С помощью этого руководства вы настроите парсинг Jira, создадите базу знаний в сервисе Managed RAG и разработаете Telegram-бота для интерактивной работы с данными. В результате вы получите готовое решение для поиска информации в задачах Jira на базе образа N8N в сервисе Notebooks.
Вы будете использовать следующие сервисы:
Notebooks — сервис для запуска сред ML и работы DS-специалистов в ноутбуках на платформе Evolution.
Object Storage — объектное S3-хранилище с бесплатным хранением файлов объемом до 15 ГБ.
Managed RAG — сервис для создания и управления базами знаний, используемыми при генерации ответов языковыми моделями.
Jira — инструмент управления проектами для планирования и отслеживания работы в команде.
Telegram — чат-платформа.
N8N — платформа для автоматизации рабочих процессов и интеграции сервисов.
Шаги:
Перед началом работы
Зарегистрируйтесь в личном кабинете Cloud.ru.
Если вы уже зарегистрированы, войдите под своей учетной записью.
На верхней панели слева нажмите
 и убедитесь в том, что сервис Notebooks в разделе AI Factory подключен.
Если сервис Notebooks не подключен, оставьте заявку на подключение.
и убедитесь в том, что сервис Notebooks в разделе AI Factory подключен.
Если сервис Notebooks не подключен, оставьте заявку на подключение.
1. Подготовьте среду
Для хранения данных создайте бакет в Object Storage. Укажите класс хранения Стандартный.
Создайте ноутбук со следующими параметрами:
Конфигурация — ncpu.medium.4.
Образ — Cloud.ru Jupyter N8n.
После создания ноутбука на главной странице сервиса Notebooks в строке нужного ноутбука нажмите JupyterLab.
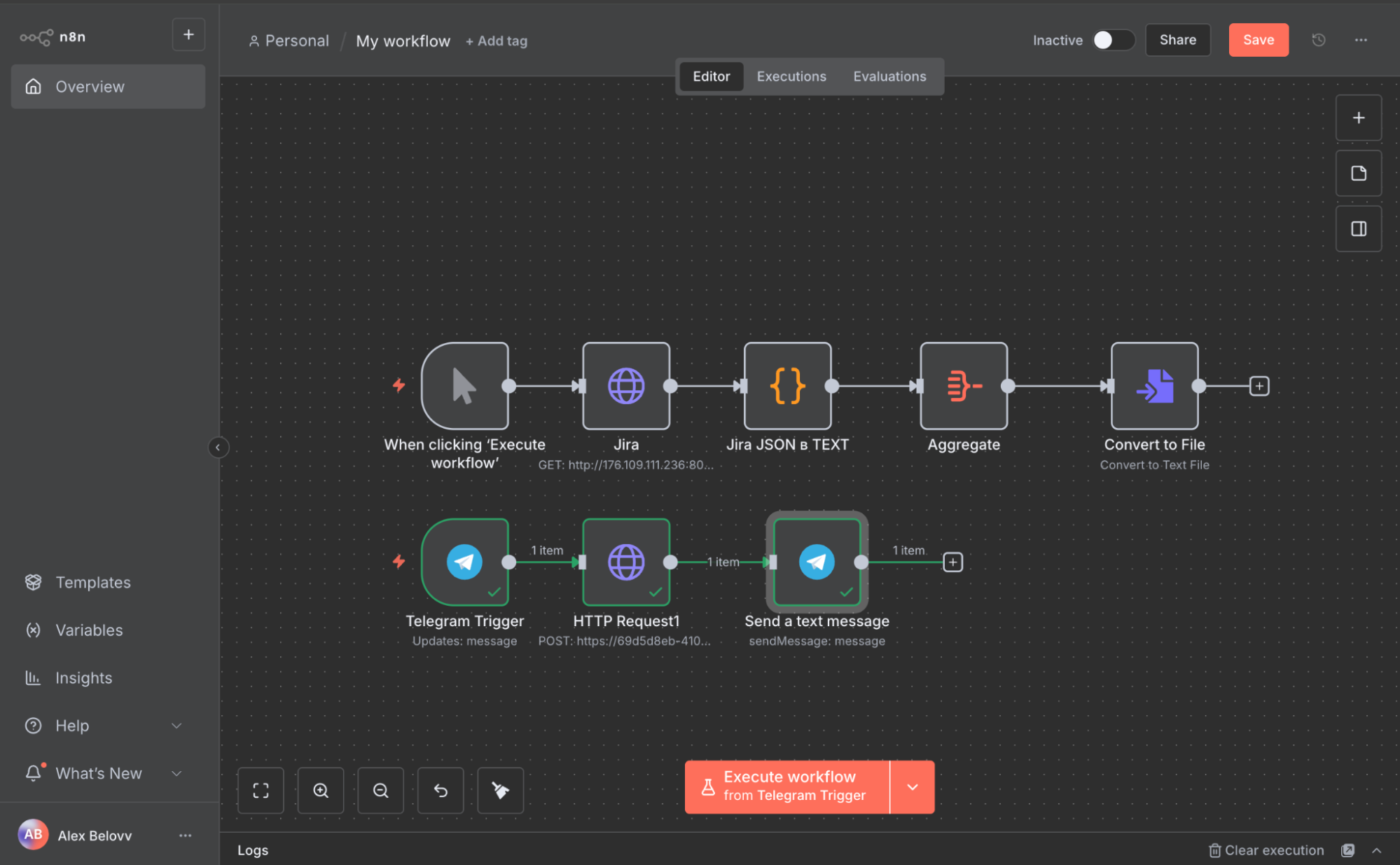
2. Настройте воркфлоу в N8N для парсинга Jira
На этом шаге вы настроите воркфлоу в N8N для извлечения данных из Jira и преобразования их в текстовый файл.
