Сценарий
CDM поддерживает миграцию таблиц и файлов между однородными или разнородными источниками данных. Для получения подробной информации о поддерживаемых источниках данных см Поддерживаемые источники данных.
Ограничения
- Функция записи грязных данных зависит от OBS.
- JSON‑файл задачи для импорта не может превышать 1 MB.
- Размер передаваемого файла не может превышать 1 TB.
- Имена полей параметров источника и назначения не могут содержать амперсанд (&) или знак решётки (%).
Предварительные требования
- Связь создана. Для получения подробной информации см Создание связи между CDM и источником данных.
- Кластер CDM может взаимодействовать с источником данных.
Процедура
- Войдите в консоль управления и выберите Список сервисов > Миграция данных в облаке. В левом навигационном панеле выберите Управление кластером. Найдите целевой кластер и нажмите Управление Джобой.
- Выберите . Отображается страница настройки джобы.
Рисунок 1 Создание задачи миграции
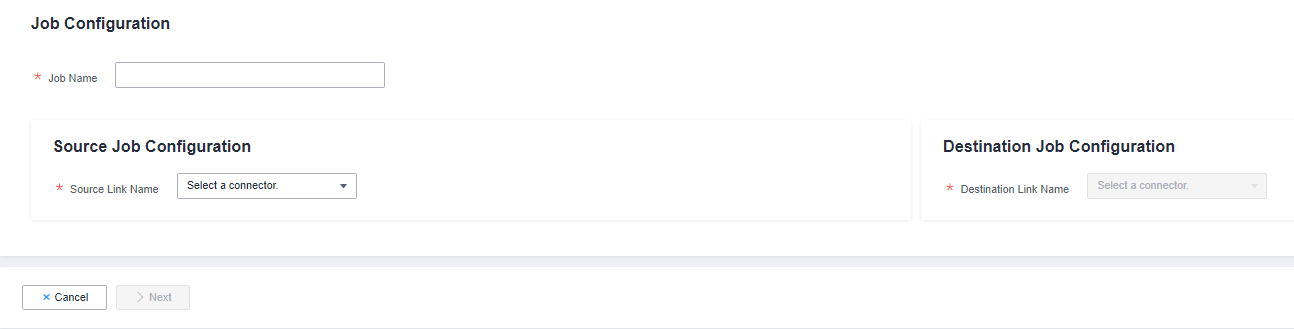
- Выберите исходные и целевые ссылки.
- Имя Джобы: Введите строку, состоящую из 1 до 240 символов. Имя может содержать цифры, буквы, дефисы (-), подчеркивания (_) и точки (.), и не может начинаться с дефиса (-) или точки (.). Пример значения oracle2rds_t.
- Имя исходной ссылки: Выберите источник данных, из которого будут экспортироваться данные.
- Имя целевой ссылки: Выберите источник данных, в который будут импортироваться данные.
- Настройте параметры исходной ссылки.
Параметры различаются в зависимости от источников данных. Подробную информацию о параметрах задания для других типов источников данных см Таблица 1 и Таблица 2.
Таблица 1 Описание параметров исходной ссылки Источник миграции
Описание
Настройки параметров
OBS
Данные можно извлекать в формате CSV, JSON или в бинарном формате. Извлечённые в бинарном формате данные не зависят от разрешения файла, что обеспечивает высокую производительность и лучше подходит для миграции файлов.
- MRS HDFS
- FusionInsight HDFS
- Apache HDFS
Данные HDFS можно экспортировать в формате CSV, Parquet или в бинарном формате и сжимать в нескольких форматах.
- MRS HBase
- FusionInsight HBase
- Apache HBase
- CloudTable Service
Данные можно экспортировать из MRS, FusionInsight HD, open source Apache Hadoop HBase или CloudTable. Вам необходимо знать все семейства столбцов и имена полей таблиц HBase.
- MRS Hive
- FusionInsight Hive
- Apache Hive
Данные можно экспортировать из Hive через JDBC API.
Если источником данных является Hive, CDM автоматически разделит данные, используя файл распределения данных Hive.
DLI
Данные можно экспортировать из DLI.
