Создание задания Spark
В списке сервисов выберите Data Lake Insight.
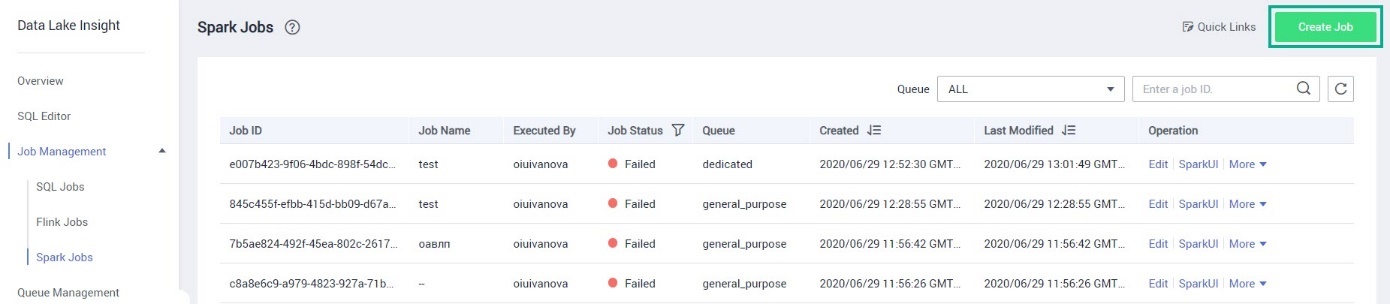
В боковом меню слева выберите Job Management → Spark Jobs.
Нажмите Create Job.
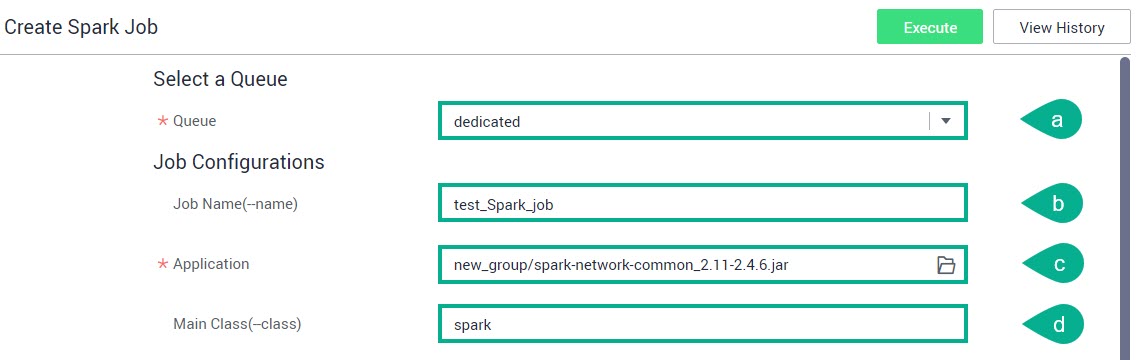
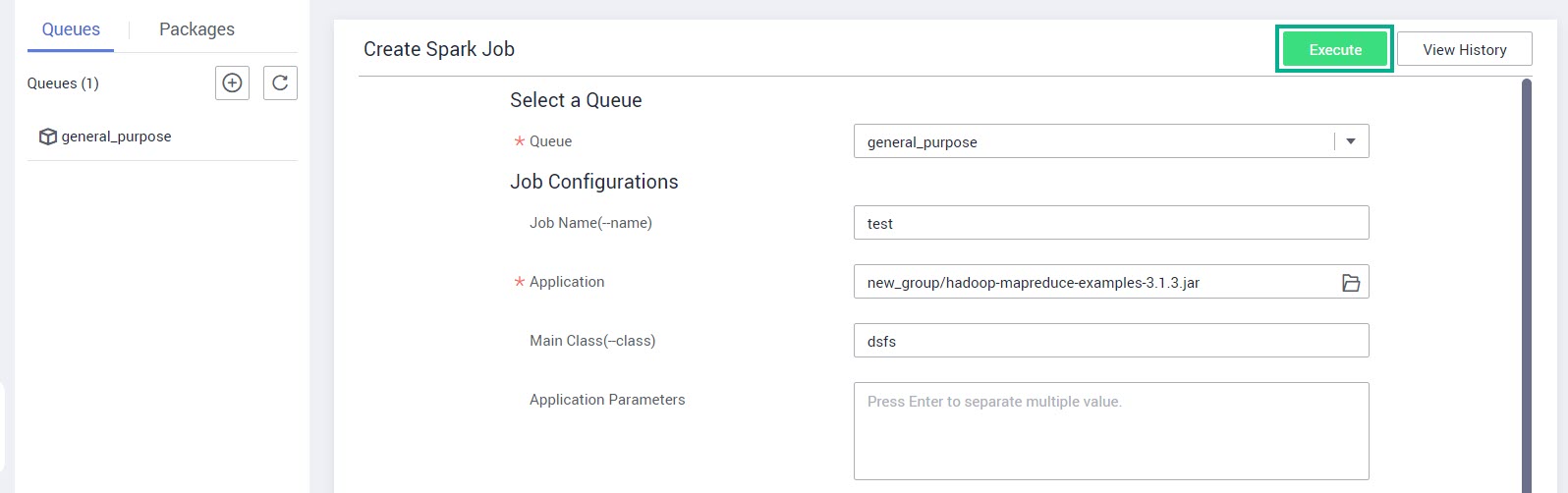
Заполните следующие поля и нажмите Execute:
Queue — выберите из списка очередь.
