В каталоге моделей представлена подборка моделей, готовых для запуска инференса. Вы можете выбрать модель под задачу любой сложности. Для выбора доступны разнообразные модели, такие как — Qwen, DeepSeek, Gemma и другие.
Модели из каталога запускаются в облачных контейнерах, без использования Docker-образов и необходимости написания кода инференса.
При выборе модели автоматически отображается стоимость ее использования. Более подробную информацию по тарификации использования моделей можно посмотреть в разделе Тарифы.
Для запуска модели:
Если у вас уже есть сервисный аккаунт, то переходите к выбору модели и запуску инференса.
Перед началом работы
Зарегистрируйтесь в личном кабинете Cloud.ru.
Если вы уже зарегистрированы, войдите под своей учетной записью.
На верхней панели слева нажмите
 и убедитесь в наличии сервиса ML Inference в разделе AI Factory.
Если сервиса нет в списке, обратитесь в техническую поддержку.
и убедитесь в наличии сервиса ML Inference в разделе AI Factory.
Если сервиса нет в списке, обратитесь в техническую поддержку.
Шаг 1. Создайте сервисный аккаунт
Сервисный аккаунт будет использоваться для авторизации. Вы можете создать сервисный аккаунт через личный кабинет или использовать уже созданный.
На верхней панели слева нажмите
и перейдите в раздел Пользователи, на вкладку Сервисные аккаунты.
В правом верхнем углу нажмите Создать аккаунт.
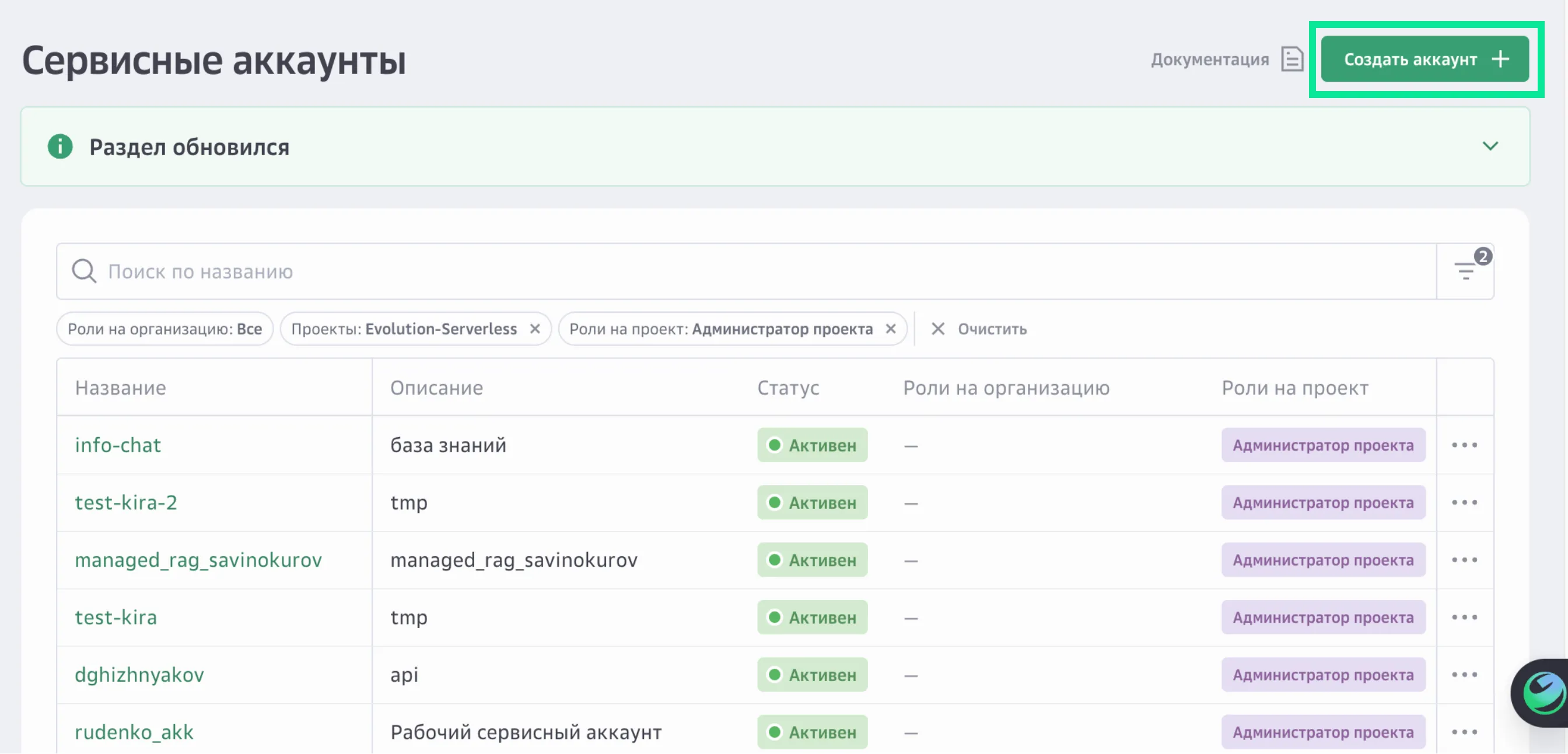
Задайте для сервисного аккаунта название и описание.
