resume training from checkpoint if requiredif resume:print('==> Resuming from checkpoint..')assert os.path.isdir(checkpoint_dir), 'Error: no checkpoint directory found!'checkpoint = torch.load(checkpoint_file)net.load_state_dict(checkpoint['net'])best_acc = checkpoint['acc']start_epoch = checkpoint['epoch']# Define loss function and optimizercriterion = nn.CrossEntropyLoss() # Cross-entropy loss for classificationoptimizer = optim.SGD(net.parameters(), lr=0.1,momentum=0.9, weight_decay=5e-4) # SGD with momentum# Learning rate scheduler with cosine annealingscheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=200)Создайте функцию для создания искусственных проблем производительности.
Функция создает искусственные проблемы производительности для демонстрации рекомендаций. Эта функция намеренно вводит неэффективности для того, чтобы профилировщик мог сгенерировать полезные рекомендации по оптимизации.
Для создания функции выполните:
# Function to create artificial performance bottlenecksdef create_performance_bottlenecks(inputs, targets):# Problem 1if device == 'cuda':# Each .item() call forces GPU to wait for computation to finishfor i in range(3): # 3 unnecessary synchronizations_ = inputs.sum().item() # .item() triggers CPU-GPU synchronization# Artificial delay to simulate poor optimization# This causes GPU idle timetime.sleep(0.001)# Create problem 2large_tensor = torch.zeros(1000, 1000).to(inputs.device)for i in range(5):large_tensor = large_tensor + 0.1 # Redundant operations# Create problem 3intermediate_results = []for i in range(10):temp_result = inputs.clone()intermediate_results.append(temp_result)# Clear memory, but the pattern still demonstrates the issuedel intermediate_resultsreturn inputs, targetsСоздайте функцию тренировки одной эпохи.
На этом шаге вы выполните тренировку модели на одной эпохе с логированием в TensorBoard и возможностью профилирования производительности с рекомендациями.
# Function to train one epochdef train(epoch):print('\nEpoch: %d' % epoch)net.train() # Set model to training mode# Initialize metrics for current epochtrain_loss = 0correct = 0total = 0# Variables for computing running averagerunning_loss = 0.0running_correct = 0running_total = 0# Determine if profiling should be performed# Profile only the first epoch to save timeshould_profile = (epoch == start_epoch)if should_profile:# Start profiling with recommendations# Configure PyTorch profiler with extended parameters# to get detailed optimization recommendationswith profile(# Profile both CPU and CUDA operations for complete analysisactivities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],# Profiling schedule:# wait=1 - wait for 1 step (not profiling)# warmup=1 - warmup for 1 step (not profiling)# active=5 - actively profile for 5 stepsschedule=torch.profiler.schedule(wait=1, warmup=1, active=5),# Save results in TensorBoard format for visualizationon_trace_ready=torch.profiler.tensorboard_trace_handler(log_dir),# Record tensor shape information for analysisrecord_shapes=True,# Record memory usage informationprofile_memory=True,# Record call stack for tracingwith_stack=True,# Enable recommendations collection# Experimental configuration for detailed recommendationsexperimental_config=torch._C._profiler._ExperimentalConfig(verbose=True)) as prof:# Use tqdm for progress displaywith tqdm(trainloader, unit="batch") as tepoch:for batch_idx, (inputs, targets) in enumerate(tepoch):# Required step for profiler# Inform profiler about new step# Without this, profiling won't work correctlyprof.step()# Profile more batches for better statistics# Increase from 10 to 15 batches for more complete analysisif batch_idx >= 15:break# Create artificial performance issues# Add artificial bottlenecks to demonstrate recommendationsinputs, targets = create_performance_bottlenecks(inputs, targets)# Transfer data to device (GPU/CPU)inputs, targets = inputs.to(device), targets.to(device)# Issue: Inefficient backward pass# Perform multiple unnecessary forward/backward passes instead of one# This creates excessive load and memory issuesif batch_idx % 3 == 0 and device == 'cuda': # Every 3rd batch# Unnecessary forward/backward passesfor _ in range(2):# Process only part of the batch (inefficient)extra_outputs = net(inputs[:32]) # Only part of the batchextra_loss = criterion(extra_outputs, targets[:32])# retain_graph=True causes memory issues# and slows down executionextra_loss.backward(retain_graph=True)# Normal forward pass# Zero