Relationship Between Spark and HDFS
Данные, вычисляемые Spark, поступают из нескольких источников данных, таких как локальные файлы и HDFS. Большинство данных, вычисляемых Spark, поступают из HDFS. HDFS может считывать данные в большом масштабе для параллельных вычислений. После вычисления данные могут быть сохранены в HDFS.
Spark включает Driver и Executor. Driver планирует задачи, а Executor выполняет задачи.
Figure 1 показывает процесс чтения файла.
Figure 1 Процесс чтения файла
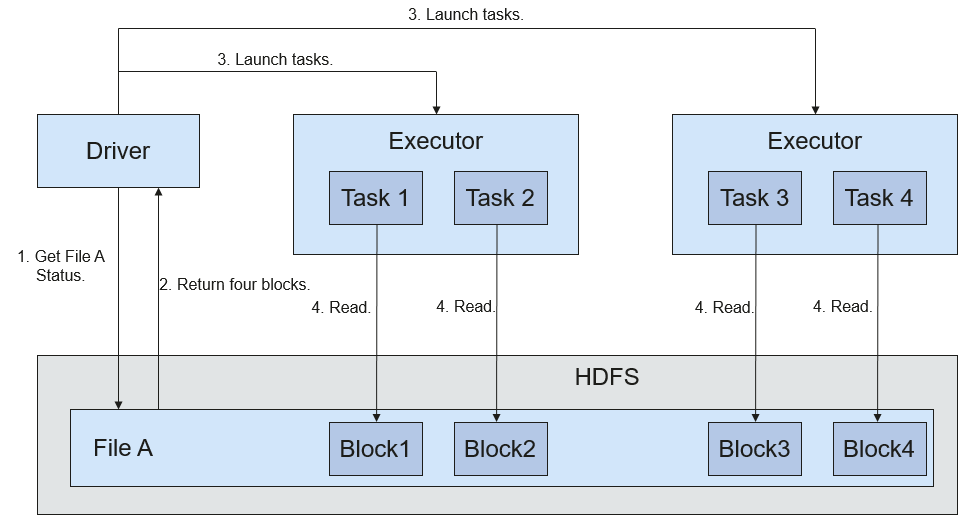
Процесс чтения файла выглядит следующим образом:
- Driver взаимодействует с HDFS, чтобы получить информацию о файле A.
- HDFS возвращает подробную информацию о блоках этого файла.
- Driver задает степень параллелизма, исходя из объёма данных блоков, и создаёт несколько задач для чтения блоков этого файла.
- Executor выполняет задачи и читает подробные блоки в составе Resilient Distributed Dataset (RDD).
Рисунок 2 показывает процесс записи данных в файл.
Рисунок 2 Процесс записи файла
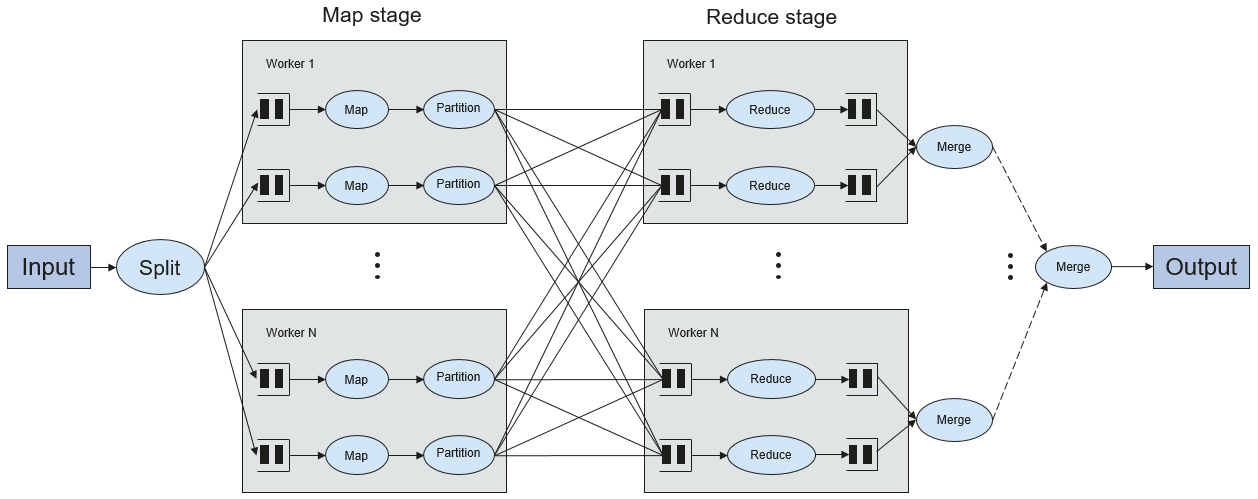
Процесс записи файла выглядит следующим образом:
- Драйвер создает каталог, в который будет записываться файл.
- На основе статуса распределения RDD вычисляется количество задач, связанных с записью данных, и эти задачи отправляются Executor.
- Executor выполняет эти задачи и записывает данные RDD в каталог, созданный в 1.
Взаимосвязь между Spark и Yarn
Вычисления и планирование Spark могут быть реализованы с использованием режима Yarn. Spark использует вычислительные ресурсы, предоставляемые кластерами Yarn, и выполняет задачи распределённым способом. Spark на Yarn имеет два режима: Yarn-cluster и Yarn-client.