На главной странице JupyterLab в разделе Other нажмите на N8N.
Дождитесь загрузки сервиса.
Пройдите регистрацию и нажмите Next.
(Опционально) Заполните следующую форму и нажмите Get started.
Нажмите Create Workflow.
Нажмите Add first step.
Выберите триггер Trigger manually.
Добавьте ноду HTTP Request со следующими параметрами:
Method: GET
URL: http://<jira_ip>/rest/api/2/search?jql=&maxResults=1000
Где <jira_ip> — IP-адрес вашего Jira-сервера.
Authentication: Authentication
Generic Auth Type: Basic Auth
Добавьте credentials — логин и пароль от аккаунта в Jira.
Добавьте справа ноду Code, указав Language — JavaScript.
В ноду Code добавьте код:
let rows = [];for (const item of items) {if (!item.json || !Array.isArray(item.json.issues)) continue;for (const issue of item.json.issues) {let id = issue.id ?? '';let key = issue.key ?? '';let desc = issue.fields?.description ?? '';let creator = issue.fields?.creator?.name ?? '';rows.push([id, key, desc, creator].join(','));}}return [{ json: { text: rows.join('\n\n') } }];Добавьте справа ноду Aggregate.
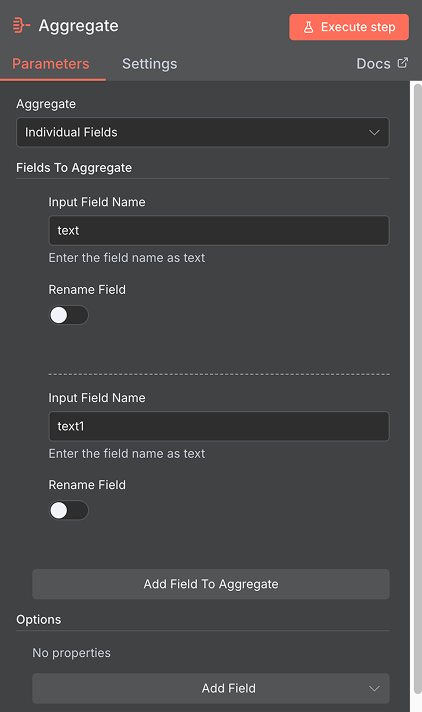
Добавьте ноду Convert to File со следующими параметрами:
Operation: Convert to Text File
Text Input Field: text
Put Output File in Field: data

В результате вы получите файл, в котором будет находиться текстовая выжимка из полей description, id, key, creator.
Добавьте полученный файл в бакет Object Storage, созданный при подготовке среды.


Вы можете продумать, какие поля вам нужны, как лучше расположить данные в файле. В этом практическом руководстве приведен пример для реализации быстрого старта.
3. Создайте базу знаний и получите токен доступа
На этом шаге вы создадите базу знаний в сервисе Managed RAG на основе данных, полученных из Jira.
В личном кабинете перейдите в сервис AI → Managed RAG.
Нажмите Создать базу знаний.
Укажите путь к папке в бакете Object Storage, созданном при подготовке среды. Для обработки ваших файлов будет создан сервисный аккаунт.