gradients before new stepoptimizer.zero_grad()# Forward pass through the networkoutputs = net(inputs)# Compute loss functionloss = criterion(outputs, targets)# Backward pass (gradient computation)loss.backward()# Update model weightsoptimizer.step()# Update metrics# Accumulate overall metricstrain_loss += loss.item()_, predicted = outputs.max(1)total += targets.size(0)correct += predicted.eq(targets).sum().item()# Update running averages for loggingrunning_loss += loss.item()running_total += targets.size(0)running_correct += predicted.eq(targets).sum().item()# Log metrics every 10 batchesif batch_idx % 10 == 0:# Log current batch loss to TensorBoardwriter.add_scalar('Training/Loss_batch',loss.item(),epoch * len(trainloader) + batch_idx)# Log current batch accuracywriter.add_scalar('Training/Accuracy_batch',100.*running_correct/running_total,epoch * len(trainloader) + batch_idx)# Reset counters for next windowrunning_loss = 0.0running_correct = 0running_total = 0# Update progress displaytepoch.set_postfix(loss = loss.item(), accuracy = 100.*correct/total)else:# Normal training without profiling# Used for other epochs to save timewith tqdm(trainloader, unit="batch") as tepoch:for batch_idx, (inputs, targets) in enumerate(tepoch):# Add some issues even in normal mode# for consistent issuesif batch_idx % 5 == 0: # Every 5th batch has issuesinputs, targets = create_performance_bottlenecks(inputs, targets)# Normal training without artificial issuesinputs, targets = inputs.to(device), targets.to(device)optimizer.zero_grad()outputs = net(inputs)loss = criterion(outputs, targets)loss.backward()optimizer.step()# Update metricstrain_loss += loss.item()_, predicted = outputs.max(1)total += targets.size(0)correct += predicted.eq(targets).sum().item()# Update running averagesrunning_loss += loss.item()running_total += targets.size(0)running_correct += predicted.eq(targets).sum().item()# Log metrics every 10 batchesif batch_idx % 10 == 0:writer.add_scalar('Training/Loss_batch',loss.item(),epoch * len(trainloader) + batch_idx)writer.add_scalar('Training/Accuracy_batch',100.*running_correct/running_total,epoch * len(trainloader) + batch_idx)running_loss = 0.0running_correct = 0running_total = 0# Update progress displaytepoch.set_postfix(loss = loss.item(), accuracy = 100.*correct/total)# Log epoch metrics# Compute average values for the epochepoch_loss = train_loss/len(trainloader)epoch_acc = 100.*correct/total# Log epoch metrics to TensorBoardwriter.add_scalar('Training/Loss_epoch', epoch_loss, epoch)writer.add_scalar('Training/Accuracy_epoch', epoch_acc, epoch)# Log current learning ratewriter.add_scalar('Learning_Rate', scheduler.get_last_lr()[0], epoch)Создайте функцию тестирования модели.
На этом шаге вы протестируете модель на тестовой выборке с логированием результатов.
def test(epoch):global best_acc # Use global variable for best accuracynet.eval() # Set model to evaluation mode (disable dropout/batchnorm training)# Initialize test metricstest_loss = 0correct = 0total = 0# Disable gradient computation for faster evaluationwith torch.no_grad():# Use tqdm to display progresswith tqdm(testloader, unit="batch") as tepoch:for inputs, targets in tepoch:# Move data to deviceinputs, targets = inputs.to(device), targets.to(device)# Forward passoutputs = net(inputs)# Compute lossloss = criterion(outputs, targets)# Update metricstest_loss += loss.item()_, predicted = outputs.max(1)total += targets.size(0)correct += predicted.eq(targets).sum().item()# Update progress bartepoch.set_postfix(loss=loss.item(), accuracy=100. * correct / total)# Compute test accuracyacc = 100. * correct / total# Save checkpoint if accuracy improvedif acc > best_acc:print('Saving..')state = {'net': net.state_dict(), # Model state'acc': acc, # Accuracy'epoch': epoch, # Epoch number}# Create directory if it does not existif not os.path.isdir(checkpoint_dir):os.mkdir(checkpoint_dir)# Save checkpointtorch.save(state, checkpoint_file)best_acc = acc # Update best accuracy# Compute average test losstest_loss_avg = test_loss / len(testloader)# Log test metrics to TensorBoardwriter.add_scalar('Testing/Loss', test_loss_avg, epoch)writer.add_scalar('Testing/Accuracy', acc, epoch)writer.add_scalar('Testing/Best_Accuracy', best_acc, epoch)# Log model architecture to TensorBoard# Create dummy input for graph visualizationdummy_input = torch.randn(1, 3, 32, 32).to(device)# Add model graph to TensorBoardwriter.add_graph(net, dummy_input)Запустите основной цикл обучения.
