Hudi — это формат таблицы data lake, который предоставляет возможность обновлять и удалять данные, а также потреблять новые данные в HDFS. Он поддерживает несколько вычислительных движков и предоставляет интерфейсы вставки, обновления и удаления (IUD) и потоковые примитивы, включая upsert и инкрементный pull, над наборами данных в HDFS.
Чтобы использовать Hudi, убедитесь, что сервис Spark2x установлен в кластере MRS.
Рисунок 1 Базовая архитектура Hudi
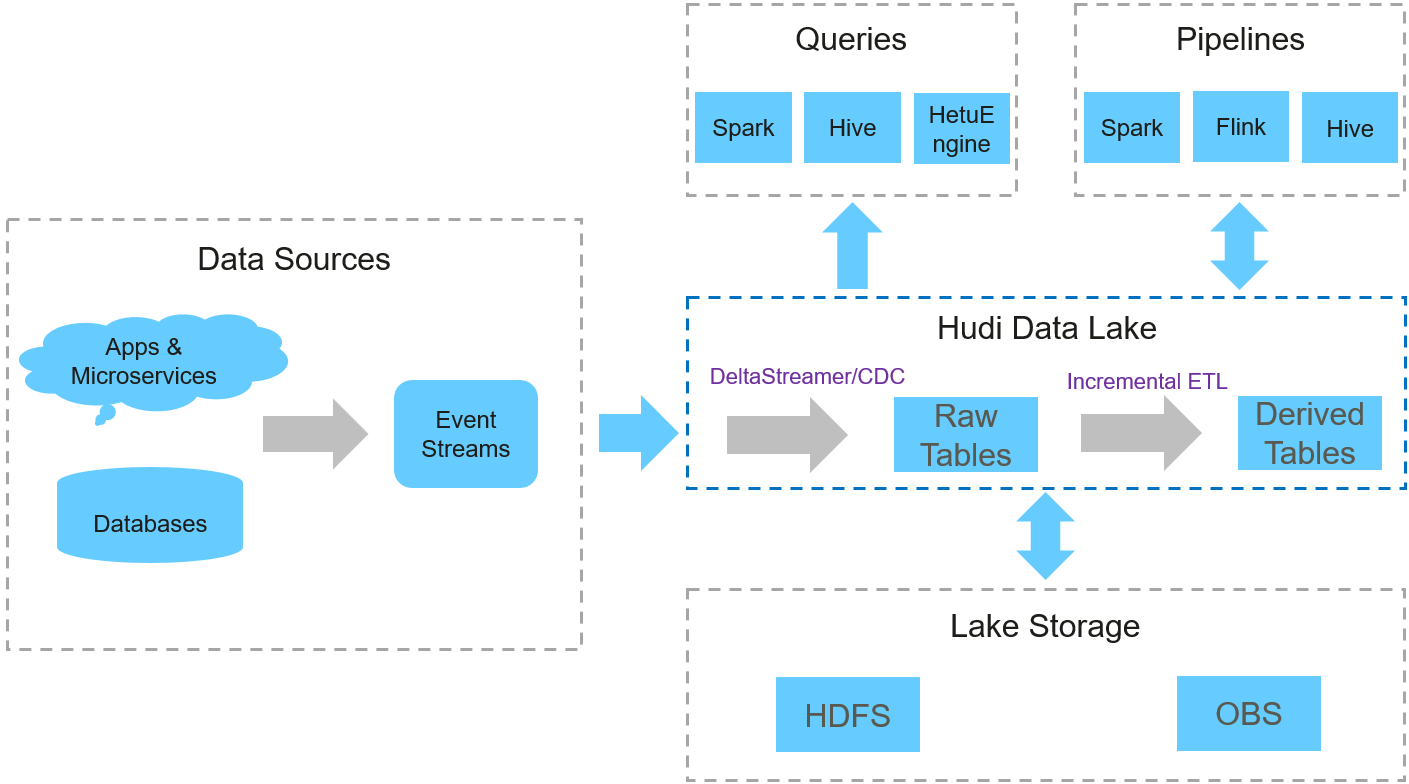
Функция
- Возможность ACID‑транзакций поддерживает импорт данных в реальном времени в озеро данных и пакетный импорт данных в озеро данных.