- Yarn-cluster mode
Рисунок 3 Фреймворк работы Spark в Yarn‑кластер
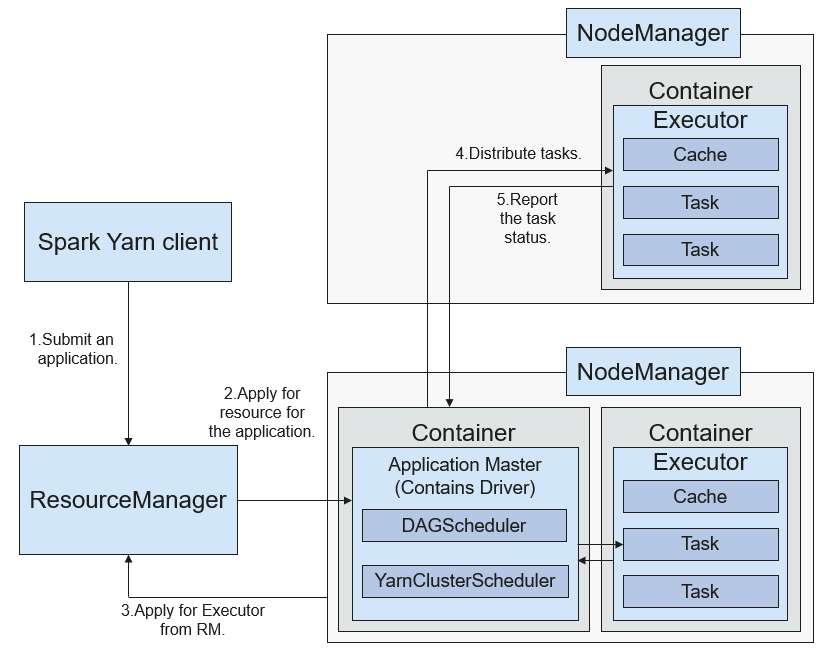
Процесс реализации Spark в Yarn‑кластер:
- Клиент генерирует информацию о приложении, а затем отправляет её в ResourceManager.
- ResourceManager выделяет первый контейнер (ApplicationMaster) для SparkApplication и запускает драйвер в контейнере.
- ApplicationMaster запрашивает ресурсы у ResourceManager для запуска контейнера.
ResourceManager выделяет контейнер ApplicationMaster, который взаимодействует с NodeManager и запускает executor в полученном контейнере. После запуска executor он регистрируется в драйвере и запрашивает задачи.
- Драйвер распределяет задачи между executor.
- Executor выполняет задачи и сообщает о статусе выполнения драйверу.
- Режим Yarn‑client
Рисунок 4 Spark on Yarn-client операционный фреймворк
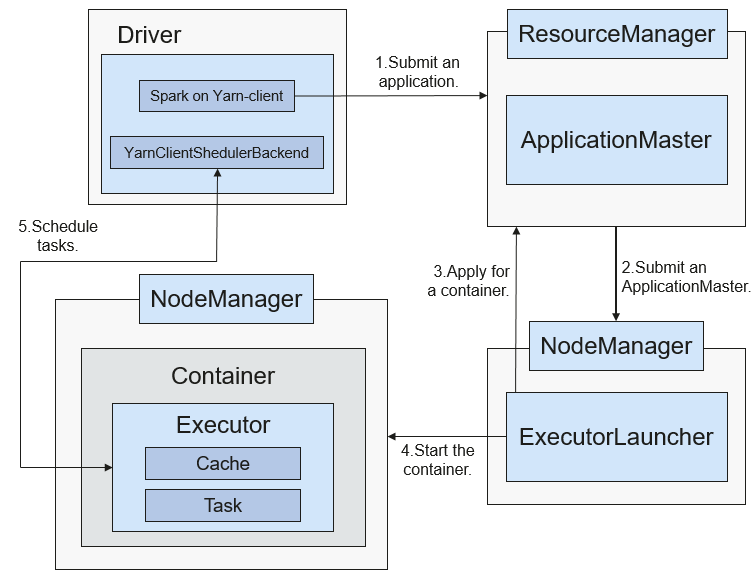
Spark on Yarn-client процесс реализации:
NoteВ режиме Yarn-client драйвер развертывается на клиенте и запускается на клиенте. В режиме Yarn-client клиент более ранней версии несовместим. Рекомендуется использовать режим Yarn-cluster.
- Клиент отправляет запрос Spark‑приложения в ResourceManager, после чего ResourceManager возвращает результаты. Результаты включают информацию, такую как ID приложения и максимальные и минимальные доступные ресурсы. Клиент собирает всю информацию, необходимую для запуска ApplicationMaster, и отправляет её в ResourceManager.
- После получения запроса ResourceManager находит подходящий узел для ApplicationMaster и запускает его на этом узле. ApplicationMaster — роль в Yarn, а имя процесса в Spark — ExecutorLauncher.
- Исходя из требований к ресурсам каждой задачи, ApplicationMaster может запросить серию контейнеров у ResourceManager для выполнения задач.
- После получения списка недавно выделенных контейнеров (из ResourceManager) ApplicationMaster отправляет информацию соответствующим NodeManagers для запуска контейнеров.
ResourceManager выделяет контейнеры ApplicationMaster, который взаимодействует с соответствующими NodeManagers и запускает executors в полученных контейнерах. После запуска executors он регистрируется с drivers и подает запрос на задачи.
NoteЗапущенные контейнеры не приостанавливаются и ресурсы не освобождаются.
- Drivers распределяют задачи executors. Executor выполняет задачи и сообщает о статусе выполнения driver.