Обучение может занимать до 30 минут.
# Main training loop# Iterate over all epochsfor epoch in range(start_epoch, start_epoch + max_epoch):train(epoch) # Train the modeltest(epoch) # Test the modelscheduler.step() # Update learning rate# Finish up# Close the writer to ensure logs are properly savedwriter.close()Выполните демонстрационный код для проверки работы обученной модели.
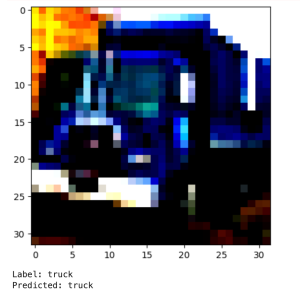
Код отображает одно изображение из тестовой выборки и показывает, как модель классифицирует его.
# Demonstration code# Code to demonstrate the trained model's performanceimport numpy as npimport matplotlib.pyplot as plt# Take the 15th example from the test datasetimg = testset[14][0]label = testset[14][1]# Convert image for displayimg_np = img.numpy()img_np = np.transpose(img_np, (1, 2, 0)) # Change axis order (CHW -> HWC)plt.imshow(img_np) # Display the imageplt.show() # Show the plot# Prepare image for predictionimg = img.reshape(1, 3, 32, 32) # Add batch dimension# Make prediction without gradient computationwith torch.no_grad():logits = net(img) # Get logitspredicted_label = torch.argmax(logits) # Find class index with highest probability# Print resultsprint(f"Label: {classes[label]}") # True labelprint(f"Predicted: {classes[predicted_label.item()]}") # Predicted label
Модель распознала объект как грузовик — предсказание верное.
3. Настройте PyTorch Profiler
На этом шаге вы настроите TensorBoard PyTorch Profiler и познакомитесь с интерфейсом.
Перейдите на вкладку TensorBoard.
В поле Log Dir введите скопированный путь до папки runs.
Дождитесь загрузки визуализации процесса обучения и различные метрики.
Перейдите на вкладку PYTORCH_PROFILER.
4. Ознакомьтесь с методами визуализации PyTorch Profiler
На этом шаге вы научитесь анализировать результаты профилирования для оптимизации производительности модели.
На вкладке PYTORCH_PROFILER отображаются следующие показатели:
Runs — отдельные запуски экспериментов, тренировки и валидации, которые вы профилировали. Их можно выбирать и сравнивать между собой.
Views — способы представления профилированных данных для анализа:
Overview — сводка нагрузки устройства и времени, общая загрузка CPU/GPU, время шагов (forward, backward, optimizer), распределение времени по категориям (Kernel, Memcpy, CPU Exec и др.) и рекомендации профайлера.
Operator — статистика по PyTorch-операторам, например aten::empty и aten::add. Количество вызовов и время на CPU и GPU.
GPU Kernel — детальный анализ отдельных GPU-ядр. Список запущенных ядер, длительность каждого ядра, использование Tensor Cores, заполненность SM (SM occupancy).
Trace — временная диаграмма исполнения потоков. Позволяет детально рассмотреть конкурентность, использование потоков и временные интервалы различных операций.
Memory — использование видеопамяти по времени. Объем выделенной (Allocated) и зарезервированной (Reserved) памяти. Точки аллокаций/освобождений и пиковое потребление.
Module — дерево вызовов на уровне слоев PyTorch. Отображает подмодули и операторы, вызванные внутри каждого модуля, время выполнения на CPU/GPU для каждого уровня.
Workers — источник данных профилирования (процессы/потоки). Например, main-процесс, DataLoader и их потоки. Объем собранных данных для каждого.
Spans — интервалы времени, за которые собирается статистика. Позволяет профилировать только интересующие фрагменты обучения. Например, первые 10 % эпохи или отдельные итерации.
Внутренние показатели профилирования GPU:
Host, Device Total, Self Duration — общее время выполнения оператора/ядра и время в self-режиме, без учета вложенных вызовов.
Tensor Cores Used — степень использования tensor-ядер, важна для операций FP16/FMA.
Calls — количество вызовов операции/ядра.
Mean Est. Achieved Occupancy — заполненность мультипроцессоров, показатель эффективности загрузки GPU.
Peak Memory Usage — пиковое использование памяти.