- Множественные возможности представлений (оптимизированный для чтения/инкрементный/в реальном времени) обеспечивают быструю аналитику данных.
- Конструкция Multi-version concurrency control (MVCC) поддерживает откат версии данных.
- Автоматическое управление размерами файлов и их макетами оптимизирует производительность запросов и предоставляет квазиреальное время данных для запросов.
- Поддерживается одновременное чтение и запись. Данные могут читаться во время их записи на основе изоляции по snapshot.
- Поддерживается Bootstrapping для преобразования существующих таблиц в датасеты Hudi.
Ключевые технологии и преимущества
- Подключаемый механизм индексации: Hudi предоставляет несколько механизмов индексации для быстрого обновления и удаления огромных объёмов данных.
- Поддержка экосистемы: Hudi поддерживает несколько движков данных, включая Hive, Spark, HetuEngine и Flink.
Два типа таблиц, поддерживаемых Hudi
- Copy On Write
Таблицы Copy-on-write также называют COW‑таблицами. Для хранения данных используются файлы Parquet, а внутренние операции обновления выполняются путем перезаписи оригинальных файлов Parquet.
- Преимущество: Это эффективно, потому что необходимо прочитать только один файл данных в соответствующем разделе.
- Недостаток: При записи данных необходимо скопировать предыдущую копию, а затем генерировать новый файл данных на её основе. Этот процесс занимает много времени. Поэтому данные, читаемые запросом чтения, отстают.
- Merge On Read
Таблицы Merge-on-read также называют таблицами MOR. Для хранения данных используется комбинация колонно-ориентированного формата Parquet и строкового формата Avro. Файлы Parquet используются для хранения базовых данных, а файлы Avro (также называемые лог‑файлами) — для хранения инкрементальных данных.
- Преимущество: данные сначала записываются в delta log, размер delta log небольшой. Поэтому стоимость записи низкая.
- Недостаток: файлы необходимо периодически уплотнять. В противном случае образуется большое количество фрагментных файлов. Производительность чтения плохая, потому что delta logs и старые файлы данных необходимо объединять.
Hudi поддерживает три типа представлений для возможностей чтения в различных сценариях
- Snapshot View
Предоставляет последние snapshot‑данные текущей таблицы Hudi. То есть, как только последние данные записаны в таблицу Hudi, ново‑записанные данные могут быть запрошены через это представление.
Как таблицы COW, так и таблицы MOR поддерживают эту возможность представления.
- Incremental View
Обеспечивает возможность инкрементного запроса. Инкрементные данные после указанного коммита могут быть запрошены. Это представление можно использовать для быстрой выборки инкрементных данных.
Таблицы COW поддерживают эту возможность просмотра. Таблицы MOR также поддерживают эту возможность просмотра, но возможность инкрементного просмотра исчезает после выполнения операции сжатия.
- Read Optimized View
Предоставляет только данные, хранящиеся в последнем файле Parquet.
Этот просмотр отличается для таблиц COW и MOR.
Для таблиц COW возможность просмотра совпадает с возможностью просмотра в режиме реального времени. (Таблицы COW используют только файлы Parquet для хранения данных.)
Для таблиц MOR доступны только базовые файлы, и предоставляются данные в указанных фрагментах файлов, начиная с последней операции сжатия. Можно просто понять, что этот просмотр предоставляет только данные, хранящиеся в файлах Parquet таблиц MOR, а данные из файлов журналов игнорируются. Данные, предоставляемые этим просмотром, могут быть не самыми последними. Однако после выполнения операции сжатия над таблицами MOR инкрементные данные журнала объединяются с базовыми данными. В этом случае этот просмотр имеет те же возможности, что и просмотр в режиме реального времени.