Job Name — укажите имя задания.
Application — выберите или создайте пакет с приложением.
Main Class — укажите имя главного класса.
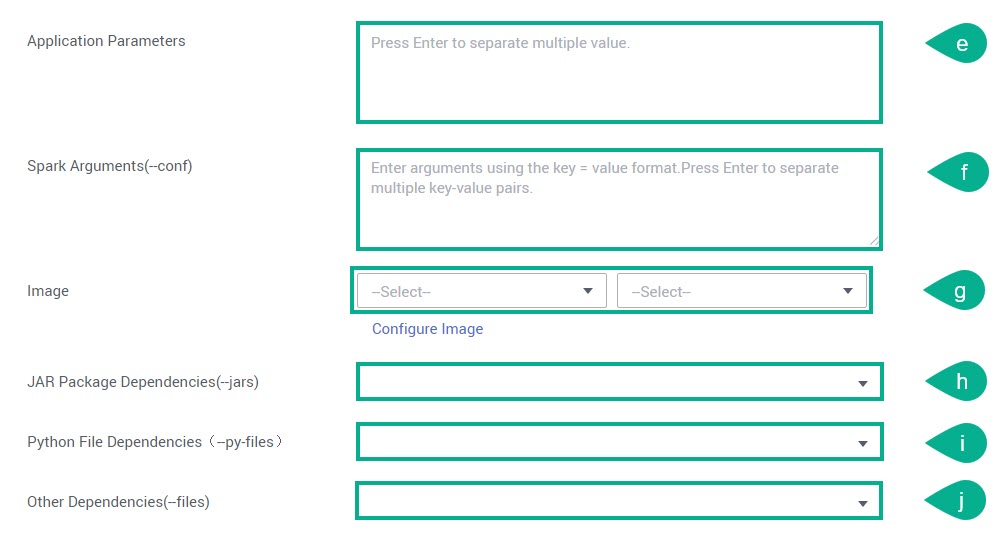
Application Parameters — введите через запятую параметры приложения.
Spark Arguments — введите параметры в следующем формате: ключ = значение (Key = Value). Нажмите клавишу Enter, чтобы разделить несколько пар ключ — значение.
Image — выберите из списка образ и его версию. Если нужного образа нет, то загрузите его через сервис SWR — нажмите Configure Image.
JAR Package Dependencies — выберите из списка JAR-файл.
Python File Dependencies — выберите из списка Python-файл.
Other Dependencies — выберите из списка нужный файл.
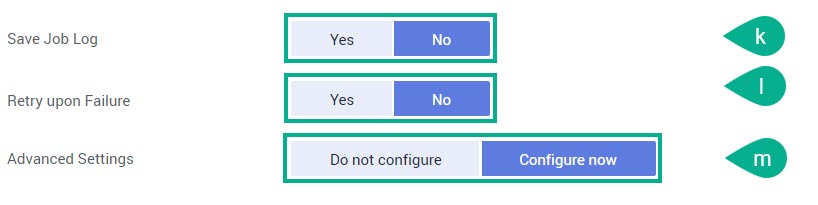
Save Job Log — укажите нужно («Yes») или нет («No») сохранять журналы заданий.
При выборе «Yes» в поле OBS Bucket нужно указать бакет OBS для хранения журналов. Если бакет не авторизован, то появится соответствующее сообщение — нажмите Authorize → ОК.
Retry upon Failure — укажите нужно («Yes») или нет («No») повторять неудачно завершенное задание.
При выборе «Yes» в поле Maximum Retries нужно указать максимальное количество повторных попыток (до 100).
Advanced Settings — укажите нужно («Configure Now») или нет («Do not configure») определять дополнительные настройки задания.
При выборе «Configure Now» перейдите к п.5 Advanced Settings.
При выборе в поле Advanced Settings — «Configure Now» заполните следующие поля:
Module Name — модули зависимостей, предоставляемые DLI для выполнения заданий по подключению к источнику данных (datasource connection). Для получения доступа к различным сервисам нужно выбрать соответствующие модули.
Group Name — выберите из списка название группы, к которой принадлежит пакет ресурсов.
Resource Package — выберите JAR-файл, от которого зависит задание Spark SQL.
