В этом разделе описывается, как создать индикатор.
Подготовка
- Проект был создан, ссылаясь на Создание проекта.
- Источник данных был создан, ссылаясь на Подключение к источнику данных.
- Датасет был создан, ссылаясь на Создание Датасета.
Процедура
- Нажмите
 в верхнем левом углу, чтобы выбрать регион.
в верхнем левом углу, чтобы выбрать регион. - В нижнем левом углу панели навигации выберите Enterprise проект из Enterprise проект.
- Выберите нужный проект и щелкните название, чтобы получить доступ к проекту.
- Выбрать Управление данными > Индикатор.
- Нажмите Создать индикатор в правом верхнем углу.
Рисунок 1 Создать индикатор
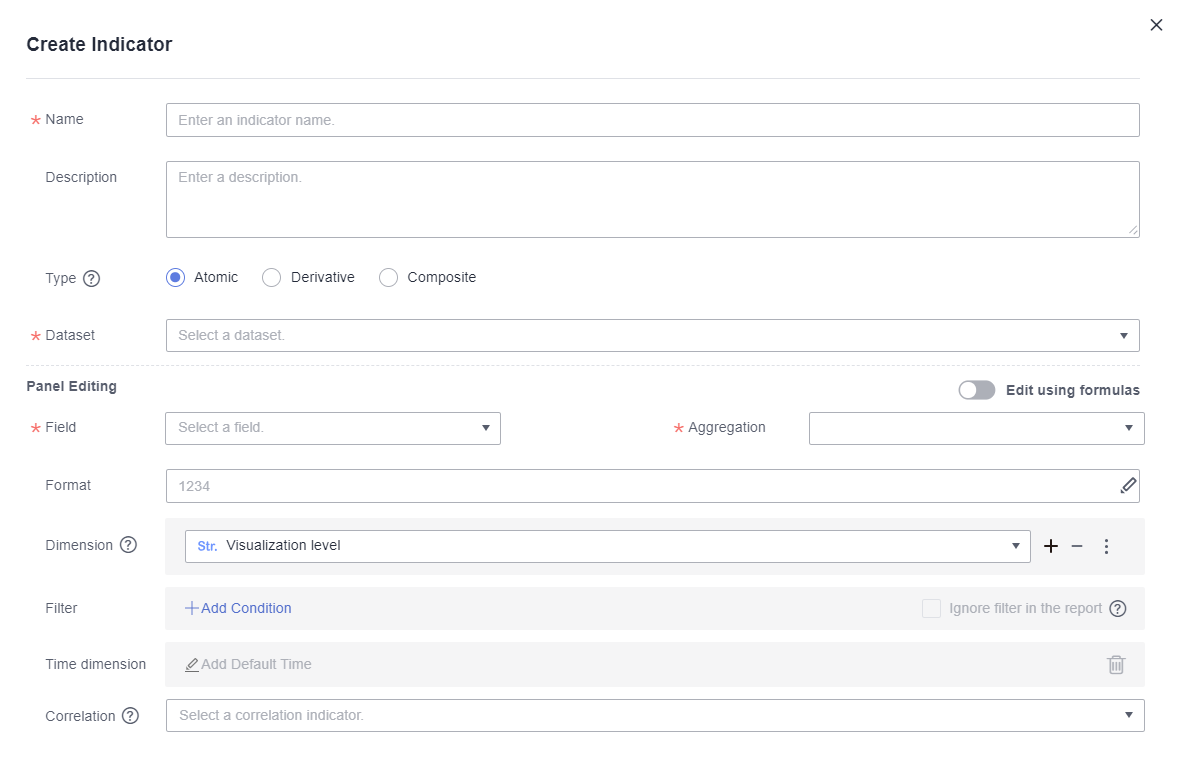
- Установите параметры и нажмите OK.
Таблица 1 Параметры индикатора Параметр
Описание
Имя
Имя индикатора, задаваемое пользователем.
NOTE:Максимальная длина имени — 512 символов. Допускаются только буквы, цифры, скобки, косые черты (/), обратные косые черты (\), подчеркивания (_) и дефисы (-).
Описание
Описание индикатора.
Тип
Атомарные индикаторы — количественные измерения продукта или бизнес‑показателя, такие как выручка от продаж.
Показатели‑производные — расширения одного индикатора, обычно используемые для расширения индикаторов со временем, такие как выручка от продаж по сравнению с предыдущим месяцем.
Составные индикаторы основаны на нескольких индикаторах и определяются входными выражениями, например profit = sales revenue – cost.
Датасет
Датасет, который вы хотите связать с индикатором.
Поле
Размеры и метрики.
Агрегация
Варианты включают Сумма, Среднее, Количество, Уникальное количество, Максимум, Минимум, Стандартное отклонение популяции, Стандартное отклонение выборки, Дисперсия популяции, and Дисперсия выборки.
Производная
Варианты включают YoY и PoP темп роста, YoY и PoP рост, От начала периода, Скользящий расчёт, Накопительный расчёт, Ранжирование, Разница, Процент разницы, и Общий процент.
Формат
Варианты включают Без формата, Числовой, Валюта, Квантификатор объекта, Длина, Вес, Энергия, Ёмкость, Время, и Процент.
Измерение
Вы можете выбрать измерения, по которым анализируются значения индикаторов.
