С помощью этого руководства вы научитесь использовать сервис Managed Spark для обработки таблиц формата Delta Lake.
Вы построите витрину данных, отражающую полную информацию о клиентах и их пути, сохраните результат в формате Delta Lake и выгрузите историю изменений таблицы в логи.
Вы будете использовать следующие сервисы:
Managed Spark — сервис, который позволяет развернуть кластерное вычислительное решение на основе Apache Spark для распределенной обработки данных.
Object Storage — объектное S3-хранилище с бесплатным хранением файлов объемом до 15 ГБ.
Шаги:
Перед началом работы
Зарегистрируйтесь в личном кабинете Cloud.ru. Если вы уже зарегистрированы, войдите под своей учетной записью.
Создайте бакет Object Storage, в котором будут храниться необходимые файлы и логи.
Скачайте и установите root-сертификат на устройство.
Создайте кластер Data Platform, в котором будет размещен инстанс.
Создайте пароль и добавьте его в Secret Management. Этот секрет станет паролем для доступа к интерфейсу Managed Spark.
Создайте публичный SNAT-шлюз для доступа инстанса к внешним источникам.
Сверьте совместимость версий Spark и Delta Lake.
1. Подготовьте файл CSV
На этом шаге вы загрузите в хранилище Object Storage файлы с данными для обработки.
Скачайте CSV-таблицу delta-table.csv: нажмите Скачать в правом верхнем углу.
В ранее созданном бакете Object Storage создайте папку input.
Загрузите CSV-таблицу в папку input.
2. Подготовьте скрипт задачи
На этом шаге вы загрузите в хранилище Object Storage файл, содержащий скрипт для обработки данных из CSV-таблицы.
Скопируйте скрипт и назовите файл delta-script.py.
import timefrom pyspark.sql import SparkSessionfrom pyspark.sql.types import DoubleType, FloatType, LongType, StructType,StructField, StringTypefrom delta import *spark = (SparkSession.builder.appName('Delta test').enableHiveSupport().getOrCreate())SCHEMA = StructType([StructField("vendor_id", LongType(), True),StructField("trip_id", LongType(), True),StructField("trip_distance", FloatType(), True),StructField("fare_amount", DoubleType(), True),StructField("store_and_fwd_flag", StringType(), True)])TABLE_TIME = time.strftime('%Y_%m_%d__%H_%M_%S')TABLE_NAME = "delta_lab" + TABLE_TIMEROOT_PATH = "s3a://your-bucket-name/"CSV_PATH = ROOT_PATH + "input/delta-table.csv"FULL_PATH_DELTA_TABLE = ROOT_PATH + "warehouse_delta/" + TABLE_NAMEdef read_csv_to_table():_csv_df = (spark.read.option("delimiter", ";").option("header", True).csv(CSV_PATH, schema=SCHEMA))_csv_df.show()return _csv_dfdef insert_data_to_table(df):df.write.format("delta").save(FULL_PATH_DELTA_TABLE)def read_data_from_table():df = spark.read.format("delta").load(FULL_PATH_DELTA_TABLE)df.show()def update_delta_table():delta_table = DeltaTable.forPath(spark, FULL_PATH_DELTA_TABLE)delta_table.update(condition="vendor_id % 2 = 0",set={"trip_distance": "trip_distance + 2"})def show_history_delta():delta_table = DeltaTable.forPath(spark, FULL_PATH_DELTA_TABLE)history = delta_table.history()history.show()def read_specific_version_delta(version: int):df = spark.read.format("delta").option("versionAsOf", version).load(FULL_PATH_DELTA_TABLE)df.show()if __name__ == "__main__":csv_df = read_csv_to_table()insert_data_to_table(df=csv_df)read_data_from_table()update_delta_table()read_data_from_table()update_delta_table()read_data_from_table()show_history_delta()read_specific_version_delta(version=1)spark.stop()В строке ROOT_PATH = "s3a://your-bucket-name/" скрипта замените your-bucket-name на название бакета Object Storage.
В ранее созданном бакете Object Storage создайте папку jobs.
Загрузите скрипт в папку jobs.
В результате получится следующая структура бакета с файлами:
<bucket>
input
delta-table.csv
jobs
delta-script.py
3. Создайте задачу Managed Spark
На этом шаге вы создадите задачу Managed Spark с использованием подготовленного скрипта.
Для продолжения работы убедитесь, что статус инстанса Managed Spark изменился на «Готов».
Перейдите в сервис Managed Spark.
Откройте созданный ранее инстанс.
Перейдите на вкладку Задачи.
Нажмите Создать задачу.
В блоке Общие параметры введите название задачи, например delta.
В блоке Образ выберите базовый образ Spark-3.5.0.
В блоке Скрипт приложения:
В поле Тип запускаемой задачи выберите Python.
В поле Путь к запускаемому файлу укажите путь к файлу delta-script.py. В данном случае путь s3a://{bucket_name}/jobs/delta-script.py, где {bucket_name} — название созданного бакета Object Storage.
В блоке Настройки активируйте опцию Добавить Spark-конфигурацию (–conf). Добавьте следующие параметры и их значения:
Параметр
Значение
spark.jars.packages
io.delta:delta-spark_2.12:3.2.0
spark.sql.extensions
io.delta.sql.DeltaSparkSessionExtension
spark.sql.catalog.spark_catalog
org.apache.spark.sql.delta.catalog.DeltaCatalog
spark.log.level
ERROR
Нажмите Создать.
Задача Managed Spark начнет выполняться и отобразится на странице инстанса на вкладке Задачи.
4. Наблюдайте за ходом выполнения задачи
На этом шаге вы будете наблюдать за ходом выполнения задачи, просматривая информацию, поступающую в логи.