- FTP
- SFTP
Данные FTP и SFTP можно экспортировать в формате CSV, JSON или бинарном формате.
- HTTP
Эти коннекторы используются для чтения файлов по URL HTTP/HTTPS, например, для чтения публичных файлов в сторонних системах объектного хранилища и веб‑дисков.
В настоящее время данные можно экспортировать только из URL HTTP.
Data Warehouse Service
Данные можно экспортировать из DWS.
SAP HANA
Данные можно экспортировать из SAP HANA.
- RDS for PostgreSQL
- RDS for SQL Server
- Microsoft SQL Server
- PostgreSQL
Данные могут быть экспортированы из облачных сервисов баз данных.
Необлачные базы данных могут быть созданы в локальном дата‑центре или развернуты на ECSs, либо представлять собой сервисы баз данных в сторонних облаках.
Когда данные экспортируются из этих источников данных, CDM использует JDBC API для извлечения данных. Параметры задания для источника миграции одинаковы. Для получения подробной информации см Из PostgreSQL/SQL Server.
MySQL
Данные могут быть экспортированы из базы данных MySQL.
Oracle
Данные могут быть экспортированы из базы данных Oracle.
Шардирование базы данных
Данные могут быть экспортированы из шарда.
- MongoDB
- Document Database Service
Данные могут быть экспортированы из MongoDB или DDS.
NOTE:Источники данных MongoDB и DDS с включённым SSL не поддерживаются.
Redis
Данные могут быть экспортированы из открытого Redis.
- Apache Kafka
- DMS Kafka
- MRS Kafka
Данные могут быть экспортированы только в Cloud Search Service (CSS).
- Cloud Search Service
- Elasticsearch
Данные могут быть экспортированы из CSS или Elasticsearch.
MRS Hudi
Данные могут быть экспортированы из MRS Hudi.
MRS ClickHouse
Данные могут быть экспортированы из MRS ClickHouse.
LogHub (SLS)
Данные могут быть экспортированы из LogHub (SLS).
ShenTong database
Данные могут быть экспортированы из базы данных ShenTong.
- Настройте параметры задачи для места назначения миграции на основе Таблица 2.
Таблица 2 Описание параметра Назначение миграции
Описание
Настройки параметра
OBS
Файлы (даже в большом объёме) можно пакетно мигрировать в OBS в формате CSV или в бинарном формате.
MRS HDFS
Вы можете выбрать формат сжатия при импорте данных в HDFS.
MRS HBase
CloudTable Service
Данные можно импортировать в HBase. Алгоритм сжатия можно задать при создании новой таблицы HBase.
MRS Hive
Данные можно быстро импортировать в MRS Hive.
- MySQL
- SQL Server
- PostgreSQL
Данные можно импортировать в облачные сервисы баз данных.
Для получения подробной информации о том, как использовать JDBC API для импорта данных, см. В MySQL/SQL Server/PostgreSQL.
DWS
Данные можно импортировать в DWS.
Oracle
Данные можно импортировать в базу данных Oracle.
DLI
Данные можно импортировать в DLI.
Elasticsearchor Cloud Search Service (CSS)
Данные могут быть импортированы в CSS.
MRS Hudi
Данные могут быть быстро импортированы в MRS Hudi.
MRS ClickHouse
Данные могут быть быстро импортированы в MRS ClickHouse.
MongoDB
Данные могут быть быстро импортированы в MongoDB.
NOTE:Источники данных MongoDB с включённым SSL не поддерживаются.
- После настройки параметров нажмите Далее. Сопоставление полей вкладка отображается.
Если файлы мигрируют между FTP, SFTP, OBS и HDFS и исходный источник Формат файла установлен в Бинарный, файлы будут переданы напрямую, без сопоставления полей.
В других сценариях CDM автоматически сопоставляет поля исходной таблицы и целевой таблицы. Необходимо проверить, корректны ли сопоставление и формат времени. Например, проверьте, может ли тип поля источника быть преобразован в тип поля назначения.
Рисунок 2 Сопоставление полей
 Note
Note- Если поля из исходного и целевого источников не совпадают, их можно перетаскивать для корректировки.