Выберите расширение загруженных файлов.
Активируйте опцию Вручную настроить обработку документов и модель.
Включите аутентификацию и выберите сервисный аккаунт, созданный при подготовке среды.
Нажмите Продолжить.
Укажите настройки для экстракторов — парсеры, которые извлекают содержимое из файлов выбранного типа.
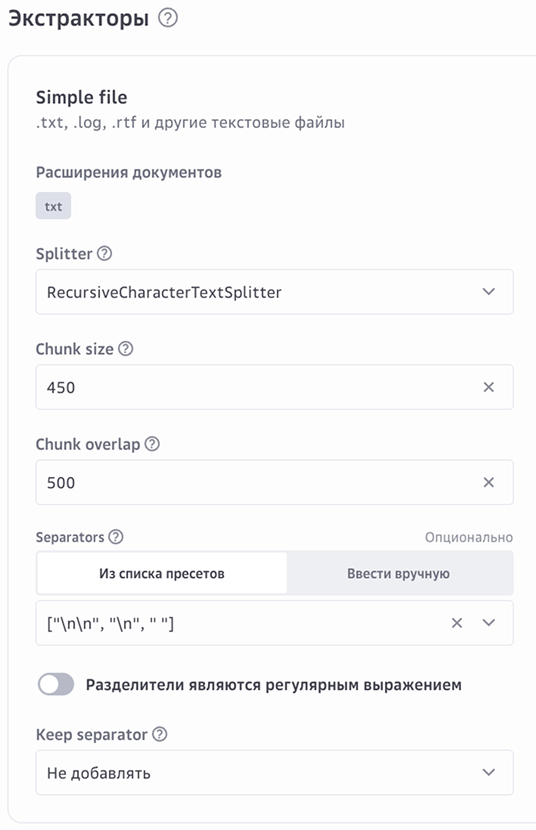
Нажмите Продолжить.
Выберите модель, которая преобразует содержимое документов в векторное представление, например, Qwen/Qwen3-Embedding-0.6B.
Нажмите Создать.
Вы будете перенаправлены на страницу сервиса Managed RAG. База знаний будет создана и запущена в течение нескольких минут. Дождитесь, когда база знаний перейдет в статус «Активная» и появится публичный URL-адрес.
Скопируйте полученный токен — значение из поля access token.

4. Настройте Telegram-бота для взаимодействия с RAG
