С помощью инструкции вы создадите инференс модели в сервисе ML Inference.
Для запуска инференса можно загрузить модель из библиотек Hugging Face, Ollama и репозитория Repo Model Registry.
Перед началом работы
Зарегистрируйтесь в личном кабинете Cloud.ru.
Если вы уже зарегистрированы, войдите под своей учетной записью.
На верхней панели слева нажмите
 и убедитесь в наличии сервиса ML Inference в разделе AI Factory.
Если сервиса нет в списке, обратитесь в поддержку.
и убедитесь в наличии сервиса ML Inference в разделе AI Factory.
Если сервиса нет в списке, обратитесь в поддержку.Для работы с моделью из Hugging Face убедитесь, что у вас есть:
аккаунт на Hugging Face;
Создание инференса
На верхней панели слева нажмите
и перейдите в раздел AI Factory → ML Inference.Выберите Model RUN.
Нажмите Создать.
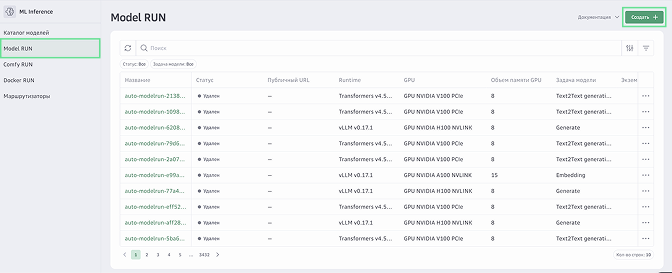
Поле Название инференса заполняется автоматически. Вы можете ввести другое название для нового инференса.
Выберите Runtime — среда запуска инференса модели для различных сценариев работы.
В зависимости от вашего выбора дальнейшие действия будут немного отличаться.
Transformers — библиотека, предоставляющая единый API для загрузки, токенизации и инференса сотен предобученных моделей‑трансформеров. Она подходит для широкого спектра задач, например, классификация текста, ответы на вопросы, суммаризация, машинный перевод и многие другие.
Выберите версию Transformers.
Доступная версия среды зависит от выбранной модели GPU.
Выберите модель GPU. Чтобы выбрать подходящий GPU, вам нужно оценить требования модели к вычислительным ресурсам: объем памяти и количество ядер. Рекомендуем начинать с менее мощного GPU и масштабировать ML-модели по мере необходимости.
Для выбора доступны:
GPU NVIDIA V100 PCIe
GPU NVIDIA H100 SXM
GPU NVIDIA A100 SXM
Выберите источник модели: Hugging Face или Model Registry.
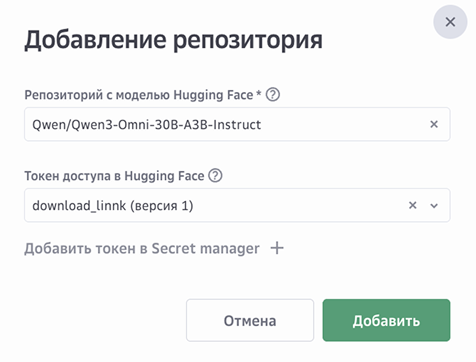
Нажмите Добавить из Hugging Face.
Укажите адрес репозитория в Hugging Face, в котором расположена модель.
Выберите токен доступа или создайте новый.
Нажмите Добавить.
(Опционально) Укажите версию и задачу для модели.
(Опционально) Добавьте LoRA-адаптер. Для добавления доступно 5 LoRA-адаптеров к основной модели. LoRA-адаптеры можно использовать с любой большой текстовой моделью, поддерживающей LoRA.
Укажите объем памяти GPU.
Нажмите Продолжить.
Укажите настройки масштабирования:
Выберите минимальное и максимальное количество экземпляров контейнера.
При минимальном количестве экземпляров «0» — модель работает в serverless-режиме и автоматически отключается при отсутствии запросов. При поступлении новых запросов модель запускается повторно.
Укажите время доступности модели при отсутствии нагрузки.
(Опционально) Чтобы модель всегда была доступна, включите опцию Не выключать модель.
Выберите тип масштабирования:
RPS — запросы в секунду на экземпляр, автомасштабирование начинается при достижении заданного лимита на количество запросов в секунду на экземпляр.
Сoncurrency — параллельные запросы на экземпляр, автомасштабирование начинается при достижении заданного лимита на количество одновременных запросов на экземпляр.
(Опционально) Чтобы модель принимала запросы только от указанного сервисного аккаунта, включите опцию Аутентификация. Подробнее об аутентификации в ML Inference.
Укажите лог-группу для ведения журнала запросов к модели.
Нажмите Создать.
Вы будете перенаправлены на страницу сервиса ML Inference. Инференс будет создан и запущен в течение нескольких минут. Дождитесь, когда инференс перейдет в статус «Запущен» и появится публичный URL-адрес.