Allocated/Reserved Memory Usage — объем выделенной и зарезервированной памяти в мегабайтах.
Module Name, Occurrences, Operators — название слоя, количество его вызовов и число различных операторов внутри него.
Показатели позволяют оценить эффективность использования вычислительных ресурсов и планировать оптимизацию.
5. Проанализируйте результаты
На этом шаге вы проанализируете результаты на основе Spans 1.
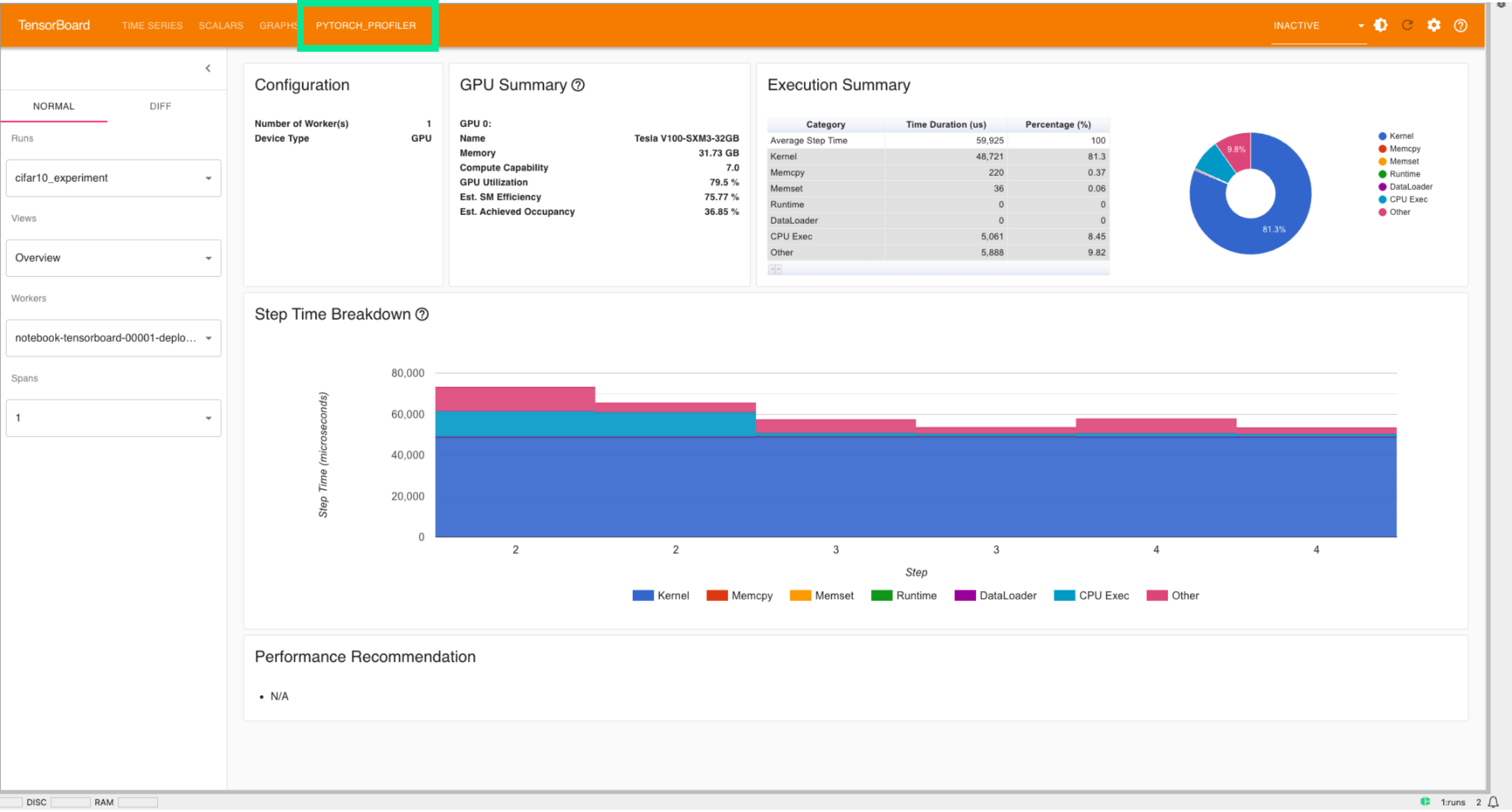
Overview (Обзор)
Основное:
Device: GPU (Tesla V100-SXM3-32GB).
GPU Utilization: 79.5% — хорошая загрузка, но не максимальная.
