С помощью быстрого старта вы создадите инференс модели на основе готовой модели из каталога. Также вы можете создать инференс на основе модели из библиотеки Hugging Face с помощью Model RUN и на основе Docker-образа в Docker Run.
При выборе модели и настройке конфигурации автоматически рассчитывается и отображается стоимость использования выбранной модели.
Для инференса с помощью готовой модели:
Если у вас уже есть сервисный аккаунт, переходите к выбору модели и запуску инференса.
Перед началом работы
Зарегистрируйтесь в личном кабинете Cloud.ru.
Если вы уже зарегистрированы, войдите под своей учетной записью.
На верхней панели слева нажмите
 и убедитесь в наличии сервиса ML Inference в разделе AI Factory.
Если сервиса нет в списке, обратитесь в техническую поддержку.
и убедитесь в наличии сервиса ML Inference в разделе AI Factory.
Если сервиса нет в списке, обратитесь в техническую поддержку.
Шаг 1. Создайте сервисный аккаунт
Сервисный аккаунт будет использоваться для авторизации. Вы можете создать сервисный аккаунт через личный кабинет или использовать уже созданный.
На верхней панели слева нажмите
и перейдите в раздел Пользователи, на вкладку Сервисные аккаунты.
В правом верхнем углу нажмите Создать аккаунт.
Задайте для сервисного аккаунта название и описание.
Нажмите Продолжить.
Назначьте роль на проект «Администратор проекта».
Роль определяет права доступа сервисного аккаунта.
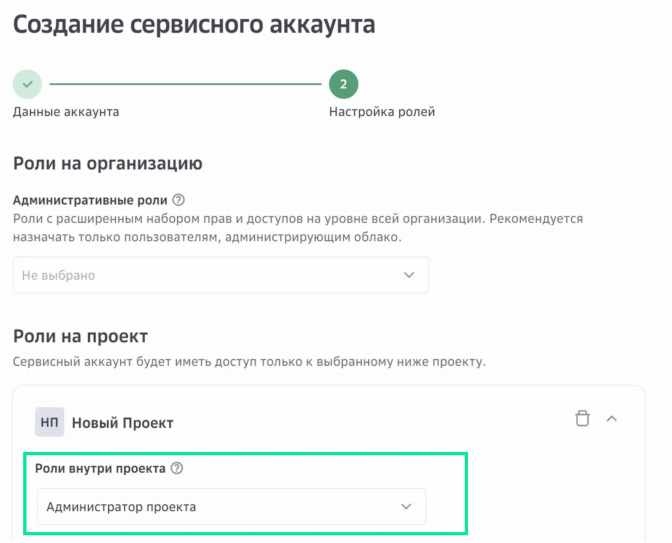
Нажмите Создать.

Шаг 2. Выберите модель и запустите инференс
На верхней панели слева нажмите
и перейдите в раздел AI Factory → ML Inference.Выберите Каталог моделей. Откроется каталог готовых моделей.
Воспользуйтесь фильтрами для подбора модели:
Подборка — тип специализации модели — Code-generation.
Задачи — задача, которую модель должна выполнять — Generate.
Поставщик — разработчик модели — Qwen.
Цена — диапазон стоимости использования модели — от 100 до 500.
Модель GPU — видеокарта — GPU NVIDIA H100 SXM.
Параметры — диапазон количества обучаемых весов, определяющих сложность и мощность модели — 8B-70B.
Параметры — диапазон объема информации, которое модель может учитывать за один раз при генерации ответа — 8-131.
В карточке подходящей модели нажмите Быстрый запуск. Откроется окно с информацией по выбранной модели.
Заполните параметры быстрой настройки модели:
Модель GPU — выберите модель GPU, на которой модель будет работать.
Режим работы — выберите режим работы модели:
Всегда онлайн — модель будет всегда доступна.
Serverless (по запросу) — модель будет доступна при поступлении запроса, если запросов нет — модель автоматически выключается.
Нажмите Запустить модель.
Вы будете перенаправлены на страницу сервиса ML Inference. Инференс будет создан и запущен в течение нескольких минут. Дождитесь, когда инференс перейдет в статус «Запущен» и появится публичный URL-адрес.
Что дальше
После запуска готовой модели вы можете продолжить работу с инференсом в Model RUN.