Big data представляет как захватывающие возможности, так и огромную проблему. По мере того как объём и типы данных стремительно растут, традиционные технологии обработки данных, такие как автономные системы хранения и реляционные базы данных, не успевают за ними. Чтобы справиться с этой задачей, Apache Software Foundation (ASF) запустила проект с открытым исходным кодом под названием Hadoop. Hadoop — это распределённая вычислительная платформа с открытым исходным кодом, способная полностью использовать вычислительные и хранилищные возможности больших вычислительных кластеров для обработки массивных объёмов данных. Hadoop является мощным фреймворком, но его не легко развернуть и эксплуатаировать — если предприятия пытаются развернуть системы Hadoop самостоятельно, они могут столкнуться с проблемами, такими как высокие затраты, длительный ввод в эксплуатацию, сложное обслуживание и негибкое использование.
Сервис MapReduce Service (MRS) предлагает комплексный сервис, который помогает быстро развернуть и управлять системами Hadoop в облаке с легкостью. С помощью MRS вы можете создать кластер Hadoop enterprise‑class с несколькими щелчками мыши. Арендаторы имеют полный контроль над своими кластерами Hadoop и могут без усилий запускать компоненты больших данных, такие как Storm, Hadoop, Spark, HBase и Kafka. MRS поддерживает полный набор открытых API, и, используя глубокую экспертизу облачной платформы в вычислениях, хранении и больших данных, предлагает клиентам полностековую платформу больших данных с высокой производительностью, высокой экономичностью, гибкостью и простотой использования. Кроме того, платформу можно легко настроить под новые требования и помочь предприятиям быстро построить масштабную систему обработки данных и обнаружить новую ценность и бизнес‑возможности, анализируя и добывая огромные объемы данных в реальном времени или вне реального времени.
Архитектура продукта
Figure 1 показывает логическую архитектуру MRS.
Figure 1 архитектура MRS
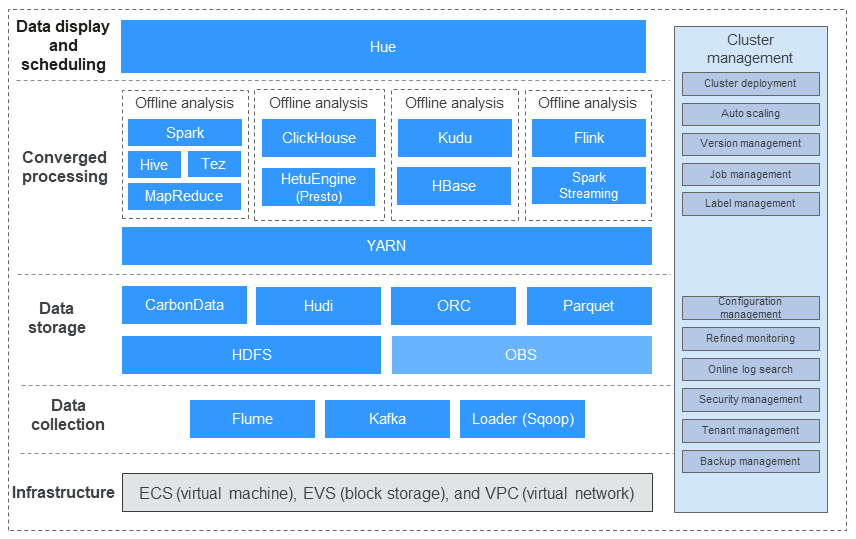
MRS включает инфраструктуру и конвейер обработки больших данных от начала до конца.
- Инфраструктура
Кластеры MRS для больших данных полностью используют высокую масштабируемость, надежность и функции безопасности уровня виртуализации, поддерживаемого облачной платформой.
- Virtual Private Cloud (VPC) предоставляет виртуальные частные сети для каждого арендатора в облаке.
- Elastic Volume Service (EVS) предоставляет надежное и высокопроизводительное хранилище.
- Elastic Cloud Server (ECS) предоставляет ВМ, которые легко масштабируются. Он работает с VPC, группами безопасности и механизмом многократных реплик EVS для создания эффективной, надежной и безопасной вычислительной среды.
- Сбор данных
Слой сбора данных обеспечивает возможность эффективного захвата данных из различных источников данных. Он состоит из Flume (захват данных), Loader (загрузка реляционных данных) и Kafka (высоконадёжная очередь сообщений). В качестве альтернативы вы можете использовать сервис Cloud Data Migration (CDM) для захвата внешних данных в кластеры MRS.