Est. SM Efficiency: 75.77%.
Achieved Occupancy: 36.85% — невысокая, есть потенциал для увеличения.
Step Time: 59,925 us (микросекунд).
Kernel: 81.3% — основная часть времени тратится на вычисления на GPU.
CPU Exec: 8.45%
Other: 9.82%
Вывод:
Узкие места — основное время уходит в GPU-ядра (Kernel), но низкий уровень occupancy может указывать на то, что не все ресурсы GPU используются оптимально. Например, низкие значения в показателе batch size указывают на неэффективные ядра.
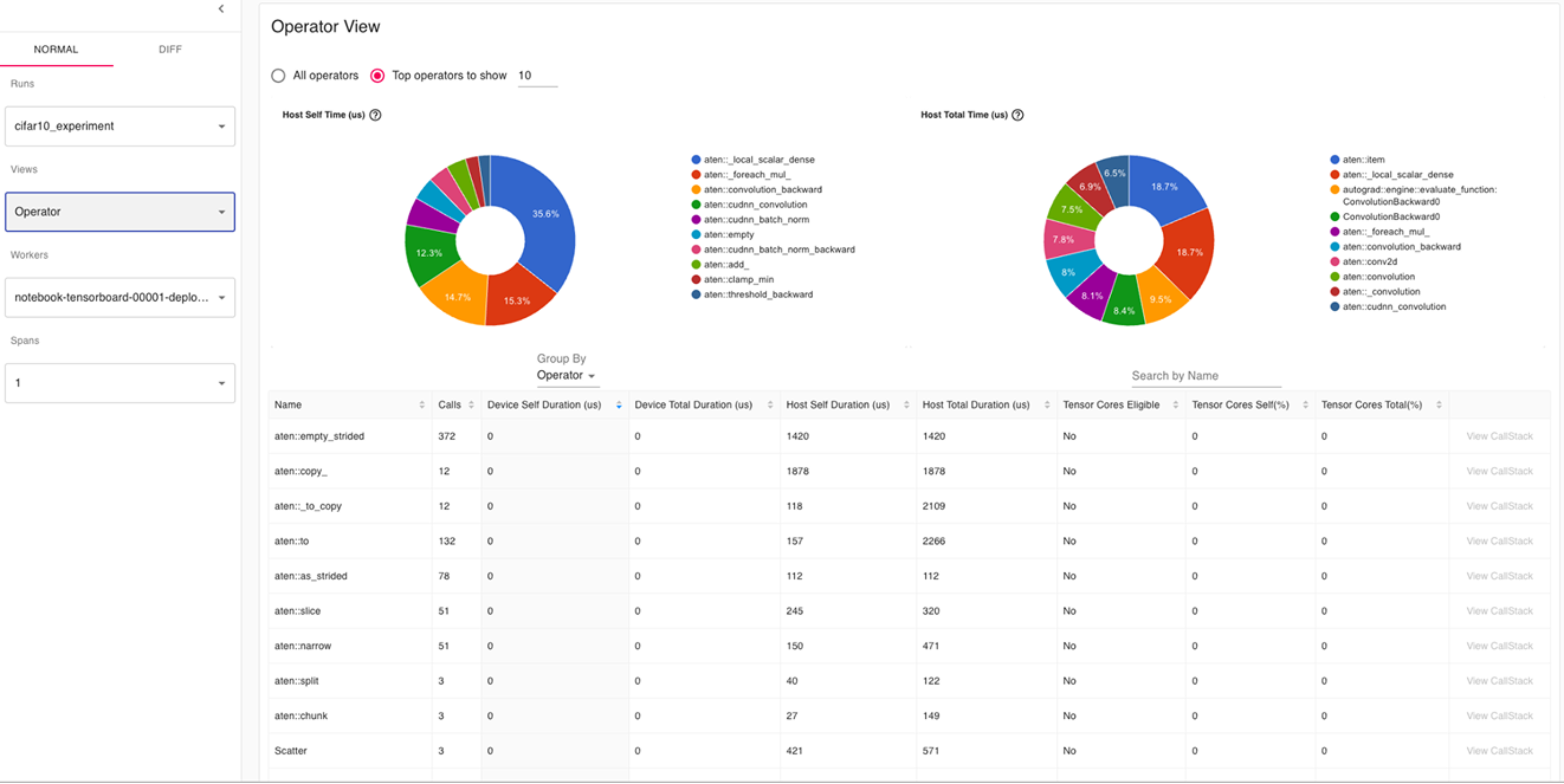
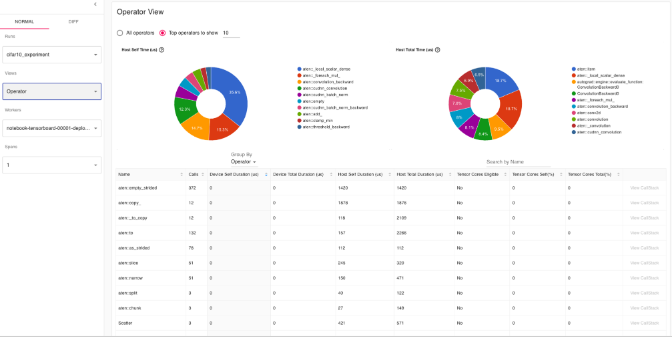
Operator View (Операторы)
Основное:
Представлен разрез времени для топ-10 PyTorch операторов.