На этом шаге вы создадите Telegram-бота и настроите его взаимодействие с базой знаний через Managed RAG.
Зарегистрируйте бота в Telegram:
В Telegram найдите бота BotFather.
Выполните команду /newbot.
Задайте имя (name) и имя пользователя (username) для бота. Имя пользователя должно заканчиваться на «Bot» или «_bot».
Сохраните токен бота, который предоставит BotFather.
Убедитесь, что в Telegram созданный бот отображается в результатах поиска по имени.
Вернитесь в N8N и в том же воркфлоу выберите Telegram Trigger: Updates message.
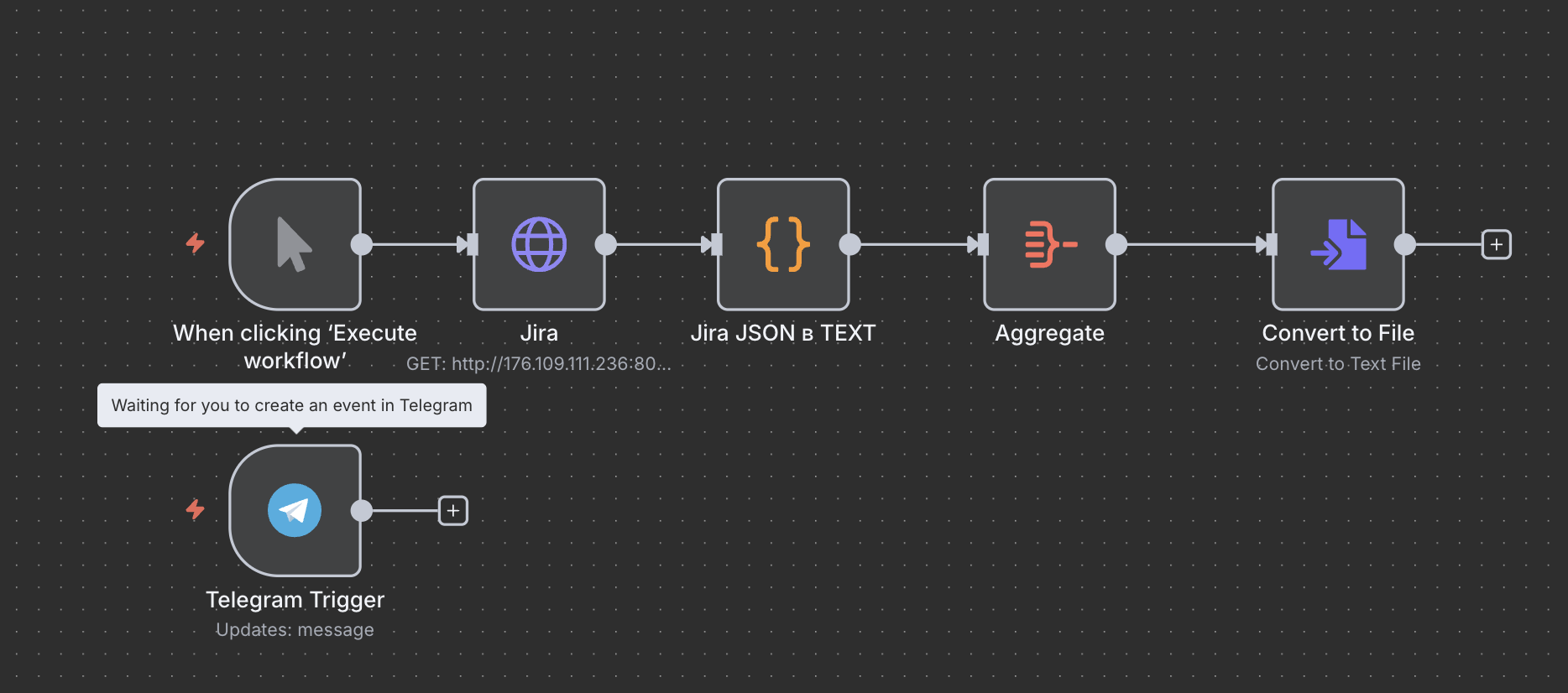
Создайте credentials, вставив токен вашего бота.

Проверьте работоспособность webhook.
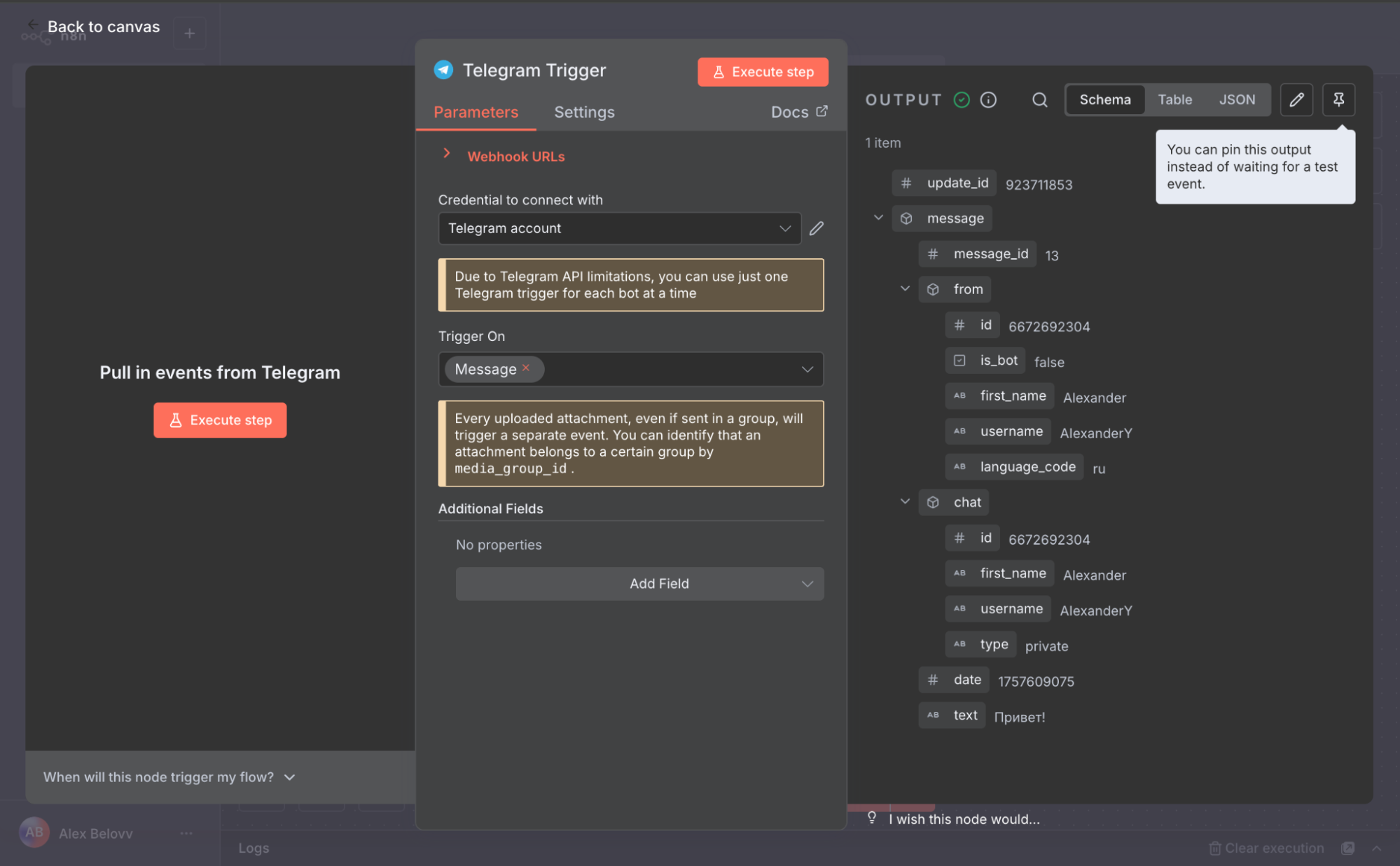
Добавьте ноду HTTP Request со следующими параметрами:
Method: POST