Вы можете посмотреть логи задачи, когда задача находится в статусах «Выполняется» и «Готово», то есть как в процессе выполнения, так и по завершению задачи.
Перейдите к логам
В строке задачи нажмите
 и выберите Перейти к логам.
и выберите Перейти к логам.Используйте фильтр, чтобы найти логи, например, за определенное время.
Перейдите в Spark UI
Откройте инстанс Managed Spark.
Во вкладке Задачи нажмите Spark UI. В соседней вкладке откроется интерфейс Spark UI.
Вернитесь в инстанс и откройте вкладку Информация.
Скопируйте данные из блока Настройки доступа.
Введите данные инстанса:
Username — значение поля Пользователь.
Password — значение секрета в поле Пароль.
В интерфейсе Spark UI вы найдете информацию о ходе выполнения задачи.
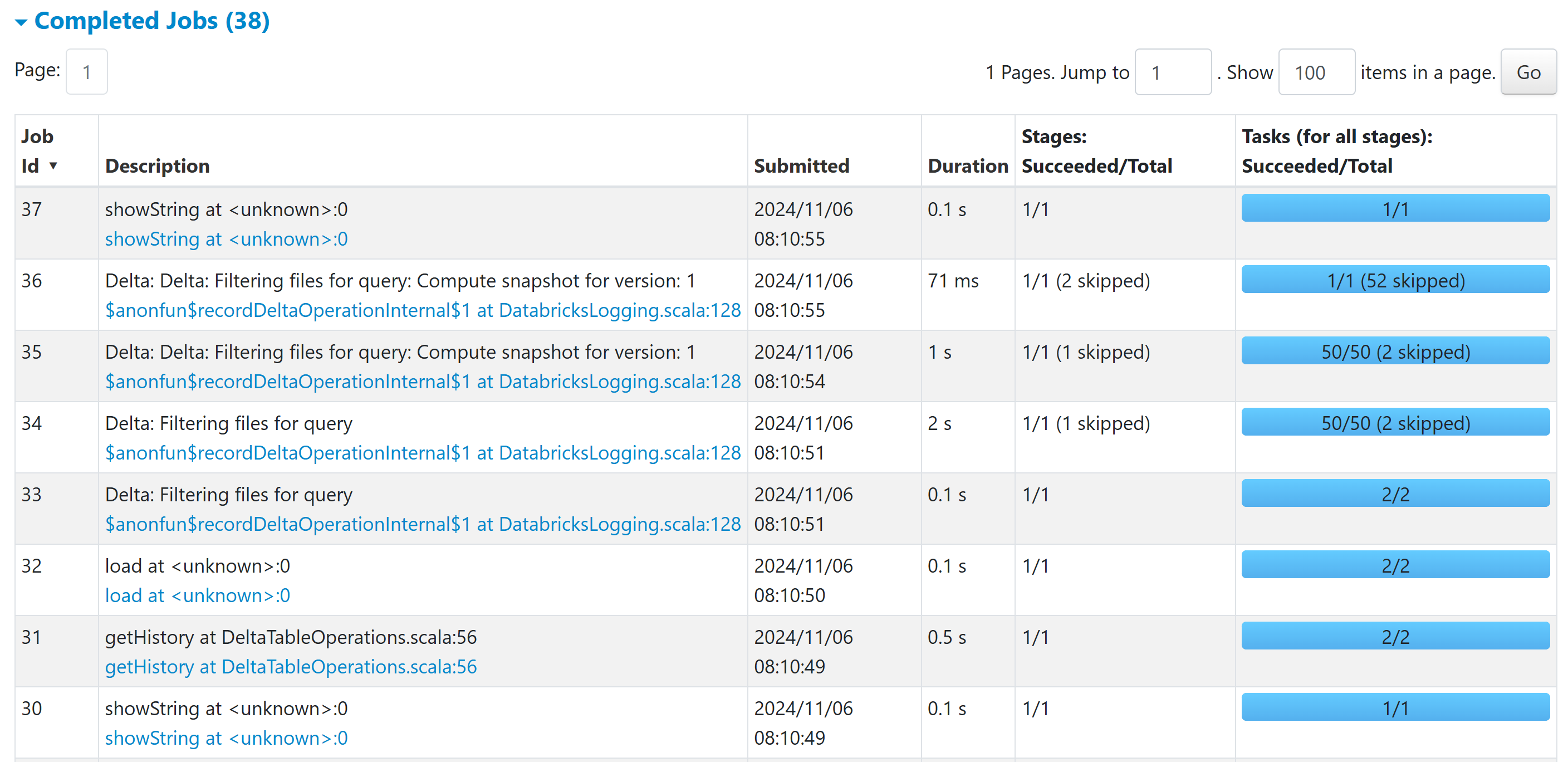
Результат
Когда задача перейдет в статус «Выполнено», откройте бакет Object Storage. В бакете появится новая папка с названием формата delta-lab_<TIME_STAMP>. В этой папке хранятся:
версии таблицы «delta-table.csv»;
папка _delta_log с логами задачи.
Чтобы посмотреть историю изменений таблицы с помощью метода history():
Откройте сервис Managed Spark.
Перейдите на вкладку Задачи.
Скопируйте ID задачи.
Нажмите
и выберите Перейти к логам.В поле Запрос введите labels.spark_job_id="ID", где ID — идентификатор задачи, скопированный ранее.
Нажмите Скачать журнал логов.
Выберите формат файла.
Нажмите Скачать.
Откройте скачанный файл.
История изменений отображается в нескольких сообщениях.
Вы обработали таблицу формата Delta Lake с помощью сервиса Managed Spark и просмотрели информацию об изменениях в таблице.