Крупнейшие по времени: aten::empty_strided, aten::copy_, aten::_to_copy — создание тензоров и копирование.
Основные вычислительные операции — aten::convolution, aten::cudnn_convolution.
Нет нагрузок на Tensor Cores — значения 0.
Вывод:
Замечено большое число вызовов операций выделения памяти: aten::empty, aten::empty_strided. Это может косвенно указывать на частое создание новых тензоров — повышенное потребление памяти и время на управление памятью.
Большая часть операторов не использует Tensor Cores. Если вы работаете с mixed precision FP32, это нормально, но для mixed precision (FP16) производительность можно повысить.
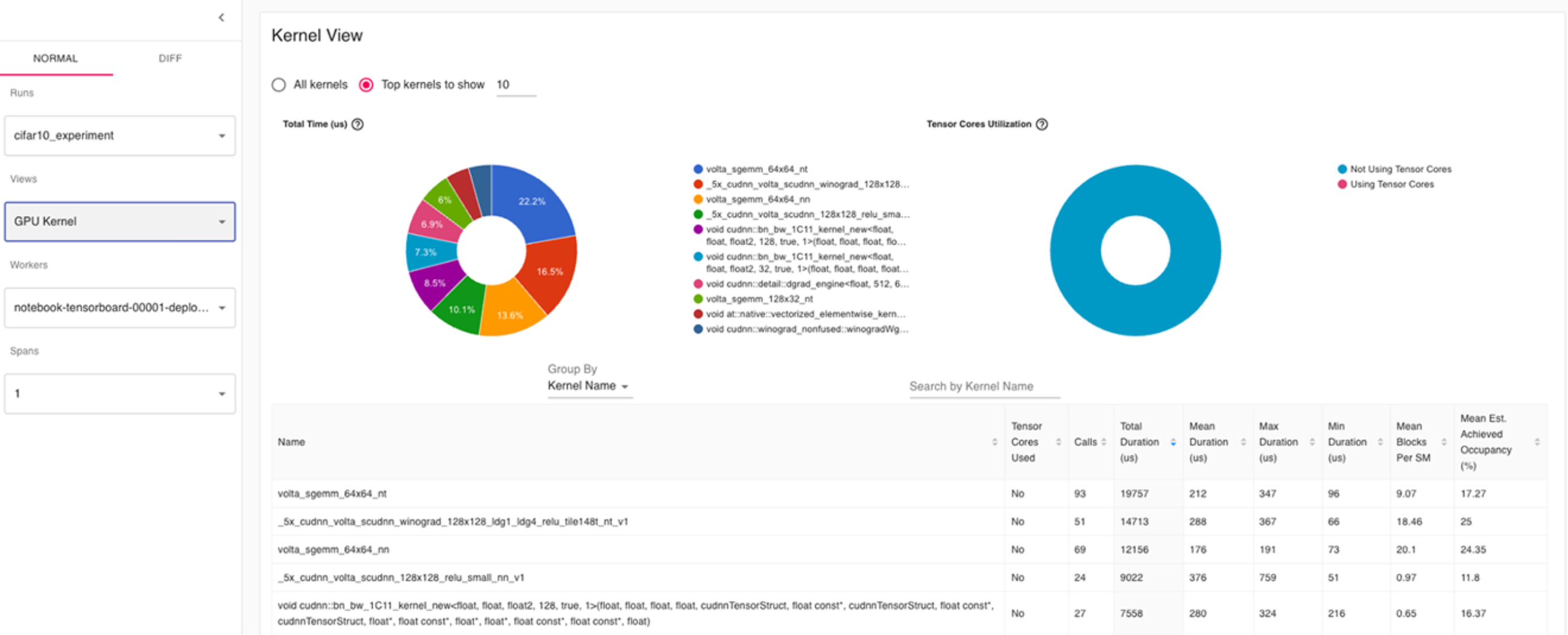
GPU Kernel View (Ядра графического процессора)
Основное:
Наибольшее время занимают матричные ядра volta_sgemm_* и *_cudnn_*, что характерно для сверточных сетей.