- Хранилище данных
Кластеры MRS могут хранить как структурированные, так и неструктурированные данные. Они поддерживают множество эффективных форматов данных, чтобы удовлетворять требования различных вычислительных движков, включая:
- HDFS, который является универсальной распределённой файловой системой для платформ больших данных.
- OBS — это Object Storage Service, характеризующийся высокой доступностью и низкой стоимостью.
- HBase, который поддерживает хранение данных с индексами, ускоряя запросы, основанные на индексах.
- Конвергентная обработка данных
- MRS поддерживает несколько основных вычислительных движков, включая MapReduce (пакетная обработка), Tez (модель DAG), Spark (вычисления в памяти), Spark Streaming (вычисления потоков микропакетов), Storm (вычисления потоков) и Flink (вычисления потоков). Они преобразуют структуры данных и логику в модели данных, отвечающие потребностям различных приложений больших данных.
- Основываясь на предустановленных моделях данных и удобном SQL‑анализе, пользователи могут выбрать Hive (хранилище данных), SparkSQL и Presto (интерактивный движок запросов) для выполнения различных аналитических задач.
- Отображение данных и планирование
MRS также интегрируется с DataArts Studio, предоставляя универсальную совместную платформу разработки больших данных, позволяя вам легко выполнять широкий спектр задач, таких как моделирование данных, интеграция данных, разработка скриптов, планирование Джоб и мониторинг O&M, делая большие данные более доступными, чем когда-либо.
- Управление кластером
Все компоненты экосистемы больших данных на основе Hadoop развернуты в распределённом режиме, а их развертывание, управление и O&M являются сложными.
MRS предоставляет единый O&M и управленческий платформу для управления кластерами, поддерживая развертывание кластера в один клик, выбор мультиверсий, а также ручное масштабирование и авто‑масштабирование кластеров без прерывания сервиса. Кроме того, MRS предоставляет управление джобами, управление тегами ресурсов и O&M, охватывающее все компоненты Hadoop. Возможности O&M «одного окна» включают мониторинг, сообщение о тревогах, настройку параметров и обновление Патчей.
Преимущества продукта
MRS имеет сильную команду ядра Hadoop и построен на базе крупномасштабной платформы больших данных FusionInsight корпоративного класса. MRS может гарантировать многоуровневые Service Level Agreements (SLAs).
У MRS есть следующие преимущества:
- Высокая производительность
MRS поддерживает решение хранения CarbonData. CarbonData позволяет использовать одну копию данных для выполнения нескольких задач. Он поддерживает такие функции, как многоуровневое индексирование, кодирование словаря, предагрегация, динамическое разбиение и почти в реальном времени запрос данных. Эти функции повышают эффективность сканирования I/O и вычислительной производительности, позволяя анализировать десятки миллиардов записей данных за секунды. Кроме того, MRS поддерживает Superior Scheduler, который превосходит открытые планировщики во всех отношениях и обеспечивает эффективное планирование в сверхбольших кластерах (до 10 000 узлов).
- Экономическая эффективность
MRS поддерживает гетерогенную инфраструктуру вычислений и хранения с разъединённым хранением и вычислениями, предлагая экономичное масштабное решение для хранения. MRS поддерживает быстрое авто масштабирование для адаптации к изменяющемуся спросу, максимизируя использование ресурсов для заказчиков. Кластеры MRS можно быстро создавать и масштабировать по мере необходимости, а также удалять или масштабировать их, когда они больше не нужны.
- Высокая безопасность
MRS предоставляет enterprise-class управление разрешениями в многопользовательской среде и управление безопасностью, поддерживая контроль доступа на основе таблиц и столбцов, а также шифрование данных.
- Простое O&M
MRS предоставляет эффективную платформу управления кластером big data, поддерживающую одно‑кликовое скользящее обновление патчей, обеспечивающее непрерывность ваших сервисов.
- Высокая надежность
Тестировано и подтверждено в многочисленных проектах, долгосрочная надёжность и стабильность MRS в масштабных развертываниях способны соответствовать корпоративным стандартам для производственных систем. Кроме того, MRS поддерживает автоматический Бэкап данных в разных AZ и регионах, а также автоматическую anti‑affinity, позволяя критически важным ВМ распределять на разные физические машины.