URL: перейдите в Managed RAG → Название вашей базы знаний → API и скопируйте URL после слова «POST».
Выберите один из методов:
retrieve — если нужны только ссылки.
retrieve_generate — если нужен быстрый ответ и точность не важна.
retrieve_rerank — когда важна точность ранжирования.
retrieve_rerank_generate — точность ранжирования + готовый ответ.
ПримерДобавьте код в формате JSON:
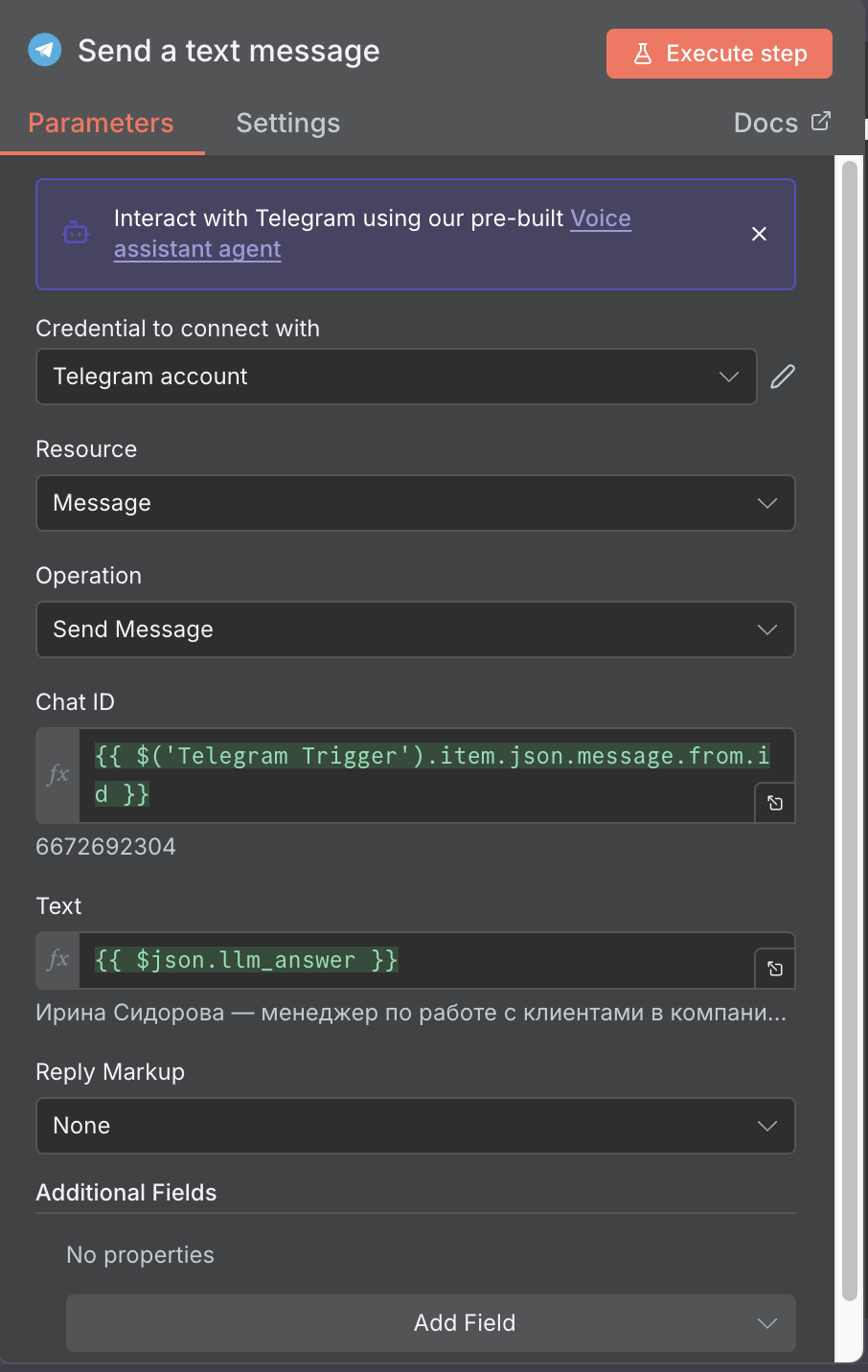
{"project_id": "<project_id>","query": "{{ $json.message.text }}","llm_settings": {"model_settings": {"model": "openai/gpt-oss-120b"},"system_prompt": "Вы полезный помощник, который отвечает на вопросы, основываясь на предоставленном контексте.","temperature": 1},"retrieve_limit": 3,"n_chunks_in_context": 3,"rag_version": "<your_rag_version>"}Где:
<project_id> — идентификатор вашего проекта.