Абсолютное доминирование синего цвета означает, что почти все ядра не используют Tensor Cores.
Вывод:
Модель не использует Tensor Cores.
Если задача позволяет, попробуйте включить mixed precision (AMP) — это поможет ускорить обучение на современных GPU.
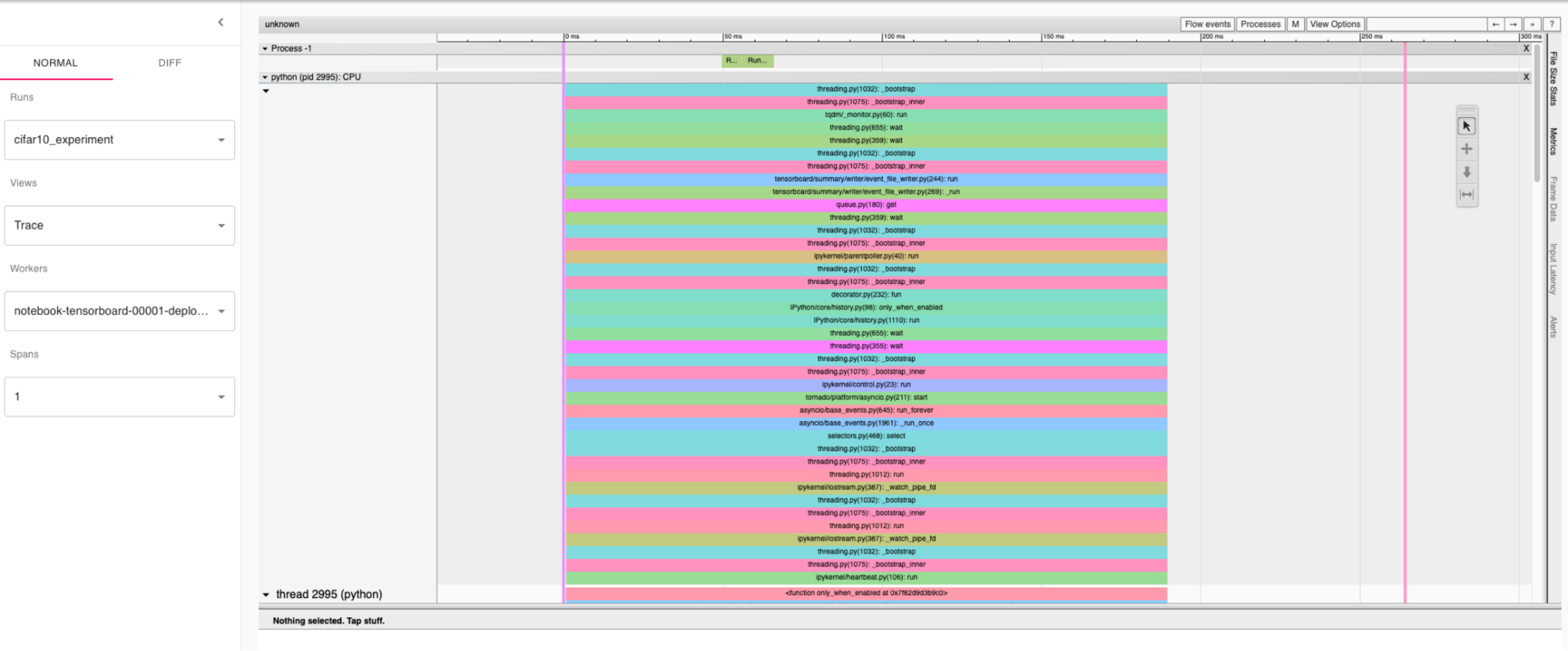
Trace (Временная диаграмма)
Основное:
Видна характерная картина многопоточности — различные потоки CPU.
Можно посмотреть, нет ли интервалов между последовательностями событий.
Вывод:
Не видно крупных задержек (пробелов) — загрузка CPU-потоков ровная.
Нет интервалов между последовательностями событий.
