С помощью этого руководства вы настроите чтение сообщений из топика Managed Kafka и отображение полученных данных в логах задачи Managed Spark. Вы создадите две задачи Managed Spark c использованием скриптов для разового и для непрерывного чтения данных.
В результате вы получите возможность просматривать сообщения из топиков Managed Kafka в логах задачи Managed Spark.
Вы будете использовать следующие сервисы:
Managed Spark — сервис, который позволяет развернуть кластерное вычислительное решение на основе Apache Spark для распределенной обработки данных.
Object Storage — объектное S3-хранилище с бесплатным хранением файлов объемом до 15 ГБ.
Managed Kafka — сервис для развертывания и управления кластерами Apache Kafka®.
Шаги:
Перед началом работы
Зарегистрируйтесь в личном кабинете Cloud.ru. Если вы уже зарегистрированы, войдите под своей учетной записью.
Создайте бакет Object Storage, в котором будут храниться необходимые файлы и логи.
Скачайте и установите root-сертификат на устройство.
Создайте кластер Data Platform, в котором будет размещен инстанс.
Создайте пароль и добавьте его в Secret Management. Этот секрет станет паролем для доступа к интерфейсу Managed Spark.
Убедитесь, что в проекте, где будет запускаться задача Managed Spark, доступен сервис Managed Kafka.
Создайте кластер Managed Kafka. На шаге Сетевые настройки в списке Подсеть выберите подсеть, указанную при создании инстанса Managed Spark.
Подключитесь к кластеру Managed Kafka и отправьте несколько сообщений в топик.
1. Подготовьте скрипт задачи
На этом шаге вы загрузите в хранилище Object Storage файлы, содержащие скрипты для чтения топика Managed Kafka. Скрипт из файла kafka_spark.py выполняет однократное чтение сообщений из топика, а скрипт из файла kafka_spark_streaming.py — непрерывное.
Скопируйте скрипт и назовите файл kafka_spark.py.
from pyspark.sql import SparkSessionimport oskafka_user = os.environ["KAFKA_USER"]kafka_pass = os.environ["KAFKA_PASS"]kafka_topic = os.environ["KAFKA_TOPIC"]kafka_server = os.environ["KAFKA_SERVER"]spark = SparkSession.builder.appName("kafka").getOrCreate()df = (spark.read.format("kafka").option("kafka.bootstrap.servers", kafka_server).option("kafka.security.protocol", "SASL_PLAINTEXT").option("kafka.sasl.mechanism", "SCRAM-SHA-512").option("kafka.sasl.jaas.config",f'org.apache.kafka.common.security.scram.ScramLoginModule required username="{kafka_user}" password="{kafka_pass}";',).option("subscribe", kafka_topic).option("startingOffsets", "earliest").option("endingOffsets", "latest").load())df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")df.show(truncate=False)spark.stop()Скопируйте скрипт и назовите файл kafka_spark_streaming.py.
from pyspark.sql import SparkSessionimport oskafka_user = os.environ["KAFKA_USER"]kafka_pass = os.environ["KAFKA_PASS"]kafka_topic = os.environ["KAFKA_TOPIC"]kafka_server = os.environ["KAFKA_SERVER"]spark = (SparkSession.builder.appName("kafka").getOrCreate())df = (spark.readStream.format("kafka").option("kafka.bootstrap.servers", kafka_server).option("kafka.security.protocol", "SASL_PLAINTEXT").option("kafka.sasl.mechanism", "SCRAM-SHA-512").option("kafka.sasl.jaas.config",f'org.apache.kafka.common.security.scram.ScramLoginModule required username="{kafka_user}" password="{kafka_pass}";',).option("subscribe", kafka_topic).option("startingOffsets", "earliest").load())df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")console = (df.writeStream.outputMode('append').format('console').start())console.awaitTermination()spark.stop()Откройте ранее созданный бакет Object Storage.
Загрузите файлы со скриптами.
2. Создайте задачу Managed Spark
На этом шаге вы создадите задачу Managed Spark с использованием подготовленного скрипта. Скрипт выполнит чтение сообщений, отправленных в топик Managed Kafka, и выведет данные из них в логи задачи Managed Spark.
