Инференс модели запускается в контейнере, созданном на основе пользовательского Docker-образа, с помощью ресурсов GPU, предоставленных ML Inference. Вызвать модель можно через обращение к публичному URL-адресу контейнера с Docker-образом и команду входа. Публичный адрес генерируется автоматически при создании инференса в Docker RUN.
Тестовый вызов
Протестировать вызов модели можно в личном кабинете.
В личном кабинете перейдите в раздел AI Factory → ML Inference.
Выберите в меню слева Docker RUN.
Откройте меню
 напротив нужного инференса и выберите Тестировать.
напротив нужного инференса и выберите Тестировать.Откроется окно Docker-образа и отобразится вкладка Тестирование.
На вкладке Тестирование сформируйте запрос, в том числе определите:
метод запроса;
тело запроса;
параметры запроса;
заголовки запроса;
(Опционально) Чтобы передать содержание JSON-файла, включите опцию JSON-структура и введите код.
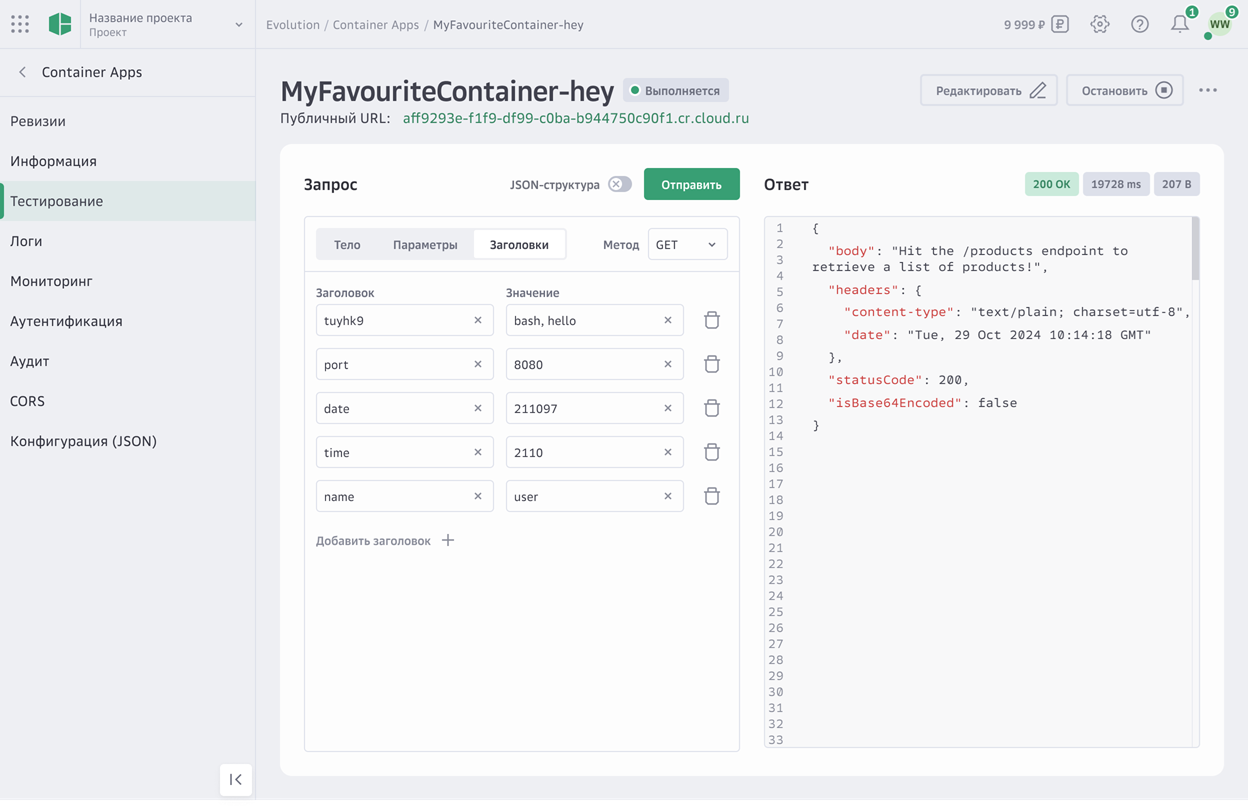
Нажмите Отправить.
Запуск Docker-образа
Запустить Docker-образ можно в личном кабинете.
В личном кабинете перейдите в раздел AI Factory → ML Inference.
Выберите в меню слева Docker RUN.
Откройте меню
напротив нужного инференса и выберите Запустить.
Контейнер, содержащий Docker-образ с пользовательской моделью, будет создан и запущен в течение нескольких минут. Дождитесь, когда инференс перейдет в статус «Запущен» и появится публичный URL-адрес.