Эта статья описывает принципы масштабирования инференса в зависимости от типа нагрузки и выбранной конфигурации. Использование механизмов масштабирования позволяет оптимизировать производительность и расход ресурсов.
Масштабирование инференса зависит от двух основных подходов:
Масштабирование по экземплярам и RPS — механизм масштабирования, при котором количество экземпляров контейнера автоматически регулируется в зависимости от текущей нагрузки.
Масштабирование по длине очереди — применяется в сценариях с асинхронной обработкой задач, например, при использовании Comfy UI. В этом случае количество контейнеров определяется объемом накопленных задач в очереди.
Масштабирование по экземплярам и RPS
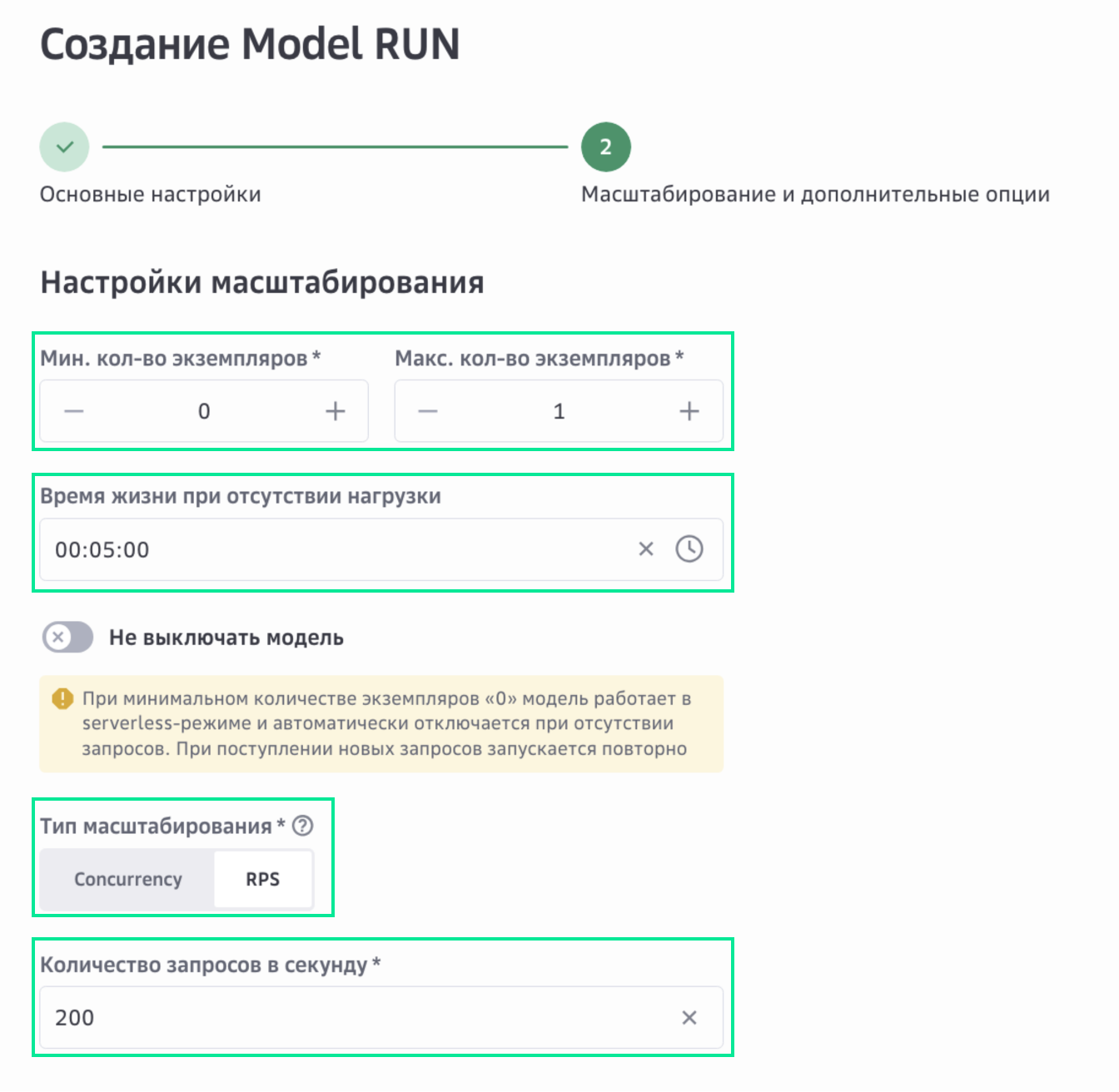
Масштабирование задается при создании инференса и зависит параметров:
минимальное и максимальное количество экземпляров контейнера;
время жизни при отсутствии нагрузки;
тип масштабирования;
количество запросов в секунду (порог масштабирования).
Работа и тарификация инференса отличается в зависимости от этих параметров.
Количество экземпляров больше нуля
Когда минимальное количество экземпляров больше нуля, указанное число экземпляров модели постоянно работает. Эти экземпляры предварительно загружены в память и готовы к обработке запросов.
Ресурсы для минимальных экземпляров тарифицируются непрерывно, независимо от текущей нагрузки. Это гарантирует постоянную доступность сервиса, но требует стабильных вычислительных затрат.
В качестве примера рассмотрим конфигурацию с min_replicas = 1 и порогом масштабирования 200 RPS (количество запросов в секунду). В этом случае один экземпляр модели всегда активен и потребляет ресурсы. Когда нагрузка превышает 200 RPS, система автоматически создает второй экземпляр для распределения запросов.
Если нагрузка снижается, например до 150 RPS или при полном отсутствии запросов, второй экземпляр уничтожается. При этом первый экземпляр сохраняет рабочее состояние вне зависимости от уровня нагрузки.
Количество экземпляров равно нулю
При минимальном количестве экземпляров равном нулю, отключенной опции Не выключать модель и отсутствии запросов дольше времени жизни модели — модель удаляется.
При поступлении новых запросов экземпляр модели создается из кеша и отвечает на запрос, происходит старт модели. В течение времени, когда нет запущенных экземпляров, инференс не тарифицируется.
Масштабирование по длине очереди
Масштабирование по длине очереди автоматически регулирует количество контейнеров обработки в зависимости от количества задач в очереди.
Все входящие задачи накапливаются в очереди. Каждый контейнер берет задачи из очереди по мере освобождения. При превышении установленного порога создается новый контейнер.
Количество контейнеров расчитывается по формуле:
Количество контейнеров = ceil(всего задач / длина очереди на контейнер)
При длине очереди, равной 10, и наличии 27 задач в очереди система автоматически создаст 3 контейнера:
1 — задачи 1 – 10.
2 — задачи 11 – 20.
3 — задачи 21 – 27.
После завершения обработки задачи удаляются из очереди. При снижении нагрузки система автоматически уменьшает количество активных контейнеров, обеспечивая эффективное использование вычислительных ресурсов и минимизацию операционных затрат.