NOTE:Если Измерение установлен в Уровень визуализации, все измерения связаны по умолчанию.
Фильтр
Он используется для добавления правил фильтрации.
- Нажмите Добавить условие.
- Выберите поле фильтра, тип фильтра, условие фильтрации фиксированного значения и значение.
- Поле фильтра: Фильтровать поля набора данных, для которых необходимо задать правила. Вы можете выбрать только одно измерение или поле метрики. Чтобы настроить правила для других полей, добавьте дополнительные условия.
- Тип фильтра: Выберите Условие, Перечисление, или Фильтрация выражения.
- Условие фильтрации фиксированного значения: варианты включают Равно, Не равно и другие.
- Фиксированное значение: Введите значение условия фильтрации. Для фильтрации перечислением выберите значение поля из раскрывающегося списка.
Чтобы задать правила для других полей, нажмите Создать правило.
Если существует несколько правил условий, задайте взаимосвязь между правилами.
- AND: Вы можете просмотреть значения полей, которые удовлетворяют обоим правилам A и B.
- OR: Вы можете просмотреть значения полей, которые удовлетворяют либо правилу A, либо B.
- Чтобы добавить правило, находящееся параллельно правилам A и B, нажмите Добавить взаимосвязь для создания новой группы правил, правило C. которое находится на том же уровне, что и правила A и B.
Игнорировать фильтр отчёта
Когда в отчёте присутствуют дублирующие фильтры столбцов, выбор этого параметра приведёт к игнорированию фильтров уровня отчёта. Если параметр не выбран, фильтр будет пересекаться с фильтрами уровня отчёта.
Таблица 2 Числовые функции Функция
Использование
Описание
ABS
ABS(x)
Возвращает абсолютное значение x.
CEIL
CEIL(x)
Возвращает наименьшее целое число, большее либо равное x.
FLOOR
FLOOR(x)
Возвращает наибольшее целое число, меньшее либо равное x.
RANDOM
RANDOM()
Возвращает случайное число в диапазоне от 0.0 до 1.0.
SIGN
SIGN(x)
Возвращает знак x, который равен -1, 0 или 1 в зависимости от того, x отрицательное, ноль или положительное.
PI
PI()
Возвращает pi.
TRUNC
TRUNC(x, y)
Возвращает значение x округлен до y десятичных знаков.
ROUND
ROUND(x)
Возвращает значение x округлен до y десятичных знаков, при этом обрезанная часть округляется.
POWER
POWER(x,y)
Возвращает значение x возведено в степень y.
SQRT
SQRT(x)
Возвращает квадратный корень от x.
EXP
EXP(x)
Возвращает значение e возведённое в степень x.
MOD
MOD(x,y)
Возвращает остаток от деления x делится на y.
LOG
LOG(x)
В режиме, совместимом с ORA- или TD-, этот оператор обозначает логарифм по основанию 10. В режиме, совместимом с MySQL, этот оператор обозначает натуральный логарифм.
RADIANS
RADIANS(x)
Преобразует угол в радиан.
DEGREES
DEGREES(x)
Преобразует радиан в угол.
SIN
SIN(x)
Вычисляет значение синуса, заданного в радианах.
ASIN
ASIN(x)
Вычисляет значение арксинуса, заданного в радианах.
COS
COS(x)
Вычисляет значение косинуса, заданного в радианах.
ACOS
ACOS(x)
Вычисляет значение арккосинуса, заданного в радианах.
TAN
TAN(x)
Вычисляет значение тангенса, заданного в радианах.
ATAN
ATAN(x)
Вычисляет значение арктангенса, заданного в радианах.
COT
COT(x)
Вычисляет значение котангенса, заданного в радианах.
Таблица 3 Оконные функции Функция
Использование
Описание
RANK_WINDOWS
RANK() OVER (PARTITIONBY expr1 ORDER BY expr2)
The RANK Функция используется для генерации несмежных порядковых номеров для значений в каждой группе. Одинаковые значения получают одинаковый порядковый номер.
ROW_NUMBER_WINDOWS
ROW_NUMBER() OVER(PARTITION BY expr1 ORDER BY expr2)
Эта ROW_NUMBER Функция используется для генерации последовательных номеров для значений в каждой группе. Одним и тем же значениям присваиваются разные номера последовательности.
AGG_WINDOWS
agg_func(x) OVER(PARTITION BY expr1 ORDER BY expr2)
agg_fun(x) — это агрегатная функция, например, sum(x) и arg(x).
Таблица 4 Агрегатные функции Функция
Использование
Описание
AVG
AVG(x)
Возвращает среднее значение в столбце x.
COUNT
COUNT(x)
Возвращает количество ненулевых значений в столбце x.
MAX
MAX(x)
Возвращает наибольшее значение столбца x.
MIN
MIN(x)
Возвращает наименьшее значение столбца x.
SUM
SUM(x)
Возвращает сумму значений в столбце x.
VAR_POP
VAR_POP(x)
Возвращает дисперсию популяции в столбце x.
VAR_SAMP
VAR_SAMP(x)
Возвращает выборочную дисперсию в столбце x.
STDDEV_SAMP
STDDEV_SAMP(x)
Возвращает стандартное отклонение образцов в столбце x.
STDDEV_POP
STDDEV_POP(x)
Возвращает стандартное отклонение совокупности в столбце x.