Инференс модели запускается в облачном контейнере. Вызвать модель можно через HTTP-запрос с помощью публичного URL-адреса. Публичный адрес генерируется автоматически при создании инференса.
Тестовый вызов
Протестировать вызов модели можно в личном кабинете.
В личном кабинете перейдите в раздел AI Factory → ML Inference.
Выберите в меню слева Model RUN.
Откройте меню
 напротив нужного инференса и выберите Отправить запрос.
напротив нужного инференса и выберите Отправить запрос.Чтобы протестировать запрос, нажмите Отправить.
Тестовый вызов из OpenAPI
Отправить тестовый вызов можно на вкладке Model RUN → OpenAPI.
Вкладка OpenAPI содержит полную спецификацию API, которая автоматически подгружается с запущенного инстанса модели.
На вкладке OpenAPI вы можете:
ознакомиться с описанием эндпоинтов, параметров, моделей, запросов и ответов;
протестировать вызовы напрямую через встроенный Swagger UI.
Отправить тестовые запросы можно для инференса в статусе «Запущен».
Спецификация и набор доступных методов зависит от модели, выбранной при создании инференса.
Для отправки тестового запроса:
На верхней панели слева нажмите
 и перейдите ML Inference → Model RUN.
и перейдите ML Inference → Model RUN.Откройте инференс со статусом «Запущен».
Перейдите на вкладку OpenAPI.
Выберите метод. Например, POST/detokenize.
Скопируйте название инференса.
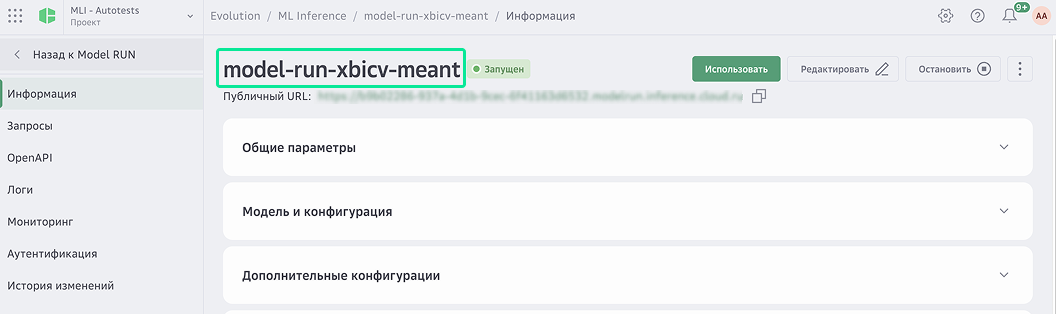
Вставьте название инференса в запрос.
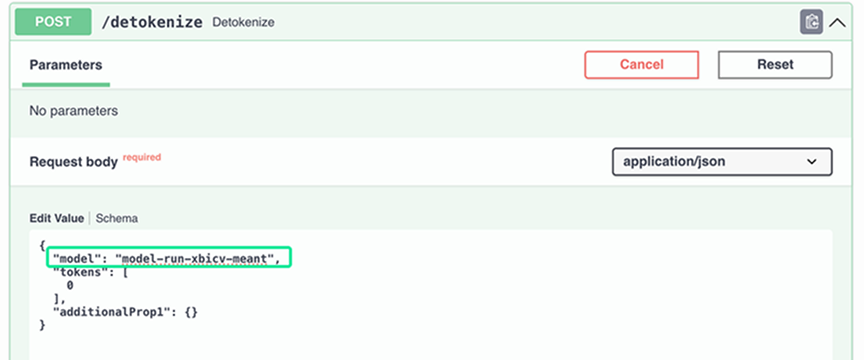
Нажмите Execute.
В результате вы получите ответ на тестовый запрос.
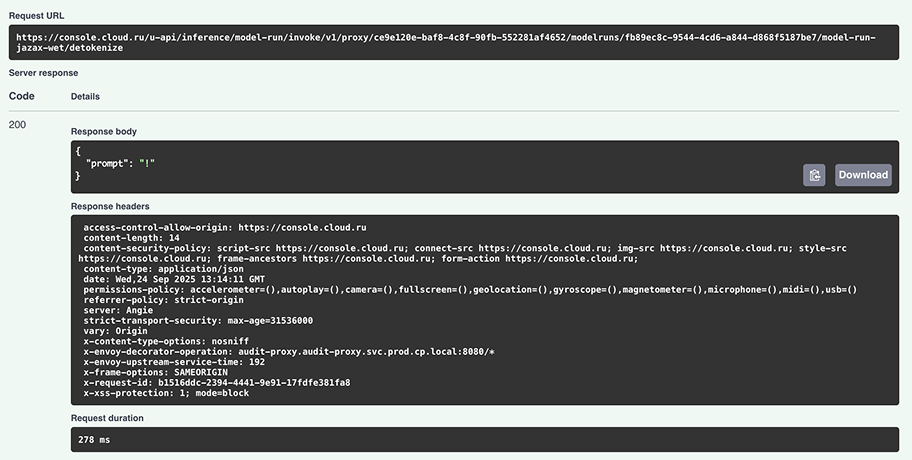
Коды ответов
API возвращает стандартные HTTP-коды ответов:
Код | Описание |
|---|---|
200 OK | Запрос успешно выполнен |
201 Created | Ресурс успешно создан |
400 Bad Request | Неверный формат запроса |
401 Unauthorized | Ошибка аутентификации |
403 Forbidden | Недостаточно прав |
404 Not Found | Ресурс не найден |
409 Conflict | Модель не запущена или недоступна |
429 Too Many Requests | Превышен лимит запросов |
500 Internal Server Error | Внутренняя ошибка сервера |