- На Сопоставить поле вкладке, если CDM не удаётся получить все столбцы, получая образцы значений (например, когда данные экспортируются из HBase, CloudTable или MongoDB, или когда данные мигрируют из SFTP/FTP в DLI, существует высокая вероятность, что CDM не получит все столбцы), вы можете нажать
 и выбрать Добавить новое поле чтобы добавить новые поля и обеспечить полную импортируемую в пункт назначения миграции данных.
и выбрать Добавить новое поле чтобы добавить новые поля и обеспечить полную импортируемую в пункт назначения миграции данных. - Когда в качестве источника миграции используется реляционная база данных, Hive, DLI или MRS Hudi, образцы значений получить невозможно.
- На Сопоставить поле странице, вы можете нажать
 чтобы добавить пользовательские константы, переменные и выражения.
чтобы добавить пользовательские константы, переменные и выражения. - Имена столбцов отображаются, когда источником задания миграции является OBS, CSV-файлы должны быть мигрированы, и параметр Извлечь первую строку как столбцы установлен в Да.
- Когда SQLServer является назначением, поля типа timestamp нельзя записать. Необходимо изменить их тип (например, на datatime), чтобы их можно было записать.
- Когда Hive выступает в качестве источника, данные типов array и map могут быть прочитаны.
- Отображение полей не используется, когда двоичный формат применяется для миграции файлов в файлы.
- Если данные импортируются в DWS, необходимо выбрать распределительные столбцы в целевых полях. Рекомендуется выбирать распределительные столбцы согласно следующим принципам:
- Используйте первичный ключ в качестве распределительного столбца.
- Если несколько сегментов данных объединены в первичные ключи, укажите все первичные ключи в качестве распределительного столбца.
- В случае отсутствия первичного ключа, если распределительный столбец не выбран, DWS по умолчанию использует первый столбец в качестве распределительного столбца. В результате существует риск перекоса данных.
- CDM поддерживает преобразование полей. Нажмите
 а затем нажмите Создать конвертер.
а затем нажмите Создать конвертер.Рисунок 3 Создание конвертера
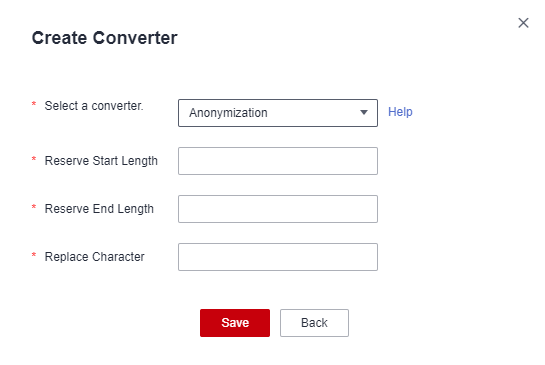
CDM поддерживает следующие конвертеры:
- Анонимизация: скрывает ключевые данные в строке символов.
Например, если вы хотите преобразовать 12345678910 в 123****8910, настройте параметры следующим образом:
- Установите Резервировать начальную длину в 3.
- Установите Резервировать конечную длину в 4.
- Установите Заменить символ в *.
- Обрезать автоматически удаляет пробелы до и после строкового значения.
- Обратить строку автоматически обращает строку. Например, reverse ABC в CBA.
- Заменить строку заменяет указанную строку.
- Преобразование выражения использует язык выражений JSP (EL) для преобразования текущего поля или строки данных.
- Удалить разрыв строки удаляет символы новой строки, такие как \n, \r и \r\n, из поля.
NoteЕсли Использовать SQL-запрос установлено в Да в конфигурации исходного джобы конверторы не могут быть созданы.
- Анонимизация: скрывает ключевые данные в строке символов.
- Нажмите Далее, задайте параметры джобы и нажмите Show Advanced Attributes для отображения и настройки дополнительных параметров.