Нажмите Продолжить.
Назначьте роль на проект «Администратор проекта».
Роль определяет права доступа сервисного аккаунта.
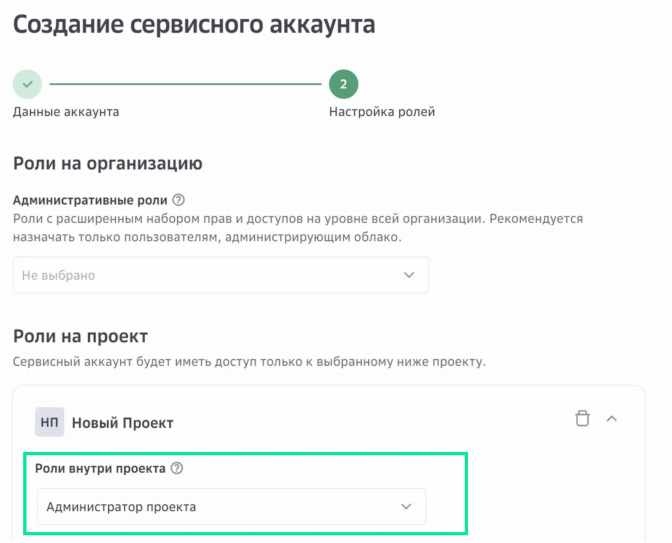
Нажмите Создать.

Шаг 2. Выберите модель и запустите инференс
На верхней панели слева нажмите
и перейдите в раздел AI Factory → ML Inference.Выберите Каталог моделей.
Воспользуйтесь фильтрами для подбора модели:
- Подборка — тип специализации модели.
Low-cost — модели, которые требуют мало вычислительных ресурсов: меньше памяти, быстрее работают, дешевле в использовании.
Instruction-following — модели, которые обучены следовать инструкциям, понимать и выполнять команды.
Русский язык — модели, которые хорошо понимают и генерируют текст на русском языке.
Code-generation — модели, которые умеют писать, читать и исправлять код на языках программирования: Python, JavaScript, C++, SQL и др.
Ассистенты — модели, которые умеют вести диалог, генерировать текст и помогать пользователю решать задачи.
Multi-language — модели, которые понимают и генерируют текст на многих языках, могут переключаться между языками и понимать смешанный текст.
Для выбора доступны:
Задачи — задача, которую модель должна выполнять.
Поставщик — разработчика модели, который предоставил готовую модель для использования.
Цена — диапазон стоимости использования модели.
Модель GPU — видеокарта, на которой будет работать модель.
Параметры — диапазон количества обучаемых весов в миллиардах, определяющих сложность и мощность модели.
Параметры — диапазон объема информации в токенах, которое модель может учитывать за один раз при генерации ответа, включая входной запрос и вывод.
Если по указанным критериям нет моделей, попробуйте их изменить.
Для запуска модели нажмите Быстрый запуск в карточке выбранной модели нажмите.
Для дополнительной настройки модели нажмите на карточку модели. Откроется окно с дополнительными настройками выбранной модели.
Заполните параметры быстрой настройки модели:
Модель GPU — выберите модель GPU, на которой модель будет работать.
Количество инстансов — укажите количество моделей, которые будут работать одновременно.
Режим работы — выберите режим работы модели:
Всегда онлайн — модель будет всегда доступна.
Serverless (по запросу) — модель будет доступна при поступлении запроса, если запросов нет — модель автоматически выключается.
(Опционально) Для аутентификации пользователя при вызове модели через публичный URL укажите сервисный аккаунт.
(Опционально) Укажите лог-группу для ведения журнала запросов к модели.
Выберите тип масштабирования и укажите допустимое количество запросов в секунду.
RPS — запросы в секунду на экземпляр, автомасштабирование начинается при достижении заданного лимита на количество запросов в секунду на экземпляр.
Сoncurrency — параллельные запросы на экземпляр, автомасштабирование начинается при достижении заданного лимита на количество одновременных запросов на экземпляр.
Нажмите Запустить модель.
Вы будете перенаправлены на страницу сервиса ML Inference. Инференс будет создан и запущен в течение нескольких минут. Дождитесь, когда инференс перейдет в статус «Запущен» и появится публичный URL-адрес.