1. Проверьте нагрузку на узел
Чтобы открыть дашборд с данными мониторинга:
Войдите в консоль Cloud Container Engine.
Нажмите на название кластера.
В левом меню выберите Nodes.
В строке недоступного узла нажмите Monitor.
Чтобы перейти к детальной статистике в сервисе AOM, нажмите View More. Высокие значения использования процессора или памяти приводят к большой задержке сети или к нехватке памяти (OOM), из-за чего узел может перейти в статус «Unavailable».
Возможные варианты решения проблемы высокой нагрузки:
Перенесите рабочую нагрузку на другие узлы и установите верхний предел использования ресурсов для рабочих нагрузок.
Установите квоты на использование CPU и RAM для каждого контейнера.
Очистите данные на узлах кластера.
Добавьте узлы в кластер.
Перезапустите узел в консоли Elastic Cloud Server.
Добавьте отдельные узлы для развертывания требовательных к памяти контейнеров.
Сбросьте узел.
2. Проверьте статус ECS
В консоли CCE перейдите в раздел Resource Management → Clusters и проверьте статус кластера:
Если кластер недоступен (статус «Unavailable»), обратитесь в техническую поддержку для обнаружения ошибки.
Если сам кластер доступен (статус «Available»), но недоступна часть узлов, перейдите к следующему пункту.
В консоли управления выберите Homepage → Computing → Elastic Cloud Server и проверьте статус сервера ECS:
Если статус ECS «Deleted», пересоздайте ECS-узел. Для этого в консоли CCE перейдите в раздел Resource Management → Nodes, удалите соответствующий ECS-узел и создайте новый.
Если статус ECS «Stopped» или «Frozen», запустите ECS. Для этого нажмите More → Start. Как правило, запуск занимает несколько минут.
Если статус ECS «Faulty», перезагрузите ECS Для этого в строке сервера нажмите More → Restart. Если перезагрузка не помогла, обратитесь в техническую поддержку для обнаружения ошибки.
Если статус ECS «Running», авторизуйтесь в виртуальной машине ECS. Для этого в строке нужного сервера нажмите Remote Login и следуйте инструкциям из следующего пункта.
Авторизуйтесь в виртуальной машине ECS для обнаружения ошибки.
Чтобы подключиться к виртуальной машине ECS, на которой расположен неработающий узел, в строке нужного сервера нажмите Remote Login.
Чтобы поверить состояние PaaS-компонентов, введите команду:
su paas -c '/var/paas/monit/bin/monit summary'
Если не удается выполнить команду, обратитесь в техническую поддержку.
При успешном выполнении команды отобразится статус каждого компонента:
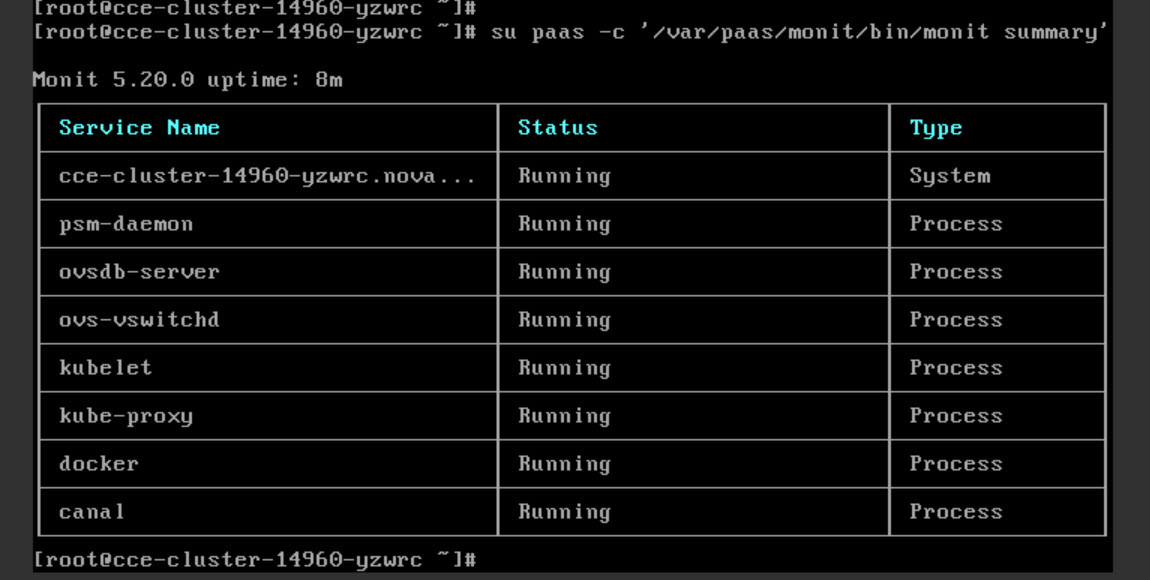
Если у одного из компонентов статус отличается от «Running», перезапустите соответствующий сервис.
Например, у компонента canal нерабочий статус:

Чтобы перезапустить компонент, введите команду:
su paas -c '/var/paas/monit/bin/monit restart canal'После перезагрузки введите команду для запроса статуса компонента:
su paas -c '/var/paas/monit/bin/monit summary'При сохранении неисправности обратитесь в техническую поддержку.
3. Проверьте уровень загрузки узла
Войдите в консоль управления Advanced.
Выберите Homepage → Computing → Elastic Cloud Server.
Нажмите на название виртуальной машины, которая соответствует узлу, и перейдите во вкладку Monitoring.
Изучите информацию об узле. Если узел перегружен, рекомендуется уменьшить рабочую нагрузку.
4. Проверьте группу безопасности (Security Group)
Войдите в консоль управления Advanced.
Выберите Homepage → Computing → Elastic Cloud Server.
Нажмите на название виртуальной машины, которая соответствует узлу, и перейдите на вкладку Security Group.
Раскройте информацию о группе безопасности и проверьте, что правила группы безопасности настроены верно.
5. Проверьте диск
При создании узла прикрепляется диск, предназначенный для Docker, объемом 100 ГБ.
Если этот диск откреплен от узла или поврежден, узел станет нерабочим. Чтобы восстановить работу узла, прикрепите диск и перезапустите узел.
Чтобы проверить наличие диска, нажмите на название виртуальной машины, которая соответствует узлу, и перейдите во вкладку Disks.
6. Проверьте работоспособность внутренних компонентов
Чтобы авторизоваться в виртуальной машине ECS, на которой расположен неработающий узел, в строке нужного сервера нажмите Remote Login.
Чтобы поверить состояние PaaS-компонентов, введите команду:
su paas -c '/var/paas/monit/bin/monit summary'Если не удается выполнить команду, обратитесь в техническую поддержку.
При успешном выполнении команды отобразится статус каждого компонента:
Если у одного из компонентов статус отличается от «Running», перезапустите соответствующий сервис. Например, у компонента canal нерабочий статус:
Перезапустите компонент:
su paas -c '/var/paas/monit/bin/monit restart canal'После перезагрузки введите команду для запроса статуса компонента:
su paas -c '/var/paas/monit/bin/monit summary'Статус каждого компонента после перезагрузки должен быть «Running».
Если не удалось перезапустить компонент, используйте команду:
ps -ef \| grep monitrcЕсли присутствует процесс monitrc, удалите его:
kill -s 9 \`ps -ef \| grep monitrc \| grep -v grep \| awk '{print$2}'\`Процесс monitrc будет автоматически перезапущен после его удаления.
Если процесс monitrc не существует или не перезапускается после его удаления, обратитесь в техническую поддержку.