Рисунок 4 Параметры задачи
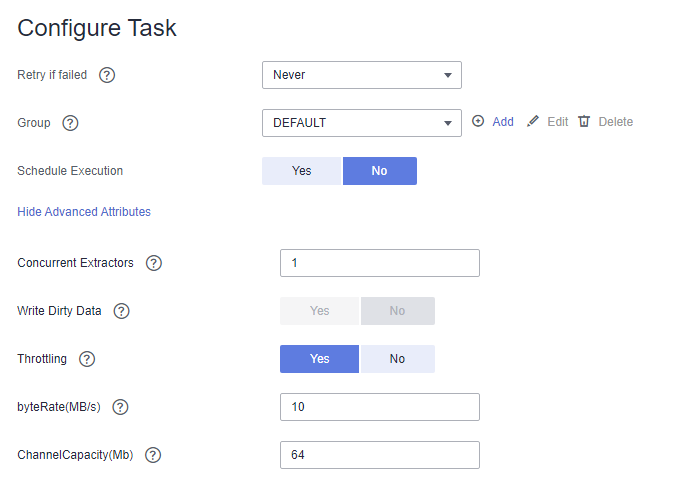
Таблица 3 описывает связанные параметры.
Таблица 3 Описание параметра Параметр
Описание
Пример значения
Retry upon Failure
Вы можете выбрать Повторить 3 раза или Никогда.
Рекомендуется настроить автоматический повтор только для задач миграции файлов или задач миграции баз данных с Импорт в промежуточную таблицу включено, чтобы избежать несоответствия данных, вызванного повторными записями.
NOTE:Если вы хотите задать параметры в DataArts Studio DataArts Factory для планирования задачи миграции CDM, не настраивайте этот параметр. Вместо этого задайте параметр Retry upon Failure для узла CDM в DataArts Factory.
Никогда
Задача
Выберите группу, в которой находится задача. Группа по умолчанию — DEFAULT. На Управление задачами странице, задачи могут отображаться, запускаться или экспортироваться по группам.
DEFAULT
Запуск расписания
Если вы выберете Да, вы можете установить время начала, цикл и период действия задания. Подробнее см. Настройка запланированного CDM задания.
NOTE:Если вы используете DataArts Studio DataArts Factory для планирования задания миграции CDM и настройки этого параметра, обе конфигурации вступают в силу. Чтобы обеспечить единообразную логику сервиса и избежать конфликтов расписаний, включите планирование заданий в DataArts Factory и не настраивайте запланированную задачу для задания в DataArts Migration.
Нет
Параллельные извлекатели
Максимальное количество потоков задания для чтения данных из источника
NOTE:Количество параллельных потоков может быть меньше или равно значению этого параметра для некоторых источников данных, которые не поддерживают параллельное извлечение, например, CSS и ClickHouse.
CDM переносит данные через задания миграции данных. Он работает следующим образом:
- Когда задания миграции данных отправляются, CDM разбивает каждое задание на несколько задач на основе Параллельные извлекатели параметра в конфигурации задания.NOTE:
Задания для разных источников данных могут быть разбиты по разным измерениям. Некоторые задания могут не разбиваться по Параллельные извлекатели параметру.
- CDM последовательно отправляет задачи в работающий пул. Задачи (определяемые Максимальное количество параллельных извлекателей) работают одновременно. Избыточные задачи ставятся в очередь.
Устанавливая подходящие значения для этого параметра и Максимального количества параллельных извлекателей параметра, вы можете ускорить миграцию.
Настройте количество параллельных извлекателей в соответствии со следующими правилами:
- Когда данные необходимо перенести в файлы, CDM не поддерживает несколько одновременных задач. В этом случае установите один процесс для извлечения данных.
- Если каждая строка таблицы содержит данные объёмом менее или равным 1 MB, данные можно извлекать одновременно. Если каждая строка содержит более 1 MB данных, рекомендуется извлекать данные в одном потоке.
- Установить Одновременные извлекатели для задачи, основанной на Максимальное количество одновременных извлекателей для кластера. Рекомендуется Одновременные извлекатели меньше чем Максимальное количество одновременных извлекателей.
- Если назначение — DLI, рекомендуется установить количество одновременных извлекателей равным 1. В противном случае данные могут не быть записаны.