<your_access_token> — токен доступа, полученный ранее.
<your_rag_version> — версия RAG из вкладки Информация о версии.
Подробнее о параметрах — в документации Managed RAG.
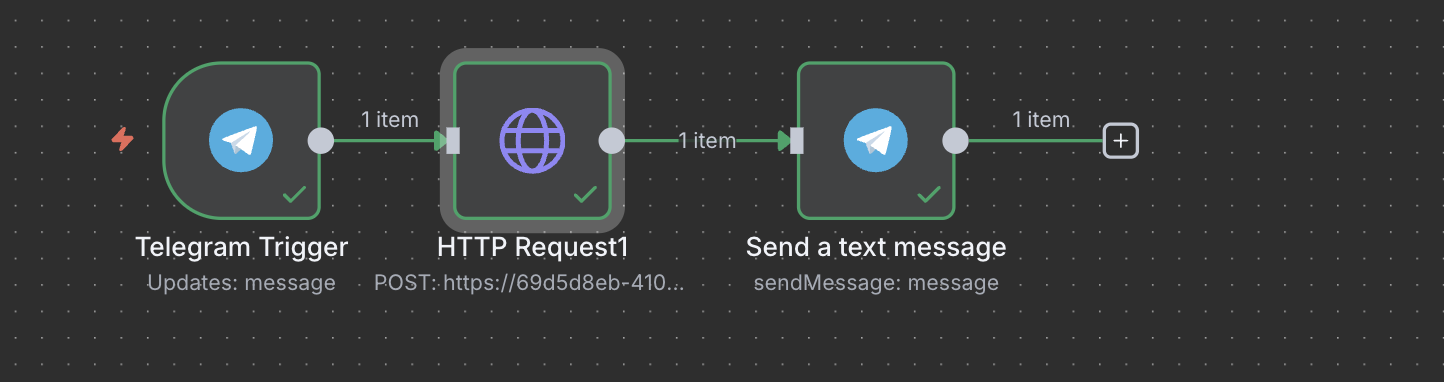
Отправьте запрос и убедитесь, что получаете корректный ответ от сервиса.
Добавьте ноду Telegram send message.
В правом верхнем углу установите переключатель в положение Activate.

Теперь вы можете получать релевантные ответы по своей базе знаний интерактивно прямо в Telegram.
Например, нас интересует информация о деятельносты Ирины Сидоровой. Такой правильный ответ мы получаем.

Результат
В ходе лабораторной работы вы создали LOW-Code RAG-систему на базе данных из Jira, настроили воркфлоу в N8N для извлечения данных, создали базу знаний в Managed RAG и разработали Telegram-бота для интерактивного взаимодействия с информацией.