Memory View (Память)
Основное:
Peak GPU Memory Usage: 1419.1 MB — для V100 это небольшая часть доступной памяти. Можно повысить batch size для большего использования GPU.
Основные аллокации идут на операцию aten::cudnn_convolution.
График показывает закономерное выделение и освобождение памяти — три возвышения по числу итераций/батчей.
Вывод:
Модель экономно расходует память, возможен запас для увеличения batch size, это поможет GPU-occupancy.
Нет чрезмерного расхода памяти.

Module View (Модули)
Основное:
Вызовы отслеживаются до слоев: DataParallel, CrossEntropyLoss, SimpleDLA.
Отображается детальная callstack-структура: видно, где и к каким операторам обращается модуль.
Вывод:
Можно использовать эти данные для pinpoint-анализа долгих вызовов внутри отдельных модулей.
Видно, что DataParallel использует относительно много времени на CPU — обычная ситуация для single-GPU.

Обратите внимание, что если менять Spans, отображаемая информация может радикально меняться, также будут появляться рекомендации от TensorBoard.
Например, при параметрах:
Мы получаем рекомендацию, связанную с низкой утилизацией GPU:
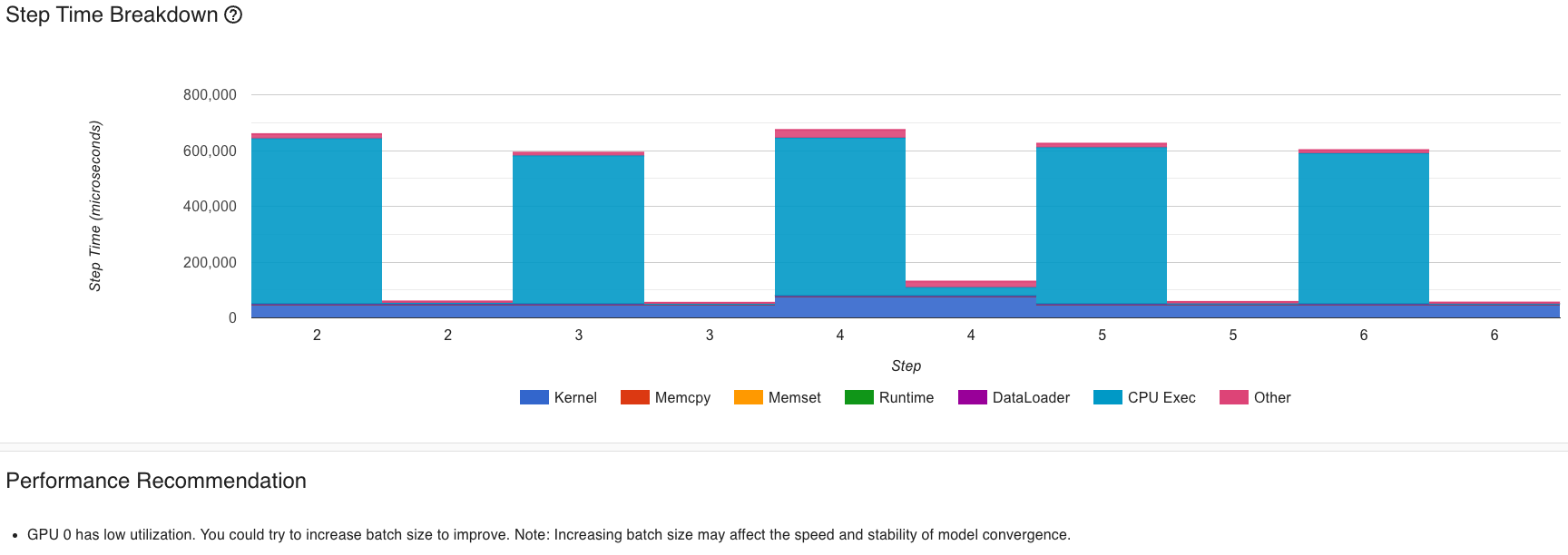
Результат
В ходе практической работы вы научились использовать TensorBoard с PyTorch Profiler для анализа производительности моделей машинного обучения.
Вы создали нейронную сеть для классификации изображений, обучили ее с применением инструментов профилирования и изучили методы анализа результатов для оптимизации производительности.
PyTorch Profiler — мощный диагностический инструмент, который существенно повышает качество кода и эффективность разработки нейронных сетей, делая его обязательным к использованию в любом крупном ML проекте.