Resource Specifications — в раскрывающемся списке выберите одну из трех спецификаций ресурса. Поля, следующие ниже (Executor Memory, Executor Cores, Executors, Driver Cores и Driver Memory) — опции спецификации, у которых можно изменить значение по умолчанию.
Executor Memory — укажите требуемое количество ресурсов.
Executor Cores — укажите требуемое количество ресурсов.
Executors — укажите требуемое количество ресурсов.
Driver Cores — укажите требуемое количество ресурсов.
Driver Memory — укажите требуемое количество ресурсов.

Изменение задания Spark
В списке сервисов выберите Data Lake Insight.
В области навигации слева выберите Job Management → Spark Jobs.
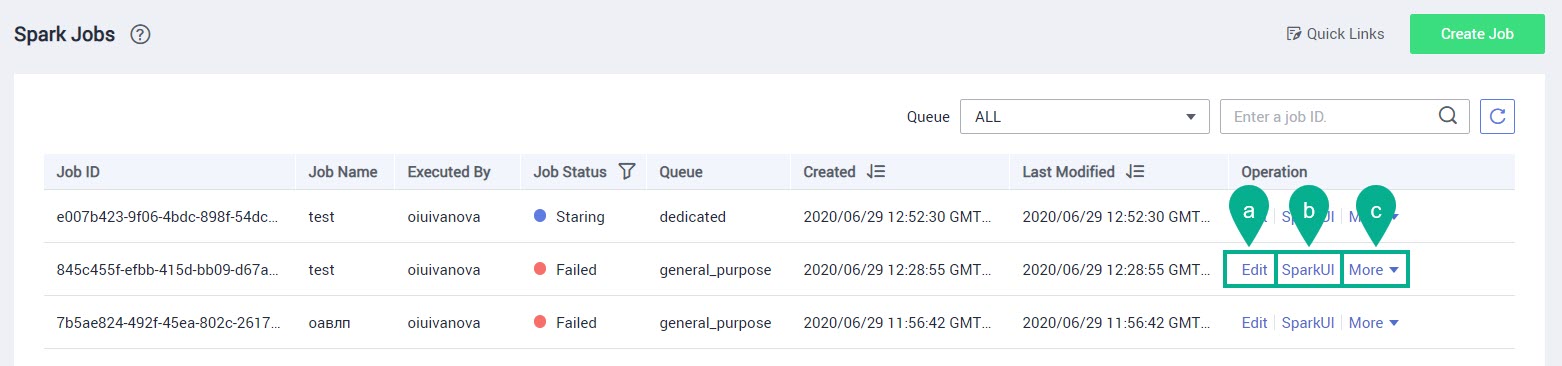
В строке с нужным заданием нажмите Edit.
На странице редактирования можно изменить код задания и выполнить операции аналогичные действиям при создании задания Spark. После внесения изменений нажмите Execute.
Прочие операции с заданиями Spark
В списке сервисов выберите Data Lake Insight.
В области навигации слева выберите Job Management → Spark Jobs.
На данной странице можно выполнить следующие операции:
Edit — изменение задания Spark.
SparkUI — после нажатия этой кнопки отобразится страница выполнения задания Spark.
ПримечаниеНельзя посмотреть страницу SparkUI при статусе задания «Starting».
More — включает в себя следующие опции:
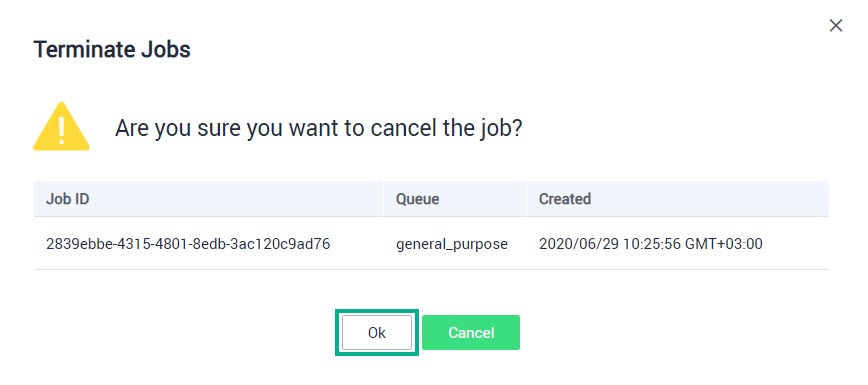
Terminate Jobs — удаление задания.
Commit Log — просмотр журналов отправленных заданий.
Run Log — просмотр журналов выполняемых заданий.
Export Log — экспорт журнала логов в бакет OBS.
ПримечаниеНельзя выгрузить журнал при статусе задания «Running».
Удаление задания Spark
В списке сервисов выберите Data Lake Insight.
В области навигации слева выберите Job Management → Spark Jobs.
В строке с нужным заданием нажмите More и выберите из списка Terminate Jobs.
ПримечаниеНельзя удалить задание, если его статус «Failed» или «Successful».

Нажмите OK.