Для продолжения работы убедитесь, что статус инстанса Managed Spark изменился на «Готов».
Перейдите в сервис Managed Spark.
Откройте созданный ранее инстанс.
Перейдите на вкладку Задачи.
Нажмите Создать задачу.
В блоке Общие параметры введите название задачи, например kafka-spark-streaming.
В блоке Образ выберите базовый образ Spark-3.5.0.
В блоке Скрипт приложения:
В поле Тип запускаемой задачи выберите Python.
В поле Путь к запускаемому файлу укажите путь к файлу kafka_spark.py.
В блоке Настройки активируйте опцию Добавить параметры окружения. Добавьте следующие параметры и их значения:
Параметр
Значение
KAFKA_USER
Имя для подключения к кластеру Managed Kafka, заданное при создании пользователя, например, cloud-admin.
KAFKA_PASS
Пароль для подключения к кластеру Managed Kafka, заданный при создании пользователя.
KAFKA_TOPIC
Имя топика Managed Kafka.
KAFKA_SERVER
Адрес кластера в формате ip:port, где ip — внутренний IP-адрес кластера Managed Kafka, port— порт кластера Managed Kafka.
Чтобы узнать внутренний IP-адрес и порт, откройте сервис Managed Kafka в отдельной вкладке, в списке кластеров нажмите на название созданного ранее кластера и перейдите в блок Данные для подключения.
В блоке Настройки активируйте опцию Добавить Spark конфигурацию (–conf).
В поле Аргумент укажите spark.jars.packages.
В поле Значение укажите org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.0.
Нажмите Создать.
Задача Managed Spark начнет выполняться и отобразится на странице инстанса на вкладке Задачи.
3. Проверьте логи
На этом шаге вы проверите логи задачи Managed Spark и отображение в них данных из топика Managed Kafka.
Для продолжения работы убедитесь, что статус задачи Managed Spark изменился на «Завершена».
В строке задачи нажмите
 и выберите Перейти к логам.
и выберите Перейти к логам.Используйте фильтр, чтобы найти логи, содержащие сообщения из топика Managed Kafka.
Пример данных, полученных из топика Managed Kafka:
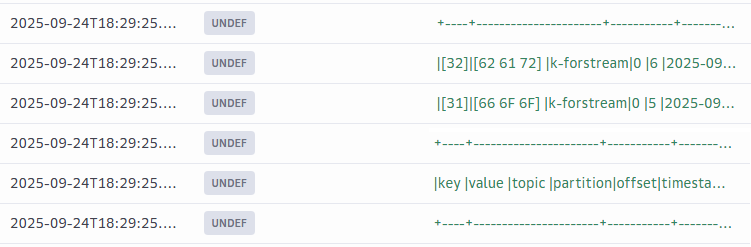
4. Запустите непрерывное чтение топика Managed Kafka
На этом шаге вы создадите вторую задачу Managed Spark с использованием скрипта, который будет непрерывно поддерживать соединение с топиком Managed Kafka и выполнять чтение поступающих в него сообщений.
В строке задачи Managed Spark, выполненной ранее, нажмите
и выберите Скопировать задачу.В блоке Скрипт приложения в поле Путь к запускаемому файлу укажите путь к файлу kafka_spark_streaming.py.
Нажмите Создать.
Дождитесь, пока статус задачи изменится на «Выполняется».
В строке задачи нажмите
и выберите Перейти к логам.Используйте фильтр, чтобы найти логи, содержащие сообщения из топика Managed Kafka. Если в топик Managed Kafka не поступают новые данные, в логах будут только отправленные ранее сообщения и информация об ожидании.
Отправьте новое сообщение в топик Managed Kafka.
Посмотрите в логах задачи Managed Spark информацию о новом сообщении.
Задача Managed Spark c данными параметрами будет выполняться, пока вы ее не завершите. Чтобы завершить задачу, в строке задачи нажмите
и выберите Остановить.
Результат
Вы настроили чтение сообщений из топика Managed Kafka и вывод полученных данных в логи задачи Managed Spark с помощью скриптов.