Максимальное количество одновременных экстракторов для кластера зависит от флейвора кластера CDM. Рекомендуется установить максимальное количество одновременных экстракторов в два раза больше количества vCPU кластера CDM. Например, максимальное количество одновременных экстракторов для кластера с 8 vCPU и 16 GB памяти равно 16.
1
Одновременные загрузчики
Количество загрузчиков, которые будут выполняться одновременно
Этот параметр отображается только в том случае, когда HBase или Hive используется в качестве целевого источника данных.
3
Количество повторов разбиения
Количество повторов, когда разбиение не удалось выполнить. Значение 0 указывает, что повтор не будет выполнен.
0
Записать грязные данные
Определяет, записывать ли грязные данные. По умолчанию этот параметр установлен в Нет.
Грязные данные в CDM относятся к данным в неверном формате. Если исходные данные содержат грязные данные, рекомендуется включить эту функцию. В противном случае задание миграции может завершиться ошибкой.
ПРИМЕЧАНИЕ:Грязные данные могут быть записаны только в пути OBS. Поэтому этот параметр доступен только при наличии ссылки OBS.
Да
Записать ссылку на грязные данные
Этот параметр отображается только когда Записать грязные данные установлен в Да.
Можно выбрать только ссылку OBS.
obs_link
OBS Бакет
Этот параметр отображается только когда Записать ссылку на грязные данные является ссылкой на OBS.
Имя OBS бакета, в который будут записаны грязные данные.
dirtydata
Каталог грязных данных
Этот параметр отображается только когда Записать грязные данные установлен на Да.
Грязные данные хранятся в каталоге для хранения грязных данных в OBS. Грязные данные сохраняются только когда этот параметр настроен.
Вы можете перейти в этот каталог, чтобы запросить данные, которые не удалось обработать или которые были отфильтрованы во время выполнения задачи, и проверить исходные данные, которые не соответствуют правилам конвертации или очистки.
/user/dirtydir
Max. Ошибочных записей в одном шарде
Этот параметр отображается только когда Записать грязные данные установлен на Да.
Когда количество записей с ошибками в отдельной карте превышает верхний предел, задание автоматически завершается, и импортированные данные нельзя откатить. Рекомендуется использовать временную таблицу в качестве таблицы назначения. После импорта данных переименуйте таблицу или объедините её с окончательной таблицей данных.
0
Троттлинг
Включение троттлинга уменьшает нагрузку чтения на источник. Он контролирует скорость передачи CDM, а не трафик NIC.
ПРИМЕЧАНИЕ:- Троттлинг можно включить для заданий миграции файлов без двоичного формата.
- Чтобы настроить троттлинг для нескольких заданий, умножьте скорость на количество одновременных заданий.
- Троттлинг не поддерживается для двоичной передачи между файлами.
Да
byteRate(MB/s)
Максимальная скорость чтения/записи задания
Регулирование может быть включено для задачи миграции данных в Hive, DLI, JDBC, OBS или HDFS. Если разрешено несколько одновременно выполняемых задач, фактическая максимальная скорость может быть рассчитана как значение этого параметра, умноженное на количество одновременно выполняемых задач.
ПРИМЕЧАНИЕ:Скорость — целое число, большее 1.
20
Размер кэша промежуточной очереди (MB)
Объём данных, который может кэшировать промежуточная очередь. Диапазон значений от 1 до 500. Значение по умолчанию — 64.
Если объём данных строки превышает значение этого параметра, миграция может завершиться с ошибкой. Если значение этого параметра слишком велико, кластер может работать некорректно. Установите подходящее значение для этого параметра и используйте значение по умолчанию (64) если не указано иное.
64
- Когда задания миграции данных отправляются, CDM разбивает каждое задание на несколько задач на основе Параллельные извлекатели параметра в конфигурации задания.
- Нажмите Сохранить или Сохранить и Запустить. На отображаемой странице, вы можете просмотреть статус задания.Note
Статус задания может быть Новый, Ожидание, Загрузка, Выполняется, Сбой, Успешно, или Остановлен.
Ожидание указывает, что задание ожидает планирования системой, и Загрузка указывает, что данные для миграции анализируются.